
热门标签
热门文章
- 1Intel SDM 之 APIC Virtualization and Virtual Interrupts
- 2SQL学习(1)——表相关操作_sql对表的操作
- 3OHIF Viewers:下一代医学影像查看器的技术解析与应用
- 4ubuntu下安装wordpress博客系统网站的详细讲解_ubuntu wordpress官网
- 5AppsFlyer 研究(五)延迟深度链接&客户端获取归因数据_appsflyer:there was an error getting deep link dat
- 6微软Edge浏览器深度解析:功能、同步、隐私与安全
- 7mysql5.7安装audit审计插件
- 8网络安全到底是什么?一篇概念详解(附学习资料)
- 9《微信小程序-基础篇》带你了解小程序中的生命周期(二)_小程序声明周期
- 10Threejs实现立体3D园区解决方案及代码_threejs3d智慧园区
当前位置: article > 正文
2D Attention Network for Scene Text Recognition
作者:笔触狂放9 | 2024-06-09 05:30:51
赞
踩
2d attention
paper地址:2D Attentional Irregular Scene Text Recognizer.
继 Transformer-based-OCR 后又一篇基于语言、翻译模型架构的不规则文字识别的paper,主要贡献如下:
- attention部分使用多层双向transformer的block(BERT)替代了单transformer block;
- label只用于计算loss,不用作网络输入,因此output过程是一次性输出整个字符串,精度和inference速度较之Transformer-based OCR都有所改善;
- decoder部分串联了一个BERT attention模块,增强了输出节点间(每个字符作为一个节点)的依赖关系;
- 支持多行字符识别;
网络结构:

- Feature Extraction Module:图像resize为32x100作为输入,encoder部分是基于ResNet的CNN模块,得到的feature map 经过flatten操作压缩为一维特征向量,记为
I ;再将I 按照顺序做 position encoding 得到位置编码矩阵E ,最后将F =I +E 作为encoder输出和后面的 Relation Attention 模块的输入; - Relation Attention Module 为一个BERT模块(橘黄色虚线处),其具体结构如下:

这是一个多层双向的transformer block,关于transformer block的具体信息,参见上篇曲形文字识别的博文:Transformer-based OCR;其中还是有几点值得说一下:
- 首先这一块的输入为前面的
F (即每一个 transformer block 的Q, K, V均为F ); - 没有self attention mask,因为预测时整个字符串一同输出,不存在靠后的字符泄露信息给前面字符的问题;
- 论文中 block size 和 layer 层数均取 2;
- Parallel Attention module部分实际上是在上一个BERT模块输出的基础上做线性变换和softmax,其公式如下:
![]() 其中
其中
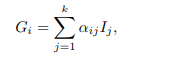
- decoder:作者称之为 two stage decoder,一般来说,在得到上述的glimpse矩阵
G 后,经过一个线性变换和softmax就可以得出最终的预测结果,但是作者认为因为 parallel attention 部分的计算使得输出节点之间的依赖关系丢失,为了弥补这一部分的损失,在G 之后又接了一个BERT模块,得到的glimpse' 再经过常规的decoder操作得到输出字符串。和前面的transformer 还有 RNN / LSTM attention网络不同,这里直接输出n个字符节点(论文中n取35,即一般单词长度不会超过35),并且以EOS标志前的字符节点作为最终的预测结果。这样的好处就是每一个字符的输出不依赖前一个字符的输入,所以不会出现中间字符预测错误后对后面字符的预测有影响的情况。结构图如下:

上面为G直接decode,下面为经过一个BERT模块再decode,inference时取下面的结果为最终结果。
- 网络的loss函数为两个stage的branch预测的结果分别与ground truth的做cross entropy,再相加得到的和作为网络总的loss。
公共数据集上的表现:

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/笔触狂放9/article/detail/692810
推荐阅读
相关标签

