
- 1鸿蒙ArkTS声明式组件:【DataPanel】
- 2【声源定位】广义互相关声源定位【含Matlab源码 548期】_声源广义互相关
- 3Python中使用opencv-python进行人脸检测_python opencv人脸识别
- 4C语言算法之CART决策树算法_决策树的c语言代码
- 5【Docker】docker 镜像如何push到私有docker仓库_docker push 到私有仓库
- 61024程序员节快乐!_1024 程序员节 有趣
- 7Java知识体系只这一篇就够了!
- 8Nacos惊现安全漏洞修复后问题仍旧存在_warn invalid server identity value for nacos
- 9微软服务器dda,实战DDA硬件直通:Hyper-V虚拟机直通NVMe固态硬盘
- 10植物大战僵尸的背后技术_慧编程植物大战僵尸
Jmeter性能测试_jemter 平均执行
赞
踩
1. 简介
JMeter是Apache组织开发的基于Java的压力测试工具,用于对软件做压力测试。可以用于测试静态和动态资源,例如静态文件、Java服务小程序、CGI脚本、Java对象、数据库、FTP服务器等。JMeter可以用于对服务器、网络或对象模拟巨大的负载,来在不同压力类别下测试他们的强度和分系整体性能。
2. 进程与线程区别
线程:是程序执行流的最小单元,是系统独立调度和分配CPU(独立运行)的基本单位。
进程:是资源分配的基本单位。一个进程包括多个线程。
多线程:同一时刻执行多个线程。如,用浏览器一边下载,一边听歌,一边看视频,一边看网页…
多进程:同时执行多个程序。如,同时运行微信,QQ,以及各种浏览器
3. Jmeter性能测试的一些相关概念
(1)压测:通过逐步加压的方法,使得系统的某些资源达到饱和,甚至失效的状态,简单粗暴的解释就是什么条件能把系统压崩溃。Jmeter通过模拟大量的虚拟用户向服务器产生负载,使服务器的资源处于极限状态下长时间连续运行,以测试服务器在高负载情况下是否能够稳定工作。
