
- 1DataWhale打卡Day01--推荐系统入门_隐语义模型与矩阵分解 协同过滤算法的特点: 协同过滤算法的特点就是完全没有利用
- 2知识图谱——事件抽取
- 3Golang 学习笔记3:Go 并发与网络_go 接口并发
- 4从GitHub克隆项目到本地
- 5卷完了!分享下我的秋招面经(投递近50家自动驾驶与机器人公司)_杉川机器人结构创新工程师面试经验
- 62020B证(安全员)模拟考试系统及B证(安全员)考试试题_安全员b证历年真题试卷网盘
- 7Transformer的位置编码笔记(positional encoding)_transformer位置编码为啥用sin和cos
- 8git从tag拉分支_git 从tag拉分支
- 9IDEA JRebel最新版(2024.2.0)在线激活以及配置_idea插件jrebel 2024.2.0激活
- 10谷歌将正式推出 Fuchsia OS,已有适配设备_fuchsia os支持设备
4.kylin的Cube的构建优化_kylin cube优化
赞
踩
一丶Cube的构建算法
逐层构建算法:
说明:我们知道,在逐层算法中,按维度层数减少来计算,每一层级的计算,是基于他上一层级的结果来计算的,每一轮的计算都是一个 MapReduce 任务,且串行执行;一个 N 维的Cube,至少需要 N 次 MapReduce Job。
图解:

优点:
- 此算法充分利用了 MapReduce 的优点,处理了中间复杂的排序和 shuffle 工作,故 而算法代码清晰简单,易于维护;
- 受益于 Hadoop 的日趋成熟,此算法非常稳定,即便是集群资源紧张时,也能保证 最终能够完成
缺点:
- MapReduce 任务过多,耗费集群的资源
- Map中,没有进行聚合操作,shuffle压力过大,效率会降低
快速构建算法:
图解:

与逐层构建算法来比:
- Mapper 会
利用内存做预聚合,算出所有组合;Mapper 输出的每个 Key 都是不同的, 这样会减少输出到 Hadoop MapReduce 的数据量, 最后再会进行聚合一次大reduce,Combiner 也不再需要; - 一轮 MapReduce 便会完成所有层次的计算,减少 Hadoop 任务的调配
- 没有逐层构建算法稳定, 毕竟是基于内存做的聚合
总结: kylin在这里面做的很完善, 会根据数据, 自动选择不同的算法来进行计算,这一点我们无需担心
二丶 Cube的存储原理
为了提高,查询的效率以及减少存储的数据量;
cube 到hbase进行存储图解:


文字说明:
- 我们会将各个维度,进行映射为一个数字,来标明(我们这里先称它为A)
- hbase存储的时候,row key 会采用 Cuboid id+A 来进行存储
- Cuboid id是维度的层级的组合,维度值是维度所对应的值的组合
- 有人会想到, 如果这个对应的数字标明是两位,三位数,这时候是怎么存储的呢?其实是按照下面方式进行存储的,而不是真的按照数字存储
图解: 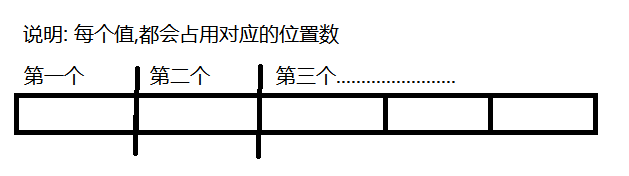
三丶Cube的构建优化
问: 我们为什么要进行优化?
答: 因为我们构建的维度的组合个数是呈指数增长的,当我们的维度达到几十,甚至上百个的时候, 这个时候构建Cube将会被称为灾难,所以kylin给我们提供了以下几种解决方案;
3.1使用聚合组(Aggregation group)
聚合组是一种强大的剪枝工具,我们可以将一些没有满足我们的硬性条件给过滤掉,减少Cube的构建维度分组
1.强制维度(Mandatory)
如果一个维度被定义为强制维度,那么这个分组产生的所 有 Cuboid 中每一个 Cuboid 都会包含该维度。每个分组中都可以有 0 个、1 个或多个强制维 度。
如果根据这个分组的业务逻辑,则相关的查询一定会在过滤条件或分组条件中,因此可以在该分组中把该维度设置为强制维度

2.层级维度(Hierarchy)
如果根据这个分组的业务逻辑,则
多个维度直接存在层级关系,因此可以在该分组中把这些维度设置为层级维度。(如地区的省级,市级,县级,县级和市级,就不应该单独存在,因为容易有重名的)

3.联合维度(Joint)
每个联合中包含两个或更多个维度,如果某些列形成一个联合, 那么在该分组产生的任何 Cuboid 中,这些联合维度
要么一起出现,要么都不出现。每个分 组中可以有 0 个或多个联合,但是不同的联合之间不应当有共享的维度

3.2 Row key 的优化
1. 被用作where过滤的维度放在前面:

2. 基数大的维度放在及基数小的维度前面:

3.3 并发粒度优化
当 Segment 中某一个 Cuboid 的大小超出一定的阈值时,系统会将该 Cuboid 的数据分片 到多个分区中,以实现 Cuboid 数据读取的并行化,从而优化 Cube 的查询速度。具体的实 现方式如下:构建引擎根据 Segment 估计的大小,以及参数“
kylin.hbase.region.cut”的设置决 定 Segment 在存储引擎中总共需要几个分区来存储,如果存储引擎是 HBase,那么分区的数 量就对应于 HBase 中的 Region 数量。kylin.hbase.region.cut的默认值是 5.0,单位是 GB,也 就是说对于一个大小估计是 50GB 的 Segment,构建引擎会给它分配 10 个分区。用户还可 以通过设置kylin.hbase.region.count.min(默认为 1)和 kylin.hbase.region.count.max(默认为 500)两个配置来决定每个 Segment 最少或最多被划分成多少个分区。
3.4 衍生维度
我也没搞明白是怎么回事…这里实在不好意思
总结: 只知道是以查询时的速度慢,换取了构建Cube时的快速度


