
热门标签
热门文章
- 1VIT模型个人笔记
- 2[已解决]Macbook/MacMini M1/M2版读写NTFS格式磁盘软件_mac m1 ntfs
- 3app安全评估报告,如何搞定呢?!_软件安全评估报告
- 4【NLP】transformer学习_黑马 transformer
- 5Postman基础功能-变量设置与使用_postman设置变量以及引用
- 6Dive into Deep Learning-优化算法(2)_dive into deeplearning
- 7Linux系统使用(超详细)_linux系统怎么用
- 8分享几个国内免费使用的 gpt 网站_免费gpt网站
- 9数据结构题目收录(十九)_平衡二叉树怎么得到降序序列
- 10Python基础入门自学——10_def init(self, output: callable = print) -> bool:
当前位置: article > 正文
spark-算子-分区算子partitionBy、coalesce、repartition_spark分区算子
作者:笔触狂放9 | 2024-06-16 17:19:46
赞
踩
spark分区算子
一、partitionBy

val inputRDD = sc.parallelize(Array[(Int,Char)] ((1, 'a'),(2,'b'),(3,'C') (4,'d'),(2,'e'),(3,'f'),(2,'g'),(1, 'h')),3)
val resultRDD = inputRDD.partitionBy(new HashPartitioner (2))//使用HashPartitioner重新分区
val resultRDD = inputRDD.partitionBy(new RangePartitioner(2,inputRDD))//使用RangePartitioner重新分区
- 1
- 2
- 3
- 4
同repartition区别,partitionBy是根据partitioner,而repartition是随机策略,不能指定partitioner
二、coalesce
用来改变分区数,根据随机生成的key,使用随机策略均匀的分布数据,只能传入分区数,不能指定partitioner
val sc = new SparkContext()
val inputRDD = sc.parallelize(Array[(Int, Char)]((3, 'c'), (3, 'f'), (1, 'a'), (4, 'd'), (1, 'h'), (2, 'b'), (5, 'e'), (2, 'g')), 5)
var coalesceRDD = inputRDD.coalesce(2) //图3.19中的第1个图
coalesceRDD = inputRDD.coalesce(6) //图3.19中的第2个图
coalesceRDD = inputRDD.coalesce(2, true) // 图3.19中的第3个图
coalesceRDD = inputRDD.coalesce(6, true) //图3.19中的第4个图
- 1
- 2
- 3
- 4
- 5
- 6
- 减少分区个数
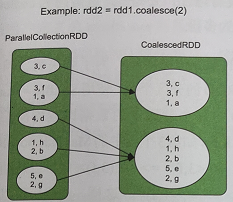
如图319中的第1个图所示,rdd1的分区个数为5,当使用coalesce(2)减少为两个分区时,spark会将相邻的分区直接合并在一起,得到rdd2,形成的数据依赖关系是多对一的NarrowDependency.这种方法的缺点是,当rdd1中不同分区中的数据量差别较大时,直接合并容易造成数据倾斜(rdd2中某些分区数据量过多或过少) - 增加分区个数

如图3.19中的第2个图所示,当使用coalesce(6)将rdd1的分区个数增加为6时,会发现生成的rdd2的分区个数并没有增加,还是5。这是因为coalesce()默认使用NarrowDependency,不能将一个分区拆分为多份。 - 使用Shuffle来减少分区个数:

如图3.19中的第3个图所示,为了解决数据倾斜的问题,我们可以使用coalesce(2, Shuffle = true)来减少RDD的分区个数。使用Shuffle = true后,Spark随机将数据打乱,从而使得生成的RDD中每个分区中的数据比较均衡。具体采用的方法是为rdd1中的每个record添加一个特殊的Key,如第3个图中的MapPartitionsRDD,Key是 Int类型,并从[0, numPartitions)中随机生成,如<3,f >=><2,(3,f)>中,2是随机生成的Key,接下来的record的Key递增1,如<1,a> =><3,(1,a)>。这样,Spark可以根据Key的 Hash值将rdd1中的数据分发到rdd2的不同的分区中,然后去掉Key即可(见最后的 MapPartitionsRDD)。 - 使用Shuffle来增加分区个数:

如图3.19 中的第4个图所示,通过使用ShuffeDepedency,可以对分区进行拆分和充足,解决分区个数不能增加的问题。
三、repartition = coalesce(numPartitions,true)
repartition(partitionNums): Reshuffle the data in the RDD randomly to create either more or fewer partitions and balance it across them. This always shuffles all data over the network.
中文:通过创建更多或更少的分区将数据随机的打散,让数据在不同分区之间相对均匀。这个操作经常是通过网络进行数打散。
从设计的角度上来说,repartition 是用来让数据更均匀分布的
coalesce和repartition 用法
语义上的区别:repartition = coalesce(numPartitions,true)
coalesce
coalesce算子默认只能减少分区数量,如果设置为false且参数大于调用RDD的分区数,那调用RDD的分区数不会变化。
coalesce的作用常常是减少分区数,已达到输出时合并小文件的效果。减少分区数有2种情况:
- 直接用默认的coalesce(parNum,false),此时只有一个stage,且stage的并行度设置为coalesce的parNum,可能会对性能有影响
在一个stage中,coalesce中设定的分区数是优先级最高的 - coalesce(parNum,true),此时会有2个stage,stage0仍然使用原来的并行度,然后合并分区,减少并行度。适合大数据量的过滤后小数据量的操作。
比如有个rdd原来有200个分区,经过filter操作后,数据大幅减少,200个分区过多了,此时就可以使用coalesce(parNum,true)
repartition
repartition 返回一定一个parNum个分区的RDD,一定会shuffle,一般用这个就是为了增加分区数,提高并行度!
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/笔触狂放9/article/detail/727546
推荐阅读
相关标签