(2)并发:在操作系统中,是指一个时间段中有几个程序都处于已启动运行到运行完毕之间,且这几个程序都是在同一个处理机上运行,但任一个时刻点上只有一个程序在处理机上运行。也就是说并发是指在一段时间内宏观上多个程序同时运行。(区别于并行,并行是指在同一时刻,有多条指令在多个处理器上同时执行。所以无论从微观还是从宏观来看,二者都是一起执行的。)JMeter是以线程的方式来进行模拟用户的并发访问的。
(3)并行:当系统有一个以上CPU时,则线程的操作有可能非并发。当一个CPU执行一个线程时,另一个CPU可以执行另一个线程,两个线程互不抢占CPU资源,可以同时进行,这种方式我们称之为并行(Parallel)
(4)吞吐量(Throughput):是指系统在单位时间处理的请求数量。对于无并发的应用系统而言,吞吐量与响应时间成严格的反比关系,实际此时吞吐量就是响应时间的倒数。对于单用户的系统,响应时间可以很好地度量系统的性能,但对于并发系统,通常需要吞吐量作为性能指标。
(5)QPS每秒查询率(Query Per Second)每秒查询率QPS是对一个特定的查询服务器在规定的查询服务器在规定时间内所处理流量多少的衡量标准。(类似于TPS,只是应用于特定场景的吞吐量)
- 术语解释
(1)测试计划:测试脚本根节点,每一个测试脚本都是一个测试计划,名称可以自己定义。
(2)线程组:控制多线程并发,设置虚拟用户。
(3)取样器(Sampler):放置请求,如常用的:HTTP请求
(4)断言:预期结果和实际结果比对。
(5)定时器:操作线程时候停顿多长时间之类。
(6)监听器:重要组成部分,是对取样器的请求结果显示、统计一些数据(吞吐量、KB/S…)等
(7)配置元件: 重要组成部分,可以在里面获取cookie信息之类的配置信息。
(8)后置处理器: 在并发完成后想要做什么。后一个请求用到前一个请求的结果,用后置处理器就可以拿到,放的一个变量里,下一次请求去用。
(9)前置处理器:请求发生前做什么。
(10)逻辑控制器:当一个条件满足时,需要去做的操作。
5. JMeter的使用
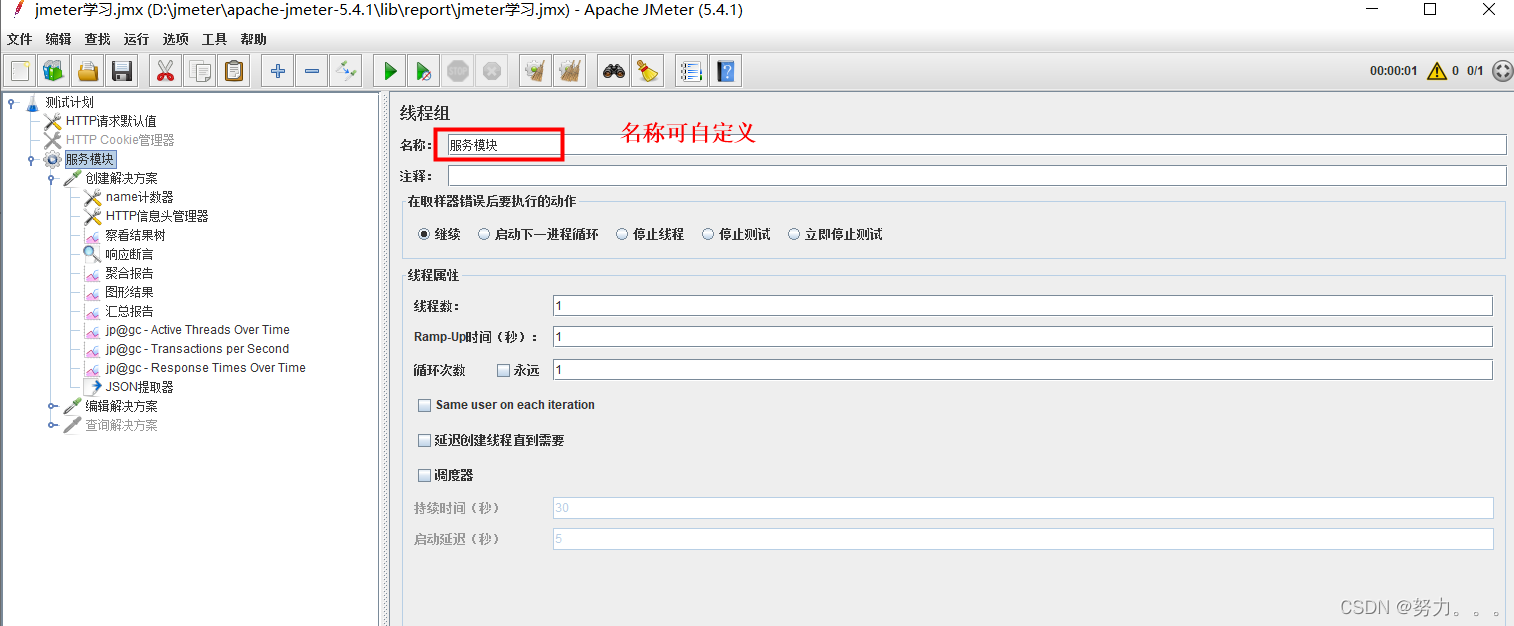
第一步:创建线程组(右键点击测试计划–>添加–>线程(用户)–>线程组)
参数解释
