
- 1JavaScript——防抖与节流_nodejs 输入框 节流防抖
- 2奇异值分解与协同过滤:为推荐系统奠定基础
- 3【网络原理】HTTP|认识请求“报头“|Host|Content-Length|Content-Type|UA|Referer|Cookie_header头的ua
- 4用WebBrowser做web 打印时的权限不足。。。。
- 5linux查看zookeep进程,启动ZOOKEEPER之后能查看到进程存在但是查不到状态,是因为。。。...
- 6欢迎入坑单目深度估计
- 7K-近邻算法_k近邻算法,农民工看完都学会了_搜索k近邻算法时间复杂度
- 8道路堵塞监测识别摄像机
- 9Android studio ListView应用设计_android studio用listview编写页面
- 10Python3 基础数据类型-字符串(str)类型及操作_python3 str
机器学习_样本集
赞
踩
机器学习基本概念
什么是机器学习和深度学习
名词解释
-
样本集:一般就是一个表格数据 ,我们研究数据的集合,每一列就是样本的一条属性,每一行就是一个数据样本
-
样本标签:我们要研究的数据指标, 可能是数据的一条属性
-
训练集:从样本集中,拆分出来的一部分样本,样本个数多 8:2 9:1 7:3,用来训练算法模型的数据集合
-
测试集:从样本集中,拆分出来的一部分样本,样本个数少 8:2 9:1 7:3,用来测试模型学习效果的集合
-
算法模型:我们选择一个算法对象 .fit()训练的函数 .predidct()预测的函数
-
表示方法
- 样本集:samples train 标准的二维数组
训练集:X_train
测试集:X_test - 样本标签:target y
训练集标签:y_train
测试集标签:y_test - 预测结果:y_
- 样本集:samples train 标准的二维数组
-
有监督学习:样本集、测试集、训练集都有对应的标签
- 分类(预测男女):样本标签一般是离散值(A\B、红黄蓝、男\女)
- KNN Logistic SVC 决策树…
- 回归(房价预测):样本标签一般是连续值(1.2,1.5,1.8.2.3.2.6)在一个数据区间的任意取值
- LinearRegression、SVR、Ridge、Lasso
- 分类(预测男女):样本标签一般是离散值(A\B、红黄蓝、男\女)
-
无监督学习:样本集、测试集、训练集都没有有对应的标签
-
聚类 :KMeans
-
半监督学习:
-
深度学习
-
特征空间:由样本集的特征,展开的空间,称为特征空间。所有的样本都属于这个特征空间
-
过拟合:,当学习器把训练样本学得"太好"了的时候,很可能巳经把训练样本自身的一些特点当作了所有潜在样本都 会具有的一般性质,这样就会导致泛化性能下降这种现象在机器学习中称为
“过拟合” (overfitting).
-
欠拟合:对数据学习的太简陋,没有学习到共性特征,导致模型的泛化能力变弱。
-
经验误差:学习器的实际预测输出与样本的真实输出之间的差异称为"误差" (error), 学习器在训练集上的误差称为"训练误差" (training error) 或"经验误差" (empirical error)
-
泛化误差:在新样本上的误差称为"泛化误差" (generalization
error).
-
鲁棒性:Huber从稳健统计的角度系统地给出了鲁棒性3个层面的概念:
- 模型具有较高的精度或有效性,这也是对于机器学习中所有学习模型的基本要求;
- 对于模型假设出现的较小偏差,只能对算法性能产生较小的影响; 主要是:噪声(noise)
- 对于模型假设出现的较大偏差,不可对算法性能产生“灾难性”的影响;主要是:离群点(outlier)
k-近邻算法(kNN)
原理
简单地说,K-近邻算法采用测量不同特征值之间的距离方法进行分类。
- 优点:精度高、对异常值不敏感、无数据输入假定。
- 缺点:时间复杂度高、空间复杂度高。
- 适用数据范围:数值型和标称型。
k近邻(k Nearest eighbo ,简称 kNN )学习是一种常用的监督学习 方法, 其工作机制非常简单 给定测试样本,基于某种距离度量找出 练集中 与其最 靠近的k 个训练样本,然后基于这 个k"邻居 “的信息来进行预测 在分 类任务中可使用"投票法” 即选择这 k个样本中出现最多的类别标记作为预 测结果;在回归任务中时使用"平均法" ,即将 k个样本的实值输出标记 平均值作为预测结果;还可基于距离远近进行加权平均或加权投票,距离越近 的样本权重越大.
- 欧几里得距离(Euclidean Distance)
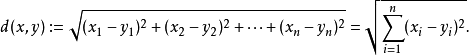
欧氏距离是最常见的距离度量,衡量的是多维空间中各个点之间的绝对距离。公式如下:
在scikit-learn库中使用k-近邻算法,用于分类
-
用途:对离散型的数据进行分类
-
分类问题:from sklearn.neighbors import KNeighborsClassifier
电影案例分析
#导包 import numpy as np import pandas as pd import matplotlib.pyplot as plt %matplotlib inline from pandas import Series,DataFrame #读取xlsx文件 train = pd.read_excel('film.xlsx')[0:9] ==> 电影名称 爱情 动作 电影类别 0 大话西游 3.0 9.0 动作 1 星语心愿 10.0 2.0 爱情 2 叶问 2.0 11.0 动作 3 黄飞鸿 2.0 9.0 动作 4 最好的我们 11.0 3.0 爱情 #删除不关联的特征 train.drop(labels=["电影名称"],axis=1, inplace=True) # 获取样本集和标签 # 标签 y = train["电影类别"] # 样本集 X = train[["爱情","动作"]] #绘制样本特征之间的散点图(图一) X1 = X[y == "动作"] X2 = X[y == "爱情"] plt.scatter(X1["爱情"],X1["动作"], label="ACTION FILM", color="green") plt.scatter(X2["爱情"],X2["动作"], label="LOVE FILM", color="black") plt.xlabel("LOVE") plt.ylabel("ACTION") plt.legend() # 1、构建一个算法模型,本案例适合分类模型 from sklearn.neighbors import KNeighborsClassifier,KNeighborsRegressor ## k必须是一个奇数 # 经验值:不要超过样本个数的平方根 knnclf = KNeighborsClassifier(n_neighbors=5) #2、训练模型 # 有监督学习的fit函数,都接收两个参数,X 样本集 应该保证 样本分布比较均匀,y 样本标签 knnclf.fit(X, y) #3、预测 #(1),对样本集(学习过的)预测 经验误差(回归模型) # (2),对未知(没学习过的)数据预测 泛化误差(回归模型) y_ = knnclf.predict(X) ==> array(['动作', '爱情', '动作', '动作', '爱情', '爱情', '动作', '爱情', '动作'], dtype=object) # 4、准确率 求得的是在训练集上的准确率 accuracy_rate = (y == y_).sum()/y.size #泛化数据的预测绘图(图二) # 【注意】要使用二维数组作为测试数据 X_test = np.array([[5,8],[11,5]]) plt.scatter(X_test[:,0], X_test[:,1], label="Predict", color="orange") plt.legend() # 预测函数中,只接收测试集,不接收标签 knnclf.predict(X_test) ==> array(['动作', '爱情'], dtype=object)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
图一

图二

系统现有数据:鸢尾花的品种分析
# 导入系统中的数据 from sklearn.datasets import load_iris #1、获取样本集和标签 iris = load_iris() data = iris.data target = iris.target target_names = iris.target_names feature_names = iris.feature_names df = DataFrame(data=data, columns=feature_names) df.shape ==>(150, 4) # 样本集 train = data # 样本标签 target = target #2、均匀的拆分训练集和测试集 from sklearn.model_selection import train_test_split # random_state 随机数种子 种子固定,随机数就固定 # 如果设定random_state,每一次分割的样本集都一样,这样可以横向比较不同算法的效果好坏 # 如果不设定random_state,每一次分割的样本集都不一样,这样可以多次训练和预测同一个模型,来查看该模型的综合效果 #封装函数得到训练集和测试集的平均得分 #准确率只能用在分类模型的评价上 def knn_score(k): # 记录测试机评分 scores = [] # 记录训练集的评分 scores1 = [] for _ in range(100): X_train,X_test,y_train,y_test = train_test_split(train, target, test_size=0.2) knn = KNeighborsClassifier(n_neighbors=k) # 训练集进行训练 knn.fit(X_train, y_train) # 测试集进行预测 y_ = knn.predict(X_test # 训练集进行预测 y1_ = knn.predict(X_train) scores.append((y_ == y_test).sum()/y_.size) scores1.append((y1_ == y_train).sum()/y1_.size) # print("测试集得分:%.3f, 训练集得分:%.3f"%(np.array(scores).mean(), np.array(scores1).mean())) return (np.array(scores).mean(), np.array(scores1).mean()) #3、测试不同的k值对平均值的影响 ks = np.arange(3,13,step=2) train_scores = [] test_scores = [] # 训练集得分和测试集得分越相近越好 for k in ks: print(k) train_s, test_s = knn_score(k) train_scores.append(train_s) test_scores.append(test_s) # 绘制k值和平均准确率的关系图(图三) # 根据图像,发现当k=3时候,经验误差和泛化误差最接近,说明此时算法模型表现最好 plt.plot(ks, np.array(train_scores),color="green", label="train_scores") plt.plot(ks, np.array(test_scores), color="black", label="test_scores") plt.legend()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
图三

定义KNN分类
# 获取样本空间所有点,绘出背景色 xmin, xmax = train[:,0].min(), train[:,0].max() ymin, ymax = train[:,1].min(), train[:,1].max() x = np.linspace(xmin, xmax, 100) y = np.linspace(ymin, ymax, 100) #使用meshgrid对一维数据升维,变为(100,100) xx, yy = np.meshgrid(x, y) X_test = np.concatenate((xx.reshape(-1,1), yy.reshape(-1,1)),axis=1) # 选择算法模型,进行训练 knn = KNeighborsClassifier(n_neighbors=3) knn.fit(train, target) #得到样本空间所有点的标签 y_ = knn.predict(X_test) #绘出分类图 from matplotlib.colors import ListedColormap plt.scatter(X_test[:,0], X_test[:,1],c = y_, cmap = ListedColormap(np.random.random(size=(3,3)))) plt.scatter(train[:,0], train[:,1], c = target, cmap=cmap)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20

- 总结:
- 样本集要拆分的均匀,不影响预测结果
- 模型应该多次预测取均值,更能说明模型的综合能力
- 经验误差和泛化误差应尽量接近,算法的泛化能力才更强
- 算法稳定性可以多次训练预测模型,看评分的标准方差,越小说明算法越稳定(受数据的影响波动不大)
KNN算法用于回归
- 用途:回归用于对趋势的预测
- 回归问题:from sklearn.neighbors import KNeighborsRegressor
- 用正弦函数作为分析案例
# 1、生成样本数据 X = np.linspace(0,2*np.pi,60) y = np.sin(X) #对标签加上适当的噪音 模拟现实数据 noise = np.random.random(size=30)*0.4 - 0.2 y[::2] += noise plt.scatter(X, y) # 2、生成测试数据的结果 from sklearn.neighbors import KNeighborsRegressor(解决回归问题) knn = KNeighborsRegressor() knn.fit(X.reshape(-1,1), y) X_test = np.linspace(0,np.pi*2,52) y_ = knn.predict(X_test.reshape(-1,1)) #3、绘制真实值和回归模型的分布图 plt.plot(X_test, y_, color="green",label="PREDICT") plt.scatter(X, y, color="black", label="TRUE") plt.legend() #4、使用不同的k值训练相同的数据,观察不同的结果 knn1 = KNeighborsRegressor(n_neighbors=1) knn2 = KNeighborsRegressor(n_neighbors=5) knn3 = KNeighborsRegressor(n_neighbors=15) X = X.reshape(-1,1) #分别训练 knn1.fit(X,y) knn2.fit(X,y) knn3.fit(X,y) #得到测试标签 X_test = X_test.reshape(-1,1) y1 = knn1.predict(X_test) y2 = knn2.predict(X_test) y3 = knn3.predict(X_test) #5、绘制三种k值的图像,进行比较 plt.figure(figsize=(16,4)) ax1 = plt.subplot(1,3,1) #k=1 ax1.set_title("K=1") plt.plot(X_test, y1, color="green", label="Predict") plt.scatter(X, y, color="black", label="TRUE") ax2 = plt.subplot(1,3,2) #k=5 ax2.set_title("K=5") plt.plot(X_test, y2, color="green", label="Predict") plt.scatter(X, y, color="black", label="TRUE") ax3 = plt.subplot(1,3,3) #k=15 ax3.set_title("K=15") plt.plot(X_test, y3, color="green", label="Predict") plt.scatter(X, y, color="black", label="TRUE") #结论:当k=5时经验误差和泛化误差都相对较小
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56


