
- 1解决本地部署SD:No module ‘xformers‘. Proceeding without it._no module 'xformers'. proceeding without it.
- 2机器学习算法(3)之决策树算法
- 3解码策略
- 4【宠粉赠书】科研绘图神器:MATLAB科技绘图与数据分析
- 5数据结构 - 二叉树代码实现_创建二叉树的代码数据结构
- 6System.out cannot be resolved to a type问题解决方式(非版本问题)
- 7数媒大一下Java期末复习笔记_数字媒体技术学jav
- 8AUTOSAR 信息安全机制有哪些?_idsm
- 9大数据平台的SQL查询引擎有哪些_大数据查询引擎
- 10Zynq7000 系列FPGA模块化仪器
[论文阅读笔记31] Object-Centric Multiple Object Tracking (ICCV2023)
赞
踩
最近Object centric learning比较火, 其借助了心理学的概念, 旨在将注意力集中在图像或视频中的独立对象(objects)上,而不是整个图像。这个方法与传统的基于像素或区域的方法有所不同,它试图通过识别和分离图像中的各个对象来进行学习和理解。
这个任务和跟踪有着异曲同工之处,跟踪也是需要在时序中定位感兴趣的目标。那么object centric learning能否用于无监督的MOT呢?在应用的过程中,会不会有什么问题呢?这就是这篇文章的主要内容。
论文:论文
代码:代码
0. 摘要
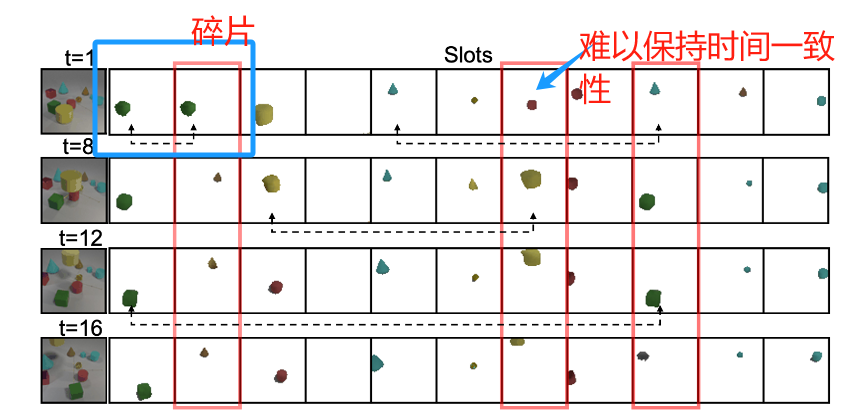
无监督的object-centric learning(OCL)可以将场景划分为多个object,而无需进行先验的定位(例如pretrain的detector)。这正好可以解决MOT标注信息繁多、困难的问题。然而,直接应用OCL的效果不好,主要有两个原因:
- 空间上,OCL没有正确认识整个物体的语义信息,导致物体往往被划分成了很多parts
- 时间上,OCL也无法准确地维护帧间连续性
所以,为了解决以上这两个问题,本文提出了以下的改进措施:
- 对于物体碎片化的问题,提出了一个index merge module,将OCL模块输出的slots中同属于一个object的几个碎片结合,变成准确的detection outputs。
- 对于时序连续性的问题,搞了一个memory module存储完整的object信息,来应对遮挡。
- 此外,还提出了一个EM算法指导的优化loss,从而实现完全的自监督。