(1)线程数:这里就是指虚拟用户数,默认的输入是“1”,则表明模拟一个虚拟用户访问被测系统,如果想模拟100个用户,则此处输入100。
(2)Ramp-up时间(秒):设置的虚拟用户数需要多长时间全部启动。如果线程数为10,准备时长为2,那么需要2秒钟启动10个线程,也就是每秒钟启动5个线程
(3)循环次数:该处设置一个虚拟用户做多少次的测试。默认为1,意味着一个虚拟用户做完一遍事情之后,该虚拟用户停止运行。
调度器选项
(1)持续时间(秒):测试计划持续运行时间
(2)启动延迟(秒):测试计划延迟启动的时间
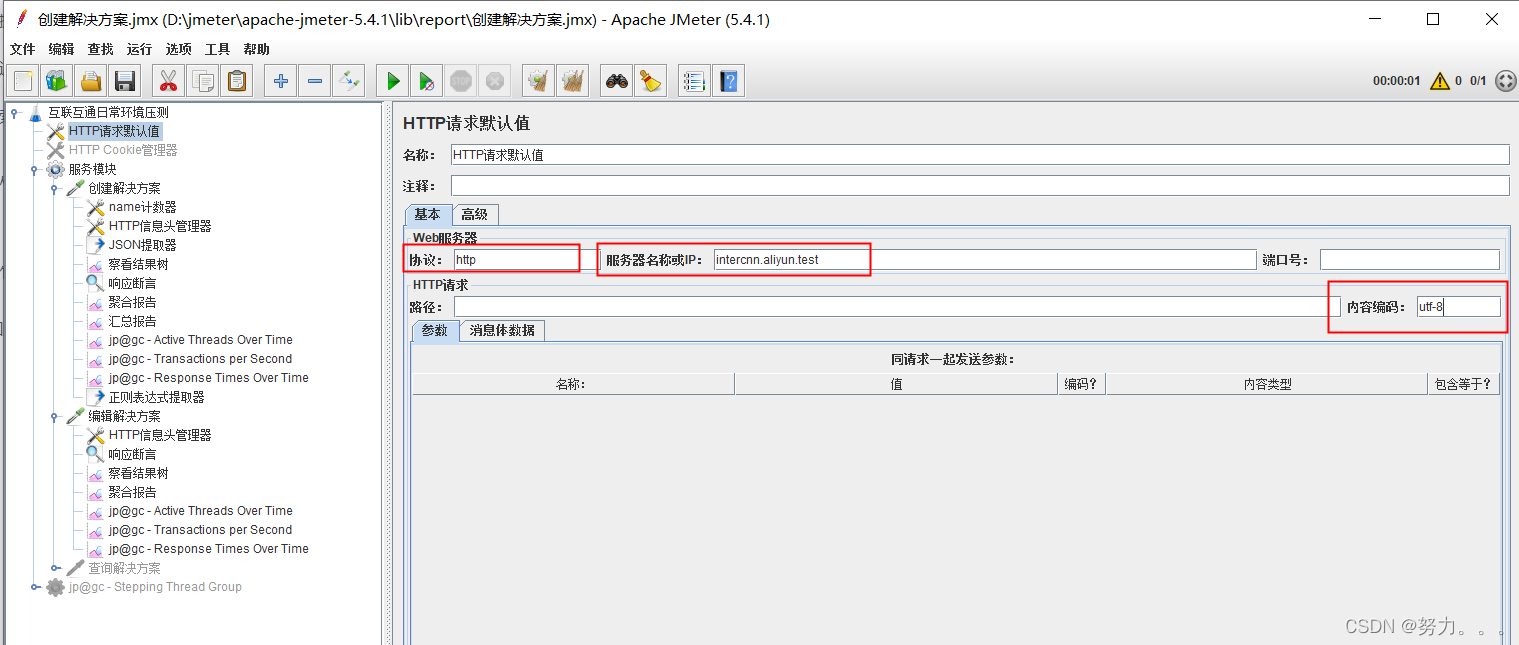
第二步:添加HTTP请求默认值(右键点击测试计划–>添加–>配置元件–>HTTP请求默认值)
例如接口URL:http://intercnn.aliyun.test/rest/intercnn/product/save
(1)HTTP 请求默认值可以直接添加到线程组下面,也可以添加到某个 HTTP 请求下面
(2)如果是在线程组下的 HTTP 请求默认值,那么它的作用域就是该线程组下的所有 HTTP 请求,包括子级、孙子级、孙孙子级的 HTTP 请求
(3)如果实在某个 HTTP 请求下的 HTTP 请求默认值,那么它的作用域就只针对这个 HTTP 请求
(4)线程组的 HTTP 请求默认值的优先级小于HTTP 请求下的 HTTP请求默认值
(5)所有 HTTP 请求默认值的优先级都比 HTTP 请求低
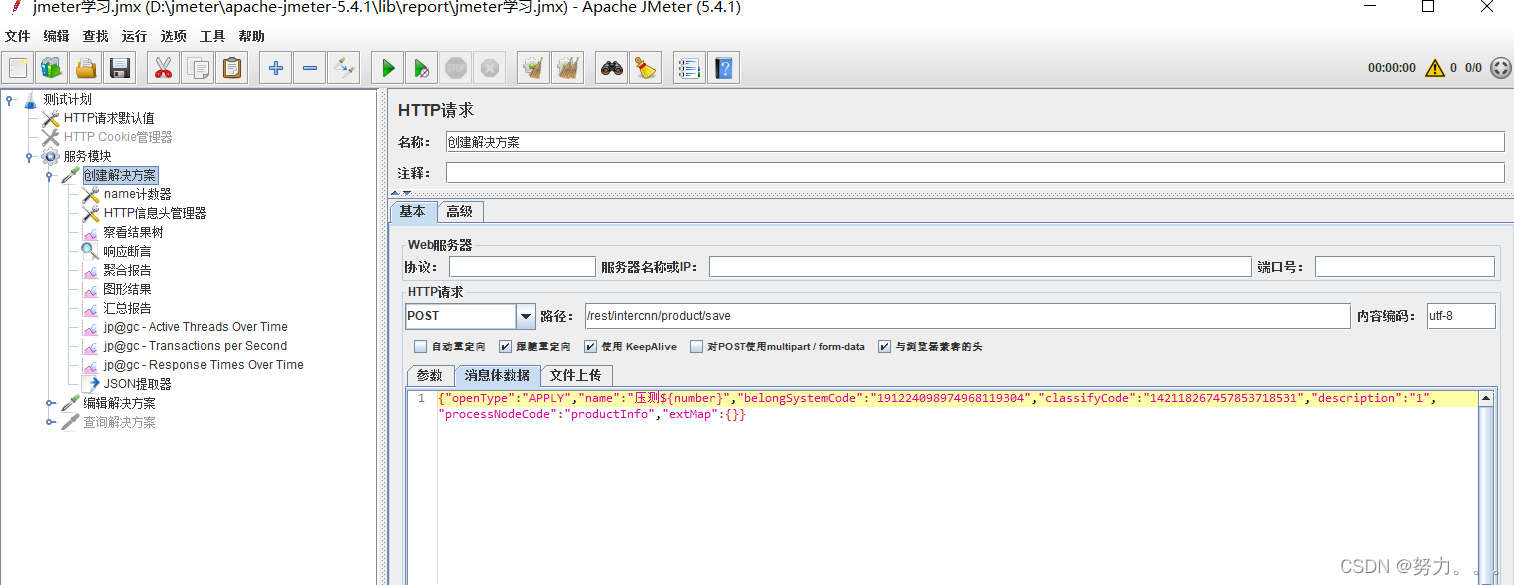
第三步:添加取样器(添加HTTP请求)(右键点击线程组–>添加–>取样器(Sampler)–>HTTP请求)
例如压测接口1:创建解决方案接口压测
Web服务器测试
(1)协议:向目标服务器发送HTTP请求协议,可以是HTTP或HTTPS,默认为HTTP
(2)服务器名称或IP :HTTP请求发送的目标服务器名称或IP
(3)端口号:目标服务器的端口号,默认值为80
HTTP请求
(1)方法:发送HTTP请求的方法,可用方法包括GET、POST、HEAD、PUT、等