线性回归
- 先复习一下大学的函数的导数及运算
① C’=0(C为常数);
② (xn)’=nx(n-1) (n∈Q);
③ (sinx)’=cosx;
④ (cosx)’=-sinx;
⑤ (ex)’=ex;
⑥ (ax)’=axIna (ln为自然对数)
⑦ loga(x)’=(1/x)loga(e) - 导数的运算
①(u±v)’=u’±v’
②(uv)’=u’v+uv’
③(u/v)’=(u’v-uv’)/ v^2
④[u(v)]’=[u’(v)]*v’ (u(v)为复合函数f[g(x)]) - 最小二乘法(又称最小平方法)是一种数学优化技术。它通过最小化误差的平方和寻找数据的最佳函数匹配。利用最小二乘法可以简便地求得未知的数据,并使得这些求得的数据与实际数据之间误差的平方和为最小。最小二乘法还可用于曲线拟合。
注: xT 表示的是向量


- 矩阵的阶:一个m行n列的矩阵简称为mn矩阵,特别把一个nn的矩阵成为n阶正方阵,或者n阶矩阵
- 矩阵的秩:用初等行变换将矩阵A化为阶梯形矩阵, 则矩阵中非零行的个数就定义为这个矩阵的秩, 记为r(A)
- 满秩矩阵:满秩矩阵(non-singular matrix): 设A是n阶矩阵, 若r(A) = n, 则称A为满秩矩阵。但满秩不局限于n阶矩阵。若矩阵秩等于行数,称为行满秩;若矩阵秩等于列数,称为列满秩。既是行满秩又是列满秩则为n阶矩阵即n阶方阵。行满秩矩阵就是行向量线性无关,列满秩矩阵就是列向量线性无关;所以如果是方阵,行满秩矩阵与列满秩矩阵是等价的。满秩有行满秩和列满秩,既是行满秩又是列满秩的话就一定是是方阵
- 奇异矩阵:奇异矩阵是线性代数的概念,就是该矩阵的秩不是满秩。首先,看这个矩阵是不是方阵(即行数和列数相等的矩阵。若行数和列数不相等,那就谈不上奇异矩阵和非奇异矩阵)
#计算矩阵的秩
a = np.array([[3,3.5,2],[3.2,3.6,3],[6,7,4]])
np.linalg.matrix_rank(a)
- 1
- 2
- 3
- 矩阵求逆:AA-¹=A-¹A=E(单位矩阵)
- 逆矩阵的作用:逆矩阵是经常遇到的一个概念。教科书中讲解了逆矩阵的求法,但是没有说清楚为何需要逆矩阵,逆矩阵的意义是什么。逆矩阵可以类比成数字的倒数,比如数字5的倒数是1/5,矩阵A的“倒数”是A的逆矩阵。5*(1/5)=1, A*(A的逆矩阵) = I,I是单位矩阵。引入逆矩阵的原因之一是用来实现矩阵的除法。比如有矩阵X,A,B,其中XA = B,我们要求X矩阵的值。本能来说,我们只需要将B/A就可以得到X矩阵了。但是对于矩阵来说,不存在直接相除的概念。我们需要借助逆矩阵,间接实现矩阵的除法。具体的做法是等式两边在相同位置同时乘以矩阵A的逆矩阵,如下所示,XA*(A的逆矩阵)= B*(A的逆矩阵)。由于A*(A的逆矩阵) = I,即单位矩阵,任何矩阵乘以单位矩阵的结果都是其本身。所以,我们可以得到X = B*(A的逆矩阵)。
#numpy求逆矩阵
a_ = np.linalg.inv(a)
- 1
- 2
- 求算法的系数和截距
# 算法的系数
lr.coef_
# 截距
lr.intercept_
- 1
- 2
- 3
- 4
- 5
【普通线性回归求解过程】
- 求解的过程 f(x) = WX + b
- 普通线性回归、Ridge、Loasso又叫 狭义线性回归
- 确定一个估计函数 f(x) = WX
- 带入数据,构造一个损失函数cost (y-y’)**2
- 对损失函数求最优解 对w求导数等于0
- 如果有截距,就是用梯度下降法求最优解
普通线性回归LinearRegression(狭义线性回归
)
- 原理:分类的目标变量是标称型数据,而回归将会对连续型的数据做出预测。
- 适用场景:一般来说,只要我们觉得数据有线性关系,LinearRegression类是我们的首先。如果发现拟合或者预测的不好,再考虑用其他的线性回归库。如果是学习线性回归,推荐先从这个类开始第一步的研究。
接下来就以糖尿病数据做线性回归分析
import numpy as np import pandas as pd from pandas import Series,DataFrame import matplotlib.pyplot as plt %matplotlib inline #1、获取数据 from sklearn.datasets import load_diabetes diabetes = load_diabetes() # 样本集 data = diabetes.data # 样本标签 target = diabetes.target #简便写法(直接获取样本集和样本标签) # X, y = load_diabetes(return_X_y=True) #2、抽取训练数据和预测数据 #创建数学模型 from sklearn.linear_model import LinearRegression lr = LinearRegression() #分割样本集得到训练集合测试集 from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(data, target, test_size=0.2, random_state=1) #训练 lr.fit(X_train, y_train) #预测 y_ = lr.predict(X_test) #3、绘制残差图 # 一般使用损失来评价回归模型 # 可以使用残差直方图来观察数据的预测结果 errs = (y_ - y_test) plt.hist(errs, bins=10) # 4、线性回归和Knn回归算法比较(通过绘图) from sklearn.neighbors import KNeighborsRegressor #计算KNN算法误差 knn = KNeighborsRegressor() knn.fit(X_train, y_train) y1_ = knn.predict(X_test) errs1 = (y1_ - y_test) errs = (y_ - y_test) #绘图 plt.hist(errs, bins=10, label="Lieaner",alpha=0.5, color="y") plt.hist(errs1, bins=10, label="KNN",alpha=0.5, color="m") plt.legend() # 5、均方误差MSE来比较回归模型的好坏 from sklearn.metrics import mean_squared_error # mean_squared_error传入两个参数:真值和预测值 lr_score = mean_squared_error(y_test, y_) knn_score = mean_squared_error(y_test, y1_) # 误差越小越好 这里LR优于KNN print(lr_score, knn_score) ==> 2992.55768145 3957.18292135
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
LinearRegression残差图

KNN和LinearRegression比较

- 单独查看某一个特征对结果的影响
feature_names = diabetes.feature_names df = DataFrame(data=data, columns=feature_names) ==> age sex bmi bp s1 s2 s3 s4 s5 s6 0 0.038076 0.050680 0.061696 0.021872 -0.044223 -0.034821 -0.043401 -0.002592 0.019908 -0.017646 1 -0.001882 -0.044642 -0.051474 -0.026328 -0.008449 -0.019163 0.074412 -0.039493 -0.068330 -0.092204 #这里研究BMI(体重指数)对结果的影响 #1、获取数据 train = df["bmi"] target = target X_train, X_test, y_train, y_test = train_test_split(train, target, test_size=0.2) #2、抽取训练数据和预测数据(使用普通线性回归) lr = LinearRegression() #lr.fit(X_train.reshape(-1,1), y_train) #lr.predict(X_test.reshape(-1,1)) #训练全部样本 lr.fit(train.reshape(-1,1), target) #测试线性数据 X_test = np.linspace(train.min(), train.max(),100).reshape(-1,1) y_ = lr.predict(X_test) # 3、绘制真值和线性回归图 plt.scatter(train, target, color="black", alpha=0.5, label="True") plt.plot(X_test, y_, color="green", label="Predict") plt.legend() plt.xlabel("BMI") plt.ylabel("Target")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28

岭回归Ridge:L2正则项
- 原理:缩减系数来“理解”数据
如果数据的特征比样本点还多应该怎么办?是否还可以使用线性回归和之前的方法来做预测?
答案是否定的,即不能再使用前面介绍的方法。这是因为输入数据的矩阵X不是满秩矩阵。非满秩矩阵在求逆时会出现问题。
为了解决这个问题,统计学家引入了岭回归(ridge regression)的概念

- 优点:缩减方法可以去掉不重要的参数,因此能更好地理解数据。此外,与简单的线性回归相比,缩减法能取得更好的预测效果
- 岭回归是加了二阶正则项的最小二乘,主要适用于过拟合严重或各变量之间存在多重共线性的时候,岭回归是有bias的,这里的bias是为了让variance更小。
- 缺点:这个类最大的缺点是每次我们要自己指定一个超参数α,然后自己评估α的好坏,比较麻烦
- 总结:
1.岭回归可以解决特征数量比样本量多的问题
2.岭回归作为一种缩减算法可以判断哪些特征重要或者不重要,有点类似于降维的效果
3.缩减算法可以看作是对一个模型增加偏差的同时减少方差 - 使用场景:
1.数据点少于变量个数
2.变量间存在共线性(最小二乘回归得到的系数不稳定,方差很大)
3.应用场景就是处理高度相关的数据 - 参数alpha对系数的影响
from sklearn.linear_model import Ridge # 1、存储每一个alpha训练出来的每一组系数 alphas = np.logspace(-10,-2,100,endpoint=False) coefs = [] ridge = Ridge() for alpha in alphas: ridge.set_params(alpha=alpha) ridge.fit(X,y) #coef_函数可以获取机器学习模型中各个特征值的系数 coef = ridge.coef_ coefs.append(coef) #2、绘制alpha和coefs的关系图 plt.figure(figsize=(10,6)) plt.plot(alphas, coefs) plt.xscale("log") plt.xlabel("ALPHA") plt.ylabel("COEFS")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18

- 结论:
- alpha值的选择如果太大:无限趋向于0,算法没有意义
- 如果太小:系数波动太大,算法不稳定
- 应该选择在0左右,比较稳定的区间
lasso回归:L1正则项
- 原理:与岭回归类似,它也是通过增加惩罚函数来判断、消除特征间的共线性。
【拉格朗日乘数法】

在lambda足够小的时候,一些系数会因此被迫缩减到0
一般来说,对于高维的特征数据,尤其线性关系是稀疏的,我们会采用Lasso回归。或者是要在一堆特征里面找出主要的特征,那么Lasso回归更是首选了。但是Lasso类需要自己对α调优,所以不是Lasso回归的首选,一般用到的是下一节要讲的LassoCV类。
对比各个算法的训练数据系数coef
#使用numpy创建数据X,创建系数,对系数进行处理,对部分系数进行归零化操作,然后根据系数进行矩阵操作求得目标值 # 1、获取数据 #样本数 n_samples = 50 #特征数 n_featrues = 200 X = np.random.random(size=(n_samples, n_featrues)) #系数 w = np.random.random(size=200) # 在200个系数中,随机选择一些有效系数,而其他系数就清零 index = np.random.permutation(200) idx = index[10:] w[idx] = 0 #样本标签 y = np.dot(X,w) # 2、训练数据和测试数据 lr = LinearRegression() ridge = Ridge(alpha=6) lasso = Lasso(alpha=0.0001) lr.fit(X,y) ridge.fit(X,y) lasso.fit(X,y) #3、数据视图,此处获取各个算法的训练数据的coef_:系数 coefs = [w, lr.coef_, ridge.coef_, lasso.coef_] models = ["True","Linear","Ridge", "Lasso"] plt.figure(figsize=(12,8)) loc = 1 for coef, model in zip(coefs, models): ax = plt.subplot(2,2,loc) loc += 1 ax.set_title(model) ax.plot(coef, color=np.random.random(size=3))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35