上面讲的问题如Fig. 1中所示:
1. Related Work
我们先直接看Related Work。
1.1 无监督的OCL
与传统的网络学习整个图像的特征不同,OCL旨在从场景中直接学习目标的特征,换句话说,就是直接将输入的视觉信号(例如图像等)与object直接“绑定”在一起,这样比较符合人类的认知习惯。自然,无监督的OCL就是用无监督的方式来完成这一过程。
这样说有点抽象。我们以nips2020的文章Object-Centric Learning with Slot Attention为例。
插曲:Object-Centric Learning with Slot Attention
我们先来看DETR:DETR首先通过CNN backbone提取图像特征,然后将特征打成patch输入Transformer Encoder,随后在Decoder一端,我们输入可能代表目标的query,并与Encoder的输出作Cross attention,最后对每个query进行FFN,得到回归的边界框和类别等等。其实这就有一点object centric的意思在了,我们用一个预先的query来代表目标。
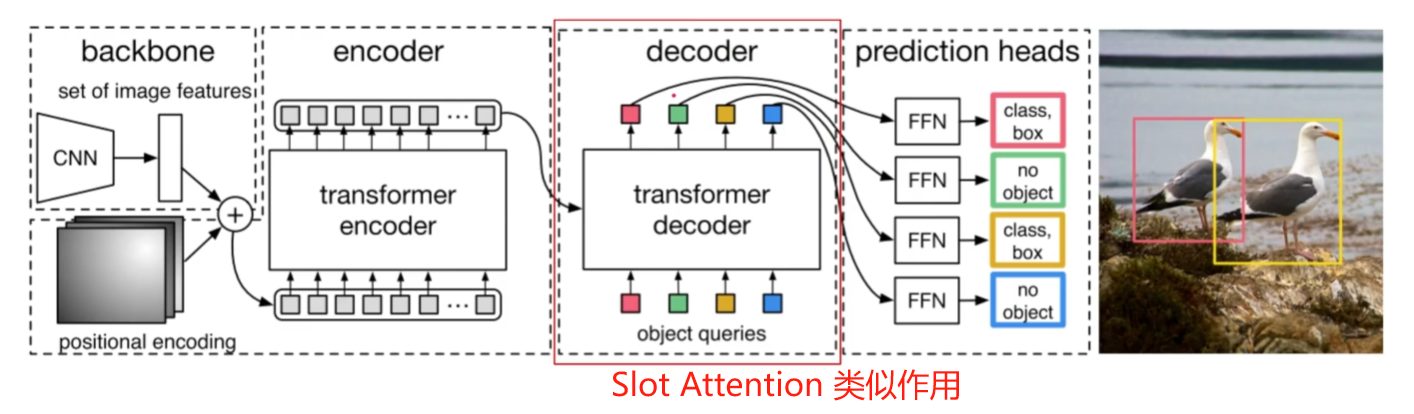
而Slot Attention,实际上发挥的作用和Decoder类似,就正如文章中所说: an architectural component that interfaces with perceptual representations such as the output of a convolutional neural network.
什么是Slot? 原文中说a set of task-dependent abstract representations which we call slots.,实际上就像一个未知的object的先验,和query类似。
Slot Attention的说明如下:

为什么要沿着slot维做softmax? softmax会将每个元素视为logits然后求概率,实际上可以让slots产生竞争(compete) 表达同一个input的part。
我有一个困惑,如果真的要达到竞争的效果,为什么只在1维上用softmax约束?应该让理想的attention matrix是分配矩阵的感觉才对,类似于:
[ 0 , 1 , 0 ] [ 0 , 0 , 1 ] [0, 1, 0] \\ [0, 0, 1] [0,1,0][0,0,1]
然后我在网上看到了一个网友的困惑,是否证明其实这种处理方式有可能直接让模型摆烂,输出同样的weight?