(2)路径:目标URL路径(URL中去掉服务器地址、端口及参数后面的剩余部分)
(3)Content encoding(内容编码):编码方式,默认为ISO-8859编码,这里配置为utf-8
(4)参数:同请求一起发送参数,在请求中发送的URL参数,用户可以将URL中所有参数设置在本表中,表中每行为一个参数(对应URL中的 name=value),注意参数传入中文时需要勾选“编码”
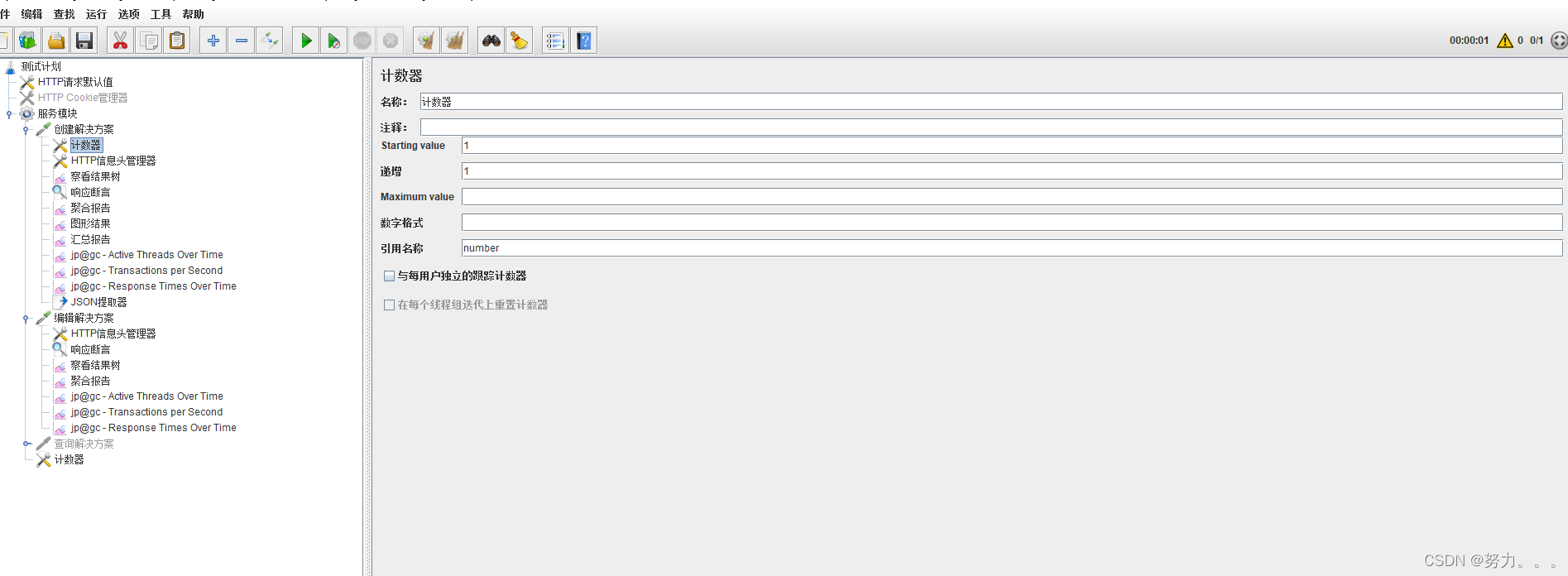
第四步:添加计数器(右键点击HTTP请求–>添加–>配置元件–>计数器)
(1)starting value:计数起始值;
(2)递增(Increment):计数器执⾏每次增加的值,例:初始值为1,递增2,计数器每次执⾏迭代的数字为1,3,5,7;
(3)maximum value:计数器最⼤值,包含最⼤值,如果超过最⼤值,则重新从起始值开始计数,持续压测的话建议不要设置最⼤值,不设置的话,默认为Long.MAX_VALUE,2^63-1;
(4)数字格式(Number format):可选格式,例:000,格式化后计数器输出001,003,005,007;
(5)引⽤名称(Reference Name):变量名,给计数器起个名字⽅便其他地⽅进⾏引⽤,形式${number};
(6)与每⽤户独⽴的跟踪计数器(Track Counter Independently for each User):全局计数器;
(7)如果不勾选,即全局的,⽐如⽤户#1 获取值为1,⽤户#2获取值还是为1;
(8)如果勾选,即独⽴的,则每个⽤户有⾃⼰的值:⽐如⽤户#1 获取值为1,⽤户#2获取值为2。
(9)在每个线程组迭代上重置计数器(Reset counter on each Thread Group Iteration):可选,仅勾选与每⽤户独⽴的跟踪计数器时可⽤;
(10)如果勾选,则每次线程组迭代,都会重置计数器的值,当线程组是在⼀个循环控制器内时⽐较有⽤
计数器的引用
引用形式${引用名称}
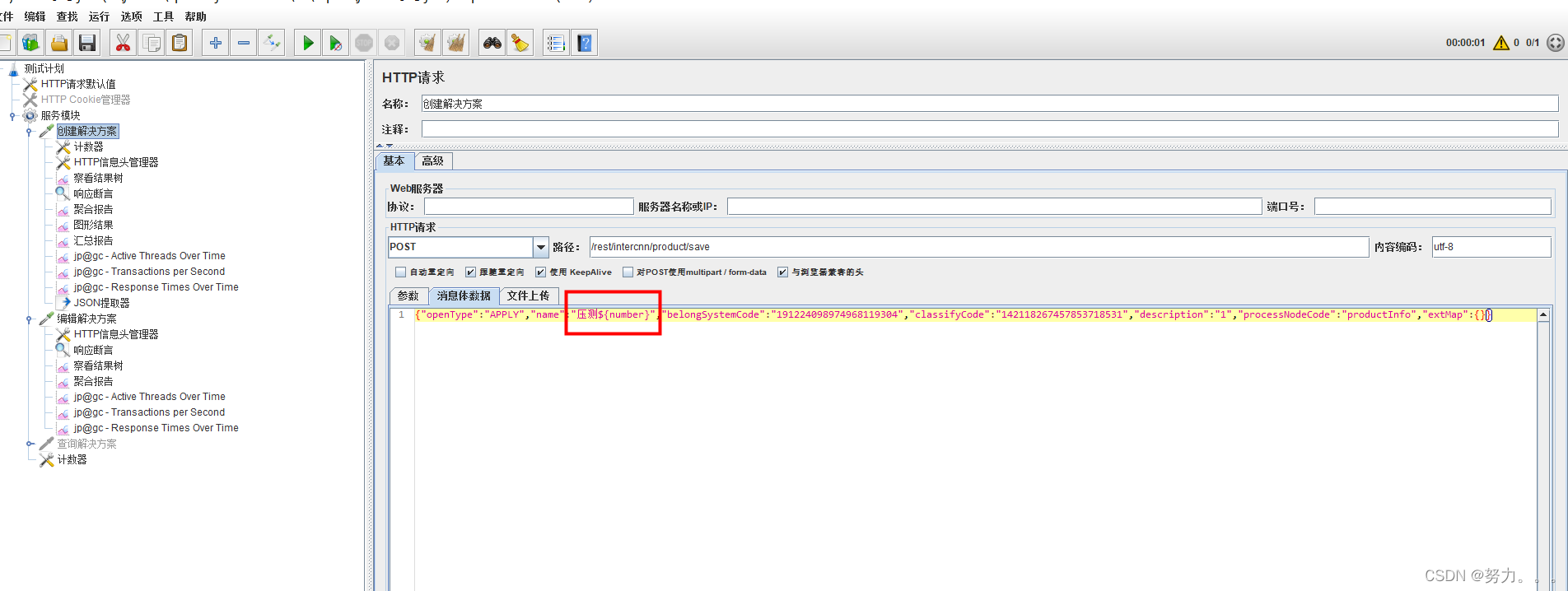