波士顿房价的影响因素分析
import numpy as np import pandas as pd from pandas import Series,DataFrame import matplotlib.pyplot as plt %matplotlib inline from sklearn.datasets import load_boston #导入数据 boston = load_boston() data = boston.data target = boston.target feature_names = boston.feature_names df = DataFrame(data=data, columns=feature_names) df.head() ==> CRIM ZN INDUS CHAS NOX RM AGE DIS RAD TAX PTRATIO B LSTAT 0 0.00632 18.0 2.31 0.0 0.538 6.575 65.2 4.0900 1.0 296.0 15.3 396.90 4.98 1 0.02731 0.0 7.07 0.0 0.469 6.421 78.9 4.9671 2.0 242.0 17.8 396.90 9.14 2 0.02729 0.0 7.07 0.0 0.469 7.185 61.1 4.9671 2.0 242.0 17.8 392.83 4.03 #分割训练数据和测试数据 from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(data, target, test_size=0.2) from sklearn.linear_model import LinearRegression, Ridge, Lasso from sklearn.neighbors import KNeighborsRegressor from sklearn.metrics import mean_squared_error #封装函数多次查看模型的均方误差的平均值、 def model_mse(model): X_train, X_test, y_train, y_test = train_test_split(data, target, test_size=2) model.fit(X_train, y_train) #测试误差 test_err = mean_squared_error(y_test, model.predict(X_test)) #训练误差 train_err = mean_squared_error(y_train, model.predict(X_train)) return test_err, train_err #计算100次训练的平均误差 def ave_err(model): ridge = model test_errs = [] train_errs = [] for i in range(100): ret = model_mse(ridge) test_errs.append(ret[0]) train_errs.append(ret[1]) print("经验误差:%.2f, 泛化误差:%.2f"%(np.array(train_errs).mean(), np.array(test_errs).mean())) return np.array(train_errs).mean(), np.array(test_errs).mean() #岭回归 r = Ridge(alpha=3) ave_err(r) ==>经验误差:22.33, 泛化误差:21.88 # KNN回归 knn = KNeighborsRegressor() ave_err(knn) ==>经验误差:23.92, 泛化误差:41.64 #普通线性回归 lr = LinearRegression() ave_err(lr) ==>经验误差:21.89, 泛化误差:24.97 #劳斯回归 lasso = Lasso() ave_err(lasso) ==>lasso = Lasso() ave_err(lasso) lasso = Lasso() ave_err(lasso) 经验误差:26.82, 泛化误差:23.35 #以上可以看出【岭回归】更适合 # 算法调参 alphas = [0.1,0.5,1,3,5,10,20] errs_train = [] errs_test = [] for alpha in alphas: ridge = Ridge(alpha=alpha) print("alphe = {}".format(alpha)) train_err, test_err = ave_err(ridge) errs_train.append(train_err) errs_test.append(test_err) ==> alphe = 0.1 经验误差:21.54, 泛化误差:24.49 alphe = 0.5 经验误差:21.86, 泛化误差:23.73 alphe = 1 经验误差:21.66, 泛化误差:24.99 alphe = 3 经验误差:22.31, 泛化误差:23.91 alphe = 5 经验误差:22.28, 泛化误差:24.80 alphe = 10 经验误差:22.46, 泛化误差:24.95 alphe = 20 经验误差:22.59, 泛化误差:25.34 plt.plot(alphas, errs_train, lab # 绘制误差随着alpha参数的变化曲线 plt.plot(alphas, errs_train, label = "train err", color="green") plt.plot(alphas, errs_test, label = "test err", color="black") plt.legend()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98

鲍鱼年龄预测
# 需求: 找出预测鲍鱼年龄的最佳算法并且对该算法进行调参 import numpy as np import pandas as pd from pandas import Series,DataFrame import matplotlib.pyplot as plt %matplotlib inline # 1、获取样本集和样本标签 abalone = pd.read_csv('abalone.txt',sep='\t',header=None) #样本集 train = abalone.loc[:,0:7] #样本标签 target = abalone[8] #查看数据信息 abalone.shape abalone.describe() abalone.info() target.unique() #分析数据的出此问题是线性回归问题 #选择线性回归模型并计算各个模型的均方误差进行比较 from sklearn.linear_model import LinearRegression, Ridge, Lasso from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error #1.封装函数进行算法比较 # 算法选择 def model_err(model): test_errs = [] train_errs = [] for i in range(10): X_train, X_test, y_train, y_test = train_test_split(train, target, test_size=0.2) model.fit(X_train, y_train) test_err = mean_squared_error(y_test, model.predict(X_test)) train_err = mean_squared_error(y_train, model.predict(X_train)) test_errs.append(test_err) train_errs.append(train_err) return np.array(test_errs).mean(), np.array(train_errs).mean() # 普通线性回归 model_err(LinearRegression()) ==> (4.9641990160053613, 4.9089488125375809) #岭回归 model_err(Ridge()) ==> (5.090121386322342, 4.9100259881458825) #劳斯回归 model_err(Lasso()) ==> model_err(Lasso()) model_err(Lasso()) (10.622280956132659, 10.336404736630442) # 比较得出结论是岭回归更适合本案例 #算法调参 alphas = [0.01,0.1,0.5,1,5,10,20] scores = [] for alpha in alphas: print(alpha) ret = model_err(Ridge(alpha)) print(ret) scores.append(ret) # 输出: 0.01 (5.1080538554670927, 4.8729995681285576) 0.1 (4.8897627039365057, 4.9249588207976505) 0.5 (4.8169160074321971, 4.9540618322712948) 1 (4.9492730109636707, 4.9498008656545007) 5 (5.2331466011422245, 5.1528772161011691) 10 (5.3599074433072493, 5.4905686777767198) 20 (5.6709909649979746, 5.9452603681400786) #绘制均方误差统计图 lines = plt.plot(alphas, scores) #测试误差 lines[0].set_color("red") #训练误差 lines[1].set_color("blue") plt.legend(["test errs","train errs"]) #结论: 参数在0-2.5 之间均方误差较小,并且经验误差和泛化误差较接近 回归模型为:Ridge(1.5)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86

梯度下降最优解
首先理解什么是梯度?通俗来说,梯度就是表示某一函数在该点处的方向导数沿着该方向取得较大值,即函数在当前位置的导数。

其中,θo是自变量参数,即下山位置坐标,η是学习因子,即下山每次前进的一小步(步进长度),θ是更新后的θo,即下山移动一小步之后的位置。
一阶泰勒展开式
这里需要一点数学基础,对泰勒展开式有些了解。简单地来说,一阶泰勒展开式利用的就是函数的局部线性近似这个概念。我们以一阶泰勒展开式为例:

凸函数f(θ)的某一小段[θo,θ]由上图黑色曲线表示,可以利用线性近似的思想求出f(θ)的值,如上图红色直线。该直线的斜率等于f(θ)在θo处的导数。则根据直线方程,很容易得到f(θ)的近似表达式为:
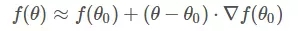
这就是一阶泰勒展开式的推导过程,主要利用的数学思想就是曲线函数的线性拟合近似。
梯度下降数学原理

想要两个向量的乘积小于零,我们先来看一下两个向量乘积包含哪几种情况:
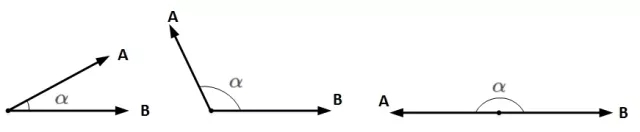
A和B均为向量,α为两个向量之间的夹角。A和B的乘积为:

- 计算二次函数的梯度最优解
import numpy as np import pandas as pd from pandas import Series,DataFrame import matplotlib.pyplot as plt %matplotlib inline # 1、假设这里是某一个线性回归模型的损失函数 # x就是线性回归方程当中的w # 我们要做的就是在这个损失函数中,找到那个使得整个函数的取值最小的x点 f = lambda x: (x-4.5)**2 + 7.5*x + 6 # 因为梯度就是导数,所以求出该损失函数的导数函数,就可以用这个函数求出每一个点的导数了 g = lambda x : 2*x -1.5 #2、求最优解 # 精度达到要求,可以结束 precision = 0.00001 # 次数达到某一个值,也可以结束 max_count = 3000 # 步长 step = 0.1 # 记录当前的迭代次数 count = 0 # 生成一个随机的起始下降的点,要在这个点上找到当前的梯度 v_min = np.random.randint(-4,10,size=1)[0] print("随机一个起始梯度下降的点:",v_min) #用于记录上一次的点 v_min_last = v_min + 1 points = [] while True: count += 1 if count > max_count: break if np.abs(v_min - v_min_last) < precision: break v_min_last = v_min # 梯度下降的公式 v_min = v_min - g(v_min)*step points.append(v_min) print("---当前梯度最优解是",v_min) #绘制出求解过程 x = np.linspace(-4,10,30) plt.figure(figsize=(24,6)) plt.plot(x, f(x)) #最优点 plt.scatter(v_min, f(v_min), color="red", s= 90) #求解过程点 plt.scatter(points, f(np.array(points)), marker="x", color="green")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47

Logistic回归模型(广义线性回归模型 )
- 什么是逻辑斯蒂函数?


- 原理
利用Logistics回归进行分类的主要思想是:根据现有数据对分类边界线建立回归公式,以此进行分类。这里的“回归” 一词源于最佳拟合,表示要找到最佳拟合参数集
Logistic Regression和Linear Regression的原理是相似的,可以简单的描述为这样的过程- 找一个合适的预测函数,一般表示为h函数,该函数就是我们需要找的分类函数,它用来预测输入数据的判断结果。这个过程是非常关键的,需要对数据有一定的了解或分析,知道或者猜测预测函数的“大概”形式,比如是线性函数还是非线性函数
- 构造一个Cost函数(损失函数),该函数表示预测的输出(h)与训练数据类别(y)之间的偏差,可以是二者之间的差(h-y)或者是其他的形式。综合考虑所有训练数据的“损失”,将Cost求和或者求平均,记为J(θ)函数,表示所有训练数据预测值与实际类别的偏差
- 显然,J(θ)函数的值越小表示预测函数越准确(即h函数越准确),所以这一步需要做的是找到J(θ)函数的最小值。找函数的最小值有不同的方法,Logistic Regression实现时有梯度下降法(Gradient Descent)




- 优缺点
实现简单,易于理解和实现;计算代价不高,速度很快,存储资源低
容易欠拟合,分类精度可能不高
手写数字识别案例
import numpy as np import pandas as pd from pandas import Series,DataFrame import matplotlib.pyplot as plt %matplotlib inline # 图像识别问题 from sklearn.datasets import load_digits #1、获取数据 digits = load_digits() data = digits.data images = digits.images target = digits.target # 每一张图片看成一个数据样本 # 每一张图片的像素点就是一个样本的所有特征 data.shape ==>(1797, 64) images.shape ==>(1797, 8, 8) #可以看出来data数据是image数据的降维形式 #2、训练和测试 # 罗杰斯迪克模型 from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split lr = LogisticRegression() X_train, X_test, y_train, y_test = train_test_split(data,target, test_size=0.2) lr.fit(X_train, y_train) lr.score(X_test, y_test) ==>0.96111111111111114 lr.score(X_train, y_train) ==>0.99443284620737649 #KNN模型 from sklearn.neighbors import KNeighborsClassifier knn = KNeighborsClassifier() knn.fit(X_train, y_train) knn.score(X_test, y_test) ==>0.98333333333333328 knn.score(X_train, y_train) ==>0.99234516353514268 # 3、把预测的真实图像绘制出来,把两种模型的预测结果作为标题展示 knn_y_ = knn.predict(X_test) lr_y_ = lr.predict(X_test) plt.figure(figsize=(50,50)) loc = 1 for i in range(100): ax = plt.subplot(10,10,loc+i) true = y_test[i] knn_res = knn_y_[i] lr_res = lr_y_[i] img_data = X_test[i] ax.imshow(img_data.reshape(8,8), cmap="binary") ax.axis("off") ax.set_title("K:{}L:{}T:{}".format(knn_res, lr_res, true))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49

- predict_proba函数的使用
X = np.array([[1,2,3],[1,3,6],[3,4,7],[5,6,8],[7,6,4],[1,5,9]]) y = np.array([1,0,1,1,0,0]) #训练 lr = LogisticRegression() lr.fit(X, y) lr.predict(X) ==>array([0, 1, 1, 0, 0, 0]) # 正负样本的概率 默认的阈值0.5 res = lr.predict_proba(X) ==> array([[ 0.51241004, 0.48758996], [ 0.49779742, 0.50220258], [ 0.44242638, 0.55757362], [ 0.5006232 , 0.4993768 ], [ 0.54528378, 0.45471622], [ 0.59605453, 0.40394547]]) res.sum(axis=1) ==>array([ 1., 1., 1., 1., 1., 1.]) #改变正负样本的阈值,来改变样本输出结果 (res[:,0] < 0.4).astype(np.uint8) ==> array([0, 0, 0, 0, 0, 0], dtype=uint8)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
人脸自动补全
#1、导包 from sklearn.datasets import fetch_olivetti_faces import matplotlib.pyplot as plt %matplotlib inline #2、读取数据 faces = fetch_olivetti_faces() data = faces.data data.shape ==>(400, 4096) images = faces.images images.shape ==>(400, 64, 64) target = faces.target #训练集 40个人,每人10张照片, 每个人提供9张照片用作训练集,1张作为测试集 # X_train = 上半张脸(集合)(每个人都应该提供一些照片用于训练) # y_train = 下半张脸(集合) #循环获取样本数据和样本标签 X_train = [] X_test = [] y_train = [] y_test = [] index = 0 for i in range(40): for j in range(10): face_data = data[index] upper_face = face_data[:2048] bottom_face = face_data[2048:] if j<9: # 记录训练集 X_train.append(upper_face) y_train.append(bottom_face) else: # 记录测试集 X_test.append(upper_face) y_test.append(bottom_face) index += 1 #3、 训练模型 from sklearn.linear_model import LinearRegression, Ridge, Lasso from sklearn.neighbors import KNeighborsRegressor import numpy as np lr = LinearRegression() ridge = Ridge(alpha=5) lasso = Lasso() knn = KNeighborsRegressor() # 样本集一般是二维的数组,但是也有可能是一列 # 样本标签一般是一列或一行,但是也有可能是一个二维数组 lr.fit(X_train, y_train) ridge.fit(X_train, y_train) lasso.fit(X_train, y_train) knn.fit(X_train, y_train) # 保存所有的预测结果 result_dic = { "True":y_test, "Linear":lr.predict(X_test), "Rige":ridge.predict(X_test), "Lasso":lasso.predict(X_test), "Knn":knn.predict(X_test) } # 展示预测结果 plt.figure(figsize=(24,24)) loc = 1 for row in range(5): upper_face = X_test[row] for title, y_ in result_dic.items(): bottom_face = y_[row] ax = plt.subplot(5,5,loc) loc += 1 face_data = np.concatenate((upper_face, bottom_face)) ax.imshow(face_data.reshape(64,64),cmap="gray") ax.set_title(title)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72

