
Raki的读paper小记:An Image is Worth One Word Personalizing Text2Image using Textual Inversion_an image is worth one word: personalizing text-to-
赞
踩
Abstract&Introduction&Related Work
- 研究任务
- text2image model
- 已有方法和相关工作
- Text-guided synthesis
- 通常条件模型经过训练以从给定的成对图像标题数据集中再现样本
- 使用注意力机制或者跨模态对比学习方法
- 大型自回归模型
- 扩散模型
- 基于文本的界面进行图像编辑
- generator域自适应
- 视频操控
- motion synthesis
- 风格迁移
- 3D对象的纹理合成
- GAN inversion
- optimization-based technique
- 使用encoder
- Diffusion-based inversion
- Personalization
- 个性化模型通常出现在推荐系统领域
- federated learning
- Text-guided synthesis
- 面临挑战
- 创新思路
- 通过使用三五张新的‘words’在冻结权重的text-to-image model(也就是作为特征抽取器)的embedding空间的表示来学习,用户提供的概念,然后这些‘words’可以组成自然语言句子,通过启发式方法来创造个性化的创作
- 对比之前的工作将给定图像转化到模型的latent space,我们转化用户提供的概念。此外,我们将这个概念表示为模型词汇表中的一个新的伪词, for more general and intuitive editing
- 实验结论
- 我们发现有证据表明,一个单词的embedding就足以捕获独特而多样的概念
- 我们的方法建立在开放式条件合成模型的基础上。我们展示了我们可以扩展冻结模型的词汇表并引入描述特定概念的新伪词,而不是从头开始训练新模型。
跟prompt非常类似,但是用了图片在特征空间的表示来学习

Method
模型的目标是支持以语言为导向生成新的、用户指定的概念。为此,我们的目标是将这些概念编码为预先训练的 text-to-image模型的中间表示
在 text-to-image model通常使用的文本编码器的word-embedding阶段,搜索此类表示的候选项是很自然的。离散的输入文本首先被转换为一个连续的向量表示形式,该表示形式易于直接优化
我们的目标是找到可以指导生成的伪词,这是一项视觉任务。因此我们建议通过视觉重建目标找到它们
Latent Diffusion Models
We implement our method over Latent Diffusion Models (LDMs) (High-resolution image synthesis with latent diffusion models, 2021), a recently introduced class of Denoising Diffusion Probabilistic Models (DDPMs) (Denoising diffusion probabilistic models, 2020) that operate in the latent space of an autoencoder
LDMs由一个在大规模图像数据上预训练好的自编码器和diffusion model组成
扩散模型被训练在学习的潜在空间内produce code,扩散模型可以以类标签、分段掩码,甚至联合训练的文本嵌入模型的输出为条件。设 c θ ( y ) c_{\theta}(y) cθ(y) 是将条件输入 y y y 映射为条件向量的模型。LDM损失函数:

t
t
t 是time step,
z
t
z_t
zt 是时刻
t
t
t 的潜在噪音,
ϵ
\epsilon
ϵ是 unscaled noise sample,
ϵ
θ
\epsilon_{\theta}
ϵθ是去噪网络,目的是准确的移去图片中加入的潜在噪声
在推理时,对随机噪声张量进行采样并迭代去噪,以产生一个新的潜在图像 z 0 z_0 z0,最后,该潜在代码通过预的解码器 x 0 ′ = D ( z 0 ) x_0^{'} = D(z_0) x0′=D(z0)转换为图像
使用1.4B参数的text-to-image model(High-resolution image synthesis with latent diffusion models, 2021)
ϵ θ \epsilon_{\theta} ϵθ用BERT作为文本编码器,y是提示文本
首先将输入字符串中的每个单词或子词转换为一个token,该token是某些预定义字典中的索引。然后,每个token都链接到一个唯一的embedding 向量,该embedding向量可以通过基于索引的查找进行检索。这些嵌入向量通常作为文本编码器 ϵ θ \epsilon_{\theta} ϵθ 的一部分来学习
选择这个embedding space作为转换的目标,指定了一个占位符字符串
S
∗
S_∗
S∗, 代表我们希望学习的新概念。我们介入嵌入过程,并用一个新的学习嵌入
v
∗
v_∗
v∗ 替换与token化字符串相关联的向量, 本质上,将这个概念“注入”到我们的词汇中。这样,我们就可以组成包含这个概念的新句子,就像我们处理其他单词一样

为了找到这些新的嵌入,我们使用了一小组图像(通常为3-5幅),这些图像描述了我们在多种背景或姿势下的目标概念。我们找到
v
∗
v_∗
v∗ 通过直接优化,最小化
L
L
D
M
L_{LDM}
LLDM 在从小集合采样的图像上的LDM损失
为了调整生成条件,我们随机抽样了来自CLIP图像网模板的中性上下文文本
优化目标定义为:
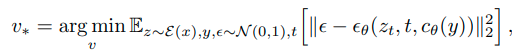
并通过重复使用与原始LDM模型相同的训练方案来实现,同时保持
c
θ
c_θ
cθ和
θ
θ
θ 不变。这是一项重建任务。因此我们希望它能够激发学习到的embedding,以捕捉概念特有的精细视觉细节
Experiments