第五步:添加HTTP信息头管理器(右键点击HTTP请求–>添加–>配置元件–>HTTP信息头管理器)
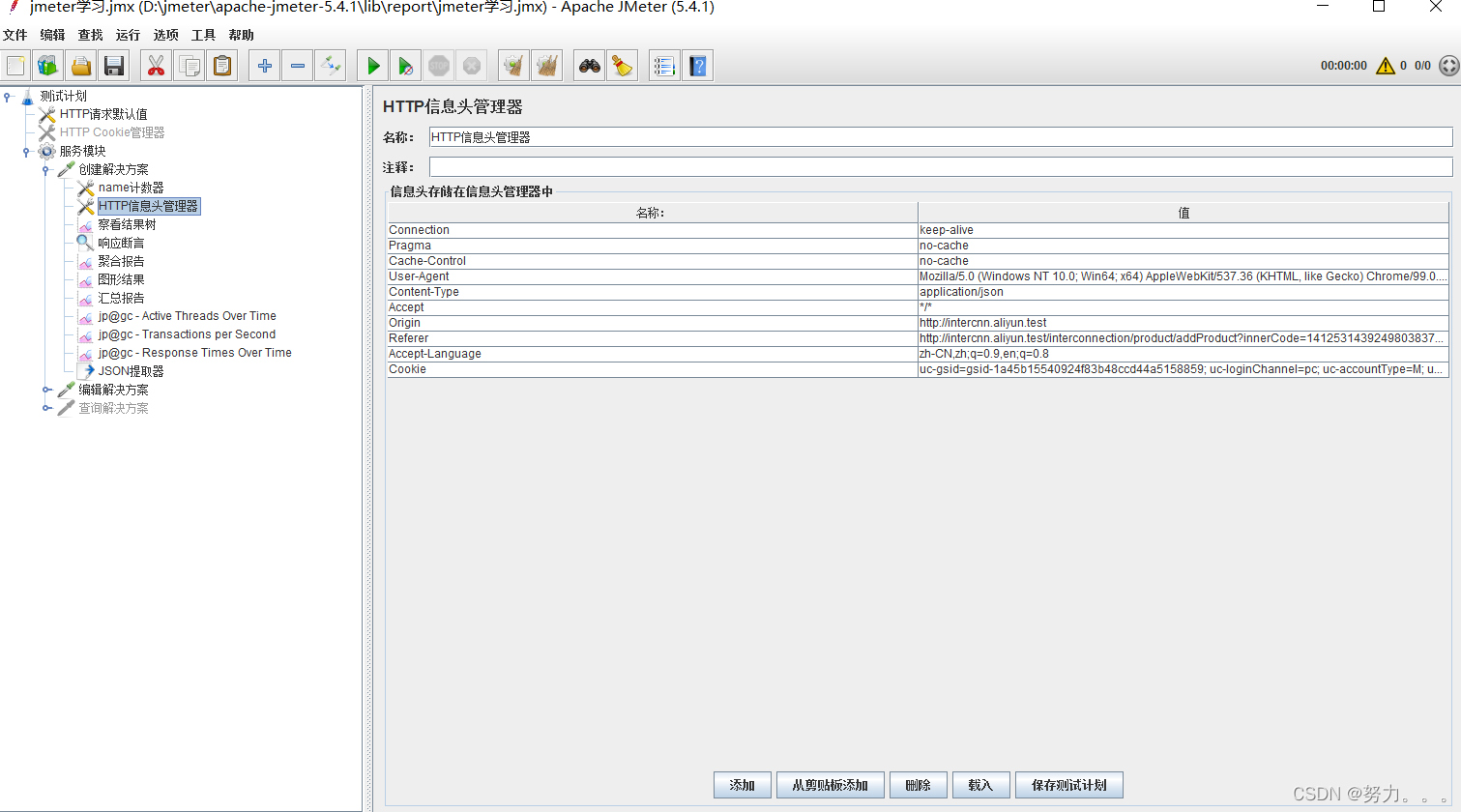
第六步:添加断言(右键点击HTTP请求–>添加–>断言–>响应断言)
常用断言:(包括、匹配、相等、字符串、否、或者)
(1)apply to:通常发出一个请求只触发一个请求,所以勾选“main sampie only”就可以;若发一个请求可以触发多个服务器请求,就有main sample 和sub-sample之分了
(2)响应文本:根据规则返回的结果中有对应的文本值,如:“success”:true
(3)响应代码:相应返回的code码,如:200,404,500等
(4)响应头:响应头信息里面的内容
(5)请求头:请求头里面包含的内容
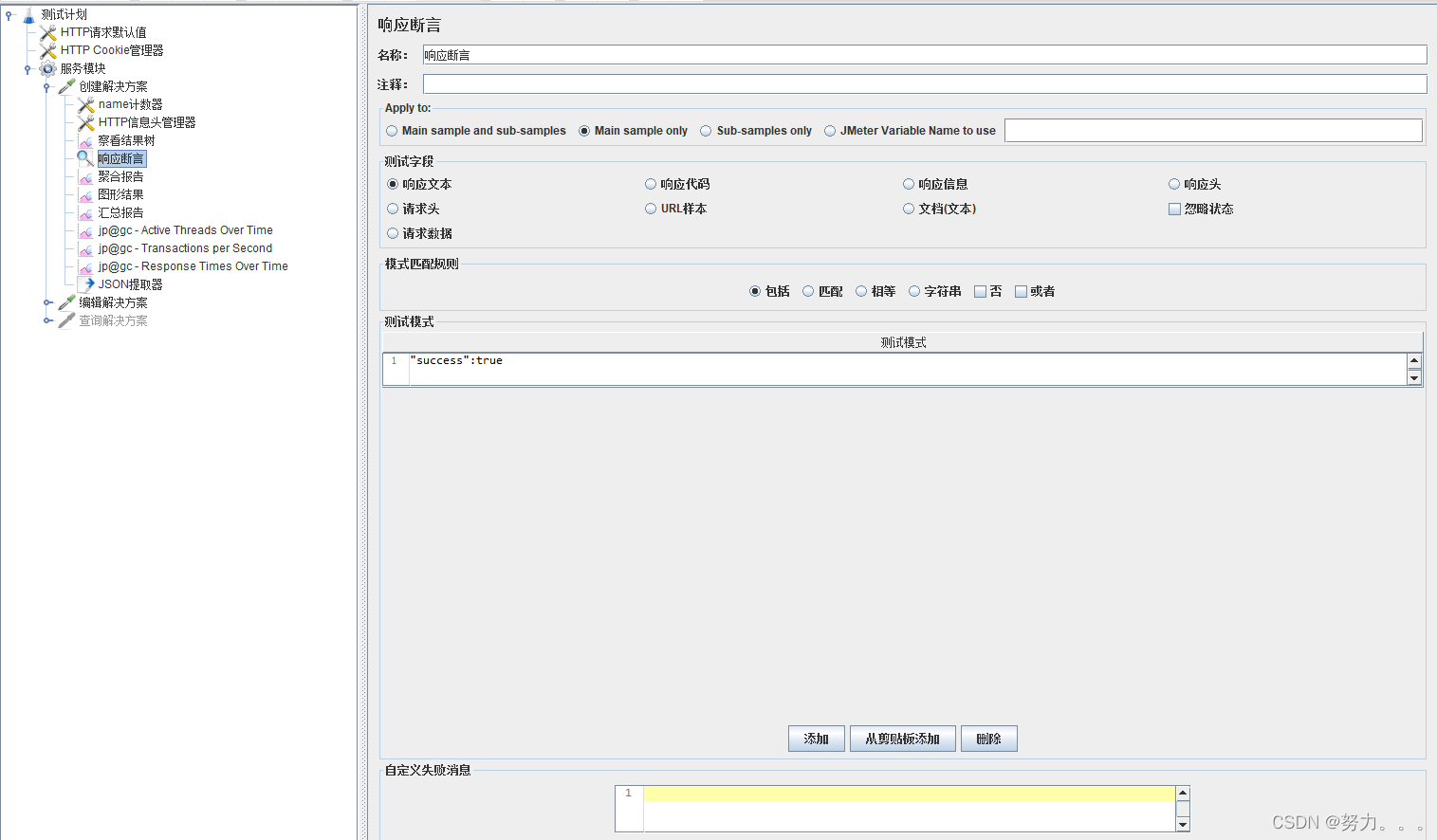
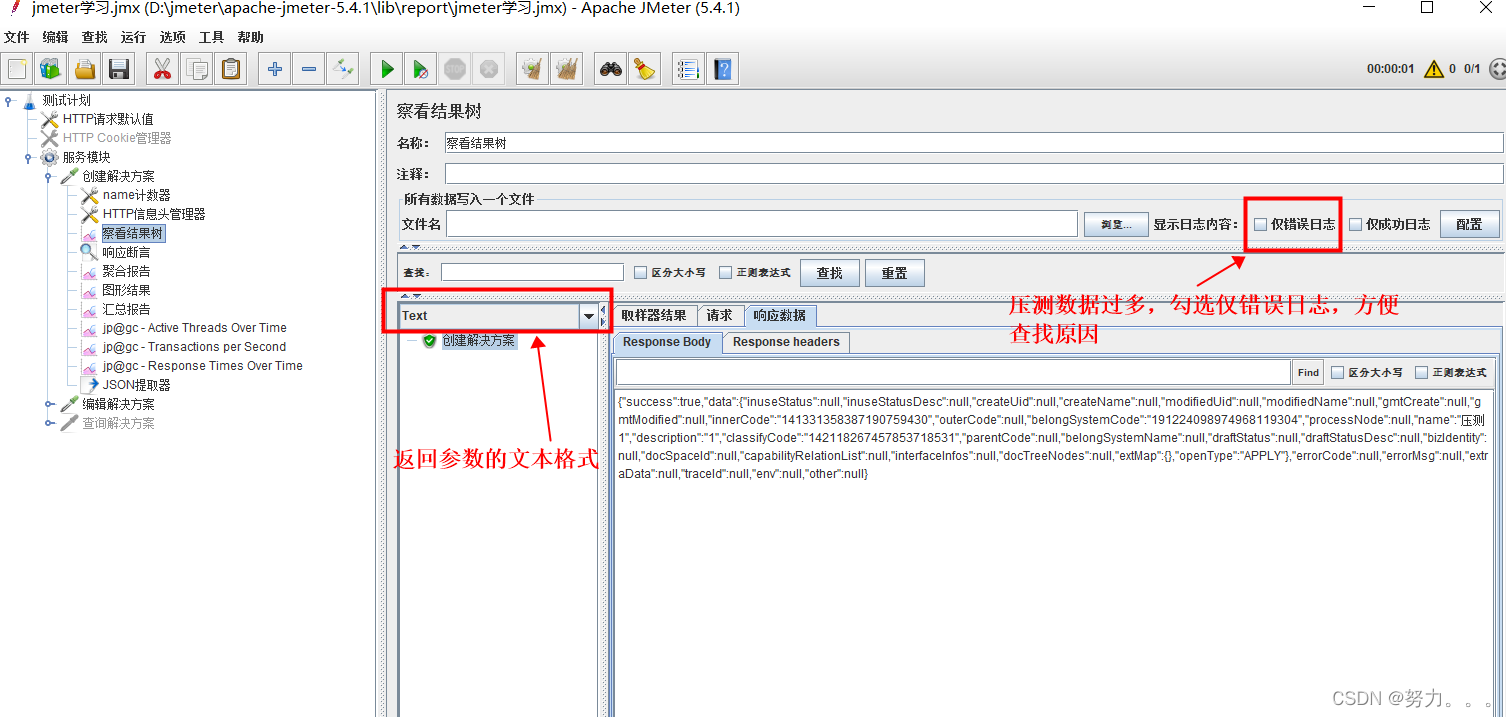
第七步:添加查看结果树(右键点击HTTP请求–>添加–>监听器–>察看结果树)
查看结果树显示所有请求响应的树,通过它可以查看任何请求的响应。除了显示响应之外,还可以查看获取响应所花费的时间以及一些响应代码
第八步:添加聚合报告(右键点击HTTP请求–>添加–>监听器–>聚合报告)
(1)Label:每个请求的名称,eg:HTTP请求
(2)样本(#Samples):请求数——表示在这次测试中一共发了多少个请求
(3)平均值(Average):平均响应时间——单个请求的平均响应时间
(4)中位数(Median):所有请求响应时间的中间值
(5)90%~99%百分位(Line):90%~99%用户的响应时间
(6)最小值(Min):最小响应时间
(7)最大值(Max):最大响应时间
(8)异常(Error)%:错误率——错误请求数/请求总数
(9)吞吐量(Throughput):每秒完成的请求数
(10)接收KB/Sec: 每秒从服务器端接收到的数据量
(11)发送 KB/src:每秒从客户端发送的请求的数量。