- 分类问题(匹配人脸的相似度)
# 1、获取数据 X_train = [] X_test = [] y_train = [] y_test = [] index = 0 for i in range(40): for j in range(10): face_data = data[index] face_y = target[index] if j<9: # 记录训练集 X_train.append(face_data) y_train.append(face_y) else: # 记录测试集 X_test.append(face_data) y_test.append(face_y) index += 1 #2、分别用KNN模型和逻辑斯蒂训练数据 from sklearn.linear_model import LogisticRegression from sklearn.neighbors import KNeighborsClassifier lr = LogisticRegression() %%time lr.fit(X_train,y_train) %%time lr.score(X_test, y_test) ==>0.94999999999999996 %%time lr.score(X_train, y_train) ==>1.0 %%time knn = KNeighborsClassifier() knn.fit(X_train, y_train) %%time knn.score(X_test, y_test) ==>0.84999999999999998 %%time knn.score(X_train, y_train) ==>0.96666666666666667
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
逻辑斯蒂分类边界绘制
- make_blobs函数 是为聚类产生数据集
- 产生一个数据集和相应的标签
make_blobs(n_samples=100, n_features=2, centers=3, cluster_std=1.0, center_box=(-10.0, 10.0), shuffle=True, random_state=None)
#参数
n_samples:表示数据样本点个数,默认值100
n_features:表示样本数据的特征数,默认值是2
centers:样本中心的分类个数,默认值3
cluster_std:数据集的标准差,浮点数或者浮点数序列,默认值1.0
center_box:中心确定之后的数据边界,默认值(-10.0, 10.0)
shuffle :洗乱,默认值是True
random_state:官网解释是随机生成器的种子,固定产生的随机数
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- np.c_[xx.ravel(), yy.ravel()]
- xx.ravel() 将xx多维数组降维到一维,扁平化处理
- np.c_ [array1,array2,…] 级联多个数组
- 案例
#1、导包 import numpy as np import pandas as pd from pandas import Series,DataFrame import matplotlib.pyplot as plt %matplotlib inline from sklearn.datasets import make_blobs #2、获取数据 train, target = make_blobs(n_samples=150, n_features=2, centers=3, cluster_std=3) plt.scatter(train[:,0],train[:,1],c=target) #3、训练测试数据 from sklearn.linear_model import LogisticRegression from sklearn.neighbors import KNeighborsClassifier #绘制底色 xmin, xmax = train[:,0].min(), train[:,0].max() ymin, ymax = train[:,1].min(), train[:,1].max() x = np.linspace(xmin, xmax, 200) y = np.linspace(ymin, ymax, 200) xx, yy = np.meshgrid(x, y) # X_test = np.concatenate((xx.reshape(-1,1), yy.reshape(-1,1)),axis=1) X_test = np.c_[xx.ravel(), yy.ravel()] #绘制底色 plt.scatter(X_test[:,0], X_test[:,1]) #训练 knn = KNeighborsClassifier() lr = LogisticRegression() knn.fit(train, target) lr.fit(train, target) #预测 knn_y = knn.predict(X_test) lr_y = lr.predict(X_test) #4、绘制边界分布图 from matplotlib.colors import ListedColormap plt.figure(figsize=(12,5)) #knn图像 ax1 = plt.subplot(1,2,1) ax1.set_title("KNN") ax1.scatter(X_test[:,0], X_test[:,1], c=knn_y, cmap=ListedColormap(np.random.random(size=(3,3)))) ax1.scatter(train[:,0], train[:,1], c=target, cmap=ListedColormap(np.random.random(size=(3,3)))) #logistic图像 ax2 = plt.subplot(1,2,2) ax2.set_title("LogisticRegression") ax2.scatter(X_test[:,0], X_test[:,1], c=lr_y, cmap=ListedColormap(np.random.random(size=(3,3)))) ax2.scatter(train[:,0], train[:,1], c=target, cmap=ListedColormap(np.random.random(size=(3,3))))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51

贝叶斯模型
-
什么是贝叶斯?
-
贝叶斯公式:
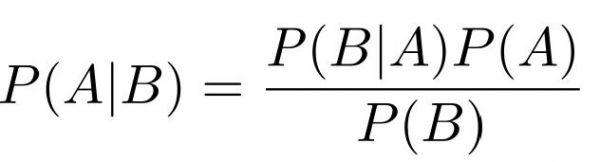
-例如:一座别墅在过去的 20 年里一共发生过 2 次被盗,别墅的主人有一条狗,狗平均每周晚上叫 3 次,在盗贼入侵时狗叫的概率被估计为 0.9,问题是:在狗叫的时候发生入侵的概率是多少?
我们假设 A 事件为狗在晚上叫,B 为盗贼入侵,则以天为单位统计,P(A) = 3/7,P(B) = 2/(20365) = 2/7300,P(A|B) = 0.9,按照公式很容易得出结果:P(B|A) = 0.9(2/7300) / (3/7) = 0.00058 -
另一个例子,现分别有 A、B 两个容器,在容器 A 里分别有 7 个红球和 3 个白球,在容器 B 里有 1 个红球和 9 个白球,现已知从这两个容器里任意抽出了一个球,且是红球,问这个红球是来自容器 A 的概率是多少?
假设已经抽出红球为事件 B,选中容器 A 为事件 A,则有:P(B) = 8/20,P(A) = 1/2,P(B|A) = 7/10,按照公式,则有:P(A|B) = (7/10)*(1/2) / (8/20) = 0.875
-
-
贝叶斯模型的分类:
- 高斯分布朴素贝叶斯 GaussianNB
- 【用途】用于一般分类问题 ,特征值为连续型变量
- 高斯模型假设某一特征属于某一类别的观测值符合高斯分布,比如身高小于160,160~170和170以上
- 多项式分布朴素贝叶斯MultinomialNB
- 【用途】适用于文本数据(特征表示的是次数,例如某个词语的出现次数。多用于文本分类,特征是单词,值是单词的出现次数
- 伯努利分布朴素贝叶斯BernoulliNB
- 【用途】适用于伯努利分布,也适用于文本数据(此时特征表示的是是否出现,例如某个词语的出现为1,不出现为0)特征值取bool类型,文本分类中表示一个值(单词)有没有出现过
绝大多数情况下表现不如多项式分布,但有的时候伯努利分布表现得要比多项式分布要好,尤其是对于小数量级的文本数据
- 【用途】适用于伯努利分布,也适用于文本数据(此时特征表示的是是否出现,例如某个词语的出现为1,不出现为0)特征值取bool类型,文本分类中表示一个值(单词)有没有出现过
- 高斯分布朴素贝叶斯 GaussianNB
-
什么是朴素贝叶斯?
-
朴素的概念:独立性假设,假设各个特征之间是独立不相关的
-
主要核心思想:朴素贝叶斯的思想基础是这样的:对于给出的待分类样本特征x,求解在此样本出现的条件下各个类别出现的概率,哪个最大,就认为此待分类样本属于哪个类别。
-
公式:
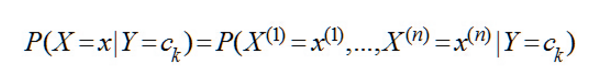
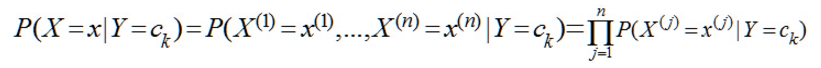
-
-
例子: 男生每天就把女神去自习室与否以及一些其他情况做一下记录,用Y表示该女生是否去自习室,即Y={去,不去},X是跟去自习室有关联的一系列条件。
这里n=4,x(1)表示主课,x(2)表示天气,x(3)表示星期几,x(4)表示气氛,Y仍然是{去,不去},现在主课有8门,天气有晴、雨、阴三种、气氛有A+,A,B+,B,C五种,那么总共需要估计的参数有8×3×7×5×2=1680个,每天只能收集到一条数据,那么等凑齐1680条数据
于是做了一个独立性假设,假设这些影响她去自习室的原因是独立互不相关的
案例
- 高斯分布就是正态分布
- 使用自带的红酒数据做案例
import numpy as np import pandas as pd from pandas import Series,DataFrame import matplotlib.pyplot as plt %matplotlib inline from sklearn.datasets import load_wine #1、获取数据(多分类问题) wine = load_wine() data = wine.data target = wine.target featur_names = wine.feature_names df = DataFrame(data=data, columns=featur_names) ==>(178,13) alcohol malic_acid ash alcalinity_of_ash magnesium total_phenols flavanoids nonflavanoid_phenols proanthocyanins color_intensity hue od280/od315_of_diluted_wines proline 0 14.23 1.71 2.43 15.6 127.0 2.80 3.06 0.28 2.29 5.64 1.04 3.92 1065.0 1 13.20 1.78 2.14 11.2 100.0 2.65 2.76 0.26 1.28 4.38 1.05 3.40 1050.0 2 13.16 2.36 2.67 18.6 101.0 2.80 3.24 0.30 2.81 5.68 1.03 3.17 1185.0 # 2、训练测试样本 from sklearn.naive_bayes import GaussianNB,MultinomialNB,BernoulliNB from sklearn.model_selection import train_test_split gNB = GaussianNB() X_train, X_test, y_train, y_test = train_test_split(data, target, test_size=0.2) # 贝叶斯模型只能处理分类模型 # 样本标签如果是连续性 可以使用映射,把样本标签映射为离散型,进而可以使用分类算法处理 #高斯分布朴素贝叶斯 gNB.fit(X_train, y_train) gNB.score(X_train, y_train) ==>0.97222222222222221 gNB.score(X_test, y_test) ==>0.97222222222222221 #多项式分布朴素贝叶斯 mNB = MultinomialNB() mNB.fit(X_train, y_train) mNB.score(X_train, y_train) ==>0.85915492957746475 mNB.score(X_test, y_test) ==>0.83333333333333337 #伯努利分布朴素贝叶斯 bNB = BernoulliNB() bNB.fit(X_train, y_train) bNB.score(X_train, y_train) ==>0.40140845070422537 bNB.score(X_test, y_test) ==>0.3888888888888889 # 逻辑斯蒂模型 from sklearn.linear_model import LogisticRegression lr = LogisticRegression() lr.fit(X_train, y_train) lr.score(X_train, y_train) ==>0.9859154929577465 lr.score(X_test, y_test) ==>0.94444444444444442 #KNN分类模型 from sklearn.neighbors import KNeighborsClassifier knn = KNeighborsClassifier() knn.fit(X_train, y_train) knn.score(X_train, y_train) ==>0.80281690140845074 knn.score(X_test, y_test) ==>0.69444444444444442
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 短信分类案例
#1、获取数据 sms = pd.read_table('../data/SMSSpamCollection',header=None) train = sms[1].copy() target = sms[0].copy() #2、训练与评分 from sklearn.naive_bayes import GaussianNB,MultinomialNB,BernoulliNB from sklearn.feature_extraction.text import TfidfVectorizer #转化文字样本为词频 tf_train = tf.fit_transform(train) X_train, X_test, y_train, y_test = train_test_split(tf_train, target, test_size=0.2) #多项式 mNB.fit(X_train, y_train) mNB.score(X_test, y_test) ==>0.96322869955156953 mNB.score(X_train, y_train) ==>mNB.score(X_train, y_train) 0.96903746914965228 #伯努利 bNB.fit(X_train, y_train) bNB.score(X_test, y_test) ==>0.98744394618834086 bNB.score(X_train, y_train) ==>0.98676239623064843
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- tf.fit_transform()¶
- 导入sklearn.feature_extraction.text.TfidfVectorizer用于转换字符串
- 参数必须是字符串的一维数组(比如列表或者Series)
返回的是一个稀疏矩阵类型的对象,行数为样本数,列数为所有出现的单词统计个数。
这里输入data[1]是Series类型,返回的是一个5572x8713 sparse matrix 其中5572是data[1]
from sklearn.feature_extraction.text import TfidfVectorizer tf = TfidfVectorizer() message = "welcome to beijing, this is a beautifull city." res = tf.fit_transform([message]) #将字符串转换为数值化的词频 res.toarray() ==> array([[ 0.37796447, 0.37796447, 0.37796447, 0.37796447, 0.37796447, 0.37796447, 0.37796447]]) # 之前用于学习样本集的tf对象,才能用于测试集文本的转换 X_test = train.loc[0:3].values tf_X_test = tf.transform(X_test) bNB.predict(tf_X_test) bNB.predict(tf_X_test) ==> array(['ham', 'ham', 'spam', 'ham'], dtype='<U4') target[:4]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 邮件分类
#1、导包 import numpy as np import pandas as pd from pandas import Series,DataFrame import matplotlib.pyplot as plt %matplotlib inline #2、读取数据 # 每一个txt文件时一个完整的邮件,它应该作为有一个样本 def read_data(categray): train = [] target = [] for i in range(25): file_path = "data/email/{}/{}.txt".format(categray, i+1) with open(file_path, "r", errors='ignore') as fp: train.append(fp.read()) target.append(categray) return (train, target) #正常邮件 X1, y1 = read_data("ham") #垃圾邮件 X2, y2 = read_data("spam") #合并数据 train = np.concatenate((X1, X2)) target = np.concatenate((y1, y2)) # 使用train_test_split,打乱顺序随机取值,确保测试机和训练集中,都存在ham和spam from sklearn.model_selection import train_test_split X_train,X_test, y_train, y_test = train_test_split(train, target, test_size=0.2, random_state=3) # 应该使用样本集去训练tf对象,不论使用X_train还是X_test都有可能会造成词频丢失 from sklearn.naive_bayes import MultinomialNB, BernoulliNB from sklearn.feature_extraction.text import TfidfVectorizer tf = TfidfVectorizer() tf.fit(train) # 使用完整的样本集训练过的tf对象,分别对训练集和测试集进行转换 tf_X_train = tf.transform(X_train) tf_X_test = tf.transform(X_test) #3、训练数据 mNB = MultinomialNB() bNB = BernoulliNB() mNB.fit(tf_X_train, y_train) bNB.fit(tf_X_train, y_train) #4、 分类模型,使用准确率来评价模型 mNB.score(tf_X_test, y_test) bNB.score(tf_X_test, y_test)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
决策树
-
什么是决策树?
决策树分类的思想类似于找对象。现想象一个女孩的母亲要给这个女孩介绍男朋友,于是有了下面的对话:

