
- 1STM32F072 CAN and USB
- 2ResNet(用pytorch搭建自己的网络ResNet)笔记_new_resnet包
- 3Gamma、Linear、sRGB 和Unity Color Space,你真懂了吗?_color space linear srgb
- 4法国计算机专业学校排名,法国计算机专业大学排名(2020年泰晤士)_快飞留学
- 5docker安装配置_docker.service配置文件
- 6科大讯飞回应了:中国版ChatGPT可以乐观以待,有信心实现类似技术跃迁
- 7华为OD机试 - 运动会(JavaScript) | 机试题+算法思路+考点+代码解析 【2023】_js机考 运动会
- 8使用Java轻松破解顶象滑动拼图验证码,成功率接近100%?_java获取验证码图片阴影框位置
- 9Dockerfile优化技巧_前端项目优化dockerfile 构建速度
- 10MongoDB安装 出现 Verify that you have sufficient privileges to start system services 的解决办法_verifthat you have sufficient
经典卷积神经网络-VGG原理_vgg卷积神经网络
赞
踩
《Very Deep Convolutional Networks for Large-Scale Image Recognition》
VGG是2014年Oxford的Visual Geometry Group提出的,其在在2014年的 ImageNet 大规模视觉识别挑(ILSVRC -2014中获得了亚军,第一名是GoogleNet。该网络是作者参加ILSVRC 2014比赛上的作者所做的相关工作,相比AlexNet,VGG使用了更深的网络结构,证明了增加网络深度能够在一定程度上影响网络性能。
1.VGG网络结构简介
网络结构如下:

上图上半部分是常见的VGG网络结构,可以看见输入图片是224*224的RGB图像,经过卷积、池化与全连接操作后输出1000个分类结果;下半部分是五段卷积组,每一段卷积组后接一个最大池化层,最后由3层全连接层输出分类结果。
VGG网络结构图:
卷积层全部为3*3的卷积核,用conv3-xxx来表示,xxx表示通道数。论文作者一共实验了6种网络结构,其中VGG16和VGG19分类效果最好(16、19层隐藏层),证明了增加网络深度能在一定程度上影响最终的性能。 两者没有本质的区别,只是网络的深度不一样。
2.VGG的亮点
1.小卷积核组。作者通过堆叠多个3*3的卷积核(少数使用1*1)来替代大的卷积核,以减少所需参数;
2.小池化核。相比较于AlexNet使用的3*3的卷积核,VGG全部为2*2的卷积核;
3.网络更深特征图更宽。卷积核专注于扩大通道数,池化专注于缩小高和宽,使得模型更深更宽的同时,计算量的增加不断放缓;
4.将卷积核替代全连接。作者在测试阶段将三个全连接层替换为三个卷积,使得测试得到的模型结构可以接收任意高度或宽度的输入。
5.多尺度。作者从多尺度训练可以提升性能受到启发,训练和测试时使用整张图片的不同尺度的图像,以提高模型的性能。
6.去掉了LRN层。作者发现深度网络中LRN(Local Response Normalization,局部响应归一化)层作用不明显。
3.VGG16网络结构详解
3.1 维度
以VGG16进行网络结构介绍,其他组类型大同小异。整个模型结构可分为两大部分:提取特征网络结构与分类网络结构
卷积层默认kernel_size=3,padding=1;池化层默认size=2,strider=2。下面进行结构分析:
输入图像尺寸为224*224*3