一般而言,性能测试中我们需要重点关注的数据有: Samples 请求数,Average 平均响应时间,Min 最小响应时间,Max 最大响应时间,Error% 错误率及Throughput 吞吐量

第九步:添加:jp@gc - Transactions per Second(右键点击HTTP请求–>添加–>监听器–jp@gc - Transactions per Second)
jp@gc - Transactions per Second:监听动态TPS,用来分析吞吐量
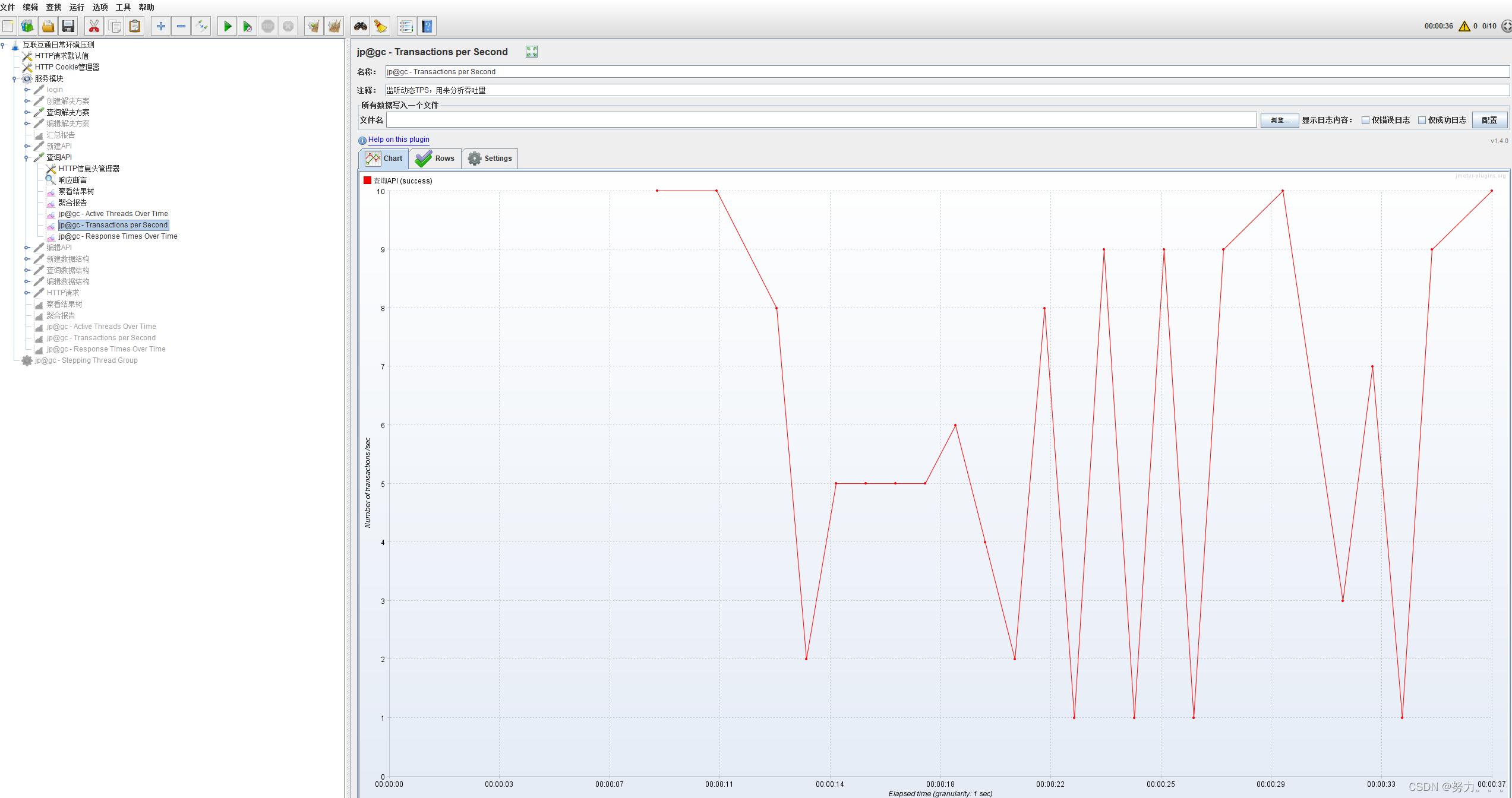
6.JMeter多接口串联的使用
例如压测接口2:编辑解决方案接口压测
需要条件:Cookie、innercode
Cookie有两种方法:
1.Cookie写进接口请求头内
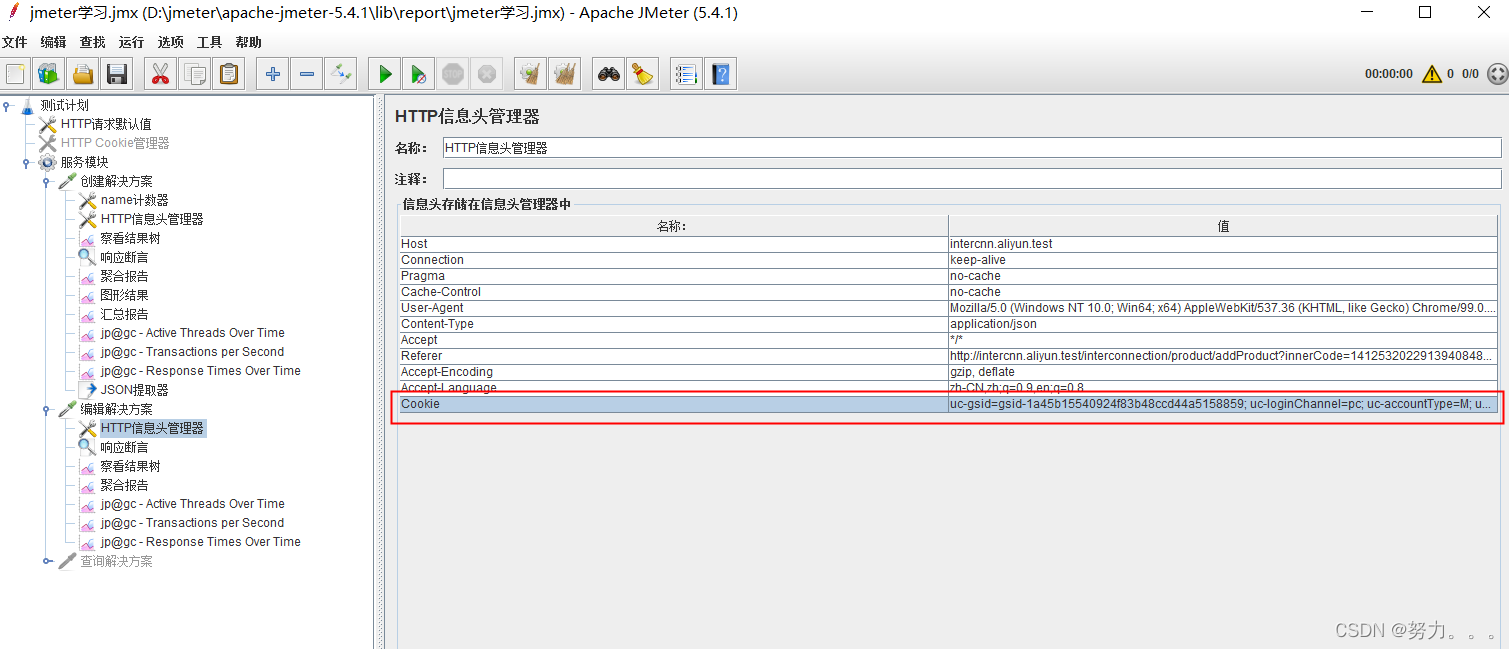
2.使用HTTP Cookie管理器(右键点击测试计划–>添加–>配置元件–>HTTP Cookie管理器)
注意:cookie管理器要放在服务器返回cookie的请求之前,这样后⾯的请求都可以使⽤该cookie
自动获取:如果你有⼀个 HTTP 请求,其返回结果⾥包含⼀个 cookie,那么使⽤ JmeterCookie 管理器会⾃动将该 cookie保存起来,⽽且以后所有对该⽹站的请求都使⽤同⼀个 cookie。每个 JMeter 线程都有⾃⼰独⽴的"cookie 保存区域"。
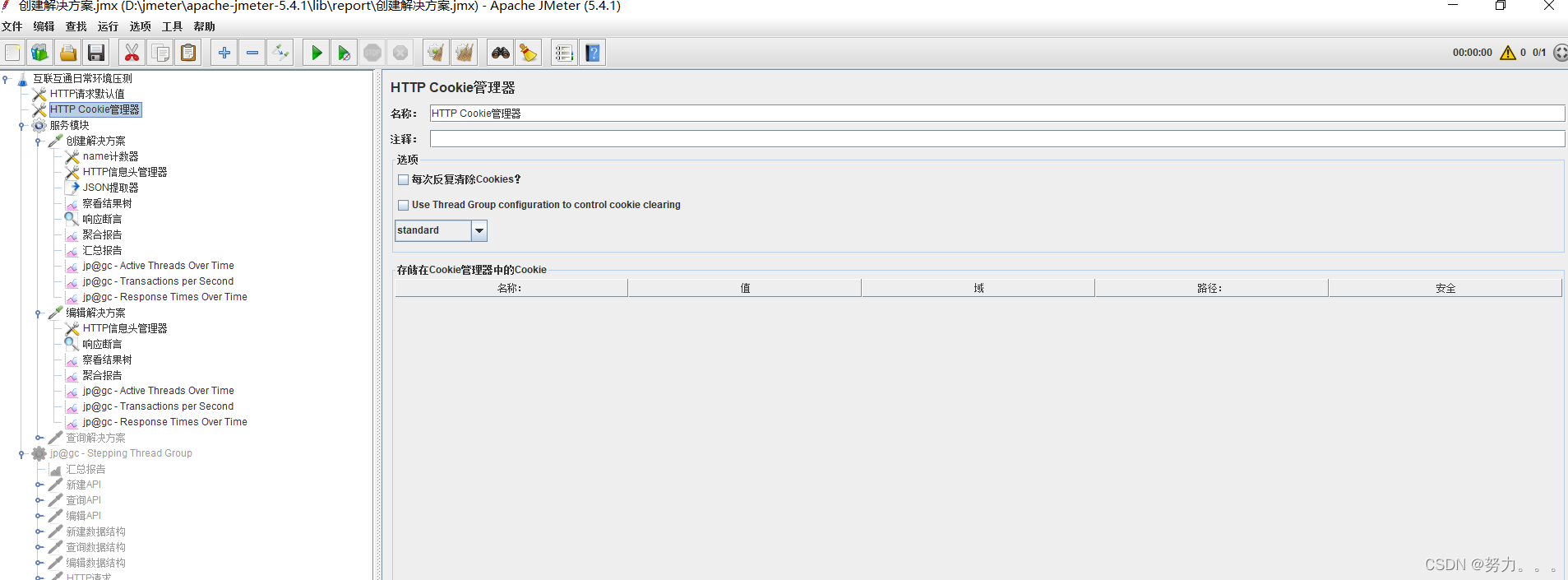
手动添加:有时候需要附件指定cookie,将cookie管理器添加到测试计划中或指定线程组中,点击添加手动添加cookie名、值、域。
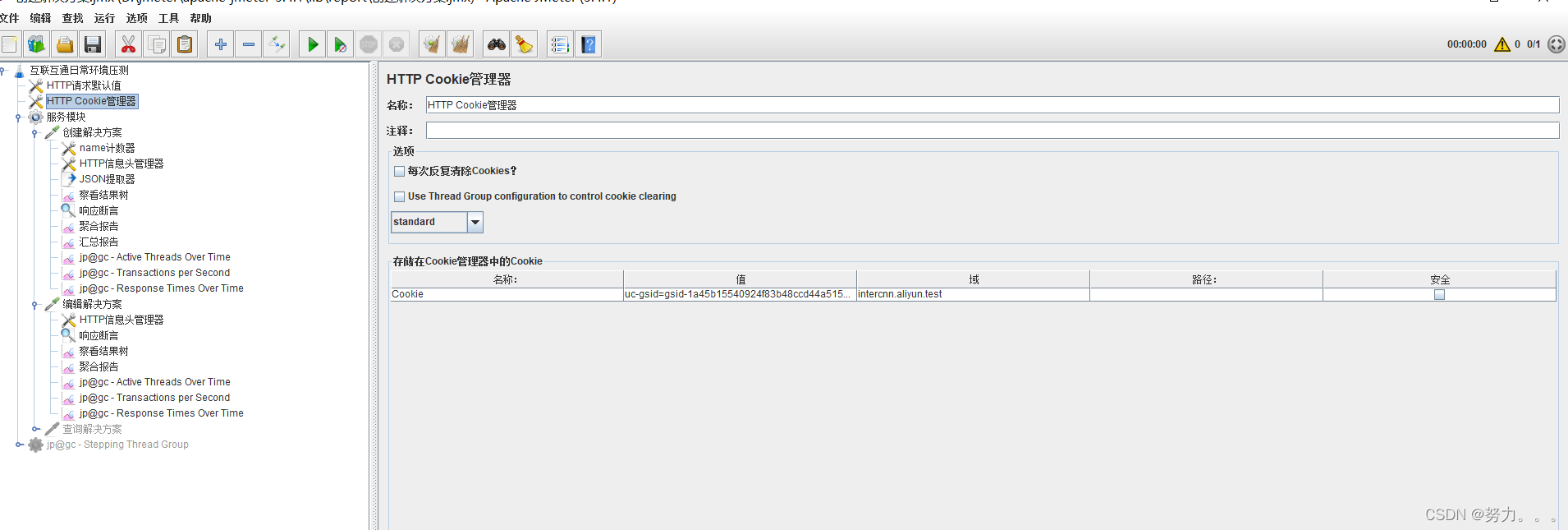
第二步:获取创建解决方案接口的innercode值
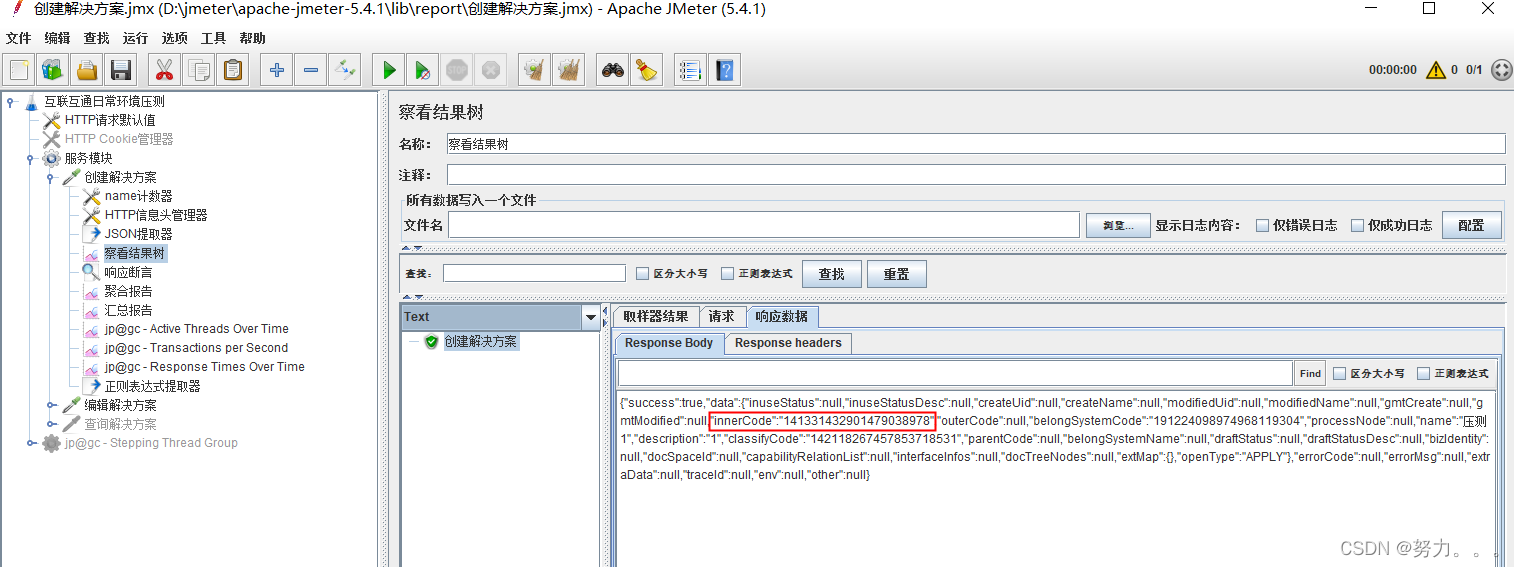
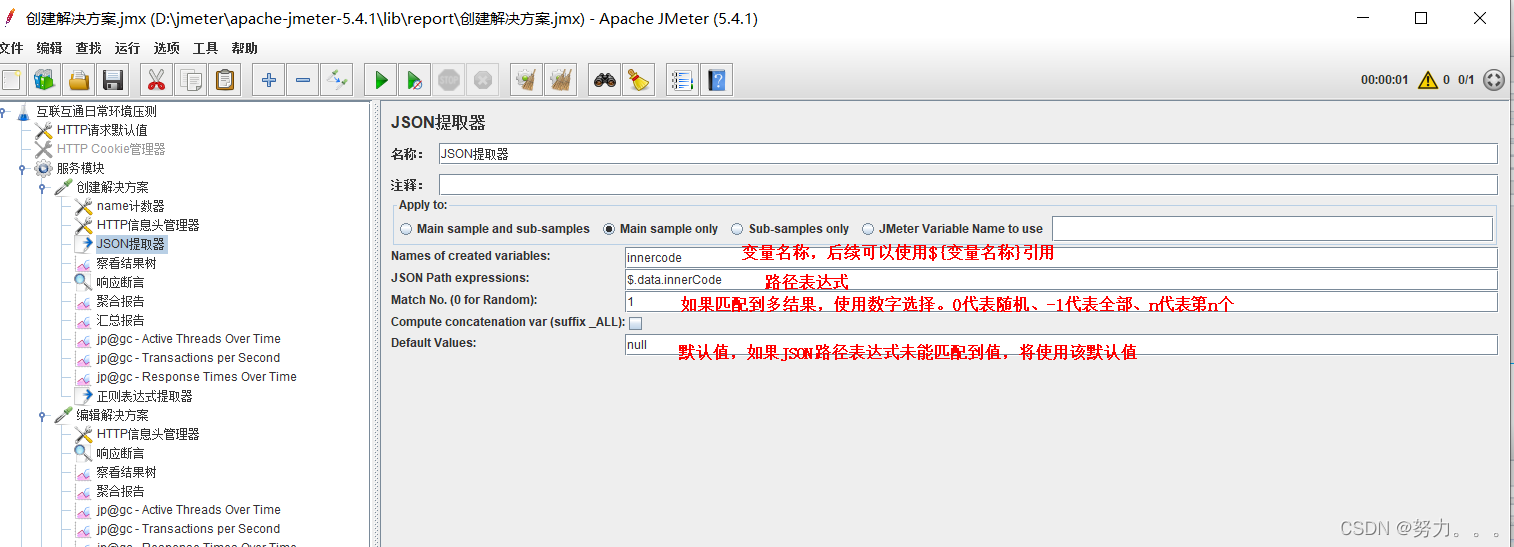
1.使用json提取器(右键点击取样器–>添加–>后置处理器–>Json提取器)
参数详解
2.JSON Path Expressions:JSON路径表达式
