
热门标签
热门文章
- 1Vue 文件下载
- 2left join 和子查询效率_Calcite 子查询处理 - II (Decorrelate)
- 3ORACLE 集合运算
- 4Unit y读取Json的三种方法(JsonUtility,LitJson,Newtonsoft)
- 5昇思25天学习打卡营第2天 | 张量 Tensor
- 6Java的NIO体系
- 7华为OD-C卷D卷-音乐小说内容重复识别[200分][Python/C++/Java]两种解法实现(并查集+动态规划)_实现一个简易的重复内容识别系统,通过给定的两个内容名称,和相似内容符号,判断两
- 8制作原版电脑系统iso格式U盘启动教程_u盘iso启动
- 9git删除分支_git 删除分支
- 10python基于svm项目+课程设计报告_基于机器学习的脑电病理诊断
当前位置: article > 正文
多类型图像OCR:基于Dify的多模态Agent实现_dify 解析图片
作者:笔触狂放9 | 2024-06-29 19:04:26
赞
踩
dify 解析图片
大模型相关目录
大模型,包括部署微调prompt/Agent应用开发、知识库增强、数据库增强、知识图谱增强、自然语言处理、多模态等大模型应用开发内容
从0起步,扬帆起航。
- 大模型应用向开发路径:AI代理工作流
- 大模型应用开发实用开源项目汇总
- 大模型问答项目问答性能评估方法
- 大模型数据侧总结
- 大模型token等基本概念及参数和内存的关系
- 大模型应用开发-华为大模型生态规划
- 从零开始的LLaMA-Factory的指令增量微调
- 基于实体抽取-SMC-语义向量的大模型能力评估通用算法(附代码)
- 基于Langchain-chatchat的向量库构建及检索(附代码)
- 一文教你成为合格的Prompt工程师
- 最简明的大模型agent教程
- 批量使用API调用langchain-chatchat知识库能力
- langchin-chatchat部分开发笔记(持续更新)
- 文心一言、讯飞星火、GPT、通义千问等线上API调用示例
- 大模型RAG性能提升路径
- langchain的基本使用
- 结合基础模型的大模型多源信息应用开发
- COT:大模型的强化利器
- 多角色大模型问答性能提升策略(附代码)
- 大模型接入外部在线信息提升应用性能
- 从零开始的Dify大模型应用开发指南
- 基于dify开发的多模态大模型应用(附代码)
- 基于零一万物多模态大模型通过外接数据方案优化图像文字抽取系统
- 快速接入stable diffusion的文生图能力
- 多模态大模型通过外接数据方案实现电力智能巡检(设计方案)
- 大模型prompt实例:知识库信息质量校验模块
- 基于Dify的LLM-RAG多轮对话需求解决方案(附代码)
- Dify大模型开发技巧:约束大模型回答范围
- 以API形式调用Dify项目应用(附代码)
- 基于Dify的QA数据集构建(附代码)
- Qwen-2-7B和GLM-4-9B:大模型届的比亚迪秦L
- 文擎毕昇和Dify:大模型开发平台模式对比
- 多类型图像OCR:基于Dify的多模态Agent实现
背景
Agent 通常是一个智能软件实体,能够感知其环境,并根据这些感知做出决策和行动。它可能包括学习能力,以优化其未来的决策和行动。
当下Agent研究往往是针对于文本类型数据输入,对语义进行感知并决策,现在对图文多模态输入的Agent研究相对比较匮乏。
技术方案
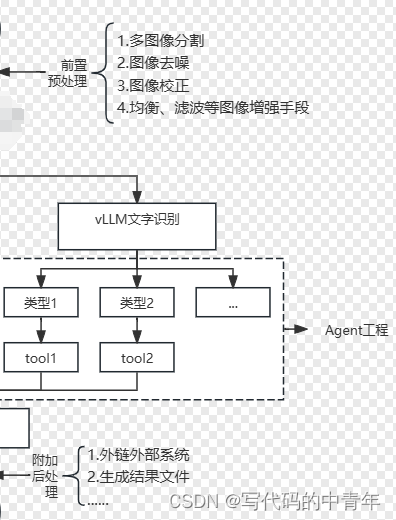
对不同类型图像进行识别时的解决方案。
- 主Agent负责对图像类型进行识别,并格式化输出。
- 子Agent负责对指定图像类型进行分析,被注入了一定的先验知识,如表格分析模型、铭牌分析模型等,并格式化输出。
技术架构图如下:
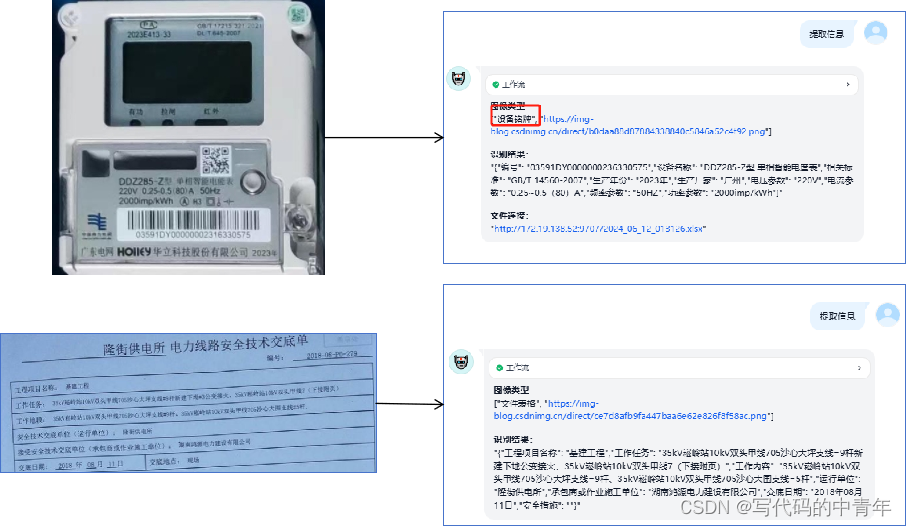
其中,工具使用效果如下:
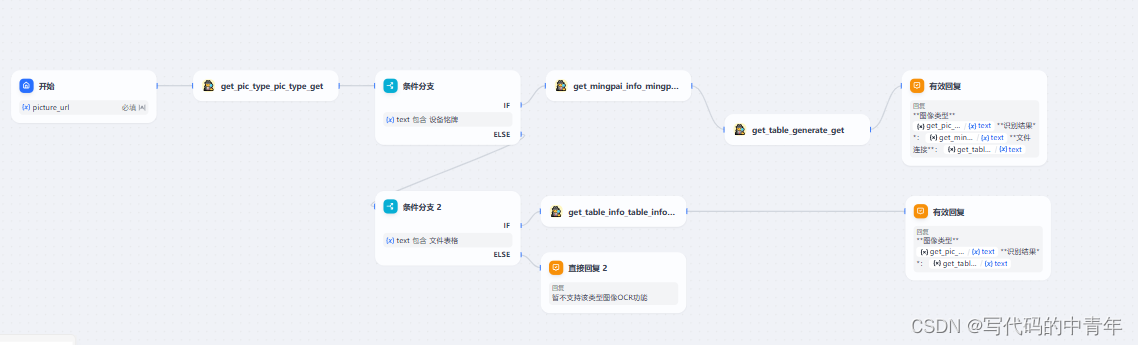
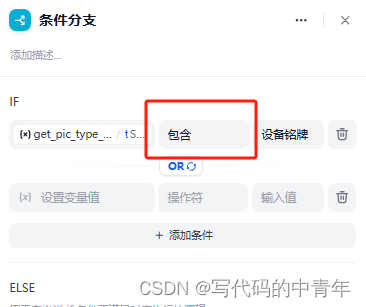
代码及Dify设计
from fastapi import FastAPI, HTTPException, Depends
from typing import List, Optional
import re
import json
import datetime
import pandas as pd
from pydantic import BaseModel
app = FastAPI()
def post_processing(input_data):
# 使用正则表达式匹配{}之间的内容
pattern = r'{(.*?)}'
match = re.search(pattern, input_data, re.DOTALL)
