
- 1C++——STL算法_c++ stl算法
- 2tkinter打造三维绘图系统,附源代码_tkinter 3d
- 3VUE ELE-UI 最简单设置组件对话框_elvui聊天框底部信息栏
- 4CuteHttpFileSever使用指南_cute file
- 5idea远程debug调试_win的idea;连接liunx服务器debug测试
- 6Docker容器 || MySQL容器时间与宿主机同步
- 7我的“大学生创新创业训练项目”_大学生创新创业大赛小程序开发
- 8MySQL导入数据库1118错误解决方案[ERR] 1118 - Row size too large (> 8126). Changing some columns to TEXT or BLOB_[err] 1118 - row size too large (> 8126). changing
- 951单片机智能小车蓝牙_c51连接jdy31
- 10Redis哨兵模式搭建
一文讲透 Vision Transformer 网络_vision transformer网络结构
赞
踩
节前,我们组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、今年参加社招和校招面试的同学。
针对大模型& AIGC 技术趋势、大模型& AIGC 落地项目经验分享、新手如何入门算法岗、该如何准备面试攻略、面试常考点等热门话题进行了深入的讨论。
总结链接如下:
喜欢记得点赞、收藏、关注。更多技术交流&面经学习,可以文末加入我们。
论文名称:An Image Is Worth 16x16 Words: Transformers For Image Recognition At Scale 论文下载链接:https://arxiv.org/abs/2010.11929
原论文对应源码:https://github.com/google-research/vision_transformer
Pytorch实现代码:pytorch_classification/vision_transformer
Tensorflow2实现代码:tensorflow_classification/vision_transformer
在bilibili上的视频讲解:https://www.bilibili.com/video/BV1Jh411Y7WQ
目录
-
Vision Transformer模型详解
-
Embedding层结构详解
-
Transformer Encoder详解
-
MLP Head详解
-
自己绘制的Vision Transformer网络结构
