
- 1基于MATLAB麻雀搜索算法求解物流选址问题_麻雀搜索算法选址
- 2Nginx学习笔记(十)如何配置HTTPS协议?(公网)
- 3Git(三) Git 的远程仓库操作(以码云为例)_码云远程仓库怎么
- 4YOLOv8-目标检测实战,训练自己的数据集(提供数据集)_yolov8目标检测自己的视频数据
- 5大数据计算模式:批处理&流处理_流计算 批处理
- 6JNI 输出LOG_jni log
- 72023首届大学生算法大赛——补题_算法大赛cff 第一届 赛题
- 8Anaconda Jupyter notebook 安装过程详解_jupyter notebook安装conda弹出窗口是怎么回事
- 9微信小程序django+uniapp学生宿舍门禁系统python
- 10经典卷积模型回顾20—YOLOv1实现猫狗检测(matlab,Tensorflow2.0)_yolov1用matlab
hive一次加载多个文件_Hive总结
赞
踩
Hive总结
一、Hive架构
1.架构图
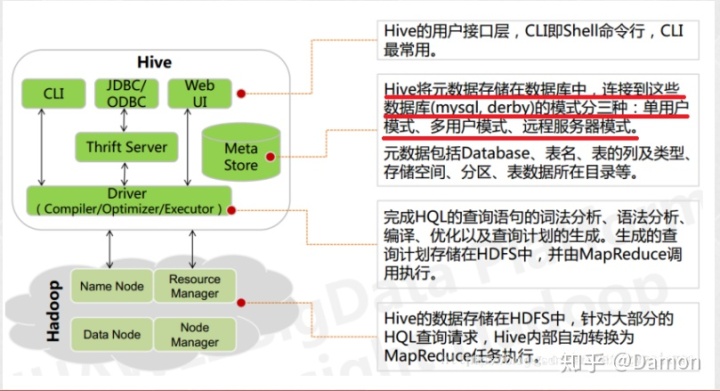
2.Hive架构解析
1)用户接口
CLI:cli即shell命令。CLI最常用CLI启动的时候会同时启动 一个Hive 副本
Client: Client是Hive的客户端,用户连接HiveServer,并指出Hive Server 所在的节点以及在该节点启动它
WUI:WUI是通过浏览器启动Hive
2)元数据
Hive将元数据存储在数据库中,如mysql、derby。Hive的元数据信息包 括,表的名字、表的列、分区机器及其属性、表的属性、表的目录等
3)Driver
解释器、编译器、优化器完成HQL的查询语句从词法分析、语法分析、 编译、优化以及查询计划的生成。生成的计划存储在HDFS中,并在MR 中调用执行,Hive的数据存储在HDFS中,大部分的查询计算由MR完成
4)注意事项
Hive会不会转换为MR取决于是否用了聚合函数
二、Hive数据倾斜问题优化
1.现象
当Hive放生数据倾斜的时候,我们在使用HQL运行mr的时候可以发现,map是100%,而reduce卡在99%
2.当Hive发生数据倾斜的时候我应该怎么办呢?
第一种方案,数据倾斜五分就是key的数据量非常不均匀,我们可以开启map聚合的参数(hive.map.aggr=ture),开启之后会把数据现在map端进行聚合,当reduce端聚合的时候就只需要聚合map端聚合完的参数就可以了
第二种是当大表和小表进行JOIN的时候,也可能导致数据倾斜。为了解决这个问题,考虑使用到mapjoin,mapjoin会把小表全部读入内存中,在map阶段直接拿另外一个表的数据和在内存中表的数据进行匹配,由于mapjion是在map端进行了join操作,省去了reduce的运行,所以效率会快很多
第三种是当大表和大表join的时候发生数据倾斜,具体操作室建立一个numbers表,其值只有一列int 行,比如从1到10(具体值可根据倾斜程度确定),然后放大B表10倍,再取模join
三、分区
1.Hive静态分区
就是在不开启动态分区的条件下都是静态分区,使用方式就是HQL
2. Hive动态分区
1)参数设置
· 开启动态分区
启用动态分区功能 hive> set hive.exec.dynamic.partition=true;
注:hive2.x该参数默认为true,1.x为false
· 模式设置(严选模式/非严选模式)
设置这个参数为nostrict
hive> set hive.exec.dynimac.partiton.mode=nostrict
默认情况下是strict
2)动态分区的相关参数
hive.exec.max.dynimac.partition.pernode 这个参数表示每个mr执行的节点上,能创建的最大分区数量(默认100)
hive.exec.max.dynimac.partition 这个参数表示所有mr执行的节点上,能创建的最大分区数量(默认1000)
hive.exec.max.creat.files 这个参数代表所有mr job能创建文件的最大数量
3)动态分区加载数据的方法
第一步:创建原数据表
第二部:load data加载数据到原数据表
第三部:使用from into table inset into table select 。。。。加载数据
4)静态分区与动态分区的区别
静态分区是手动指定分区的,动态分区是根据数据来判断
5)静态分区结合动态分区使用
动静结合使用的话,静态分区值必须在动态分区值的前面
四、Hive SQL
1.外部表和内部表
区别在于删除的时候只删除元数据,而内部表删除的时候连数据都给删除了
2.Hive DDL
定义:Hive的数据定义语言 (LanguageManual DDL)
1)建表语句
· 创建普通的表: create table abc( id int ) row format delimited fields terminated by ',' stored as textFile
· 创建带有分区的表:create table abc( id int ) partitioned by (dt String) row format delimited fields terminated by ','
· 创建外表:create external table abc( id int ) row format delimited fields terminated by ',' location'/home/hive/text.text';
3.Hive DML
定义:Hive数据操作语言(LanguageManual DML)
1)操作语句
HDFS上导入数据:load data inpath 'filePath' into table table_name;
· 从别的表中导入:insert into table table_name1 [patition(dt '.....', value)] select id,name from table_name2