经过2层的64*3*3卷积核,即卷积两次,再经过ReLU激活,输出尺寸大小为224*224*64
经最大池化层(maxpooling),图像尺寸减半,输出尺寸大小为112*112*64
经过2层的128*3*3卷积核,即卷积两次,再经过ReLU激活,输出尺寸大小为112*112*128
经最大池化层(maxpooling),图像尺寸减半,输出尺寸大小为56*56*128
经过3层的256*3*3卷积核,即卷积三次,再经过ReLU激活,输出尺寸大小为56*56*256
经最大池化层(maxpooling),图像尺寸减半,输出尺寸大小为28*28*256
经过3层的512*3*3卷积核,即卷积三次,再经过ReLU激活,输出尺寸大小为28*28*512
经最大池化层(maxpooling),图像尺寸减半,输出尺寸大小为14*14*512
经过3层的512*3*3卷积核,即卷积三次,再经过ReLU激活,输出尺寸大小为14*14*512
经最大池化层(maxpooling),图像尺寸减半,输出尺寸大小为7*7*512
然后将feature map展平,输出一维尺寸为7*7*512=25088
经过2层的1*1*4096全连接层,经过ReLU激活,输出尺寸为1*1*4096
经过1层的1*1*1000全连接层(1000由最终分类数量决定,当年比赛需要分1000类)输出尺寸为1*1*1000,最后通过softmax输出1000个预测结果
3.2 权重参数(不考虑偏置)
输入层为214*224*3,没有参数为0,存储容量为224*224*3=150k
第一层卷积,输入层有3个channels,卷积核数量为64,所以参数为64*3*3*3=1728,存储容量为224*224*64=3.2m
第二层卷积,输入有64个channels,卷积核数量为64,所以参数为64*3*3*64=36864,存储容量为224*224*64=3.2m
第一层池化,输入为64个channels,高宽减半,所以参数为0,存储容量为112*112*64=800k
第三层卷积,输入有64个channels,卷积核数量为128,所以参数为64*3*3*128=73728,存储容量为112*112*128=1.6m
第四层卷积,输入有128个channels,卷积核数量为128,所以参数为128*3*3*128=147456,存储容量为112*112*128=1.6m
第二层池化,输入为128个channels,高宽减半,所以参数为0,存储容量为56*56*128=400k
第五层卷积,输入有128个channels,卷积核数量为256,所以参数为256*3*3*128=294912,存储容量为112*112*128=800k
第六层卷积,输入有256个channels,卷积核数量为256,所以参数为256*3*3*256=589824,存储容量为112*112*128=800k
。。。。。。
全连接层权重参数为:前一层节点数×本层的节点数
FC1(1×1×4096)参数:7×7×512×4096=102760448,存储容量为4096
FC2(1×1×4096)参数:4096×4096=16777216,存储容量为4096
FC3(1×1×1000)参数:4096×1000=4096000,存储容量为1000

VGG16具有如此之大的参数数目(主要集中在全连接层),可以预期它具有很高的拟合能力;但同时缺点也很明显:即训练时间过长,调参难度大;需要的存储容量大,不利于部署。
4.VGG的特点
4.1 小卷积核
