
热门标签
热门文章
- 1人脸识别系统真的不难?今天手把手教你用Python写,程序员开发指南_智慧教育人脸识别项目设计python
- 2SVG、D3.js、Echarts.js_d3.js下载
- 3数据结构----排序总结_数据结构排序总结
- 4求n以内最大的k个素数以及它们的和_18个必背经典C语言程序,收藏备用
- 5用CodePen实现JavaScript程序动态在线开发
- 6Oracle 12c创建用户时出现“ORA-65096: invalid common user or role name”的错误
- 7学习计划|一个月学会 Python,零基础入门数据分析_python学习计划
- 8Unit2_1:动态规划DP
- 9计算机视觉——基于OpenCV和Python进行模板匹配_python opencv 模板匹配
- 10【教学赛】金融数据分析赛题1:银行客户认购产品预测(0.9676)
当前位置: article > 正文
扩散模型Stable Diffusion_扩散模型latents
作者:笔触狂放9 | 2024-06-21 06:25:50
赞
踩
扩散模型latents
扩散模型构成
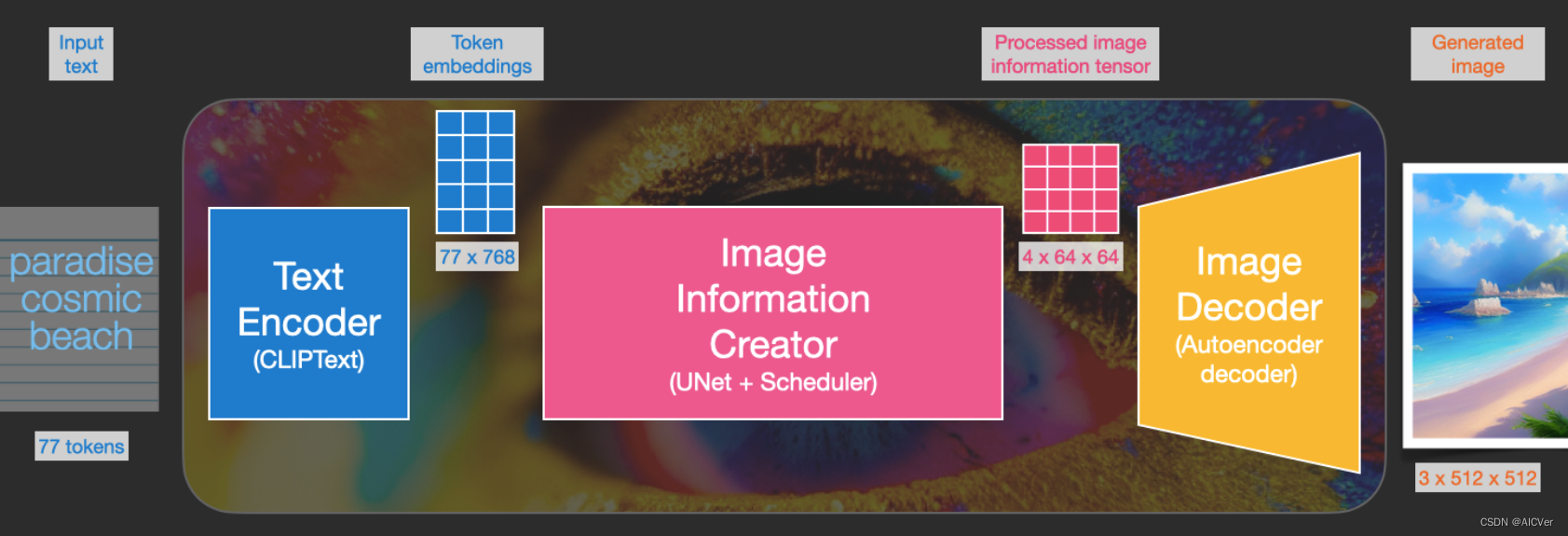
Text Encoder(CLIPText)
Clip Text为文本编码器。以77 token为输入,输出为77 token 嵌入向量,每个向量有768维度。
Diffusion(UNet+Scheduler)