上图完整表达了这个女孩决定是否见一个约会对象的策略,其中绿色节点表示判断条件,橙色节点表示决策结果,箭头表示在一个判断条件在不同情况下的决策路径,图中红色箭头表示了上面例子中女孩的决策过程。
这幅图基本可以算是一颗决策树,说它“基本可以算”是因为图中的判定条件没有量化,如收入高中低等等,还不能算是严格意义上的决策树,如果将所有条件量化,则就变成真正的决策树了。有了上面直观的认识,我们可以正式定义决策树了:
决策树(decision tree)是一个树结构(可以是二叉树或非二叉树)。其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。可以看到,决策树的决策过程非常直观,容易被人理解。目前决策树已经成功运用于医学、制造产业、天文学、分支生物学以及商业等诸多领域。
之前介绍的K-近邻算法可以完成很多分类任务,但是它最大的缺点就是无法给出数据的内在含义,决策树的主要优势就在于数据形式非常容易理解。
决策树算法能够读取数据集合,构建类似于上面的决策树。决策树很多任务都是为了数据中所蕴含的知识信息,因此决策树可以使用不熟悉的数据集合,并从中提取出一系列规则,机器学习算法最终将使用这些机器从数据集中创造的规则。专家系统中经常使用决策树,而且决策树给出结果往往可以匹敌在当前领域具有几十年工作经验的人类专家。 -
决策树的优缺点:
优点:计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不相关特征数据。既能用于分类,也能用于回归
缺点:可能会产生过度匹配问题 -
决策树的构造:
分类解决离散问题,回归解决连续问题 决策树:信息论 逻辑斯底回归、贝叶斯:概率论- 1
- 2
- 3
不同于逻辑斯蒂回归和贝叶斯算法,决策树的构造过程不依赖领域知识,它使用属性选择度量来选择将元组最好地划分成不同的类的属性。所谓决策树的构造就是进行属性选择度量确定各个特征属性之间的拓扑结构。
构造决策树的关键步骤是分裂属性。所谓分裂属性就是在某个节点处按照某一特征属性的不同划分构造不同的分支,其目标是让各个分裂子集尽可能地“纯”。尽可能“纯”就是尽量让一个分裂子集中待分类项属于同一类别。分裂属性分为三种不同的情况:
1、属性是离散值且不要求生成二叉决策树。此时用属性的每一个划分作为一个分支。
2、属性是离散值且要求生成二叉决策树。此时使用属性划分的一个子集进行测试,按照“属于此子集”和“不属于此子集”分成两个分支。
3、属性是连续值。此时确定一个值作为分裂点split_point,按照>split_point和<=split_point生成两个分支。
构造决策树的关键性内容是进行属性选择度量,属性选择度量是一种选择分裂准则,它决定了拓扑结构及分裂点split_point的选择。
属性选择度量算法有很多,一般使用自顶向下递归分治法,并采用不回溯的贪心策略。这里介绍常用的ID3算法。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- iD3算法
划分数据集的大原则是:将无序的数据变得更加有序。 - 熵:熵这个概念最早起源于物理学,在物理学中是用来度量一个热力学系统的无序程度。
而在信息学里面,熵是对不确定性的度量。
在1948年,香农引入了信息熵,将其定义为离散随机事件出现的概率,一个系统越是有序,信息熵就越低,反之一个系统越是混乱,它的信息熵就越高。所以信息熵可以被认为是系统有序化程度的一个度量。 - 信息增量
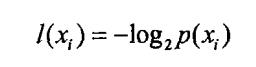
p(x)是选择该分类的概率
我们可以使用多种方法划分数据集,但是每种方法都有各自的优缺点。组织杂乱无章数据的一种方法就是使用信息论度量信息,信息论是量化处理信息的分支科学。我们可以在划分数据之前使用信息论量化度量信息的内容。
在划分数据集之前之后信息发生的变化称为信息增益,知道如何计算信息增益,我们就可以计算每个特征值划分数据集获得的信息增益,获得信息增益最高的特征就是最好的选择。
在可以评测哪种数据划分方式是最好的数据划分之前,我们必须学习如何计算信息增益。集合信息的度量方式称为香农熵或者简称为熵,这个名字来源于信息论之父克劳德•香农。
熵定义为信息的期望值,在明晰这个概念之前,我们必须知道信息的定义。如果待分类的事务可能划分在多个分类之中,则符号x的信息定义为:
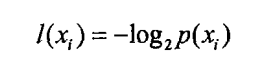
- 计算熵:
为了计算熵,我们需要计算所有类别所有可能值包含的信息期望值,通过下面的公式得到:
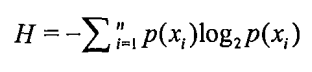
在决策树当中,设D为用类别对训练元组进行的划分,则D的熵(entropy)表示为:
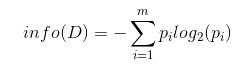
其中pi表示第i个类别在整个训练元组中出现的概率,可以用属于此类别元素的数量除以训练元组元素总数量作为估计。熵的实际意义表示是D中元组的类标号所需要的平均信息量
现在我们假设将训练元组D按属性A进行划分,则A对D划分的期望信息为:
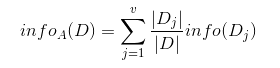
信息增益即为两者的差值:
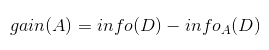
ID3算法就是在每次需要分裂时,计算每个属性的增益率,然后选择增益率最大的属性进行分裂


下面我们继续用SNS社区中不真实账号检测的例子说明如何使用ID3算法构造决策树。为了简单起见,我们假设训练集合包含10个元素
在决策树当中,设D用为类别对训练元组进行的划分,则D的熵(entropy)表示为:
info_D = -0.7*math.log2(0.7)-0.3*math.log2(0.3)
#计算日志密度的信息增益
info_L = 0.3*(-1/3*math.log2(1/3)-2/3*math.log2(2/3))+0.4*(-1/4*math.log2(1/4)-3/4*math.log2(3/4))+0.3*(-math.log2(1))
l = info_D - info_L
#计算是否使用真是头像的信息增益
info_H = 0.5*(-2/5*math.log2(2/5)-3/5*math.log2(3/5))+0.5*(-1/5*math.log2(1/5)-4/5*math.log2(4/5))
h = info_D - info_H
#计算好友密度的信息增益
info_F = 0.4*(-3/4*math.log2(3/4)-1/4*math.log2(1/4))+0.4*(-math.log2(1))+0.2*(-math.log2(1))
f = info_D - info_F
print(l,h,f)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 决策树基本使用
- ID3找的是当前最佳的分裂点 注意不要把他理解为计算几个特征
- max_depth 决策树深度 如果是分类问题,一般选特征个数的平方根 如果是回归问题,一般选特征个数
- max_depth 值越大,越容易过拟合, 越小越容易欠拟合
- splitter=‘best’ 找到最佳分裂点
DecisionTreeClassifier(criterion='gini', splitter='best', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, class_weight=None, presort=False) #参数解析 criterion:gini或者entropy,前者是基尼系数,后者是信息熵。 splitter: best or random 前者是在所有特征中找最好的切分点 后者是在部分特征中,默认的”best”适合样本量不大的时候,而如果样本数据量非常大,此时决策树构建推荐”random” 。 max_features:None(所有),log2,sqrt,N 特征小于50的时候一般使用所有的 max_depth: int or None, optional (default=None) 设置决策随机森林中的决策树的最大深度,深度越大,越容易过拟合,推荐树的深度为:5-20之间。 min_samples_split:设置结点的最小样本数量,当样本数量可能小于此值时,结点将不会在划分。 min_samples_leaf: 这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝。 min_weight_fraction_leaf: 这个值限制了叶子节点所有样本权重和的最小值,如果小于这个值,则会和兄弟节点一起被剪枝默认是0,就是不考虑权重问题。 max_leaf_nodes: 通过限制最大叶子节点数,可以防止过拟合,默认是"None”,即不限制最大的叶子节点数。 class_weight: 指定样本各类别的的权重,主要是为了防止训练集某些类别的样本过多导致训练的决策树过于偏向这些类别。这里可以自己指定各个样本的权重,如果使用“balanced”,则算法会自己计算权重,样本量少的类别所对应的样本权重会高。 min_impurity_split: 这个值限制了决策树的增长,如果某节点的不纯度(基尼系数,信息增益,均方差,绝对差)小于这个阈值则该节点不再生成子节点。即为叶子节点 。 plt.suptitle(u'决策树对鸢尾花数据的两特征组合的分类结果', fontsize=18)设置整个大画布的标题 plt.tight_layout(2) 调整图片的布局 plt.subplots_adjust(top=0.92) 自适应,绘图距顶部的距离为0.92
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 决策树的绘制
tree.export_graphviz(decision_tree, out_file="tree.dot", max_depth=None, feature_names=None, class_names=None, label='all', filled=False, leaves_parallel=False, impurity=True, node_ids=False, proportion=False, rotate=False, rounded=False, special_characters=False, precision=3)
- 1
决策树分类
- 基础写法(各特征之间的相互关系图)
import numpy as np import matplotlib.pyplot as plt import matplotlib as mpl from sklearn.tree import DecisionTreeClassifier from sklearn.datasets import load_iris iris_feature = u'花萼长度', u'花萼宽度', u'花瓣长度', u'花瓣宽度' mpl.rcParams['font.sans-serif'] = [u'SimHei'] mpl.rcParams['axes.unicode_minus'] = False target = load_iris().target.reshape(-1,1) data = load_iris().data data = np.concatenate((data,target),axis=1) x_prime, y = np.split(data, (4,), axis=1) feature_pairs = [[0, 1], [0, 2], [0, 3], [1, 2], [1, 3], [2, 3]] plt.figure(figsize=(10, 9), facecolor='#FFFFFF') for i, pair in enumerate(feature_pairs): # 准备数据 x = x_prime[:, pair] # 决策树学习 clf = DecisionTreeClassifier(criterion='entropy', min_samples_leaf=3) dt_clf = clf.fit(x, y) # 画图 N, M = 500, 500 x1_min, x1_max = x[:, 0].min(), x[:, 0].max() x2_min, x2_max = x[:, 1].min(), x[:, 1].max() t1 = np.linspace(x1_min, x1_max, N) t2 = np.linspace(x2_min, x2_max, M) x1, x2 = np.meshgrid(t1, t2) x_test = np.stack((x1.flat, x2.flat), axis=1) y_hat = dt_clf.predict(x) y = y.reshape(-1) c = np.count_nonzero(y_hat == y) # 统计预测正确的个数 print('特征: ', iris_feature[pair[0]], ' + ', iris_feature[pair[1]]) print('\t预测正确数目:', c) print('\t准确率: %.2f%%' % (100 * float(c) / float(len(y)))) # 显示 cm_light = mpl.colors.ListedColormap(['#A0FFA0', '#FFA0A0', '#A0A0FF']) cm_dark = mpl.colors.ListedColormap(['g', 'r', 'b']) y_hat = dt_clf.predict(x_test) # 预测值 y_hat = y_hat.reshape(x1.shape) plt.subplot(2, 3, i+1) plt.pcolormesh(x1, x2, y_hat, cmap=cm_light) plt.scatter(x[:, 0], x[:, 1], c=y, edgecolors='k', cmap=cm_dark) plt.xlabel(iris_feature[pair[0]], fontsize=14) plt.ylabel(iris_feature[pair[1]], fontsize=14) plt.xlim(x1_min, x1_max) plt.ylim(x2_min, x2_max) plt.grid() plt.suptitle(u'决策树对鸢尾花数据的两特征组合的分类结果', fontsize=18) plt.tight_layout(2) plt.subplots_adjust(top=0.92) plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
运行结果:
特征: 花萼长度 + 花萼宽度
预测正确数目: 123
准确率: 82.00%