-
Hybrid模型详解
前言
Transformer最初提出是针对NLP领域的,并且在NLP领域大获成功。这篇论文也是受到其启发,尝试将Transformer应用到CV领域。关于Transformer的部分理论之前的博文中有讲,链接,这里不再赘述。通过这篇文章的实验,给出的最佳模型在ImageNet1K上能够达到88.55%的准确率(先在Google自家的JFT数据集上进行了预训练),说明Transformer在CV领域确实是有效的,而且效果还挺惊人。

模型详解
在这篇文章中,作者主要拿ResNet、ViT(纯Transformer模型)以及Hybrid(卷积和Transformer混合模型)三个模型进行比较,所以本博文除了讲ViT模型外还会简单聊聊Hybrid模型。
Vision Transformer模型详解
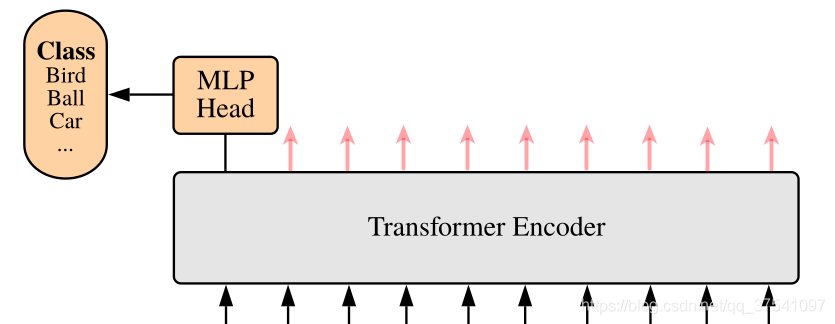
下图是原论文中给出的关于Vision Transformer(ViT)的模型框架。简单而言,模型由三个模块组成:
-
Linear Projection of Flattened Patches(Embedding层)
-
Transformer Encoder(图右侧有给出更加详细的结构)
-
MLP Head(最终用于分类的层结构)
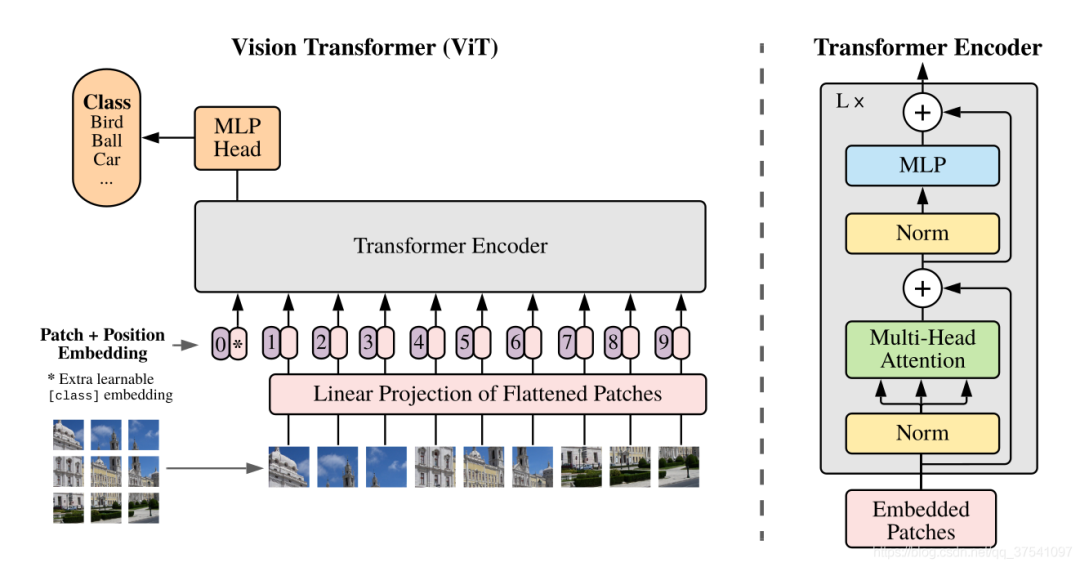
Embedding层结构详解
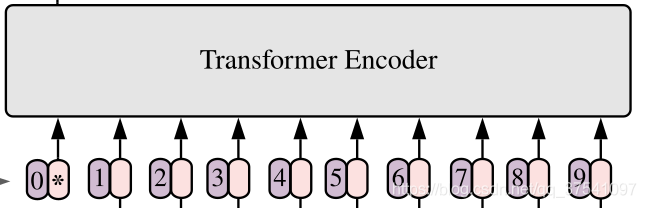
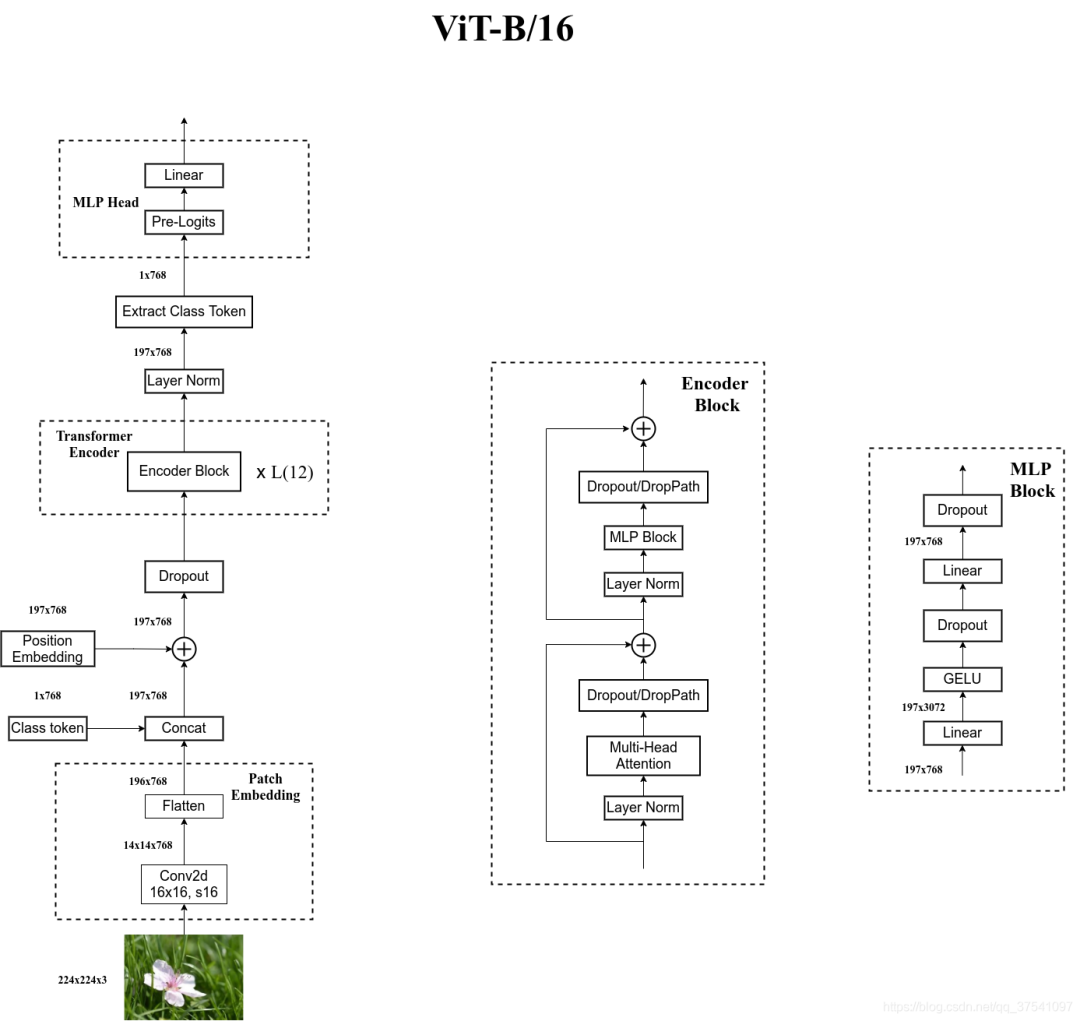
对于标准的Transformer模块,要求输入的是token(向量)序列,即二维矩阵[num_token, token_dim],如下图,token0-9对应的都是向量,以ViT-B/16为例,每个token向量长度为768。
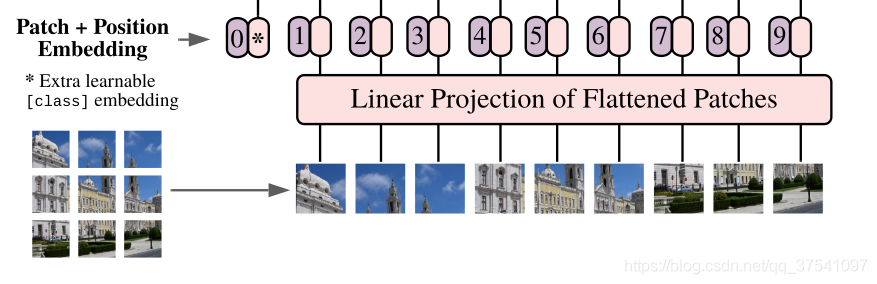
 对于图像数据而言,其数据格式为[H, W, C]是三维矩阵明显不是Transformer想要的。所以需要先通过一个Embedding层来对数据做个变换。如下图所示,首先将一张图片按给定大小分成一堆Patches。以ViT-B/16为例,将输入图片(224x224)按照16x16大小的Patch进行划分,划分后会得到个Patches。接着通过线性映射将每个Patch映射到一维向量中,以ViT-B/16为例,每个Patche数据shape为[16, 16, 3]通过映射得到一个长度为768的向量(后面都直接称为token)。
