
- 1「燃烧吧!天才程序员」首档程序员综艺真人秀即将开播
- 2AI绘画Stable Diffusion SDXL 超赞!高质量万能大模型,写实人像、时尚设计、建筑设计、电影制作—筑梦工业XLV4.0_sdxl模型
- 3网络安全之Windows提权(上篇)(高级进阶)
- 4太良心了!微软面向初学者,开源机器学习、数据科学、AI、LLM_microsoft 的ai课程
- 5C++循环结构_c++如何写0到9循环排列的代码
- 6【技术干货】聊聊在大厂推荐场景中embedding都是怎么做的
- 7python---3--sort、lambdalen(list1)、sorted_numbers = sorted(numbers)、list.sort()
- 8YoloV5改进策略:BackBone改进|ECA-Net:用于深度卷积神经网络的高效通道注意力_改进yolov5backbone
- 9怎么卸载gitlab_git仓库怎么完全卸载
- 10TF-IDF详解
【机器学习】集成算法:bagging策略包含详细案例_集成学习的bagging策略
赞
踩
前言
Bagging是一种基于集成学习的算法,是一种广泛使用的机器学习技术。Bagging的全称是Bootstrap Aggregating,其思想是通过将许多相互独立的学习器的结果进行结合,从而提高整体学习器的泛化能力。本篇博客将介绍Bagging算法的工作原理,优点和缺点,以及如何在Python中实现。
一、工作原理
Bagging算法的工作原理非常简单。首先,它从原始数据集中使用有放回的随机采样方式抽取多个子集,这些子集的大小与原始数据集相同。然后,它使用每个子集独立地训练一个学习器。最后,当需要进行预测时,Bagging算法将所有学习器的预测结果进行结合,以得出最终的预测结果。
原理过程
-
- 将原始数据集D随机划分成m个子集D1, D2, …, Dm
-
- 对于每个子集Di, 训练一个基学习器Hi
-
- 对于每个测试样本x,将其输入到所有的基学习器Hi中,并得到对应的预测结果{yi1, yi2, …, yim}
-
- 将所有的预测结果进行结合,以得出最终的预测结果y
二、优缺点
Bagging算法具有以下几个优点:
- Bagging算法可以显著降低模型的方差,提高模型的稳定性。通过使用多个相互独立的学习器,Bagging可以减少模型对训练数据的敏感性,从而更好地适应未知的测试数据。
- Bagging算法可以并行计算,加速模型训练的速度。由于每个基学习器都是独立训练的,所以Bagging算法可以并行处理多个子集,从而加速训练过程。
- Bagging算法不容易出现过拟合。通过使用随机抽样的方式来生成多个子集,Bagging可以避免模型对训练数据的过分拟合。
Bagging算法的缺点包括:
- Bagging算法对于噪声数据比较敏感。由于Bagging算法对于每个子集都会训练一个基学习器,因此如果某个子集包含大量的噪声数据,那么对应的基学习器的性能可能会下降,从而影响整个模型的性能。
- Bagging算法在处理分类问题时,容易出现过于一致性问题。如果不同的基学习器都对同一个测试样本做出了相同的错误预测,那么Bagging算法将无法有效纠正这个错误。
三、实战案例
- 构造训练测试数据集,这里我们只拿后两个特征值来训练
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
iris=load_iris()
X=iris.data[:,2:4]
y=iris.target
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 决策树bagging策略模型
bgg_clf=BaggingClassifier(
DecisionTreeClassifier(max_depth=2),
n_estimators=10,
max_samples=155,
bootstrap=True,
random_state=42
)
bgg_clf.fit(X_train,y_train)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
这个采用看决策树模型,生成50棵决策树,最大样本为50,根据自己的数据量选择
- 预测结果
y_pred=bgg_clf.predict(X_test)
from sklearn.metrics import accuracy_score
print('准确率:',accuracy_score(y_test,y_pred))
- 1
- 2
- 3

- 对比实验
我们把上面的个bagging模型与单个决策树进行比较
tree_clf=DecisionTreeClassifier(random_state=42)
tree_clf.fit(X_train,y_train)
y_pred_tree=tree_clf.predict(X_test)
accuracy_score(y_test,y_pred_tree)
- 1
- 2
- 3
- 4
- 5

准确率相对与bagging有点小差距,为了更好的观察,我们可视化下决策边界
from sklearn.inspection import DecisionBoundaryDisplay import matplotlib.pyplot as plt import mplcyberpunk plt.style.use('cyberpunk') def plot_decision_boundar(modal,ax): DecisionBoundaryDisplay.from_estimator( modal, X, ax=ax, response_method="auto", alpha=0.5,) for i,target in enumerate(iris.target_names): plt.scatter( X[:,0][y==i], X[:,1][y==i], edgecolors='black', label=target, ) ax=plt.subplot(121) plot_decision_boundar(tree_clf,ax) plt.title('Decision Tree') ax=plt.subplot(122) plot_decision_boundar(bag_clf,ax) plt.title('Decision Tree With Bagging')