4.Compute concatenation var:勾选此项后,如果匹配到多个结果,JMeter会使用","将他们连接起来,存储在的变量中
5.Default Values:默认值,如果JSON 路径表达式未能匹配到值,将使用该默认值
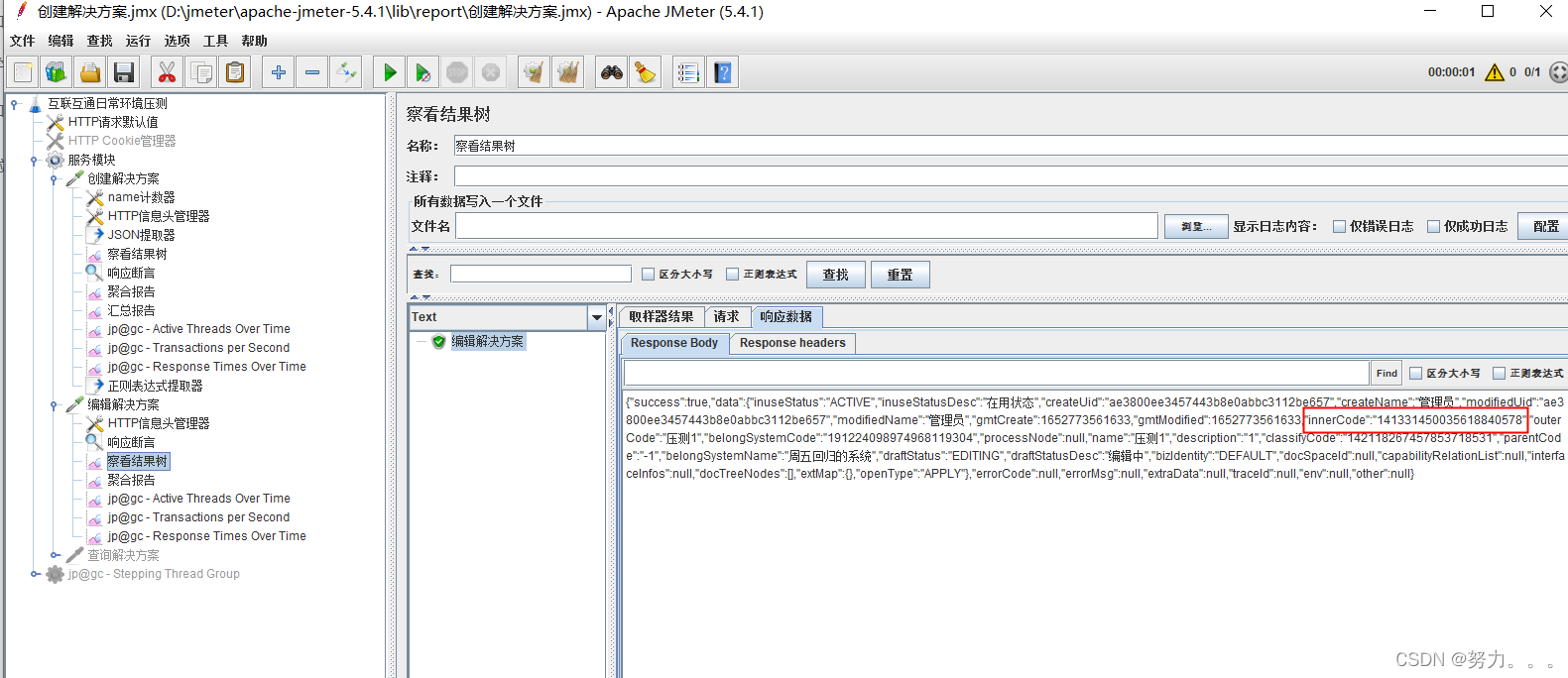
编辑解决方案接口引用JSON提取器提取的值:“innerCode”: “141331450035618840578”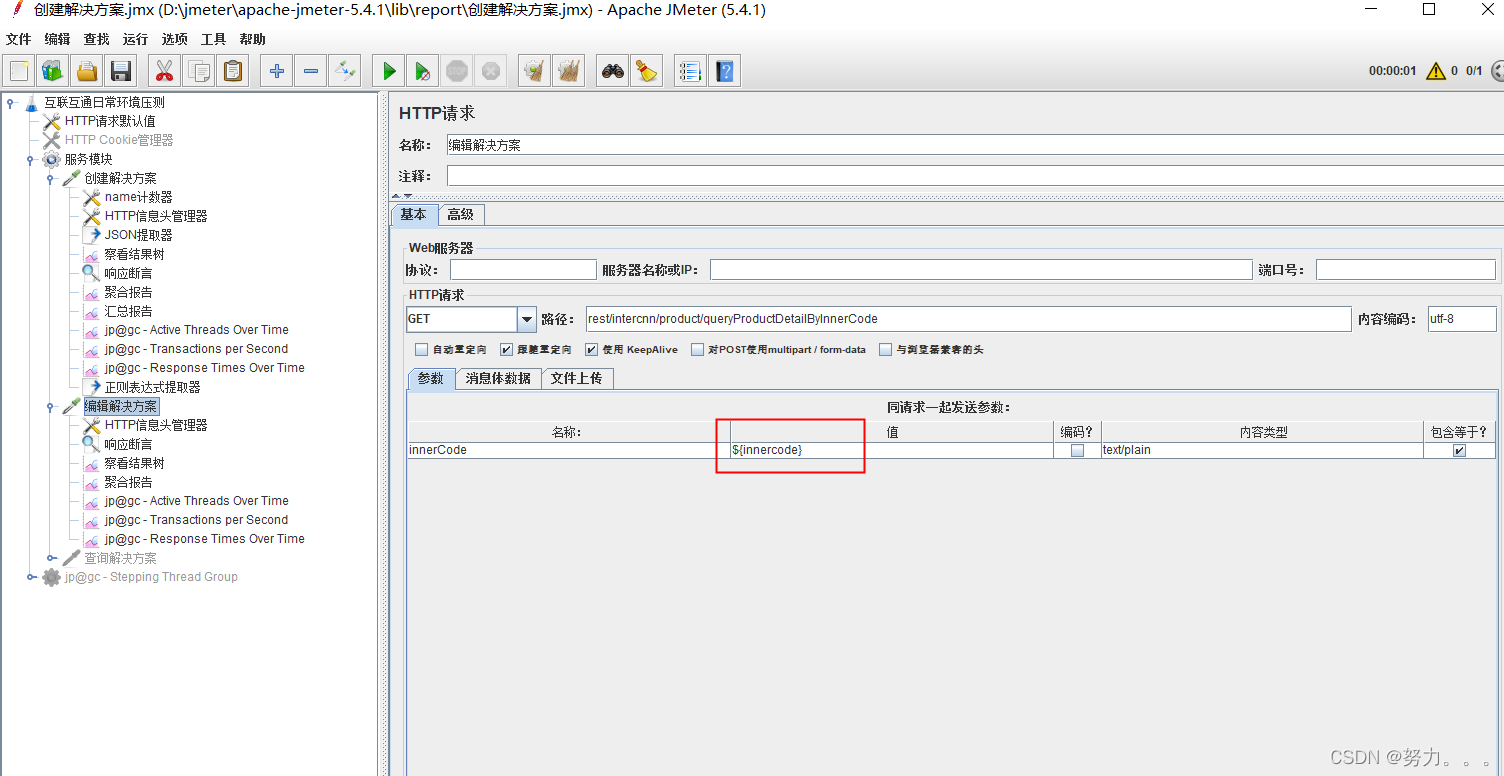
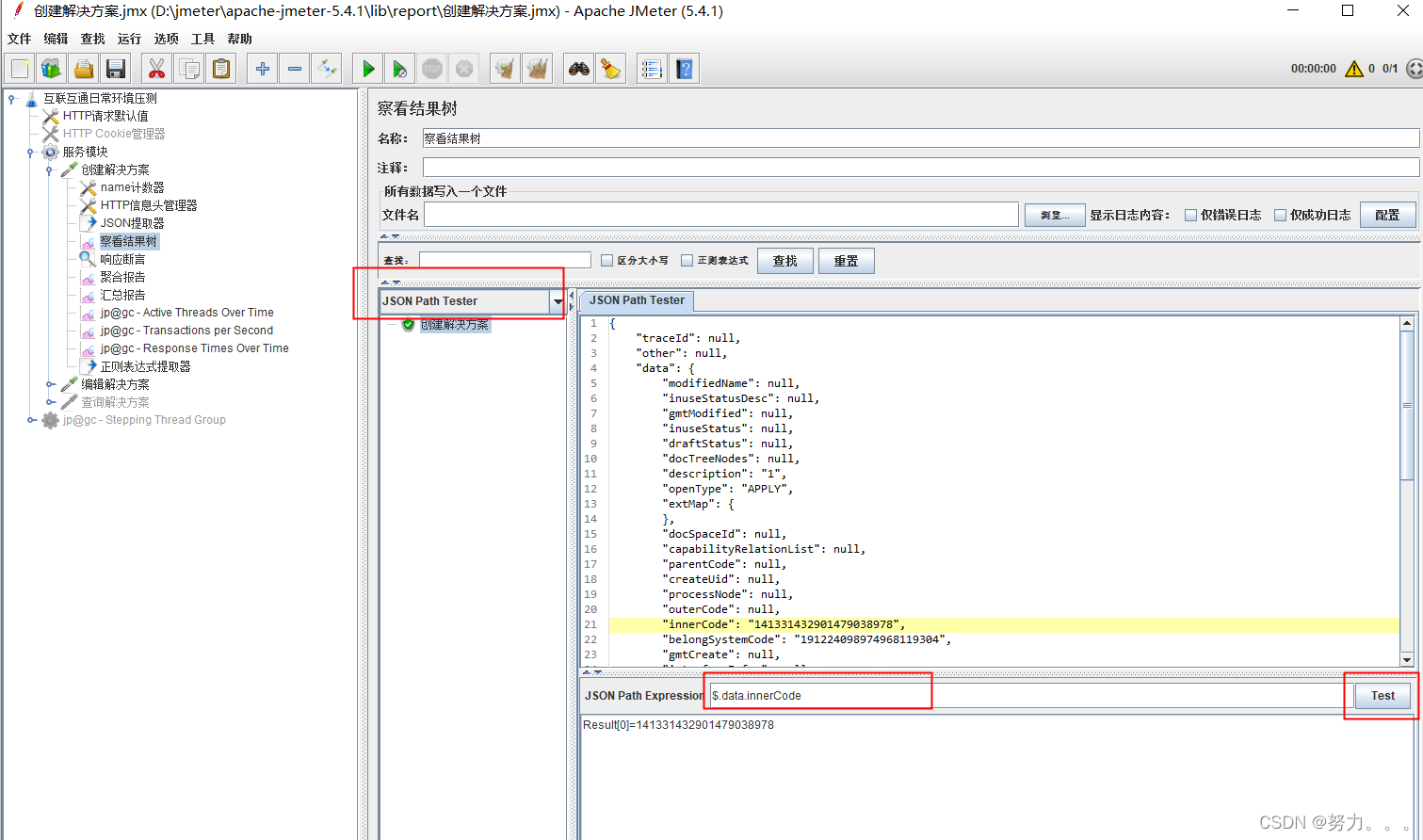
注意1:不确定Json表达式是否正确的情况下,可以在查看结果集中进⾏调试,如下,切换JSON Path Tester,在表达式输⼊框中输⼊json提取表达式($.data.innerCode),点击test,下⽅显⽰提取的结果
注意2:如果是下⼀个请求需要关联上⼀个请求的多个字段,那么可以添加多个提取器,但是jmeter也⽀持⼀个提取器提取多个字段的值,只需要原来变量的地⽅填写多个,中间⽤分号隔开即可例如: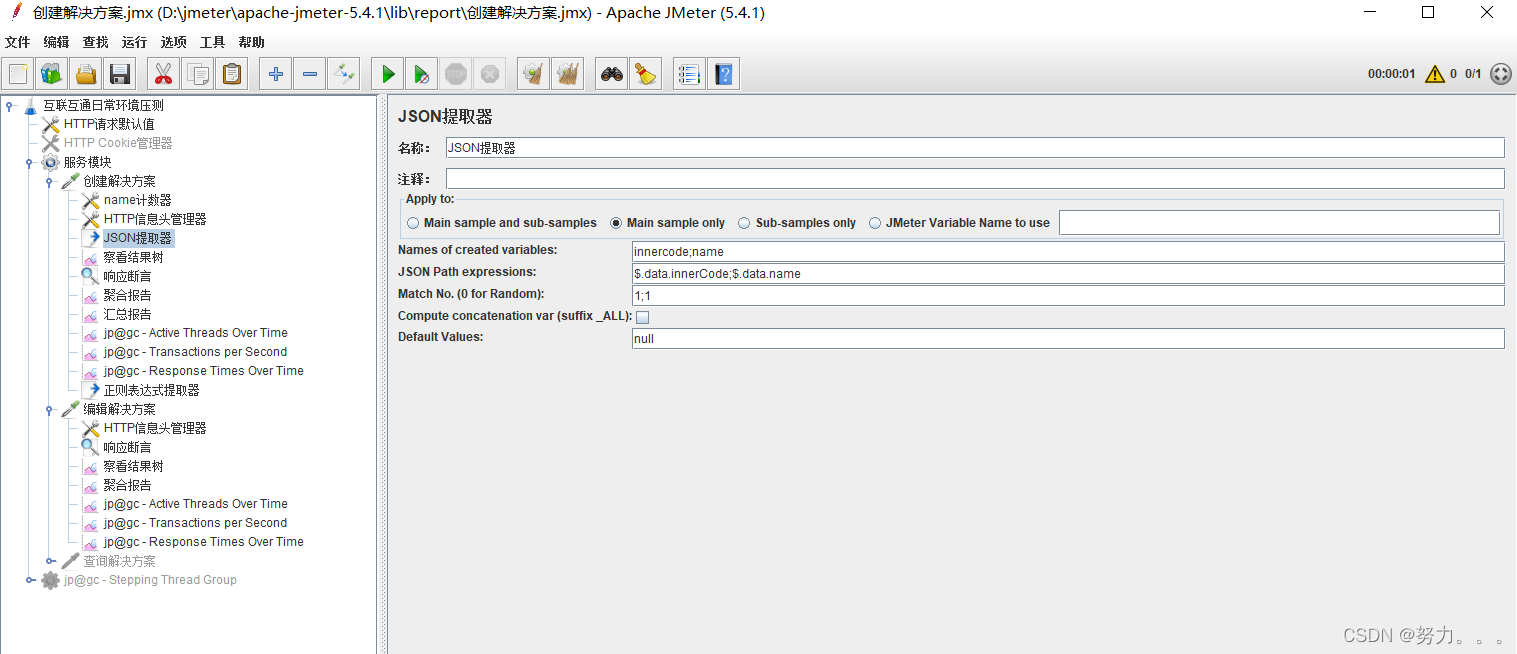
编辑解决方案的运行结果:
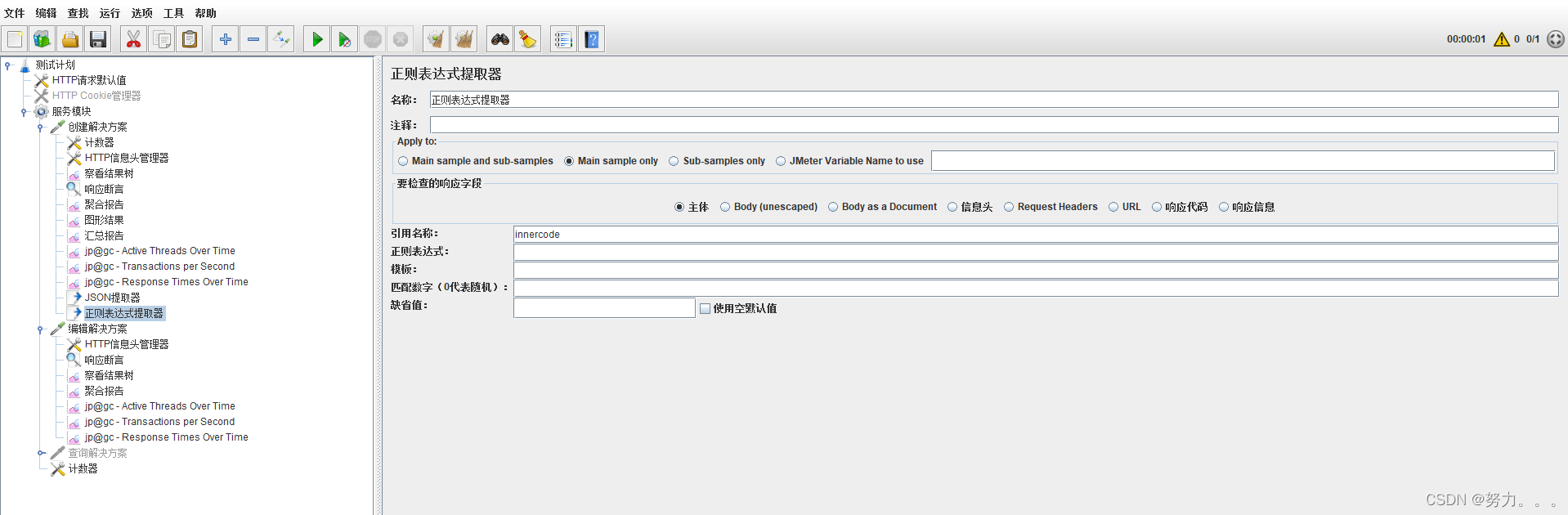
2.正则表达式
参数解释
(1)要检查的响应字段:相当于是要提取哪个位置的内容数据
(2)引用名称:我们把内容提取出来后要赋值给一个变量,这个变量在jmeter里就是应用名称,注意这里不能出现数字和一些乱七八糟的特殊符号,建议使用英文
(3)正则表达式:提取内容的正则表达式【稍注意一下:()表示提取,对于你要提前的内容需要用小括号括起来】
(4)模板:用$$引用起来,如果在正则表达式中有多个提取表达式(多个括号括起来的东东),则可以是
1
1
1,
2
2
2等等,表示解析到的第几个值给str,正则表达式的提取模式,值从1开始
(5)匹配数字:0代表随机,-1代表所有,其余正整数代表将在已提取的内容中,第几个匹配的内容。
(6)缺省值:正则匹配失败时,取的值