# 匹配后做数据后处理
if match:
match = '{' + match.group(1) + '}'
json_str = match.replace(': {\n ', ':null,').replace('\n', '').replace('},', ',').replace(':',':')
json_str = json_str.strip('"\"')
return json_str
else:
return str({'error':'llm out error!'})
@app.get("/pic_type")
def get_pic_type(url):
import openai
from openai import OpenAI
import re
API_BASE = "https://api.lingyiwanwu.com/v1"
API_KEY = "e6609f77a0fb40a290eb034535917144"
client = OpenAI(
# defaults to os.environ.get("OPENAI_API_KEY")
api_key=API_KEY,
base_url=API_BASE
)
prompt = '''
## 职位:你是一个图像类型判别小助手。
## 职能:你可以将图像分类为【设备铭牌、文件表格、其他】三个类型。其中,设备铭牌指包含设备类型、设备规范、设备厂家、编号、参数等信息的铭牌图像;文件表格指以表格形式存储信息的图像。
## 输出格式:你只能输出判断后得出的图像类型,不需要输出图像类型以外的信息。如:设备铭牌、文件表格、其他
'''
completion = client.chat.completions.create(
model="yi-vl-plus",
messages= [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": url
}
},
{
"type": "text",
"text": prompt
}
]
}
]
)
raw_result = completion.choices[0].message.content
print('LLM Respone:',raw_result)
# 定义正则表达式,匹配“设备铭牌”或“文件表格”
pattern = re.compile(r'设备铭牌|文件表格')
# 使用正则表达式搜索字符串
match = pattern.search(raw_result)
return match.group() if match else None,url
@app.get("/mingpai_info")
def get_mingpai_info(url):
import openai
from openai import OpenAI
import re
API_BASE = "https://api.lingyiwanwu.com/v1"
API_KEY = "e6609f77a0fb40a290eb034535917144"
client = OpenAI(
# defaults to os.environ.get("OPENAI_API_KEY")
api_key=API_KEY,
base_url=API_BASE
)
prompt = '''
## 职位:你是一个具备图像信息提取、信息规整的智能助手
## 职能:请提取图像中的文字、数字等文本内容,重点提取【提取下二维码下方的数字和字母组成的条形码编号】。
根据识别内容信息提取【设备名称】、【规约标准】、【电压参数】、【电流参数】、【频率参数】、【生产年份】、【生产公司】等内容。
提取后,返回格式参考如下:{
"编号":"09991DY00000009999999999",
"设备名称":"配电箱",
"相关标准":"GB12345.1-2099",
"生产年份":"2059年",
"生产厂家":"某某有限公司",
"电压参数":"110V",
"电流参数":"0.3A",
"频率参数":"80HZ"
"功率参数":“COSΦ=0.8滞后”
}
注意,提取不到时将提取内容标注“null”,且不要填入多余内容。
注意,我不需要任何代码,请输出json格式结果,json中不允许嵌套json。
'''
completion = client.chat.completions.create(
model="yi-vl-plus",
messages= [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": url
}
},
{
"type": "text",
"text": prompt
}
]
}
]
)
raw_result = completion.choices[0].message.content
print('LLM Respone:',raw_result)