对于图像数据而言,其数据格式为[H, W, C]是三维矩阵明显不是Transformer想要的。所以需要先通过一个Embedding层来对数据做个变换。如下图所示,首先将一张图片按给定大小分成一堆Patches。以ViT-B/16为例,将输入图片(224x224)按照16x16大小的Patch进行划分,划分后会得到个Patches。接着通过线性映射将每个Patch映射到一维向量中,以ViT-B/16为例,每个Patche数据shape为[16, 16, 3]通过映射得到一个长度为768的向量(后面都直接称为token)。[16, 16, 3] -> [768]
在代码实现中,直接通过一个卷积层来实现。 以ViT-B/16为例,直接使用一个卷积核大小为16x16,步距为16,卷积核个数为768的卷积来实现。通过卷积[224, 224, 3] -> [14, 14, 768],然后把H以及W两个维度展平即可[14, 14, 768] -> [196, 768],此时正好变成了一个二维矩阵,正是Transformer想要的。
在输入Transformer Encoder之前注意需要加上[class]token以及Position Embedding。 在原论文中,作者说参考BERT,在刚刚得到的一堆tokens中插入一个专门用于分类的[class]token,这个[class]token是一个可训练的参数,数据格式和其他token一样都是一个向量,以ViT-B/16为例,就是一个长度为768的向量,与之前从图片中生成的tokens拼接在一起,Cat([1, 768], [196, 768]) -> [197, 768]。然后关于Position Embedding就是之前Transformer中讲到的Positional Encoding,这里的Position Embedding采用的是一个可训练的参数(1D Pos. Emb.),是直接叠加在tokens上的(add),所以shape要一样。以ViT-B/16为例,刚刚拼接[class]token后shape是[197, 768],那么这里的Position Embedding的shape也是[197, 768]。
对于Position Embedding作者也有做一系列对比试验,在源码中默认使用的是1D Pos. Emb.,对比不使用Position Embedding准确率提升了大概3个点,和2D Pos. Emb.比起来没太大差别。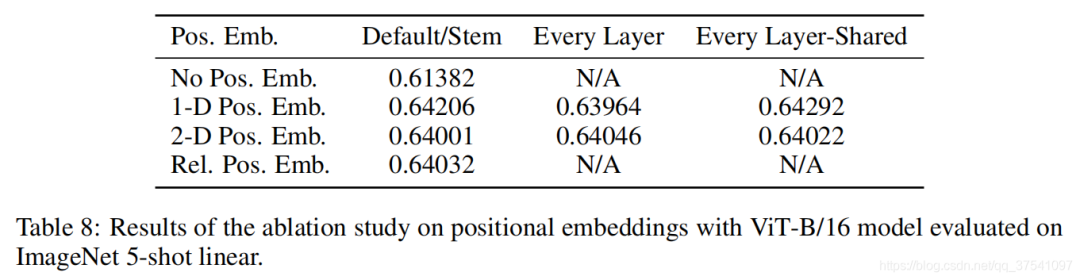
Transformer Encoder详解
