
- 1rasterio介绍以及代码
- 2篇三:让OAuth2 server支持密码模式_oauth2authorizationgrantauthenticationtoken
- 3Django 自定义权限管理系统(通过中间件认证)_中间件对指定的文件配置权限认证
- 4Confluent kafka rest实战
- 5关于Gitee的安装与概述_gitee安装
- 6SF相关1111
- 7补: Codeforces Round #698 (Div. 2)_codeforces round #698 (div. 2) c
- 8基于微信小程序+SpringBoot的私家车位共享系统小程序(源码+文档+部署+讲解)
- 9Codeforces Round #828 (Div. 3) 题解(A-E2)_828 codeforces
- 10Mac 系统安装 PyCharm 并使用_mac安装pycharm
如何使用python做中文情感分析_python 中文情感分析
赞
踩
学习补充:


作为一门编程语言,Python的编写简单,支持库强大,应用场景多,越来越多的人开始将它作为自己的编程入门语言。
Python一个比较重要的场景是做舆情分析,比如分析社交网络上群众对某一话题的态度,分析股民的情绪作为投资参考等。其中最基础的环节就是--分析一段话的情感倾向。
这里搬出笔者曾经做过的一个例子:分析知乎论坛2017年,“清华大学”话题下的集体情绪变化。
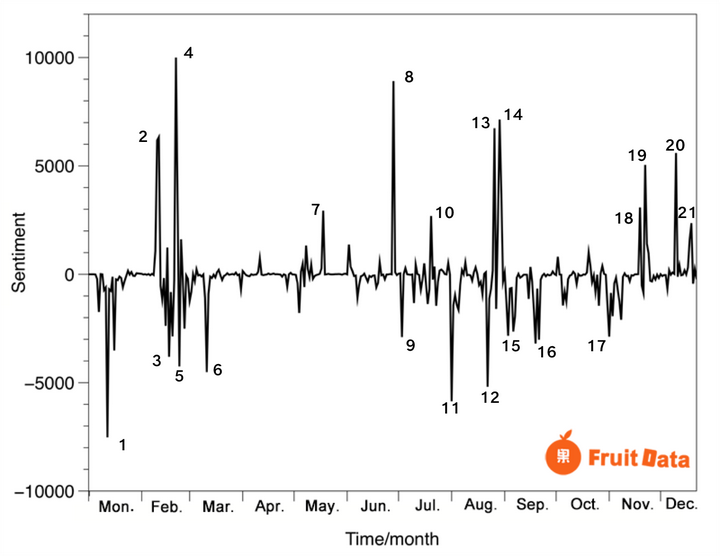
下面就分理论和实践两个部分,讲一讲怎么快速实现上面一幅图。
1.中文情感分析方法和难点
在上文所讲的例子中,我们希望得到的是人们对一件事情评价的情感倾向。比如支持还是反对一件事情,喜欢一件产品与否--结果可能是积极的,消极的或者中立的。比如
特别喜欢这种可爱的小狗这句话的情感倾向显而易见是正面的。
情感标注的工作交给机器去做,可以有以下几种实现方式:
1.1 词性词典和分词
简单的说,就是给每个词语标注情感极性,比如好看是积极的,丑陋是消极的。拥有这样一个词典,机器就能对词语情感做分类。 对于一句话,可以按先分词,再统计每个词语的情感极性的方法。中文分词的方法可以参照笔者之前的文章: 如何绘制好看的中文云词图。
这种方法看起来是很简便,但是问题在于,汉语言博大精深,同一个词在不同语境里有不同的意思,可能表达不同的情感态度。
比如“这个电影拍得太牛逼了”,“你牛逼你上啊”,前一句表示电影拍的好,情感积极,而后一句则属于反讽,情感负面。仅靠词语标注是没法准确反映一句话的情感倾向的。
另一个比较客观的情况是目前也没有比较好的开源中文情感词典。
1.2 机器学习
传统的机器学习方法如SVM,Naive Bayes等也可以用来做情感分类。这里的关键是将文本转换文本矩阵(比如常用的Bag of Words),交给训练好的分类器进行情感识别和分类。
Python里有一个常用的中文文本处理库SnowNLP,里面就使用了Bayes的方法,通过已经标注好极性的语句进行训练得到分类器。需要注意的是官方用于情感分析的训练集来自买卖东西的评价,因此这个情感分析用于商品评价最为准确,其它领域最好自建训练集。
下载SnowNLP使用以下命令即可:
pip install snownlp1.3 神经网络
神经网络在图像识别上发挥了巨大的威力,同样的方法也被用在了文本处理上。笔者认为现有比较简单的方法是以字符为单位,训练神经网络。这种方法不需要提前知道语法和语义的知识,但需要比较大的训练集做训练。在情感分析方面这种方法已经达到了比较好的效果。
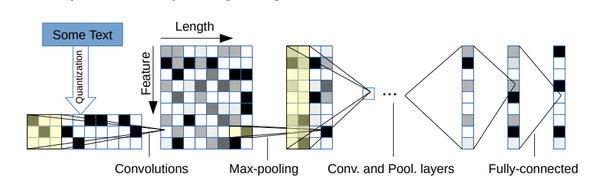
这种方法由纽约大学Yann LeCun团队提出,具体实现可以阅读他们的论文。 https://arxiv.org/pdf/1509.01626.pdf
2.简单实现文本的情感分析
上面提到了诸多实现中文文本情感分析的方法,读者可以根据自己的兴趣去实现。尽管有这么多方法,但都是要花一些功夫去研究和实现的。针对某一领域相关的文本的情感分析可能需要不断的去优化,才能达到比较好的效果。
这里我给大家推荐一个现成的轮子,百度提供的情感倾向分析API(搜索“百度AI开放平台”即可)。文章开始的集体情感变化曲线就是用这个实现的。
使用的方法也很简单,在官网注册之后,可以得到每月免费使用的10W次权限。python可以直接下载百度情感分析的调用模块。 安装方法:
pip install baidu-aip
- 1
使用方法:
from aip import AipNlp
""" 你的 APPID AK SK """
APP_ID = '你的 App ID'
API_KEY = '你的 Api Key'
SECRET_KEY = '你的 Secret Key'
client = AipNlp(APP_ID, API_KEY, SECRET_KEY)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
输入待分析的文本(一段知乎的回答):
text="以前约过一个电子系妹子,之前和妹子关系都挺好的
约出去一切也很正常,直到不知怎么问起GPA。 我说我GPA不行,只有多少
多少。(大概略高于平均吧) 她哦了一声,说她有多少多少(反正比我高很多,
她貌似是他们系前几名) 从此以后她再也没理过我。 "
result=client.sentimentClassify(text)
- 1
- 2
- 3
- 4
- 5
返回结果:
{
'items': [ {
'confidence': 0.528202, //表示分类的置信度
'negative_prob': 0.787691, //表示属于消极类别的概率
'positive_prob': 0.212309, //表示属于积极类别的概率
'sentiment': 0 //表示情感极性分类结果
}
],
'text': '以前约过一个电子系妹子...... '
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
解读一下结果,这句话情绪比较负面,负面的概率是0.787691,置信度是0.528202。
不用自建训练集,也不用自己调优,完全依赖百度的黑盒子,就可以实现简单的情感分析。是不是很赞O(∩_∩)O~
关于我更多的实践,请关注 “果果数据” 微信公众号,未来也会推出更多数据相关的应用和技术分享!