卷积与网络深度息息相关,虽然AlexNet使用了11x11和5x5的大卷积,但大多数还是3x3卷积,对于stride=4的11x11的大卷积核,理由在于一开始原图的尺寸很大因而冗余,最为原始的纹理细节的特征变化可以用大卷积核尽早捕捉到,后面更深的层数害怕会丢失掉较大局部范围内的特征相关性,后面转而使用更多3x3的小卷积核和一个5x5卷积去捕捉细节变化。
而VGGNet则全部使用3x3卷积。因为卷积不仅涉及到计算量,还影响到感受野。前者关系到是否方便部署到移动端、是否能满足实时处理、是否易于训练等,后者关系到参数更新、特征图的大小、特征是否提取的足够多、模型的复杂度和参数量等。
计算量
VGG16相比AlexNet的一个改进是采用连续的几个3x3的卷积核代替AlexNet中的较大卷积核(11x11,7x7,5x5)。对于给定的感受野(与输出有关的输入图片的局部大小),采用堆积的小卷积核是优于采用大的卷积核,因为多层的非线性层可以增加网络深度来保证学习更复杂的模式,而且代价还比较小(参数更少)。
在VGG中,使用了3个3x3卷积核来代替7x7卷积核,使用了2个3x3卷积核来代替5*5卷积核,这样做的主要目的是在保证具有相同感知野的条件下,提升网络的深度,在一定程度上提升神经网络的效果。
比如,3个3x3连续卷积相当于1个7x7卷积:3个3*3卷积的参数总量为 3x() =
,1个7x7卷积核参数总量为
,这里 C 指的是输入和输出的通道数。很明显,
<
,即最终减少了参数,而且3x3卷积核有利于更好地保持图像性质,多个小卷积核的堆叠也带来了精度的提升。
感受野
简单理解就是输出feature map上的一个对应输入层上的区域大小。
计算公式:(从深层推向浅层)
F(i)为第i层感受野
strider为第i步的步距
ksize为卷积核或池化核尺寸
例如:
feature map:F=1
conv3*3(3):F=(1-1)*1+3=3
conv3*3(2):F=(3-1)*1+3=5
conv3*3(1):F=(5-1)*1+3=7
见下图,输入的8个元素可以视为feature map的宽或者高,当输入为8个神经元经过三层conv3x3的卷积得到2个神经元。三个网络分别对应stride=1,pad=0的conv3x3、conv5x5和conv7x7的卷积核在3层、1层、1层时的结果。因为这三个网络的输入都是8,也可看出2个3x3的卷积堆叠获得的感受野大小,相当1层5x5的卷积;而3层的3x3卷积堆叠获取到的感受野相当于一个7x7的卷积。
-
input=8,3层conv3x3后,output=2,等同于1层conv7x7的结果;
-
input=8,2层conv3x3后,output=2,等同于2层conv5x5的结果。
-
或者我们也可以说,三层的conv3x3的网络,最后两个输出中的一个神经元,可以看到的感受野相当于上一层是3,上上一层是5,上上上一层(也就是输入)是7。
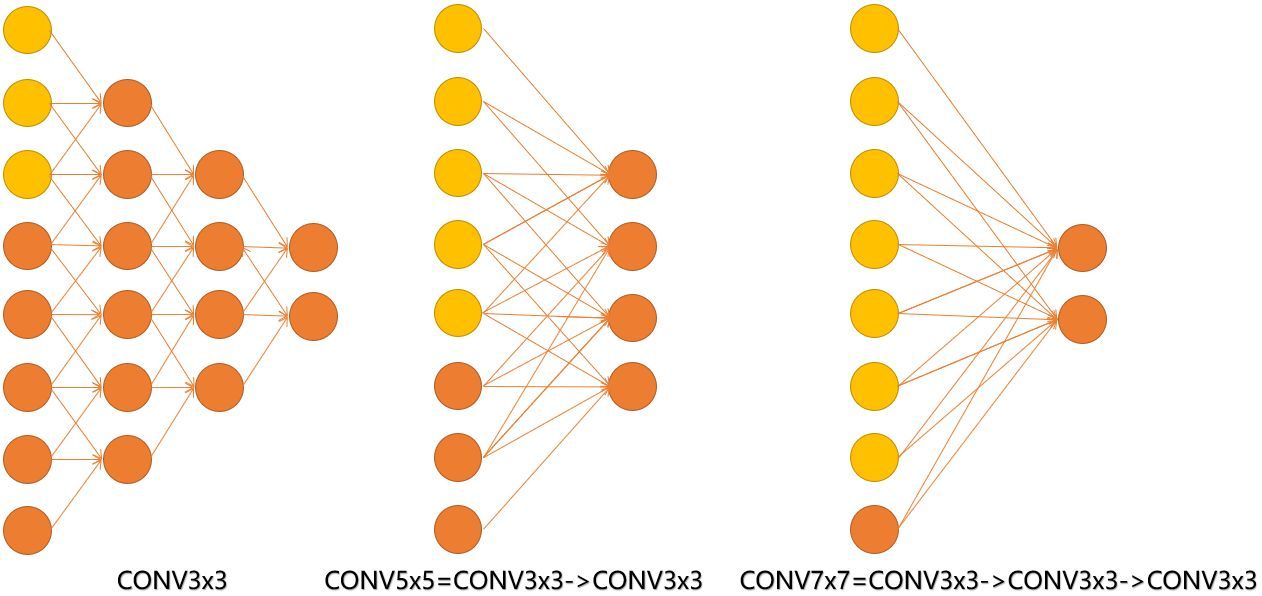
此外,倒着看网络,也就是backprop的过程,每个神经元相对于前一层甚至输入层的感受野大小也就意味着参数更新会影响到的神经元数目。在分割问题中卷积核的大小对结果有一定的影响,在上图三层的conv3x3中,最后一个神经元的计算是基于第一层输入的7个神经元,换句话说,反向传播时,该层会影响到第一层conv3x3的前7个参数。从输出层往回forward同样的层数下,大卷积影响(做参数更新时)到的前面的输入神经元越多。
堆叠小卷积核相比使用大卷积核具有更多的激活函数、更丰富的特征,更强的辨别能力。卷积后都伴有激活函数,可使决策函数更加具有辨别能力;此外,3x3比7x7就足以捕获细节特征的变化:3x3的9个格子,最中间的格子是一个感受野中心,可以捕获上下左右以及斜对角的特征变化;3个3x3堆叠近似一个7x7,网络深了两层且多出了两个非线性ReLU函数,网络容量更大,对于不同类别的区分能力更强。