· 多重数据插入:from table_name1 t1,table_name2 t2 insert overwrite table table_name3 [patition(col1=val1,col2=val2)] select t1.id, t2.id, .....................;
五、Hive优化
1.优化一:本地模式
· 开启本地模式 hive> set hive.exec.mode.local.auto=true
· 需要注意的是:hive.exec.mode.local.auto.inputbytes.max 这个参数默认 是128M,这个值表示了当加载文件的值大于这个值的时候,该配置仍 会以集 群来运行;默认就是集群运行的;当项目上线的时候开启; 使 用本地模式 的话,小数据小表可以避免提交时间的延迟
2.优化二:并行计算
· 开启并行计算 hive> set hive.exec.parallel=true
· 相关参数 hive.exec.parallel.thread.number(一次sql计算中允许并执行的 job 数量)
· 需要注意的是,并行计算会加大集群的压力
3.优化三:严格模式
· 开启严格模式 hive> set hive.mapred.mode = strict
· 主要是防止一群sql查询将集群压力大大增加
· 同时它也有一些限制:1、对于分区表,必须添加where对于分区字段的 条件过滤 1、orderby语句必须包含limit输出限制 3、限制执行笛卡尔积 查询
4.优化四:排序
· order by 对于查询结果做全排序,只允许有一个reduce处理
· 需要注意的是:当数据过大的时候谨慎使用,在严选模式下需要结合limit 来使用
· sort by 是对单个reduce的数据进行排序
· 只会在每个reducer 中对数据进行排序,也就是执行局部排序过程,只 能保证每个reducer的输出数据都是有序的(但并非全局有序)
· distribut by 是分区排序经常结合sort by一起使用
· cluster by 相当于distribut br + sort by
· cluster by 默认是倒序排序,不能用asc和desc来指定排序规则;可以通 过distribute by clumn sort by clumn asc|desc方式来指定排序方式
5.优化五:JOIN
· join时将小表放在join的左边
· mapjoin:在map端进行join(可以省略shuffle和reduce提高性能)
1)实现方式1:mapJoin标记
sql方式,在sql语句中添加mapjoin标记(mapjoin hint) select /*+mapjoin(smalltable)*/smalltable.key ,bigTable.value from smallTable join bigTable on smallTable.key=bigTable.key
2)实现方式2:开启自动的mapjoin
参数配置: 自动对小表进行mapjoin
hive> set hive.auto.convert.join=true
相关参数
· hive.mapjoin.smalltable.filesize这个值是大表和小表的判定阀值,小于这 个值就会被放入内存
· hive.ignore.mapjoin.hint 默认为true,是够忽略mapjoin hint
· hive.aotu.caonvert.join.noconditionaltask 默认为true,将普通的join转 换为mapjoin的时候是否将多个mapjoin转为一个mapjoin
· hive.aotu.caonvert.join.noconditionaltask.size 将多个mapjoin转为一个 mapjoin的最大值
6.优化六:聚合
开启map聚合 hive> set hive.map.aggr=true
相关参数
· hive.groupby.mapaggr.checkinterval: map端group by执行聚合时处理的多少行数据(默认:100000)
· hive.map.aggr.hash.min.reduction: 进行聚合的最小比例(预先对100000条数据做聚合,若聚合之后的数据量 /100000的值大于该配置0.5,则不会聚合)
· hive.map.aggr.hash.percentmemory:map端聚合使用的内存的最大值
· hive.map.aggr.hash.force.flush.memory.threshold: map端做聚合操作是hash表的最大可用内容,大于该值则会触发flush
· hive.groupby.skewindata :是否对GroupBy产生的数据倾斜做优化,默认为false
7.优化七:控制Hive中map和reduce的数量
Map数量相关的参数
· mapred.max.split.size:一个split的最大值,即每个map处理文件的最大值
· mapred.min.split.size.per.node:一个节点上split的最小值
· mapred.min.split.size.per.rack:一个机架上split的最小值
Reduce数量相关的参数
· mapred.reduce.tasks: 强制指定reduce任务的数量
· hive.exec.reducers.bytes.per.reducer 每个reduce任务处理的数据量
· hive.exec.reducers.max 每个任务最大的reduce数 [Map数量 >= Reduce数量 ]
8.优化八:JVM的重用
适用场景: 1、小文件个数过多 2、task个数过多
· 通过 set mapred.job.reuse.jvm.num.tasks=n; 来设置(n为task插槽个数)
缺点:设置开启之后,task插槽会一直占用资源,不论是否有task运行,直 到所有的task即整个job全部执行完成时,才会释放所有的task插槽资源!
