- 1gitee公开仓库clone出现 fatal: unable to access 的错误_unable to access gitee
- 2如何在Python中安装TensorFlow_tensorflow怎么安装到python
- 3零数科技汽车产业应用入选2023全球数商大会数据要素典型应用场景优秀案例_2023数据要素典型案例
- 4Apache PDFBox 学习
- 5java判断栈中元素数目_Java数据结构与算法-栈和队列
- 6NX二次开发 批量导出图纸 合并DWG_nx多个图纸页输出到一个dwg
- 7超详细的Jmeter随机参数各种搭配_jmeter从csv文件取值随机
- 8echarts柱状图,折线图样式
- 9区块链技术架构分析(数据层)
- 10Vmware workstation pro16虚拟机的安装配置详细教程_vmware16
利用Python进行数字识别_python数字识别
赞
踩
思路
通过Python实现KNN算法。而KNN算法就是K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:如果一个样本在特征空间中的k个最相似的样本中的大多数属于某一个类别,则该样本也属于这个类别。详情可在上一篇文章开头有介绍:
https://www.jianshu.com/p/bddf84a60efc
转载请注明出处:Michael孟良
准备
在Java项目里写了一个RGBUtils的class,将32x32像素的图片全部数字化输出:
package com.yml.common;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
public class RGBUtils {
public static void main(String[]args){ try { BufferedImage bi = ImageIO.read(new File("D:\\workspace\\Utils\\src\\com\\yml\\common\\9_1.png")); String picString = ""; for (int i = 0; i < 32; i++) { for (int j = 0; j < 32; j++) { picString += getRGB(bi, j, i); } picString += "\r\r\n"; } System.out.println(picString); } catch (IOException e) { e.printStackTrace(); } } public static int getRGB(BufferedImage image, int x, int y) { int[] rgb = null; if (image != null && x < image.getWidth() && y < image.getHeight()) { rgb = new int[3]; int pixel = image.getRGB(x, y); rgb[0] = (pixel & 0xff0000) >> 16; rgb[1] = (pixel & 0xff00) >> 8; rgb[2] = (pixel & 0xff); } if(null!=rgb&&255==rgb[0]&&255==rgb[1]&&255==rgb[2]){ return 0; }else{ return 1; } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
}
这是我在PS新建的32x32像素的数字9:
数字9
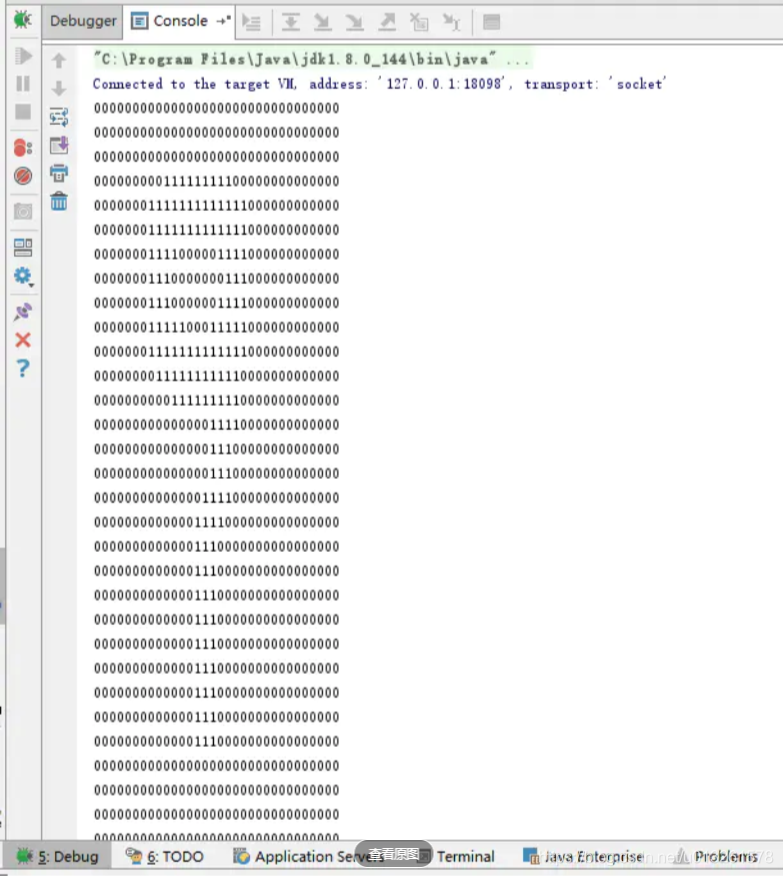
黑色是1白色是0,执行上述java类后得到
数字9
JAVA代码:https://github.com/MichaelYipInGitHub/PythonTest/blob/master/com/test/knn/JavaUtils/RGBUtils.java
要放到java项目里跑
如此这般我写了三个字一个5两个9,将他们变成TXT文件再TestData文件夹下
代码(Python)
coding:utf-8
import os
import numpy as np
此方法将每个文件中3232的矩阵数据,转换到11024一行中
from com.test.knn.KNNArcheyTest import classify
def img2vector(filename):
# 创建一个1行1024列的矩阵
returnVect = np.zeros((1, 1024))
# 打开当前的文件
fr = open(filename, “rb”)
# 每个文件中有32行,每行有32列数据,遍历32个行,将32个列数据放入1024的列中
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0, 32 * i + j] = int(lineStr[j])
return returnVect
def IdentifImg():
labels = []
# 读取训练集 TrainData目录下所有的文件和文件夹
trainingFileList = os.listdir(‘TrainData’)
m = len(trainingFileList)
# zeros((m,1024)) 返回一个m行 ,1024列的矩阵,默认是浮点型的
trainingMat = np.zeros((m, 1024))
for i in range(m):
# 获取文件名称 0_0.txt
fileNameStr = trainingFileList[i]