这个Slot Attention就是一个接口(interface),作者将其嵌入到Encoder-Decoder结构做了两个任务:1. 无监督的物体发现;2. 有监督的集合预测问题,如下图所示:
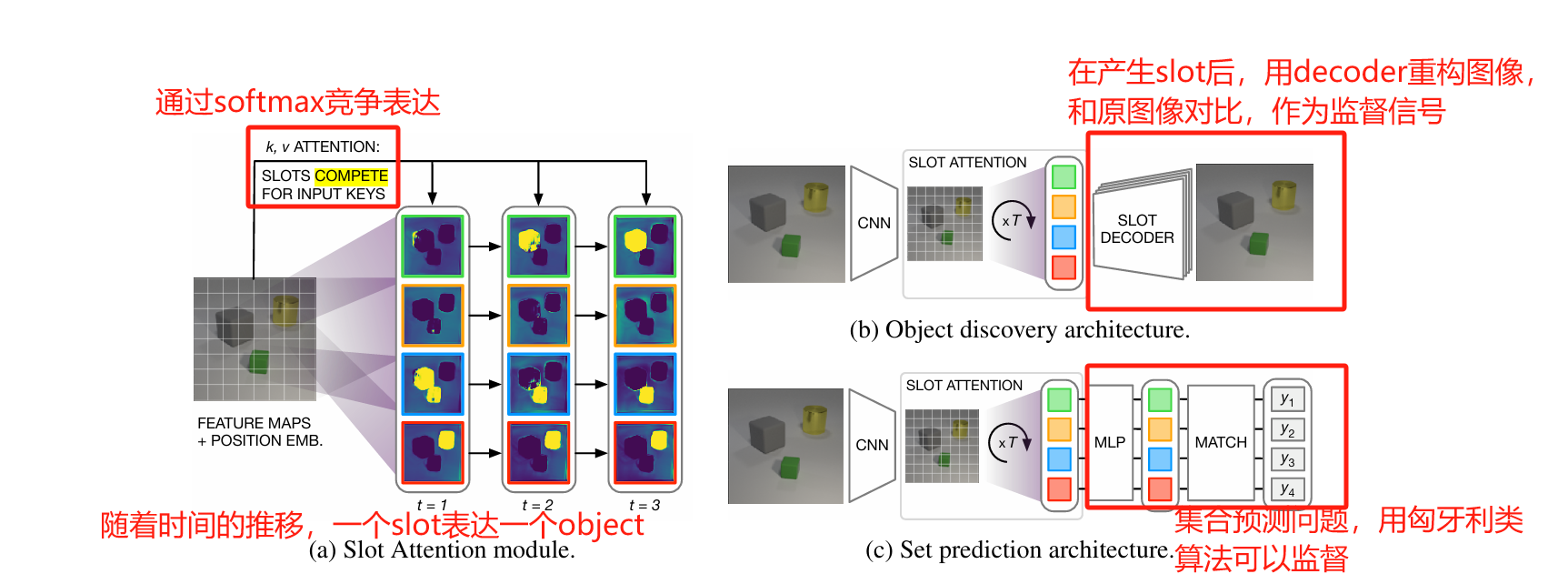
我们先只说object discovery任务。对于Encoder,采用位置编码增强的CNN backbone,并使用slot attention获得slot的embedding。对于Decoder,首先将每个slot广播成2D的,也通过位置编码增强。对于每个2D的slot,用CNN解码成
H
×
W
×
[
R
G
B
+
α
]
H \times W \times [RGB + \alpha]
H×W×[RGB+α]的张量,其中
α
\alpha
α表示这一块的mask,然后将若干个slot叠加,最理想的情况就是恢复出原图像的样子。
插曲结束
因此,我们初步对什么是OCL有了一个例子上的概念。回归到这篇MOT的文章上来,其实这篇文章想借助OCL对于object discovery的用处,对于摘要里提出的两个问题,通过object merge处理碎片,以及memory module进行时序信息传输,来改善其在MOT上的性能。
1.2 自监督MOT