4.2 小池化核
2012年的AlexNet的pooling的kernel size全是奇数,所有池化采用kernel size=3x3,stride=2的max-pooling,而VGG使用的max-pooling的kernel size=2x2,stride=2。pooling kernel size从奇数变为偶数。小kernel带来的是更细节的信息捕获。
池化做的事情是根据对应的max或者average方式进行特征筛选,max-pooling更容易捕捉图像上的变化,梯度的变化,带来更大的局部信息差异性,更好地描述边缘、纹理等构成语义的细节信息。
4.3 全连接层
VGG最后三个全连接层在形式上完全平移了AlexNet的最后三层,VGGNet后面三层(三个全连接层)为:
-
FC4096-ReLU6-Drop0.5,FC为高斯分布初始化(std=0.005),bias常数初始化(0.1)
-
FC4096-ReLU7-Drop0.5,FC为高斯分布初始化(std=0.005),bias常数初始化(0.1)
-
FC1000-SoftMax1000分类,FC为高斯分布初始化(std=0.005),bias常数初始化(0.1)
超参数上只有最后一层fc有变化:bias的初始值,由AlexNet的0变为0.1,该层初始化高斯分布的标准差,由AlexNet的0.01变为0.005。
4.4 特征图(feature map)
在随层数递增的过程中,池化逐渐忽略局部信息,特征图的宽度高度随着每个池化操作缩小50%,5个池化操作使得宽或者高度变化过程为:224->112->56->28->14->7,但是深度(channel)随着5组卷积每次增大一倍:3->64->128->256->512->512。特征信息从一开始输入的224x224x3被变换到7x7x512,从原本较为local的信息逐渐分摊到不同channel上,随着每次的卷积与池化操作打散到channel上。
特征图从512维后开始进入全连接层,因为全连接层相比卷积层更考虑全局信息,将原本有局部信息的特征图(width,height还有channel)全部映射到4096维度。也就是说全连接层前是7x7x512维度的特征图,估算大概是25000,这个全连接过程要将25000映射到4096,大概是5000,换句话说全连接要将信息压缩到原来的五分之一。VGGNet有三个全连接,我的理解是作者认为这个映射过程的学习要慢点来,太快不易于捕捉特征映射来去之间的细微变化,让backprop学的更慢更细一些。
feature map维度的整体变化过程是:先将local信息压缩,并分摊到channel层级,然后无视channel和local,通过fc这个变换再进一步压缩为稠密的feature map,这样对于分类器而言有好处也有坏处,好处是将local信息隐藏于/压缩到feature map中,坏处是信息压缩都是有损失的,相当于local信息被破坏了。
4.5 卷积组
1
前两组卷积形式一样,每组都是:conv-relu-conv-relu-pool;
中间三组卷积形式一样,每组都是:conv-relu-conv-relu-conv-relu-pool;
最后三个组全连接fc层,前两组fc,每组都是:fc-relu-dropout;最后一个fc仅有fc,在softmax。