return post_processing(raw_result)
@app.get("/table_info")
def get_table_info(url):
import openai
from openai import OpenAI
import re
API_BASE = "https://api.lingyiwanwu.com/v1"
API_KEY = "e6609f77a0fb40a290eb034535917144"
client = OpenAI(
# defaults to os.environ.get("OPENAI_API_KEY")
api_key=API_KEY,
base_url=API_BASE
)
prompt = '''
## 职位:你是一个具备表单图像信息提取、信息规整的智能助手
## 职能:请提取图像中的文字、数字等文本内容,注意图像是一个表格,你需要理解表格中的内容。
根据识别内容信息提取【工程项目名称】、【工作任务】、【工作内容】、【运行单位】、【承包商或作业施工单位】、【交底日期】、【安全措施】等内容。
提取后,返回格式参考如下:{
"工程项目名称":"某某项目",
"工作任务":"XXKv站XX任务",
"运行单位":"某某所",
"承包商或作业施工单位":"某某公司",
"交底日期":"2024年6月13日",
"安全措施":""
}
注意,提取不到时将提取内容标注“null”,且不要填入多余内容。
注意,我不需要任何代码,请输出json格式结果。
'''
completion = client.chat.completions.create(
model="yi-vl-plus",
messages= [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": url
}
},
{
"type": "text",
"text": prompt
}
]
}
]
)
raw_result = completion.choices[0].message.content
print('LLM Respone:',raw_result)
return post_processing(raw_result)
@app.get("/generate")
def get_table(input_str = Depends(post_processing)):
print(input_str)
# 将字符串转换为字典
data_dict = json.loads(input_str.replace('\\n','').replace('\\',''))
for k, v in data_dict.items():
if type(v) == list:
data_dict[k] = [' '.join(v)]
else:
data_dict[k] = [v]
print('##################','json')
df_json = pd.DataFrame(data_dict)
print(data_dict)
print('##################','df')
print(df_json)
'''
# 读取excel文件
df_excel = pd.read_excel('/home/gputest/lyq/py_file/result.xlsx', engine='openpyxl')
# 将json数据追加到excel的DataFrame中(这里简单地追加到末尾)
# 注意:你可能需要根据你的数据结构和需求调整这一步
df_excel = pd.concat([df_excel, df_json], ignore_index=True)
'''
# 保存修改后的excel文件
# 获取当下时间并format
formatted_time = str(datetime.datetime.now().strftime("%Y_%m_%d_%H%M%S"))
df_json.to_excel(formatted_time+'.xlsx', index=False, engine='openpyxl')
return 'http://172.19.138.52:9707/'+formatted_time+'.xlsx'
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="172.19.138.52", port=9706)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
需要强调的是,由于Dify不支持图像数据在工作流中的流通控制,因此本设计使用图像链接。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/笔触狂放9/article/detail/770073
推荐阅读
相关标签