特征: 花萼长度 + 花瓣长度
预测正确数目: 145
准确率: 96.67%
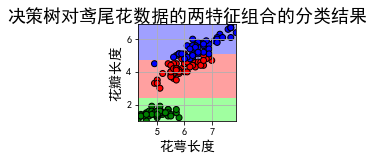
特征: 花萼长度 + 花瓣宽度
预测正确数目: 144
准确率: 96.00%

特征: 花萼宽度 + 花瓣长度
预测正确数目: 143
准确率: 95.33%

特征: 花萼宽度 + 花瓣宽度
预测正确数目: 145
准确率: 96.67%

特征: 花瓣长度 + 花瓣宽度
预测正确数目: 147
准确率: 98.00%

- 多个分类模型之间的比较
#导基础包 import numpy as np import pandas as pd from pandas import Series,DataFrame import matplotlib.pyplot as plt %matplotlib inline #算法包 from sklearn.datasets import load_iris from sklearn.tree import DecisionTreeClassifier from sklearn.neighbors import KNeighborsClassifier from sklearn.linear_model import LogisticRegression from sklearn.naive_bayes import GaussianNB #1、获取数据 from sklearn.model_selection import train_test_split iris = load_iris() X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=3) #2、使用决策树模型训练样本数据 dt = DecisionTreeClassifier(max_depth=4, criterion='entropy') dt.fit(X_train, y_train) #3、对决策树算法评分 dt.score(X_test, y_test) ==>0.8666666666666667 dt.score(X_train, y_train) ==>0.97499999999999998 #4、绘制决策过程( 1. pip install graphviz # 2. 本地安装graphviz软件,并且配置了环境变量) feature_names = iris.feature_names target_names = iris.target_names tree.export_graphviz(dt, out_file='tree.dot',feature_names=feature_names, class_names=target_names, filled=True) with open('tree.dot', 'r') as fp: dot = fp.read() graphviz.Source(dot) # 5、其他算法比较 knn = KNeighborsClassifier() lr = LogisticRegression(solver="lbfgs") gNB = GaussianNB() #knn算法评分 knn.fit(X_train, y_train) knn.score(X_test, y_test) knn.score(X_train, y_train) #logistic算法评分 lr.fit(X_train, y_train) lr.score(X_test, y_test) lr.score(X_train, y_train) #查看正负样本的概率 lr.predict_proba(X_test) #GaussianNB(高斯朴素贝叶斯)算法平分 gNB.fit(X_train, y_train) gNB.score(X_test, y_test) gNB.score(X_train, y_train) #6、绘制边界线 # 1). 用所有数据训练所有的模型 dt.fit(iris.data[:,:2], iris.target) knn.fit(iris.data[:,:2], iris.target) lr.fit(iris.data[:,:2], iris.target) gNB.fit(iris.data[:,:2], iris.target) # 2). 获取全屏数据,作为测试数据,预测结果 xmin, xmax = iris.data[:,0].min(), iris.data[:,0].max() ymin, ymax = iris.data[:,1].min(), iris.data[:,1].max() x = np.linspace(xmin, xmax, 100) y = np.linspace(ymin, ymax, 100) xx, yy = np.meshgrid(x, y) X_test = np.c_[xx.ravel(), yy.ravel()] # 3). 用预测结果填充背景点颜色 result = { "DecisonTree":dt.predict(X_test), "KNN":knn.predict(X_test), "Logistic":lr.predict(X_test), "GaussionNB":gNB.predict(X_test) } # 4). 绘图展示 from matplotlib.colors import ListedColormap plt.figure(figsize=(16,12)) loc = 1 for key, y_ in result.items(): ax = plt.subplot(2,2,loc) loc += 1 ax.set_title(key) ax.scatter(X_test[:,0], X_test[:,1], c=y_, cmap=ListedColormap(np.random.random(size=(3,3)))) ax.scatter(iris.data[:,0], iris.data[:,1], c=iris.target, cmap=ListedColormap(np.random.random(size=(3,3)))) ax.grid()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92

决策树回归模型
- 利用sin函数模拟回归
# 1、导包 import numpy as np import pandas as pd from pandas import Series,DataFrame import matplotlib.pyplot as plt %matplotlib inline #2、获取数据 X = np.linspace(0,2*np.pi, 60) y = np.sin(X) # 加噪音(-0.2到0.2之间的随机数) noise = (np.random.random(size=20)-0.5)*0.4 y[::3] += noise #3、训练模型DecisionTreeRegressor from sklearn.tree import DecisionTreeRegressor dt = DecisionTreeRegressor(max_depth=4) dt.fit(X.reshape(-1,1), y) #4、绘制决策树from sklearn import tree import graphviz dot = tree.export_graphviz(dt, out_file=None, filled=True) graphviz.Source(dot) #5、绘制预测结果 X_test = np.linspace(0,2*np.pi, 35) y_ = dt.predict(X_test.reshape(-1,1)) plt.figure(figsize=(12,6)) plt.scatter(X, y, label = "True", c="black") plt.plot(X_test, y_, label="Predict", color="orange") plt.legend() #6、max_depth参数的比较 dt1 = DecisionTreeRegressor(max_depth=1) dt2 = DecisionTreeRegressor(max_depth=7) dt1.fit(X.reshape(-1,1), y) dt2.fit(X.reshape(-1,1), y) y1 = dt1.predict(X_test.reshape(-1,1)) y2 = dt2.predict(X_test.reshape(-1,1)) plt.figure(figsize=(12,6)) plt.scatter(X, y, label = "True", c="black") plt.plot(X_test, y1, label="Max Depth=1", color="orange") plt.plot(X_test, y2, label="Max Depth=7", color="green") plt.legend()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45


- 使用决策树回归预测椭圆(一个特征多输出)
# 1、获取数据 # sin\cos函数,接收的参数是弧度,不是角度 radians = np.sort(np.random.random(size=(200)))*200 - 100 x = np.cos(radians) y = np.sin(radians) #np.c_[x, y] #2、训练数据 dt1 = DecisionTreeRegressor(max_depth=2) dt2 = DecisionTreeRegressor(max_depth=8) dt3 = DecisionTreeRegressor(max_depth=15) train = radians.reshape(-1,1) target = np.c_[x, y] dt1.fit(train, target) dt2.fit(train, target) dt3.fit(train, target) #3、获取测试集 X_test = np.linspace(-100,100,200).reshape(-1,1) result = { "max_dpth=2":dt1.predict(X_test), "max_dpth=8":dt2.predict(X_test), "max_dpth=15":dt3.predict(X_test) } #4、绘制分布图 plt.figure(figsize=(16,4)) loc = 1 for key, value in result.items(): ax = plt.subplot(1,3,loc) loc += 1 ax.scatter(value[:,0], value[:,1]) ax.set_title(key) ax.axis("equal")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34

集成方法
集成方法 的目标是把多个使用给定学习算法构建的基估计器的预测结果结合起来,从而获得比单个估计器更好的泛化能力/鲁棒性。
集成方法通常分为两种:
-
平均方法(投票制),该方法的原理是构建多个独立的估计器,然后取它们的预测结果的平均。一般来说组合之后的估计器是会比单个估计器要好的,因为它的方差减小了。
示例: Bagging 方法(自定义获取子样本集 子特征集
) , 随机森林 (取子样本集, 基估计器是决策树 计算分裂点的方式 best
), 极限森林(计算分裂点的方式 random)… -
相比之下,在 boosting 方法 中,基估计器是依次构建的,并且每一个基估计器都尝试去减少组合估计器的偏差。这种方法主要目的是为了结合多个弱模型,使集成的模型更加强大。(迭代 后一次的值依赖于前一次的值
)
示例: AdaBoost (调整基模型的权重
), 梯度提升树(利用损失构造新的样本集,然后多次拟合
) , …
Bagging meta-estimator(Bagging 元估计器)
在集成算法中,bagging 方法会在原始训练集的随机子集上构建一类黑盒估计器的多个实例,然后把这些估计器的预测结果结合起来形成最终的预测结果。 该方法通过在构建模型的过程中引入随机性,来减少基估计器的方差(例如,决策树)。 在多数情况下,bagging 方法提供了一种非常简单的方式来对单一模型进行改进,而无需修改背后的算法。 因为 bagging 方法可以减小过拟合,所以通常在强分类器和复杂模型上使用时表现的很好(例如,完全决策树,fully developed decision trees),相比之下 boosting 方法则在弱模型上表现更好(例如,浅层决策树,shallow decision trees)。
bagging 方法有很多种,其主要区别在于随机抽取训练子集的方法不同:
-
如果抽取的数据集的随机子集是样例的随机子集,我们叫做粘贴 (Pasting) [B1999] 。
-
如果样例抽取是有放回的,我们称为 Bagging [B1996] 。
-
如果抽取的数据集的随机子集是特征的随机子集,我们叫做随机子空间 (Random Subspaces) [H1998] 。
-
最后,如果基估计器构建在对于样本和特征抽取的子集之上时,我们叫做随机补丁 (Random Patches) [LG2012]。
在 scikit-learn 中,bagging 方法使用统一的 BaggingClassifier 元估计器(或者 BaggingRegressor ),输入的参数和随机子集抽取策略由用户指定。max_samples 和 max_features 控制着子集的大小(对于样例和特征), bootstrap 和 bootstrap_features 控制着样例和特征的抽取是有放回还是无放回的。 当使用样本子集时,通过设置 oob_score=True ,可以使用袋外(out-of-bag)样本来评估泛化精度。下面的代码片段说明了如何构造一个 KNeighborsClassifier 估计器的 bagging 集成实例,每一个基估计器都建立在 50% 的样本随机子集和 50% 的特征随机子集上。 -
数学基础