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
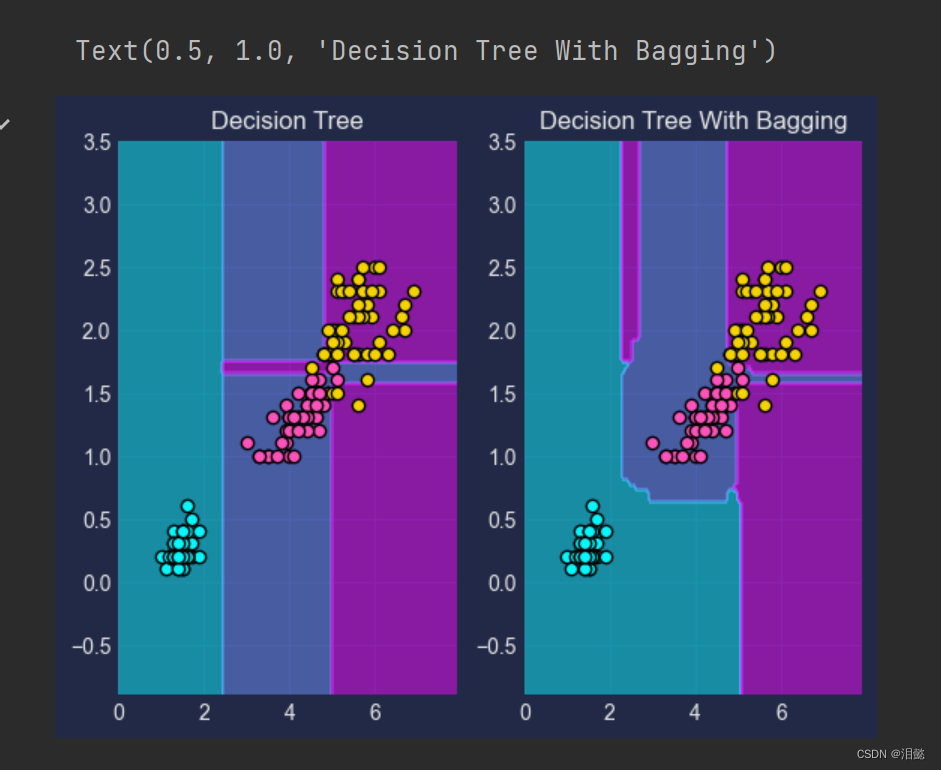
四 、OOB策略
OOB(Out-Of-Bag)策略是Bagging算法的一种特殊形式。在Bagging算法中,为了训练多个基学习器,我们从原始数据集中有放回地抽取多个子样本,并将每个子样本分别用于训练一个基学习器。但是,在每个子样本中,只有大约63.2%的样本被抽取到。因此,剩余的约36.8%的样本可以被用于模型的评估,这些样本被称为OOB样本。
OOB(Out-Of-Bag)策略是Bagging算法的一种特殊形式,可以用于评估Bagging模型的性能和特征重要性。,使用oob_score_属性来获取模型的OOB评估结果。使用OOB策略可以提高Bagging算法的性能,并在一定程度上避免了过拟合的问题。同时,通过统计每个特征在OOB样本上的预测结果,我们还可以评估特征的重要性,从而进一步优化模型的性能。
需要注意的是,在使用OOB策略时,我们需要确保每个基学习器都使用了不同的子样本进行训练。如果使用相同的子样本进行训练,那么在OOB样本中可能会出现重复样本,导致评估结果不准确。
- 重新构建模型
bag_clf=BaggingClassifier(
DecisionTreeClassifier(),
n_estimators=50,
max_samples=50,
random_state=42,
bootstrap=True,
oob_score=True
)
bag_clf.fit(X_train,y_train)
bag_clf.oob_score_
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
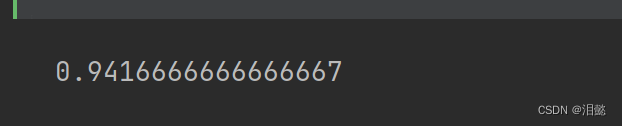
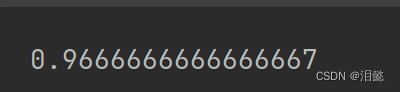
验证得分为0.94,然后我们用测试集来预测得分
y_pred=bag_clf.predict(X_test)
accuracy_score(y_test,y_pred)
- 1
- 2
我们可以打印一下每个特征值的决策得分概率情况
bag_clf.oob_decision_function_
- 1
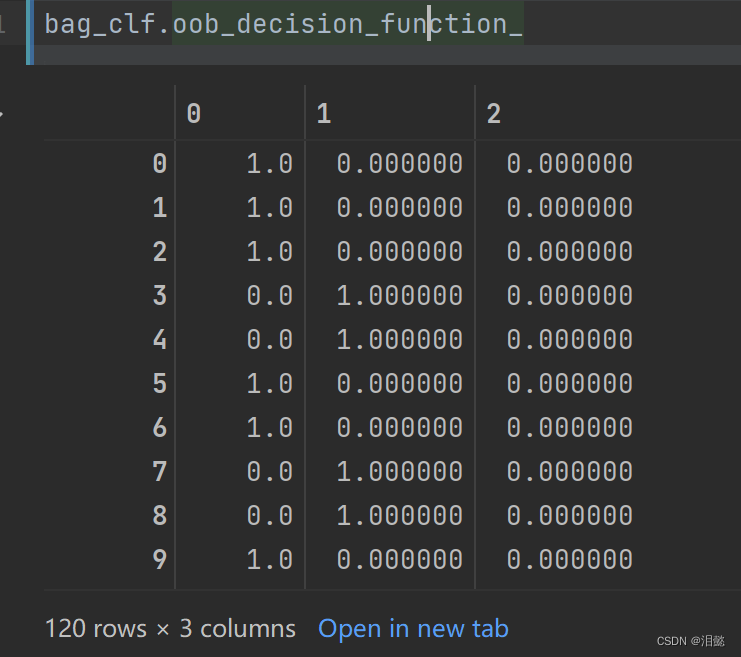
表示每个类别所属的概率
五、总结
Bagging算法是一种基于集成学习的算法,可以显著降低模型的方差,提高模型的稳定性。Bagging算法的优点包括降低模型的方差、并行计算和避免过拟合。Bagging算法的缺点包括对噪声数据比较敏感和容易出现一致性问题
希望大家多多支持,后续分享有趣的只是