Transformer Encoder其实就是重复堆叠Encoder Block L次,下图是我自己绘制的Encoder Block,主要由以下几部分组成:
-
Layer Norm,这种Normalization方法主要是针对NLP领域提出的,这里是对每个token进行Norm处理,之前也有讲过Layer Norm不懂的可以参考链接
-
Multi-Head Attention,这个结构之前在讲Transformer中很详细的讲过,不在赘述,不了解的可以参考链接
-
Dropout/DropPath,在原论文的代码中是直接使用的Dropout层,但在
rwightman实现的代码中使用的是DropPath(stochastic depth),可能后者会更好一点。 -
MLP Block,如图右侧所示,就是全连接+GELU激活函数+Dropout组成也非常简单,需要注意的是第一个全连接层会把输入节点个数翻4倍
[197, 768] -> [197, 3072],第二个全连接层会还原回原节点个数[197, 3072] -> [197, 768]

MLP Head详解
上面通过Transformer Encoder后输出的shape和输入的shape是保持不变的,以ViT-B/16为例,输入的是[197, 768]输出的还是[197, 768]。注意,在Transformer Encoder后其实还有一个Layer Norm没有画出来,后面有我自己画的ViT的模型可以看到详细结构。这里我们只是需要分类的信息,所以我们只需要提取出[class]token生成的对应结果就行,即[197, 768]中抽取出[class]token对应的[1, 768]。接着我们通过MLP Head得到我们最终的分类结果。MLP Head原论文中说在训练ImageNet21K时是由Linear+tanh激活函数+Linear组成。但是迁移到ImageNet1K上或者你自己的数据上时,只用一个Linear即可。
自己绘制的Vision Transformer网络结构
为了方便大家理解,我自己根据源代码画了张更详细的图(以ViT-B/16为例):
Hybrid模型详解
在论文4.1章节的Model Variants中有比较详细的讲到Hybrid混合模型,就是将传统CNN特征提取和Transformer进行结合。下图绘制的是以ResNet50作为特征提取器的混合模型,但这里的Resnet与之前讲的Resnet有些不同。首先这里的R50的卷积层采用的StdConv2d不是传统的Conv2d,然后将所有的BatchNorm层替换成GroupNorm层。在原Resnet50网络中,stage1重复堆叠3次,stage2重复堆叠4次,stage3重复堆叠6次,stage4重复堆叠3次,但在这里的R50中,把stage4中的3个Block移至stage3中,所以stage3中共重复堆叠9次。