-
图例描述

-
格式
BaggingClassifier(base_estimator=None, n_estimators=10, max_samples=1.0, max_features=1.0, bootstrap=True, bootstrap_features=False, oob_score=False, warm_start=False, n_jobs=1, random_state=None, verbose=0)
#参数:
# base_estimator 指的是基估计器,就是一个任意的机器学习算法
# n_estimators 指的是要同时构建多少个基估计器
# max_samples 指随机抽取的子样本集中,样本的最大个数 必须是一个float(1.0代表100%,不能用1代替)
# max_features 指随机抽取子样本特征时,最大特征数 必须是一个float
#参数 bootstrap 和 bootstrap_features 控制是否在有或没有替换的情况下绘制样本和特征。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
-
知识点
- bc.estimators_ # 获取所有基估计器
-
红酒数据案例
# Bagging算法的一种,元估计器 from sklearn.ensemble import BaggingClassifier, BaggingRegressor from sklearn.datasets import load_wine from sklearn.neighbors import KNeighborsClassifier import pandas as pd from pandas import Series,DataFrame #1、构建模型 bc = BaggingClassifier(KNeighborsClassifier(), n_estimators=100,max_samples=0.6, max_features=1.0) #2、获取数据 X, y = load_wine(return_X_y=True) #3、训练模型并评分 #knn模型 knn = KNeighborsClassifier() knn.fit(X, y) knn.score(X, y) #baggingclassifier模型 bc.fit(X, y) #4、对每个基估计器进行评分 # 获取所有基估计器 bc.estimators_ for i in range(10): score = bc.estimators_[i].score(X, y) print(score)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
由随机树组成的森林
sklearn.ensemble 模块包含两个基于 随机决策树 的平均算法: RandomForest 算法和 Extra-Trees 算法。 这两种算法都是专门为树而设计的扰动和组合技术(perturb-and-combine techniques) [B1998] 。 这种技术通过在分类器构造过程中引入随机性来创建一组不同的分类器。集成分类器的预测结果就是单个分类器预测结果的平均值。
与其他分类器一样,森林分类器必须拟合(fit)两个数组: 保存训练样本的数组(或稀疏或稠密的)X,大小为 [n_samples, n_features],和 保存训练样本目标值(类标签)的数组 Y,大小为 [n_samples]:
同 决策树 一样,随机森林算法(forests of trees)也能用来解决 多输出问题 (如果 Y 的大小是 [n_samples, n_outputs]) )。
随机森林
在随机森林中(参见 RandomForestClassifier 和 RandomForestRegressor 类), 集成模型中的每棵树构建时的样本都是由训练集经过有放回抽样得来的(例如,自助采样法-bootstrap sample,这里采用西瓜书中的译法)。 另外,在构建树的过程中进行结点分割时,选择的分割点不再是所有特征中最佳分割点,而是特征的一个随机子集中的最佳分割点。 由于这种随机性,森林的偏差通常会有略微的增大(相对于单个非随机树的偏差),但是由于取了平均,其方差也会减小,通常能够补偿偏差的增加,从而产生一个总体上更好的模型。
与原始文献[B2001]不同的是,scikit-learn 的实现是取每个分类器预测概率的平均,而不是让每个分类器对类别进行投票。
- 鸢尾花数据案例
#导包 from sklearn.ensemble import RandomForestClassifier from sklearn.datasets import load_iris # 一、决策树写法 from sklearn.tree import DecisionTreeClassifier dt = DecisionTreeClassifier(max_depth=2, criterion='entropy') #1、训练模型 X, y = load_iris(return_X_y=True) dt.fit(X, y) dt.score(X, y) # 2、绘制决策树 from sklearn import tree import graphviz feature_names = load_iris().feature_names target_names = load_iris().target_names dot = tree.export_graphviz(dt, out_file=None, filled=True, feature_names=feature_names, class_names=target_names) graphviz.Source(dot) # 二、随机森林 rfc = RandomForestClassifier(n_estimators=10, criterion="entropy", max_depth=2) rfc.fit(X, y) rfc.score(X,y) # 获取随机森林中所有的决策树模型 rfc.estimators_ # 随机森林的子集是又放回的取样, 所以每一个随机子集的个数一定小于或等于原始样本集的个数
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
极限随机森林
在极限随机树中(参见 ExtraTreesClassifier 和 ExtraTreesRegressor 类), 计算分割点方法中的随机性进一步增强。 在随机森林中,使用的特征是候选特征的随机子集;不同于寻找最具有区分度的阈值, 这里的阈值是针对每个候选特征随机生成的,并且选择这些随机生成的阈值中的最佳者作为分割规则。 这种做法通常能够减少一点模型的方差,代价则是略微地增大偏差
- make_blobs生成样本集
from sklearn.datasets import make_blobs from sklearn.ensemble import ExtraTreesClassifier from sklearn.tree import DecisionTreeClassifier from sklearn.ensemble import RandomForestClassifier #1、生成数据 X, y = make_blobs(n_samples=10000, n_features=10, centers=100, random_state=1) # 观察决策树评分 dt = DecisionTreeClassifier(max_depth=5) dt.fit(X, y) dt.score(X, y) ==>0.2598 ## 观察随机森林的评分 rdt = RandomForestClassifier(max_depth=5, n_estimators=100) rdt.fit(X, y) rdt.score(X, y) ==>0.9985 ## 极限随机森林 etc = ExtraTreesClassifier(max_depth=5, n_estimators=100) etc.fit(X, y) etc.score(X, y) ==>0.9998
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
AdaBoost
模型 sklearn.ensemble 包含了流行的提升算法 AdaBoost, 这个算法是由 Freund and Schapire 在 1995 年提出来的 [FS1995].
AdaBoost 的核心思想是用反复修改的数据(校对者注:主要是修正数据的权重)来训练一系列的弱学习器(一个弱学习器模型仅仅比随机猜测好一点, 比如一个简单的决策树),由这些弱学习器的预测结果通过加权投票(或加权求和)的方式组合, 得到我们最终的预测结果。在每一次所谓的提升(boosting)迭代中,数据的修改由应用于每一个训练样本的(新) 的权重 w_1, w_2, …, w_N 组成(校对者注:即修改每一个训练样本应用于新一轮学习器的权重)。 初始化时,将所有弱学习器的权重都设置为 w_i = 1/N ,因此第一次迭代仅仅是通过原始数据训练出一个弱学习器。在接下来的 连续迭代中,样本的权重逐个地被修改,学习算法也因此要重新应用这些已经修改的权重。在给定的一个迭代中, 那些在上一轮迭代中被预测为错误结果的样本的权重将会被增加,而那些被预测为正确结果的样本的权 重将会被降低。随着迭代次数的增加,那些难以预测的样例的影响将会越来越大,每一个随后的弱学习器都将 会被强迫更加关注那些在之前被错误预测的样例 [HTF].

AdaBoost 既可以用在分类问题也可以用在回归问题中:
对于 multi-class 分类, AdaBoostClassifier 实现了 AdaBoost-SAMME 和 AdaBoost-SAMME.R [ZZRH2009].
对于回归, AdaBoostRegressor 实现了 AdaBoost.R2 [D1997].
AdaBoostClassifier(base_estimator=None, n_estimators=50, learning_rate=1.0, algorithm='SAMME.R', random_state=None)
'''
弱学习器的数量由参数 n_estimators 来控制。 learning_rate 参数用来控制每个弱学习器对 最终的结果的贡献程度(校对者注:其实应该就是控制每个弱学习器的权重修改速率,这里不太记得了,不确定)。 弱学习器默认使用决策树。不同的弱学习器可以通过参数 base_estimator 来指定。 获取一个好的预测结果主要需要调整的参数是 n_estimators 和 base_estimator 的复杂度 (例如:对于弱学习器为决策树的情况,树的深度 max_depth 或叶子节点的最小样本数 min_samples_leaf 等都是控制树的复杂度的参数)
- 1
- 2
- 3
- 4
- 鸢尾花案例
from sklearn.ensemble import AdaBoostClassifier
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
# 调整基模型,可以改变预测效果
# 通过调整各个学习器的权重,来缩小误差
adbc = AdaBoostClassifier(n_estimators=100, base_estimator=DecisionTreeClassifier(max_depth=3, min_samples_leaf=3))
X, y = load_iris(return_X_y=True)
adbc.fit(X, y)
adbc.score(X, y)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
Gradient Tree Boosting(梯度树提升)
Gradient Tree Boosting 或梯度提升回归树(GBRT)是对于任意的可微损失函数的提升算法的泛化。 GBRT 是一个准确高效的现有程序, 它既能用于分类问题也可以用于回归问题。梯度树提升模型被应用到各种领域,包括网页搜索排名和生态领域。
GBRT 的优点:
-
对混合型数据的自然处理(异构特征)
-
强大的预测能力
-
在输出空间中对异常点的鲁棒性(通过具有鲁棒性的损失函数实现)
GBRT 的缺点: -
可扩展性差(校对者注:此处的可扩展性特指在更大规模的数据集/复杂度更高的模型上使用的能力,而非我们通常说的功能的扩展性;GBRT 支持自定义的损失函数,从这个角度看它的扩展性还是很强的!)。由于提升算法的有序性(也就是说下一步的结果依赖于上一步),因此很难做并行.
模块 sklearn.ensemble 通过梯度提升树提供了分类和回归的方法.
注意:在LightGBM的启发下,Scikit-learn 0.21引入了两种新的梯度提升树的实验实现,即 HistGradientBoostingClassifier和 HistGradientBoostingRegressor。这些快速估计器首先将输入样本X放入整数值的箱子(通常是256个箱子)中,这极大地减少了需要考虑的分裂点的数量,并允许算法利用基于整数的数据结构(直方图),而不是依赖于排序后的连续值。
当样本数量大于数万个样本时,基于直方图的新估计值可以比连续估计值快几个数量级。这些新的估计器的API略有不同,目前还不支持GradientBoostingClassifier和GradientBoostingRegressor的一些特性。
这些新的评估器目前仍处于试验阶段:它们的预测和API可能会在没有任何弃用周期的情况下发生变化。要使用它们,您需要显式地导入enable_hist_gradient_boost:
- 分类:GradientBoostingClassifier 既支持二分类又支持多分类问题。
- 弱学习器(例如:回归树)的数量由参数 n_estimators 来控制;每个树的大小可以通过由参数 max_depth 设置树的深度,或者由参数 max_leaf_nodes 设置叶子节点数目来控制。 learning_rate 是一个在 (0,1] 之间的超参数,这个参数通过 shrinkage(缩减步长) 来控制过拟合。
- 注意:超过两类的分类问题需要在每一次迭代时推导 n_classes 个回归树。因此,所有的需要推导的树数量等于 n_classes * n_estimators 。对于拥有大量类别的数据集我们强烈推荐使用 RandomForestClassifier 来代替 GradientBoostingClassifier 。
#1、获取数据 from sklearn.ensemble import GradientBoostingClassifier, GradientBoostingRegressor from sklearn.datasets import load_wine X, y = load_wine(return_X_y=True) feature_names = load_wine().feature_names target_names = load_wine().target_names import pandas as pd from pandas import Series,DataFrame import matplotlib.pyplot as plt %matplotlib inline wine = DataFrame(data=X, columns=feature_names) #2、训练数据 gbdt = GradientBoostingClassifier(n_estimators=10,max_depth=4) gbdt.fit(X, y) gbdt.estimators_ #3、绘制决策树 from sklearn import tree import graphviz dt = gbdt.estimators_[0,0] dot = tree.export_graphviz(dt, out_file=None, filled=True, feature_names=feature_names, class_names=target_names) graphviz.Source(dot) ## 4、可以获取到所有特征对结果影响的权重,权重越高,对结果影响越大 gbdt.feature_importances_ #5、绘制 import numpy as np plt.figure(figsize=(12,5)) plt.bar(np.arange(gbdt.feature_importances_.size), gbdt.feature_importances_) _ = plt.xticks(np.arange(gbdt.feature_importances_.size), feature_names, rotation=90) gbdt.score(X, y) improtance_featrues = ["malic_acid","flavanoids","color_intensity","od280/od315_of_diluted_wines","proline"] gbdt.fit(train, y) gbdt.score(train, y) # 训练误差,都记录在此属性当中 gbdt.train_score_ ==>array([ 162.1809493 , 136.94667586, 116.58721484, 99.86570593, 85.95614833, 74.15300959, 64.17889087, 55.69977399, 48.32408391, 42.00252507]) # 测试误差 for y_ in gbdt.staged_predict(train): print((y_ == y).sum()/y_.size)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
-
回归:对于回归问题 GradientBoostingRegressor 支持一系列 different loss functions ,这些损失函数可以通过参数 loss 来指定;对于回归问题默认的损失函数是最小二乘损失函数( ‘ls’ )。
-
案例:预测阴影眼镜类型
#1、基础包导入 import pandas as pd import numpy as np from pandas import Series,DataFrame import matplotlib.pyplot as plt %matplotlib inline #2、读取数据 samples = pd.read_csv('lenses.txt',sep='\t',header=None) # 确认样本标签和特征 samples.head() target = samples[4].copy() train = samples.loc[:,:3].copy() #量化训练数据(数值转换的思路:1. 有序的转换 高 中 低 2. 无序的转换 黑 白) for column in train.columns: unique_arr = train[column].unique() def map_data(x): #np.argwhere 函数返回数组中值等于x的元素的索引 return np.argwhere(unique_arr==x)[0,0] train.loc[:,column] = train[column].map(map_data) #3、分别用决策树、随机森林、梯度提升回归树模型训练数据 from sklearn.tree import DecisionTreeClassifier from sklearn.ensemble import GradientBoostingClassifier from sklearn.ensemble import RandomForestClassifier #DecisionTreeClassfier dt = DecisionTreeClassifier(max_depth=2) dt.fit(train, target) dt.score(train, target) ==>0.875 #GradientBoostingClassfier dt = DecisionTreeClassifier(max_depth=2) dt.fit(train, target) dt.score(train, target) ==>1 # RandomForestClassifier rdfc = RandomForestClassifier(max_depth=2, n_estimators=100) rdfc.fit(train, target) rdfc.score(train, target) ==>0.91667
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 八种分类算法 分类边界的绘制
#1、导包 import pandas as pd import numpy as np from pandas import Series,DataFrame import matplotlib.pyplot as plt %matplotlib inline from sklearn.neighbors import KNeighborsClassifier from sklearn.linear_model import LogisticRegression from sklearn.naive_bayes import GaussianNB from sklearn.tree import DecisionTreeClassifier from sklearn.ensemble import RandomForestClassifier from sklearn.ensemble import ExtraTreesClassifier from sklearn.ensemble import GradientBoostingClassifier from sklearn.ensemble import AdaBoostClassifier #2.获取样本集和标签 from sklearn.datasets import make_blobs X, y = make_blobs(n_samples=150, n_features=2, centers=3, cluster_std=2) plt.scatter(X[:,0],X[:,1], c=y) #获取画布背景点数据 xmin, xmax = X[:,0].min(), X[:,0].max() ymin, ymax = X[:,1].min(), X[:,1].max( x1 = np.linspace(xmin, xmax, 100) y1 = np.linspace(ymin, ymax, 100) xx, yy = np.meshgrid(x1, y1) X_test = np.c_[xx.ravel(), yy.ravel()] #3、封装函数训练并绘制每个算法的分类图 models = [KNeighborsClassifier(), LogisticRegression(), GaussianNB(), DecisionTreeClassifier(), RandomForestClassifier(), ExtraTreesClassifier(), GradientBoostingClassifier(), AdaBoostClassifier()] def show_classes(model, ax): ax.set_title(model.__class__.__name__) model.fit(X, y) y_ = model.predict(X_test) ax.scatter(X_test[:,0], X_test[:,1], c=y_, cmap=ListedColormap(np.random.random(size=(3,3)))) ax.scatter(X[:,0], X[:,1], c=y, cmap=ListedColormap(np.random.random(size=(3,3)))) ax.grid() #调用函数绘制 plt.figure(figsize=(24,8)) loc = 1 for model in models: ax = plt.subplot(2,4,loc) loc += 1 show_classes(model, ax)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
SVM支持向量机
-
【关键词】支持向量,最大几何间隔,拉格朗日乘子法
-
什么是SVM:Support Vector Machine(机器,分类器)?
- 是一类按监督学习(supervised learning)方式对数据进行二元分类的广义线性分类器(generalized linear classifier),其决策边界是对学习样本求解的最大边距超平面(maximum-margin hyperplane)
- SVM支持向量机,主要针对小样本数据、非线性及高维模式识别中表现出许多特有的优势,而且有很好的泛化能力
-
支持向量机的原理(把低维(特征维度)数据向高维数据转换,再进行预测
)
支持向量机,其含义是通过支持向量运算的分类器。其中“机”的意思是机器,可以理解为分类器。 那么什么是支持向量呢?在求解的过程中,会发现只根据部分数据就可以确定分类器,这些数据称为支持向量。 见下图,在一个二维环境中,其中点R,S,G点和其它靠近中间黑线的点可以看作为支持向量,它们可以决定分类器,也就是黑线的具体参数。