为了减少手工标记注释,最近的一些方法利用自监督信号从广泛可用的未标记视频中学习关联。例如,CRW和JSTG通过应用cycle-consistent loss来学习视频对应关系。在没有微调的情况下,这些模型可以通过从第一帧传播注释来跟踪。
这篇工作还是类似于传统的TBD,也就是假定有一个好的detector了。
1.3 Memory Models
Memory的策略在动作识别等领域已经有了很广泛的应用了。在MOT中,也有一些工作,例如MeMOTR、MeMOT等等。但是,这些无一例外都是有监督的,仍然面临着ID标注昂贵的问题。
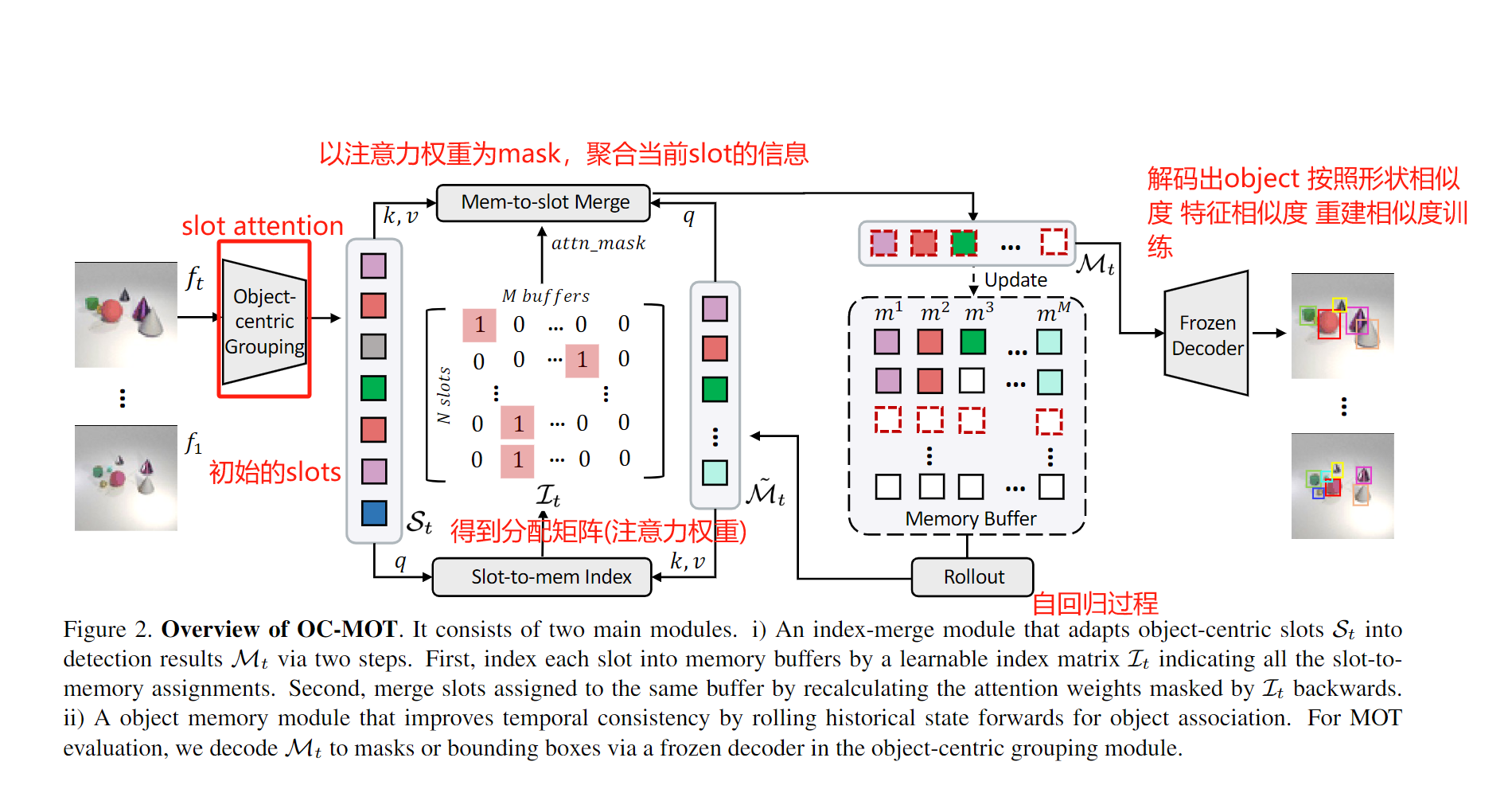
2. Method
整个模型由三部分组成,一个是类似于detector作用的Object-centric Grouping,其输入图像,输出对应的slots,这里作者直接采用了前面咱们介绍的Object-Centric Learning with Slot Attention,并且权重是frozen的,没有参与训练。
比较关键的点是Memory Module和Index Merge,前者用来传播帧间信息应对遮挡,后者用来将碎片化的slots对应成一个object。
2.1 Memory Module
对于 M M M个目标(轨迹), 存储时间长度为 T T T, 特征维度为 d d d, Memory buffer的维度是 M ∈ M × T × d \mathcal{M}\in M \times T\times d M∈M×T×d.