():括起来的部分就是要提取的。
.:匹配任何字符串。
*: 匹配(*之前的符号)0次或多次。
+:一次或多次。
?:不要太贪婪,在找到第一个匹配项后停止。
例如:response的返回,可以看到有三个packageId
{
“code”: 0,
“data”: {
“serviceInfos”: [
{
“packageId”: “1676176670240829445”,
“packageType”: “0”,
},
{
“packageId”: “1674316942942433281”,
“packageType”: “1”,
},
{
“packageId”: “1674317078124851204”,
“packageType”: “13”,
}
],
}
获取第一个packageId:1676176670240829445
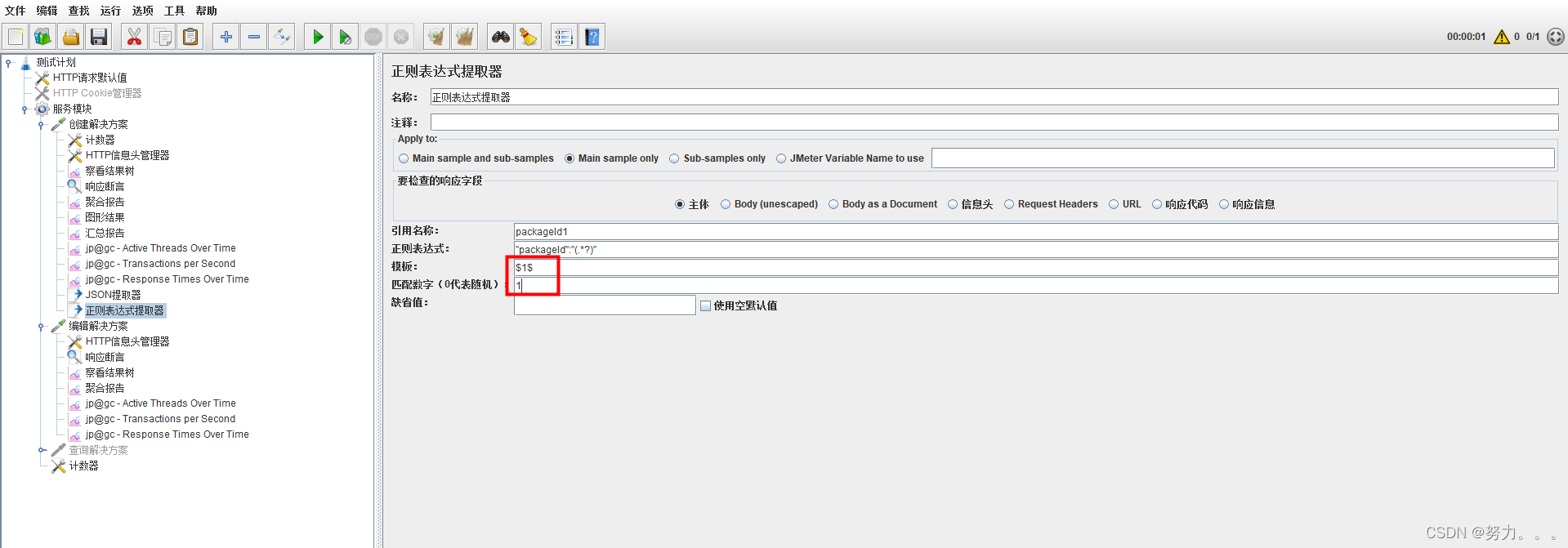
获取第一个packageId完整信息:“packageId”:“1676176670240829445”
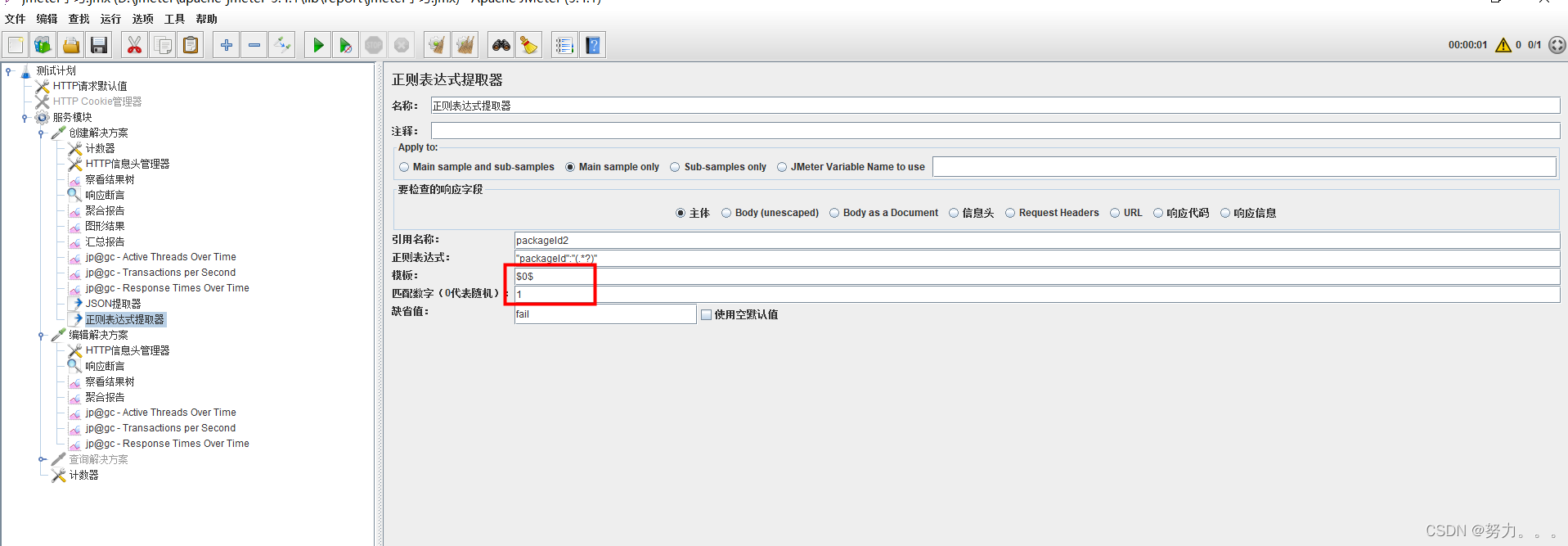
获取第2个packageId:1674316942942433281
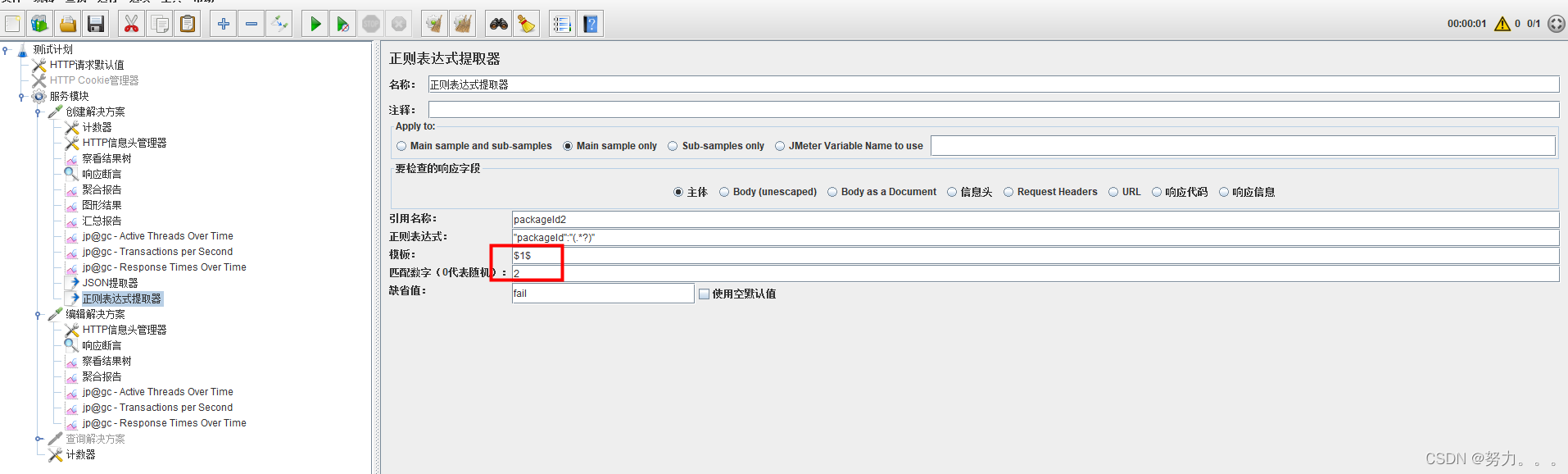
获取所有packageId
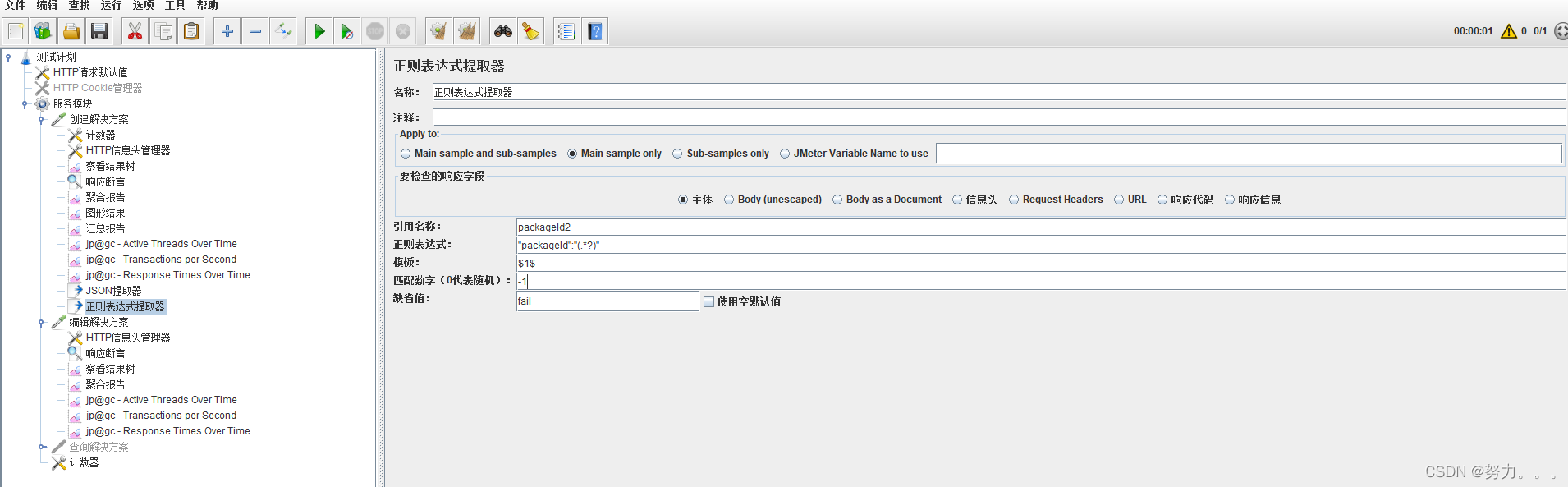
正则的贪婪模式和非贪婪模式
贪婪模式与非贪婪模式是两种不同的表达式匹配行为,贪婪模式再整个表达式匹配成功的前提下尽可能多的匹配,而非贪婪模式在整个表达式匹配成功的前提下,尽可能的少匹配。
例如:
{
“code”:“0”,
“msg”:“请求成功”,
“bizSeqNo”:“12345678ab9”,
“result”:{
“bizSeqNo”:“ab87654321”,
“traceID”:“111222333”
}
}
贪婪模式
表达式:“bizSeqNo”
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

