
- 1Nvidia TX2 Ubuntu18.04 安装 IntelRealsense L515 realsense SDK 及 Realsense ROS (make各种问题解答,一篇到位版本)_ubuntu18.04中安装realsense sdk v2.50.0版本
- 2如何使用python做中文情感分析_python 中文情感分析
- 3安装Win2016服务器_winserver2016
- 4边缘检测算法总结及其python实现——二阶检测算子_python 边缘检测log算法
- 5mac本地部署 局域网访问_mac搭建本地服务器
- 6VK cup 2017 E. Singer House (奇妙的dp)_550384565
- 7ChatGPT模型大战:讯飞星火认知大模型、百度文心一言能否击败GPT-4(含个人内测体验测试邀请码获取方法,2小时申请成功,亲测有效)_文心大模型体验申请
- 8过滤器没起作用的,即自定义filter处理了数据但不起效果的原因_filter不起作用
- 9计算机网络之TCP四次挥手
- 10python离线安装第三方库_python离线安装第三方库whl
行人检测方法之YOLO和YOLOv2_res2net 尺度 3 4 行人识别 原理 方案
赞
踩
YOLO将物体检测作为回归问题求解。基于一个单独的end-to-end网络,完成从原始图像的输入到物体位置和类别的输出。而rcnn/fast rcnn/faster rcnn将检测结果分为两部分求解:物体类别(分类问题),物体位置即bounding box(回归问题)。

一、YOLO
1、原理:
YOLO将输入图像分成SxS个格子,每个格子负责检测‘落入’该格子的物体。若某个物体的中心位置的坐标落入到某个格子,那么这个格子就负责检测出这个物体。如下图所示,图中物体狗的中心点(红色原点)落入第5行、第2列的格子内,所以这个格子负责预测图像中的物体狗。

2、网络架构

3、网络输出信息:
B个bounding box(包含物体的矩形区域)信息,以及C个物体属于某种类别的概率信息。
Bounding box信息包含5个数据值,分别是x,y,w,h,和confidence。其中x,y是指当前格子预测得到的物体的bounding box的中心位置的坐标。w,h是bounding box的宽度和高度。注意:实际训练过程中,w和h的值使用图像的宽度和高度进行归一化到[0,1]区间内;x,y是bounding box中心位置相对于当前格子位置的偏移值,并且被归一化到[0,1]。
confidence反映当前bounding box是否包含物体以及物体位置的准确性,计算方式如下:
confidence = P(object)* IOU
因此,YOLO网络最终的全连接层的输出维度是 SS(B5 + C)。YOLO论文中,作者训练采用的输入图像分辨率是448x448,S=7,B=2;采用VOC 20类标注物体作为训练数据,C=20。因此输出向量为77*(20 + 2*5)=1470维。作者开源出的YOLO代码中,全连接层输出特征向量各维度对应内容如下:

4、Loss函数

5、训练
1)预训练。使用ImageNet
1000类数据训练YOLO网络的前20个卷积层+1个average池化层+1个全连接层。训练图像分辨率resize到224x224。
2)用步骤1)得到的前20个卷积层网络参数来初始化YOLO模型前20个卷积层的网络参数,然后用VOC 20类标注数据进行YOLO模型训练。为提高图像精度,在训练检测模型时,将输入图像分辨率resize到448x448。
二、YOLOv2
1、改进之处

2、网络架构


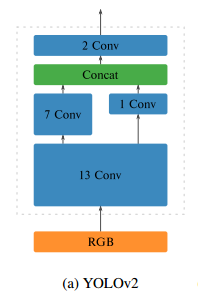
3、网络输出问题


由第二张网络结构图可知,最终输出为13 x13 x125。其中125=5*(4+1+20)。
网络共分13*13网格,每个grid cell有5个anchor box,4个值(中心点x,y、宽高w,h),一个confience。
4、训练
第一阶段:先在ImageNet分类数据集上预训练Darknet-19,此时模型输入为224x224,共训练160个epochs。
第二阶段:将网络的输入调整为448x448,继续在ImageNet数据集上finetune分类模型,训练10个epochs,此时分类模型的top-1准确度为76.5%,而top-5准确度为93.3%。
第三阶段:修改Darknet-19分类模型为检测模型,移除最后一个卷积层、global avgpooling层以及softmax层,并且新增加三个3x3x1024卷积层,同时增加了一个passthrough层,最后使用1x1卷积层输出预测结果,输出的channels数为:num_anchorsx(5+num_classes)。
另外,在训练过程中,还引入了多尺寸训练,由于网络删除了全连接层,所以该网络并不关心图片的具体大小,训练时使用320~608尺寸的图像{320,352,….,608}。
YOLOv2几个难理解的细节
1、anchor box
YOLOv2最大的改进之处就是引入了R-CNN的anchor box(先验框),来解决多尺度输入的问题。,YOLOv1在训练过程中学习适应不同物体的形状是比较困难的,这也导致YOLOv1在精确定位方面表现较差,YOLOv2采用先验框使得模型更容易学习。
利用k-means聚类算法来获得anchor box数量,综合考虑模型复杂度和召回率,作者最终选取5个聚类中心作为先验框。
聚类分析时选用box与聚类中心box之间的IOU值作为距离指标:
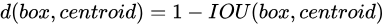

2、Direct location prediction

边界框预测的4个offsets(tx、ty、tw、th),其中 (Cx、Cy)为cell的左上角坐标,(Pw、Ph)为先验框(anchor box)的预设宽和高(k-means),每个grid cell有5个先验框,用形状最贴近的来计算。
3、网络27层的passthrough层
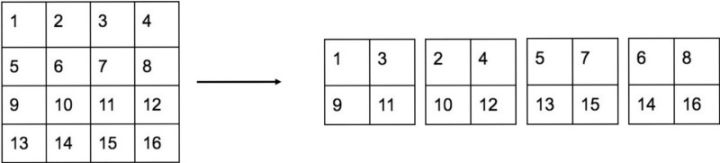
4、网络28层concat层
融合27层和24层,通道数变为1024+256=1280。可具体查看concat的相关原理来理解这一部分。