# 获取文件除了后缀的名称
fileStr = fileNameStr.split(’.’)[0]
# 获取文件"数字"的类别
classNumStr = int(fileStr.split(’’)[0])
labels.append(classNumStr)
# 构建训练集, img2vector 每个文件返回一行数据 1024列
trainingMat[i, :] = img2vector(‘TrainData/%s’ % fileNameStr)
# 读取测试集数据
testFileList = os.listdir(‘TestData’)
errorCount = 0.0
mTest = len(testFileList)
for i in range(mTest):
fileNameStr = testFileList[i] #0_0.txt
fileStr = fileNameStr.split(’.’)[0]
classNumStr = int(fileStr.split(’’)[0])
vectorUnderTest = img2vector(‘TestData/%s’ % fileNameStr)
classifierResult = classify(vectorUnderTest, trainingMat, labels, 5)
print(“识别出的数字是: %d, 真实数字是: %d” % (classifierResult, classNumStr))
if (classifierResult != classNumStr):
errorCount += 1.0
print("\n识别错误次数 %d" % errorCount)
errorRate = errorCount / float(mTest)
print("\n正确率: %f" % (1 - errorRate))
if name == ‘main’:
IdentifImg()
思路
首先将32x32像素的图片转变成一行1024(=32x32)空间坐标,其实就相当于一个1024维的空间。TainData 里面有两千条数据就相当于有两千个点。
我们新建一个方法叫classify,就是把我们要测试的点放到训练数据空间里,看离他最近的k个点是什么值,这里我们K设置为5
normData 测试数据集的某行, dataSet 训练数据集 ,labels 训练数据集的类别,k k的值
def classify(normData, dataSet, labels, k):
# 计算行数
dataSetSize = dataSet.shape[0]
# print (‘dataSetSize 长度 =%d’%dataSetSi ; vzvz ze)
# 当前点到所有点的坐标差值 ,np.tile(x,(y,1)) 复制x 共y行 1列
diffMat = np.tile(normData, (dataSetSize, 1)) - dataSet
# 对每个坐标差值平方
sqDiffMat = diffMat ** 2
# 对于二维数组 sqDiffMat.sum(axis=0)指 对向量每列求和,sqDiffMat.sum(axis=1)是对向量每行求和,返回一个长度为行数的数组
# 例如:narr = array([[ 1., 4., 6.],
# [ 2., 5., 3.]])
# narr.sum(axis=1) = array([ 11., 10.])
# narr.sum(axis=0) = array([ 3., 9., 9.])
sqDistances = sqDiffMat.sum(axis=1)
# 欧式距离 最后开方
distance = sqDistances ** 0.5
# x.argsort() 将x中的元素从小到大排序,提取其对应的index 索引,返回数组
# 例: tsum = array([ 11., 10.]) ---- tsum.argsort() = array([1, 0])
sortedDistIndicies = distance.argsort()
# classCount保存的K是魅力类型 V:在K个近邻中某一个类型的次数
classCount = {}
for i in range(k):
# 获取对应的下标的类别
voteLabel = labels[sortedDistIndicies[i]]
# 给相同的类别次数计数
classCount[voteLabel] = classCount.get(voteLabel, 0) + 1
# sorted 排序 返回新的list
# sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
sortedClassCount = sorted(classCount.items(), key=lambda x: x[1], reverse=True)
return sortedClassCount[0][0]
我之前写的3的数字也变成1024维空间的点,选择最近的五个点进行判断。
输出结果
原来图片
代码
https://github.com/MichaelYipInGitHub/PythonTest/blob/master/com/test/knn/IdentifImg.py
总结
1.Python没用封装KNN 算法, 因为太简单,可以直接手写。
2.从图片上看, 我用粗笔写的数字能识别到,细笔写的就识别不到,这可能与我的训练数据多为粗笔字体。
3.数字识别可以引申到动物识别,人物识别,不过他们用的像素不只是0和1,数据会更加庞大, 算法更加复杂。
作者:Michael孟良
链接:https://www.jianshu.com/p/eea94034e3be
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。