通过R50 Backbone进行特征提取后,得到的特征矩阵shape是[14, 14, 1024],接着再输入Patch Embedding层,注意Patch Embedding中卷积层Conv2d的kernel_size和stride都变成了1,只是用来调整channel。后面的部分和前面ViT中讲的完全一样,就不再赘述。

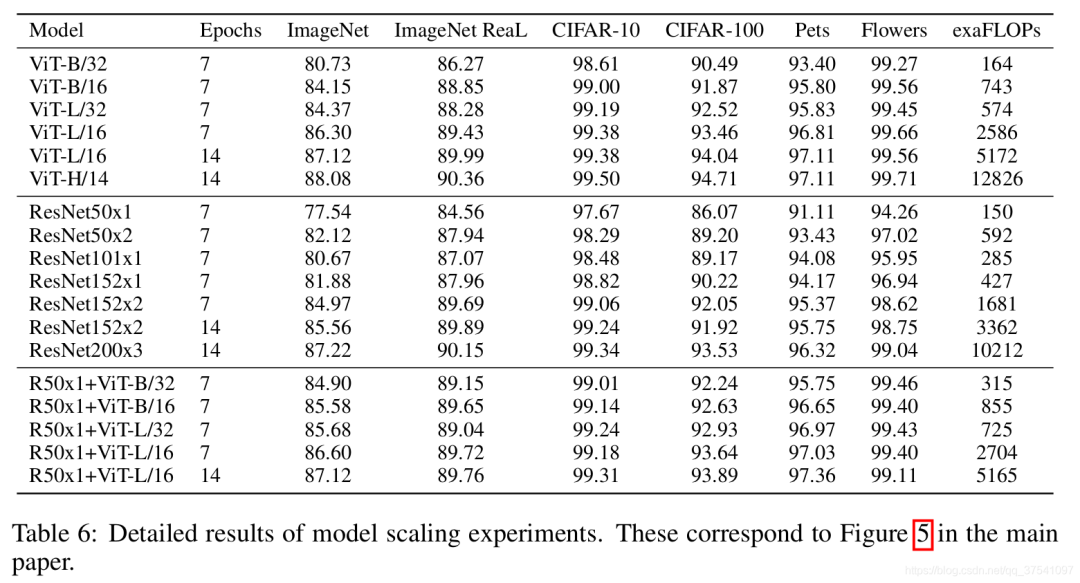
下表是论文用来对比ViT,Resnet(和刚刚讲的一样,使用的卷积层和Norm层都进行了修改)以及Hybrid模型的效果。通过对比发现,在训练epoch较少时Hybrid优于ViT,但当epoch增大后ViT优于Hybrid。
ViT模型搭建参数
在论文的Table1中有给出三个模型(Base/ Large/ Huge)的参数,在源码中除了有Patch Size为16x16的外还有32x32的。其中的Layers就是Transformer Encoder中重复堆叠Encoder Block的次数,Hidden Size就是对应通过Embedding层后每个token的dim(向量的长度),MLP size是Transformer Encoder中MLP Block第一个全连接的节点个数(是Hidden Size的四倍),Heads代表Transformer中Multi-Head Attention的heads数。
| Model | Patch Size | Layers | Hidden Size D | MLP size | Heads | Params |
|---|---|---|---|---|---|---|
| ViT-Base | 16x16 | 12 | 768 | 3072 | 12 | 86M |
| ViT-Large | 16x16 | 24 | 1024 | 4096 | 16 | 307M |
| ViT-Huge | 14x14 | 32 | 1280 | 5120 | 16 | 632M |
技术交流&资料
技术要学会分享、交流,不建议闭门造车。一个人可以走的很快、一堆人可以走的更远。
成立了算法面试和技术交流群,相关资料、技术交流&答疑,均可加我们的交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、微信搜索公众号:机器学习社区,后台回复:加群
方式②、添加微信号:mlc2040,备注:来自CSDN + 技术交流