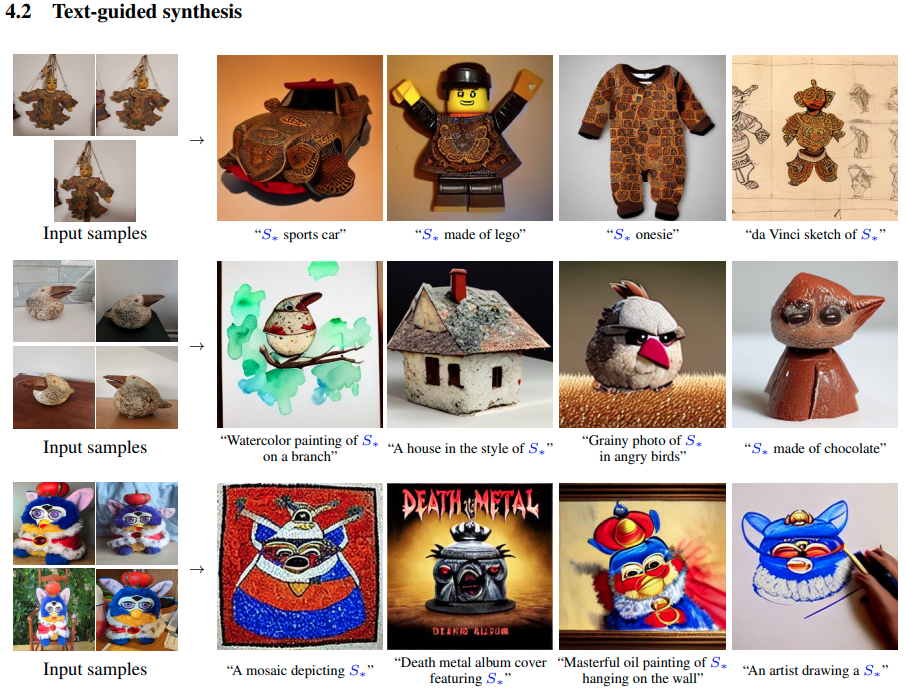





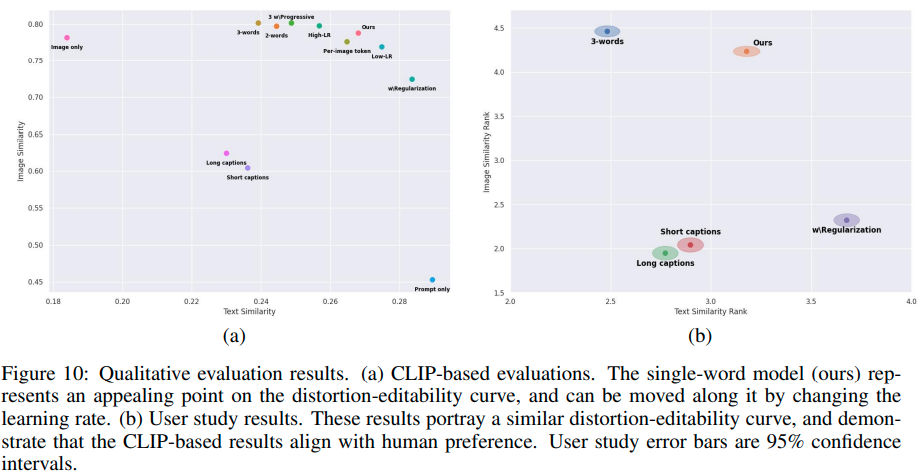
Limitations
虽然我们的方法提供了更多的自由度,但它可能仍然难以学习精确的形状,而不是融入概念的“语义”本质。对于艺术创作来说,这通常就足够了。未来,我们希望能够更好地控制重构概念的准确性,使用户能够利用我们的方法处理需要更高精度的任务
我们方法的另一个限制是优化时间过长。使用我们的设置,学习一个概念大约需要两个小时。通过训练编码器将一组图像直接映射到其文本embedding,可以缩短这些时间
Social impact
文本到图像模型可用于生成误导性内容和促进虚假信息。个性化创建可以让用户打造更具说服力的非公共个人图像。然而,我们的模型目前并没有将身份保留到令人担忧的程度。
这些模型更容易受到训练数据中发现的偏差的影响。例如,在描绘“医生”和“护士”时存在性别偏见,在要求科学家拍照时存在种族偏见,以及在促成“婚礼”时存在更微妙的偏见,例如过度代表异性伴侣和西方传统(Mishkin等人,2022)。当我们建立在这样的模型上时,我们自己的工作可能同样会表现出偏见

然而,如图8所示,我们更精确地描述特定概念的能力也可以作为减少这些偏见的一种手段。
最后,学习艺术风格的能力可能被滥用来侵犯版权。用户可以在未经同意的情况下对自己的图像进行培训,并以类似的风格制作图像,而不是为艺术家的作品付钱
虽然生成的艺术品仍然很容易识别,但在未来,此类侵权行为可能很难被发现或合法追查。然而,我们希望这些工具可以为艺术家提供新的机会来弥补这些不足,例如能够授权他们的独特风格,或者能够快速创建新作品的早期原型
Conclusions
我们介绍了个性化、语言引导的生成任务,其中利用文本到图像模型在新颖的场景和场景中创建特定概念的图像。我们的方法,“文本转换”,通过在预先训练的文本到图像模型的文本嵌入空间内将概念转换为新的伪词来操作。这些伪词可以通过简单的自然语言描述注入到新场景中,从而进行简单直观的修改。从某种意义上说,我们的方法允许用户利用多模态信息——使用文本驱动的界面以便于编辑,但在接近自然语言的极限时提供视觉提示。
我们的方法是在LDM(Rombach等人,2021)上实现的,LDM是最大的公开文本到图像模型。然而,它并不依赖于任何独特的 architectural details。因此,我们认为文本转换很容易应用于其他更大比例的文本到图像模型。在那里,文本到图像的对齐、形状保持和图像生成保真度可能会进一步提高
我们希望我们的方法为未来的个性化生成工作铺平道路。这些可能是众多下游应用程序的核心,从提供艺术灵感到产品设计
Remark
一篇有意思的多模态工作,做的是“个性化”,跟风格迁移有点联系,基于CLIP,不得不说CLIP是真的能打呀