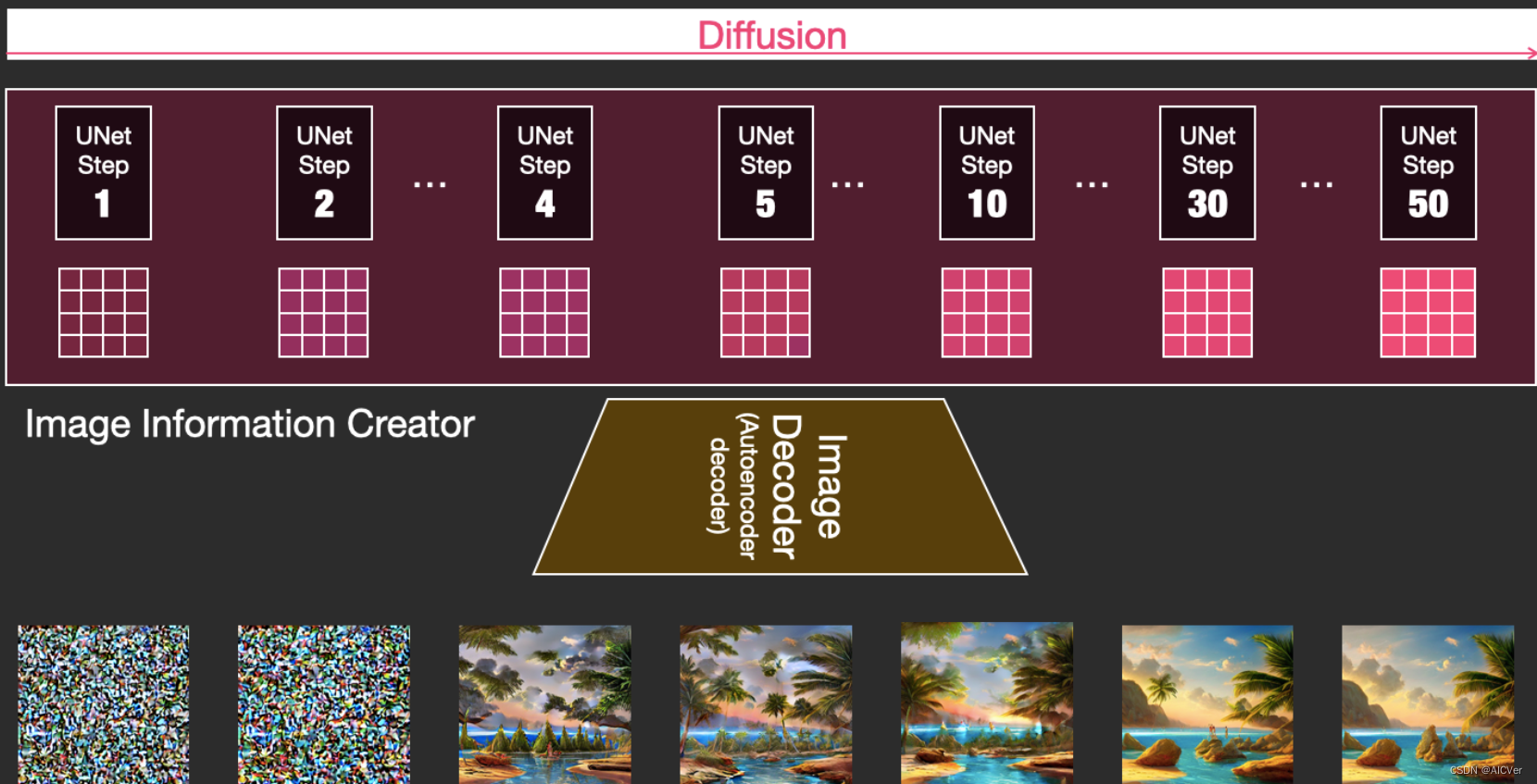
在潜在空间中逐步处理扩散信息。以文本嵌入向量和由噪声组成的起始多维数组为输入,输出处理的信息数组。
UNet
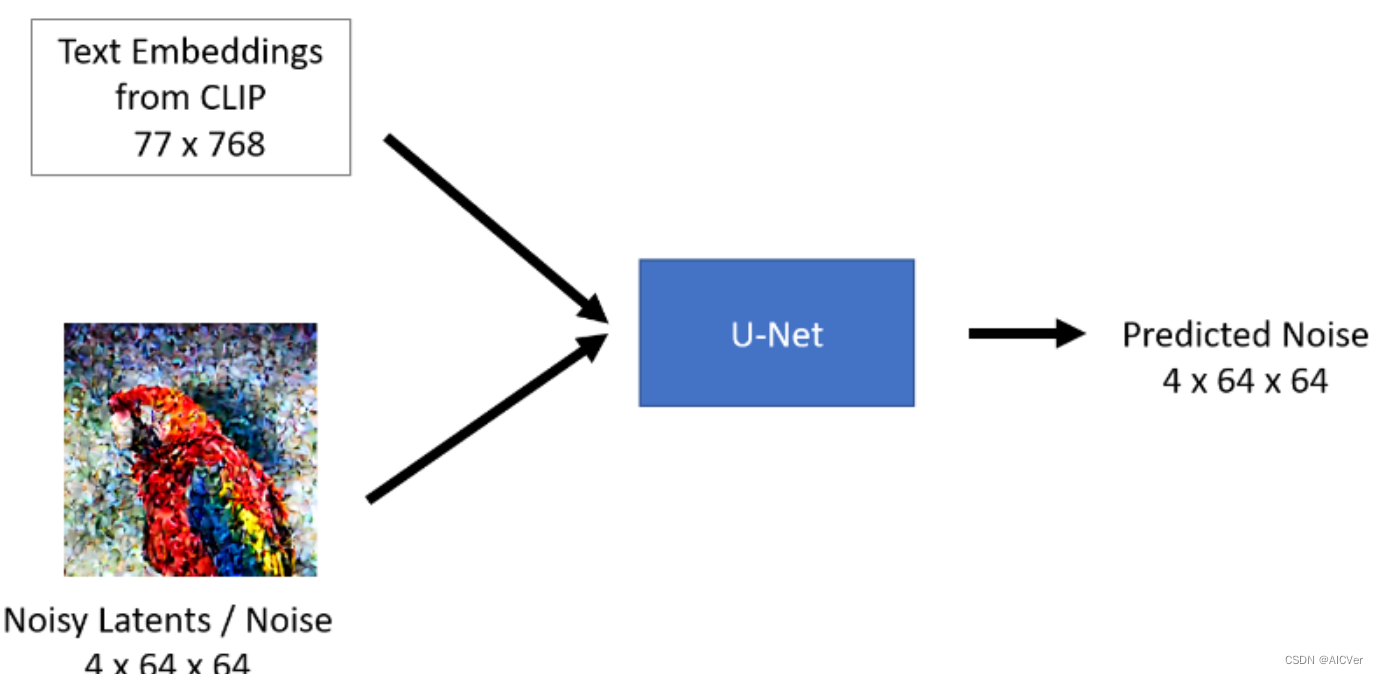
训练过程
- 随机噪声添加到图像上,构成一个训练样本
- 不同的噪声不同的图像,可构成训练集
- 使用上述训练集,训练噪声预测模型(Unet)
推理过程
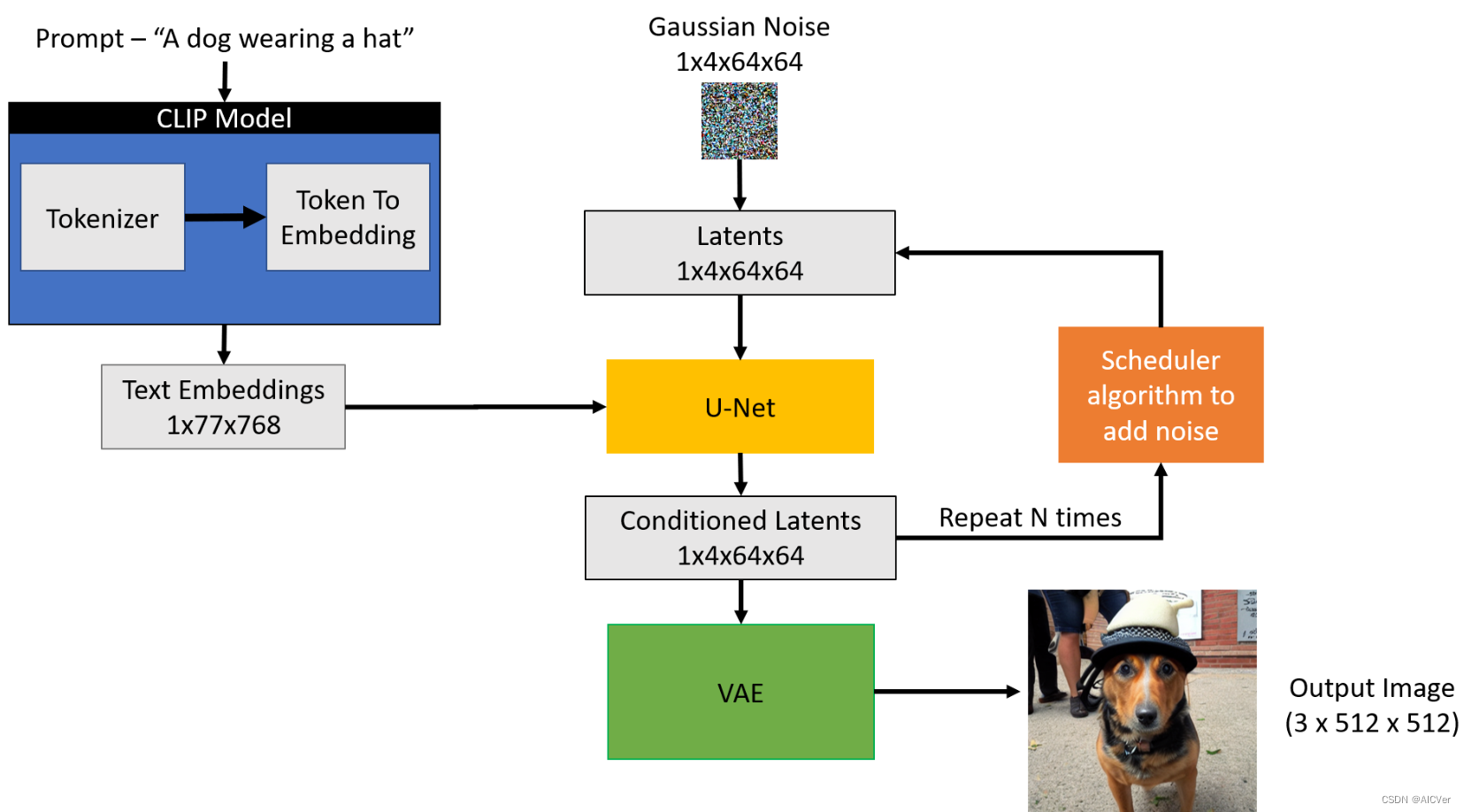
通常来说一个U-Net包含两个输入:
- Noisy latent/Noise : 该Noisy latent主要是由VAE编码器产生并在其基础上添加了噪声;或者如果我们想仅根据文本描述来创建随机的新图像,则可以采用纯噪声作为输入。
- Text embeddings: 基于CLIP的将文本输入提示转化为文本语义嵌入(embedding)
U-Net模型的输出:
- 从包含输入噪声的Noisy Latents中预测其所包含的噪声。换句话说,它预测输出的为Noisy Latents减去de-noised latents后的结果。
Scheduler
scheduler的目的是确定在扩散过程中的给定的步骤中向latent 添加多少噪声。随着step的增大,添加噪声的权重在逐渐减小。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/笔触狂放9/article/detail/742295
推荐阅读

相关标签