多出的relu对网络中层进一步压榨提炼特征。结合一开始单张feature map的local信息更多一些,还没来得及把信息分摊到channel级别上,那么往后就慢慢以增大conv filter的形式递增地扩大channel数,等到了网络的中层,channel数升得差不多了(信息分摊到channel上得差不多了),那么还想抽local的信息,就通过再加一个[conv-relu]的形式去压榨提炼特征。有点类似传统特征工程中,已有的特征在固定的模型下没有性能提升了,那就用更多的非线性变换对已有的特征去做变换,产生更多的特征的意味;多出的conv对网络中层进一步进行学习指导和控制不要将特征信息漂移到channel级别上。
上一点更多的是relu的带来的理解,那么多出的[conv-relu]中conv的意味就是模型更强的对数据分布学习过程的约束力/控制力,做到信息backprop可以回传回来的学习指导。本身多了relu特征变换就加剧(权力释放),那么再用一个conv去控制(权力回收),也在指导网络中层的收敛;其实conv本身关注单张feature map上的局部信息,也是在尝试去尽量平衡已经失衡的channel级别(depth)和local级别(width、height)之间的天平。这个conv控制着特征的信息量不要过于向着channel级别偏移。
2
串联和串联中带有并联的网络架构。近年来,GoogLeNet在其网络结构中引入了Inception模块,ResNet中引入了Residual Block,这些模块都有自己复杂的操作。换句话说,传统一味地去串联网络可能并不如这样串联为主线,带有一些并联同类操作但不同参数的模块可能在特征提取上更好。 所以我认为这里本质上依旧是在做特征工程,只不过把这个过程放在block或者module的小的网络结构里,毕竟kernel、stride、output的大小等等超参数都要自己设置,目的还是产生更多丰富多样的特征。用在ImageNet上pre-trained过的模型。设计自己模型架构很浪费时间,尤其是不同的模型架构需要跑数据来验证性能,所以不妨使用别人在ImageNet上训练好的模型,然后在自己的数据和问题上在进行参数微调,收敛快精度更好。 我认为只要性能好精度高,选择什么样的模型架构都可以,但是有时候要结合应用场景,对实时性能速度有要求的,可能需要多小网络,或者分级小网络,或者级联的模型,或者做大网络的知识蒸馏得到小网络,甚至对速度高精度不要求很高的,可以用传统方法。
4.6 全连接变卷积
作者在测试阶段把网络中原本的三个全连接层依次变为1个conv7x7,2个conv1x1,也就是三个卷积层,整个网络由于没有了全连接层,网络中间的feature map不会固定,所以网络对任意大小的输入都可以处理。
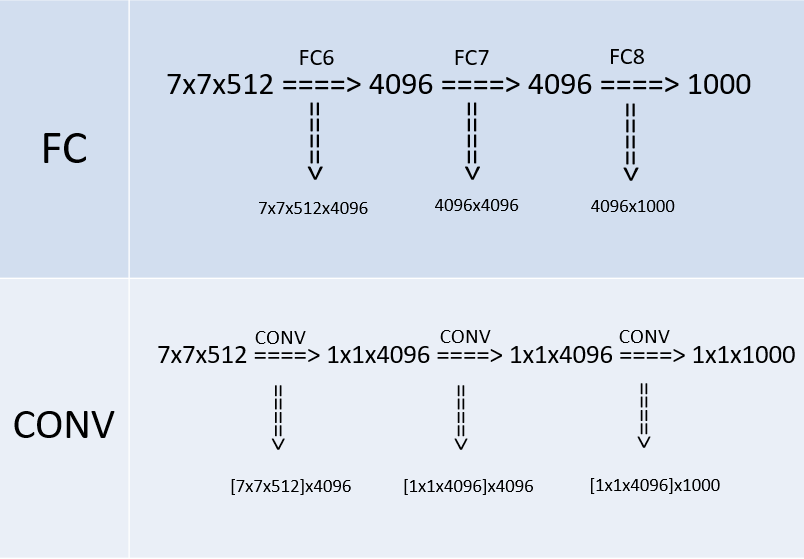
二者最明显的差异不外乎一个前者是局部连接,但其实二者都有用到全局信息,只是卷积是通过层层堆叠来利用的,而全连接就不用说了,全连接的方式直接将上一层的特征图全部用上,稀疏性比较大,而卷积从网络深度这一角度,基于输入到当前层这一过程逐级逐层榨取的方式利用全局信息。
4.7 1*1卷积
1*1在维度上继承全连接,然而作者首先认为1x1卷积可以增加决策函数的非线性能力,非线性是由激活函数ReLU决定的,本身1x1卷积则是线性映射,即将输入的feature map映射到同样维度的feature map。1x1根本不考虑单通道上像素的局部信息,专注于那一个卷积核内部通道的信息整合;对feature map的channel级别降维或升维:例如224x224x100的图像(或feature map)经过20个conv1x1的卷积核,得到224x224x20的feature map。尤其当卷积核(即filter)数量达到上百个时,3x3或5x5卷积的计算会非常耗时,所以1x1卷积在3x3或5x5卷积计算前先降低feature map的维度。
仅作为学习记录,侵删!
参考:VGG网络模型详解_陌上羽的博客-CSDN博客_vgg模型