Memory rollout. 这个Buffer采用FIFO的策略, 在每一帧更新时, 预测当前的状态. rollout过程将多视图目标表示集成在一起, 并在遮挡场景中处理部分-整体匹配. (存疑.)
M ~ t = R o l l o u t ( M < t ) \tilde{\mathcal{M}}_t = Rollout(\mathcal{M}_{<t}) M~t=Rollout(M<t)
技术上, 作者用自回归模型GPT2-mini实现从历史状态到当前的预测.
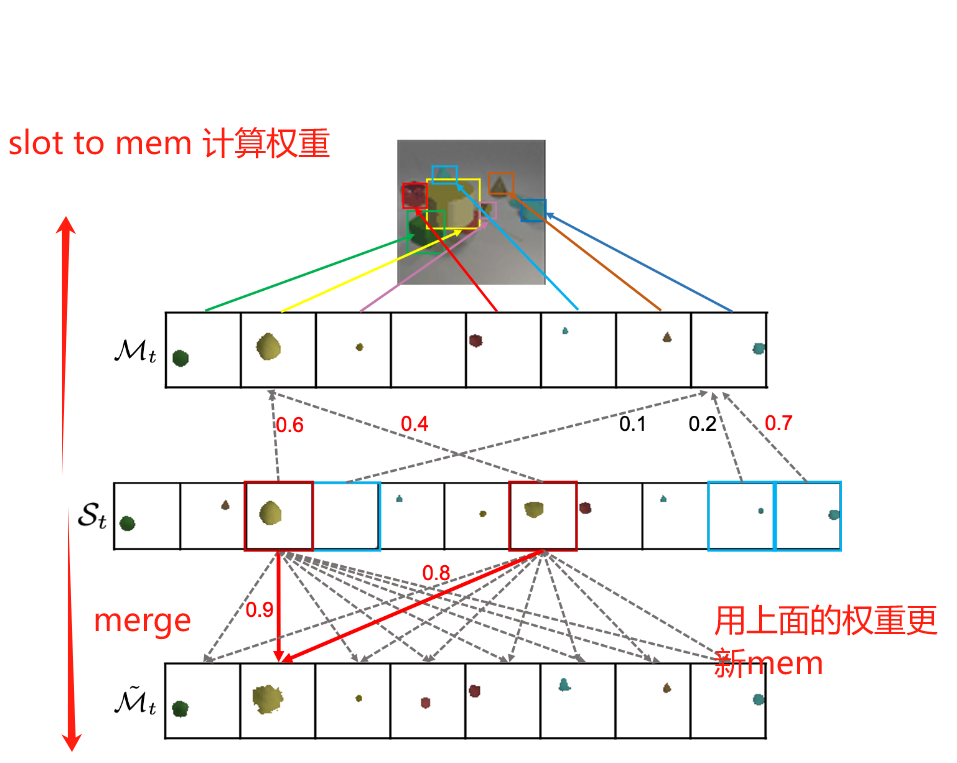
2.2 Index merge module
2.2.1 slot to memory
多个slots往往是同一个物体的多个碎片, 无法直接和memory buffer中的object一一对应起来. 为了解决这个问题, 我们需要预测出到底哪些slots是属于同一个物体的.