六、Hive函数
1.函数自定义
1)UDF (常用) 一进一出
http://blog.csdn.net/duan19056/article/details/17917253
<1>UDF 函数可以直接应用于 select 语句,对查询结构做格式化处理后,再 输出内容。
<2>编写 UDF 函数的时候需要注意一下几点:
a)自定义 UDF 需要继承 org.apache.hadoop.hive.ql.UDF。
b)需要实现 evaluate 函数,evaluate 函数支持重载。
<3>步骤
a)把程序打包放到目标机器上去;
b)进入 hive 客户端,添加 jar 包:hive>add jar /jar/udf_test.jar;(清除缓存 时记得删除jar包delete jar /*)
c)创建临时函数:hive>CREATE TEMPORARY FUNCTION add_example AS 'hive.udf.Add';
d)查询 HQL 语句:
SELECT add_example(8, 9) FROM scores;
SELECT add_example(scores.math, scores.art) FROM scores;
SELECT add_example(6, 7, 8, 6.8) FROM scores;
e)销毁临时函数:hive> DROP TEMPORARY FUNCTION add_example;
2)UDAF聚集函数,多进一出
多行进一行出,如 sum()、min(),用在 group by 时
<1>必须继承org.apache.hadoop.hive.ql.exec.UDAF(函数类继承)
org.apache.hadoop.hive.ql.exec.UDAFEvaluator(内部类 Eval uator 实现 UDAFEvaluator 接口)
<2>Evaluator 需要实现 init、iterate、terminatePartial、merge、t erminate 这 几个函数
· init():类似于构造函数,用于 UDAF 的初始化
· iterate():接收传入的参数,并进行内部的轮转,返回 boolean
· terminatePartial():无参数,其为 iterate 函数轮转结束后,返回轮转数据, 类似于 hadoop 的 Combinermerge():接收 terminatePartial 的返回结果, 进行数据 merge 操作,其返回类型为 boolean
·terminate():返回最终的聚集函数结果
3)UDTF,一进多出
一进多出,如 lateralview explore()
使用方式 :在HIVE会话中add自定义函数的jar 文件,然后创建 function 继 而使用函数; 这些函数都是针对单元格值的,并不是针对行的。
七、Hive数据储存
Hive没有专门的存储结构,数据表,视图,元数据等等都可以;而且也没有专门的数据存储格式,textFile、RCFile都可以的;
Hive只需要在创建表的时候告诉Hive数据中的列分隔符和行分隔符,Hive就可以解析数据。
那么分割符都有那些呢,默认的话是列分隔符“ctrl+A”
默认行分隔符是“/n”
八、Hive表
1.Hive表常用的存储格式
textfile 默认格式 行存储
sequencefile 二进制文件 行存储
rcfile 按行分块 按列存储
orc 按行分块 按列存储
2.Hive索引(了解)
一个表上创建索引创建一个索引使用给定的列表的列作为键
3.Hive工作原理
首先用户先将任务交给Diver
接着编译器获得这个用户的plan,并根据这个用户的任务去metaStore获取需要的Hive元数据信息
然后进行对任务的编译,将HQL先后转换为抽象语法树、查询块、逻辑计划、最后转为物理计划(mapreduce),最终选择最优方案提交给Diver
Diver将这个最优方案转交给excutionengion执行,将获得的元数据信息交给jobTracker或者sourceManager执行该任务
最终这个任务会直接读取HDFS中的文件进行操作,取得并返回结果