假设slots有 N N N个. 本质上, 要解决这个问题, 就是要计算一个 I ∈ N × M \mathcal{I} \in N \times M I∈N×M的映射. 作者直接让多头注意力的注意力分数矩阵充当了 I \mathcal{I} I的角色.
具体来说, 我们以slots为query, 以更新的 M ~ t \tilde{\mathcal{M}}_t M~t为key和value, 取多头注意力的注意力分数:
I t = MHA ( k , v = M ~ t , q = S t ) . a t t n w e i g h t \mathcal{I}_t=\operatorname{MHA}\left(k, v=\tilde{\mathcal{M}}_t, q=\mathcal{S}_t\right).attn weight It=MHA(k,v=M~t,q=St).attnweight
2.2.2 memory to slot
我们的目标是通过聚合属于同一个物体的slots来确保其表达buffer中的物体,同时处理哪些重复和表示parts的slots. 因此, 又用一个多头注意力模块, 以上面得到的 I t \mathcal{I}_t It为mask, 从而从buffer中聚合信息.
m t = MHA ( k , v = S t , q = M ~ t , a t t n m a s k = I t ) m_t=\operatorname{MHA}\left(k, v=\mathcal{S}_t, q=\tilde{\mathcal{M}}_t\right., attnmask \left.=\mathcal{I}_t\right) mt=MHA(k,v=St,q=M~t,attnmask=It)
实际上slot to memory和memory to slot就是把一次注意力计算分成了两步.
首先, 索引步, 计算哪些slot对应哪些buffer, 得到一个权重矩阵
之后, 聚合步, 为了用这个权重聚合特征, 作为一个强约束(attention weight) 来防止不正确的slot被聚合成一个. 作者举了一个例子:例如,如果有三个slot,其中两个与一个buffer匹配,注意力权重可以是 [0.8, 0.2, 0],表明第3个slot不属于这个buffer。
上面的流程如下图所示:
2.3 训练
训练的关键在于我们如何无监督地计算assignment损失.
我们有三种选择来计算分配成本:
- 在解码的掩码上使用二进制交叉熵损失来提高对象属性(如形状)的一致性
- 对对象重建(像素重建乘以对象掩模)使用逐像素平方的重建损失来学习颜色信息;
有点像Object-Centric Learning with Slot Attention - 使用与2)相同的损耗,但直接应用于特征空间。
L
assign
(
S
t
i
,
M
t
j
)
=
λ
1
B
C
E
Loss
(
Dec
(
S
t
i
)
,
Dec
(
M
t
j
)
)
+
λ
2
∥
Dec
(
S
t
i
)
−
Dec
(
M
t
j
)
∥
2
+
λ
3
∥
S
t
i
−
M
t
j
∥
2
其中 D e c Dec Dec表示解码器,估计结构和slot attention中的相似。
最终的loss为:
L = ∑ t = 1 T ∑ i = 1 N ∑ j = 1 M I t [ i , j ] L assign ( S t i , M t j ) \mathcal{L}=\sum_{t=1}^T \sum_{i=1}^N \sum_{j=1}^M \mathcal{I}_t[i, j] \mathcal{L}_{\text {assign }}\left(\mathcal{S}_t^i, \mathcal{M}_t^j\right) L=t=1∑Ti=1∑Nj=1∑MIt[i,j]Lassign (Sti,Mtj)
整个模型的流程如下图所示:
3. 实验
作者只用了比较少的标签,在CATER和fishbowl数据集上达到了比较好的效果

但是在更通用的数据集,比如KITTI,效果就一般了:

作者认为是分辨率下采样过大的原因。