-
最大几何间隔

-
求解w、b
我们使用拉格朗日乘子法(http://blog.csdn.net/on2way/article/details/47729419) 来求w和b,一个重要原因是使用拉格朗日乘子法后,还可以解决非线性划分问题。 拉格朗日乘子法可以解决下面这个问题:

消除w之后变为:

可见使用拉格朗日乘子法后,求w,b的问题变成了求拉格朗日乘子αi和b的问题。 到后面更有趣,变成了不求w了,因为αi可以直接使用到分类器中去,并且可以使用αi支持非线性的情况. -
解决问题
- 线性分类:在训练数据中,每个数据都有n个的属性和一个二类类别标志,我们可以认为这些数据在一个n维空间里。我们的目标是找到一个n-1维的超平面(hyperplane),这个超平面可以将数据分成两部分,每部分数据都属于同一个类别。 其实这样的超平面有很多,我们要找到一个最佳的。因此,增加一个约束条件:这个超平面到每边最近数据点的距离是最大的。也成为最大间隔超平面(maximum-margin hyperplane)。这个分类器也成为最大间隔分类器(maximum-margin classifier)。 支持向量机是一个二类分类器。
- 非线性分类
SVM的一个优势是支持非线性分类。它结合使用拉格朗日乘子法和KKT条件,以及核函数可以产生非线性分类器。
SVM的目的是要找到一个线性分类的最佳超平面 f(x)=xw+b=0。求 w 和 b。
首先通过两个分类的最近点,找到f(x)的约束条件。
有了约束条件,就可以通过拉格朗日乘子法和KKT条件来求解,这时,问题变成了求拉格朗日乘子αi 和 b。
对于异常点的情况,加入松弛变量ξ来处理。
非线性分类的问题:映射到高维度、使用核函数。
-
线性分类及其约束条件:
SVM的解决问题的思路是找到离超平面的最近点,通过其约束条件求出最优解。 -
三个内核:
- linear 一般的线性问题
- rbf 处理非线性问题
- poly 非线性问题的增强版本 时间成本会显著提升
-
案例:利用SVC算法画出决策边界
#1、导包 from sklearn.svm import SVC import matplotlib.pyplot as plt %matplotlib inline import numpy as np #2、随机生成数据 train1 = np.random.random(size=(20,2)) + [-0.5,0.5] train2 = np.random.random(size=(20,2)) + [0.5, -0.5] plt.scatter(train1[:,0], train1[:,1], c="blue") plt.scatter(train2[:,0], train2[:,1], c="green") train = np.concatenate((train1, train2)) target = [0]*20 + [1]*20 #3、训练模型 # C=1.0 惩罚项 惩罚力度越大,说明对误差容忍越小 # kernel='rbf' 内核选择 linear rbf poly svc = SVC(kernel="linear", C=0.1) svc.fit(train, target) #4、获取关键参数 coef_ intercept_(注意此时的系数和斜距只是ax + by +c =0 函数里的参数) # 获取系数(最佳分类线的系数) svc.coef_ ==>array([[ 0.86543841, -0.95509823]]) # 获取截距 svc.intercept_ ==>array([0.04188426]) # 计算出最佳分类超平面的斜率和截距 w = -svc.coef_[0,0]/svc.coef_[0,1] k = -svc.intercept_[0]/svc.coef_[0,1] X_test = np.linspace(train[:,0].min(), train[:,0].max(),100) y = w*X_test + k #5、使用svc.supportvectors找出支持向量,即离分割线最近的点集合,绘制出支持向量的所有点 left_point = svc.support_vectors_[0] right_point = svc.support_vectors_[-1] #计算支持向量的斜距和直线方程 k1 = left_point[1] - w*left_point[0] k2 = right_point[1] - w*right_point[0] y1 = w*X_test + k1 y2 = w*X_test + k2 plt.scatter(train1[:,0], train1[:,1], c="blue") plt.scatter(train2[:,0], train2[:,1], c="green") plt.plot(X_test, y, color="red") plt.plot(X_test, y1, color="orange", label="f(x) = w*x - 1") plt.plot(X_test, y2, color="yellow", label="f(x) = w*x + 1") plt.legend()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46

- 使用多种核函数对iris数据集进行分类比较
# 1.导包 import numpy as np import pandas as pd from pandas import Series,DataFrame import matplotlib.pyplot as plt %matplotlib inline from sklearn.datasets import load_iris #2、提取数据只提取两个特征,方便画图 #创建支持向量机的模型:'linear', 'poly'(多项式), 'rbf'(Radial Basis Function:基于半径函数), data, target =load_iris(return_X_y=True) train = data[:,:2].copy() # 3、训练模型 from sklearn.svm import SVC linear = SVC(kernel='linear', gamma="scale") rbf = SVC(kernel='rbf', gamma="scale") poly = SVC(kernel="poly", gamma="scale") # gamma参数决定了支持向量的个数, 影响算法的运行效率 # C 惩罚项 越小,对惩罚容忍度越低,越容易过拟合 linear.fit(train, target) rbf.fit(train, target) poly.fit(train, target) # 4、图片背景点 xmin, xmax = train[:,0].min(), train[:,0].max() ymin, ymax = train[:,1].min(), train[:,1].max() x = np.linspace(xmin, xmax, 150) y = np.linspace(ymin, ymax, 150) xx, yy = np.meshgrid(x, y) X_test = np.c_[xx.ravel(), yy.ravel()] result = { "linear":linear.predict(X_test), "rbf":rbf.predict(X_test), "poly":poly.predict(X_test) } # 5、预测并绘制图形for循环绘制图形 from matplotlib.colors import ListedColormap plt.figure(figsize=(12,4)) loc = 1 for key, y_ in result.items(): ax = plt.subplot(1,3,loc) loc += 1 ax.set_title(key) ax.scatter(X_test[:,0], X_test[:,1], c=y_, cmap=ListedColormap(np.random.random(size=(3,3)))) ax.scatter(train[:,0], train[:,1], c=target, cmap=ListedColormap(np.random.random(size=(3,3))))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48

- 使用SVM多种核函数进行回归
#1 、自定义样本点rand,并且生成sin函数曲线 X = np.linspace(0,2*np.pi, 60) y = np.sin(X) #数据加噪 noise = (np.random.random(size=(20))-0.5)*0.5 y[::3] += noise #2.建立模型,训练数据,并预测数据,预测训练数据就行 from sklearn.svm import SVR linear = SVR(kernel="linear") rbf = SVR(kernel="rbf") poly = SVR(kernel="poly") X = X.reshape((-1,1)) linear.fit(X, y) rbf.fit(X, y) poly.fit(X, y) #3、绘制图形,观察三种支持向量机内核不同 X_test = np.linspace(X.min(), X.max(), 45).reshape((-1,1)) result = { "linear":linear.predict(X_test), "rbf":rbf.predict(X_test), "poly":poly.predict(X_test) } plt.figure(figsize=(8,6)) plt.scatter(X, y, color="black", label="True") for key, y_ in result.items(): plt.plot(X_test, y_, label=key) plt.legend() #由此可见,非分线性数据的处理还是rbf内核更强
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34

K均值算法(K-means)聚类
- K-means算法原理
聚类的概念:一种无监督的学习,事先不知道类别,自动将相似的对象归到同一个簇中。
K-Means算法是一种聚类分析(cluster analysis)的算法,其主要是来计算数据聚集的算法,主要通过不断地取离种子点最近均值的算法。
K-Means算法主要解决的问题如下图所示。我们可以看到,在图的左边有一些点,我们用肉眼可以看出来有四个点群,但是我们怎么通过计算机程序找出这几个点群来呢?于是就出现了我们的K-Means算法

这个算法其实很简单,如下图所示:

从上图中,我们可以看到,A,B,C,D,E是五个在图中点。而灰色的点是我们的种子点,也就是我们用来找点群的点。有两个种子点,所以K=2。
然后,K-Means的算法如下:
-
随机在图中取K(这里K=2)个种子点。
-
然后对图中的所有点求到这K个种子点的距离,假如点Pi离种子点Si最近,那么Pi属于Si点群。(上图中,我们可以看到A,B属于上面的种子点,C,D,E属于下面中部的种子点)
-
接下来,我们要移动种子点到属于他的“点群”的中心。(见图上的第三步)
-
然后重复第2)和第3)步,直到,种子点没有移动(我们可以看到图中的第四步上面的种子点聚合了A,B,C,下面的种子点聚合了D,E)。
这个算法很简单,重点说一下“求点群中心的算法”:欧氏距离(Euclidean Distance):差的平方和的平方根
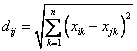
-
K-Means主要最重大的缺陷——都和初始值有关:
K是事先给定的,这个K值的选定是非常难以估计的。很多时候,事先并不知道给定的数据集应该分成多少个类别才最合适。(ISODATA算法通过类的自动合并和分裂,得到较为合理的类型数目K)
K-Means算法需要用初始随机种子点来搞,这个随机种子点太重要,不同的随机种子点会有得到完全不同的结果。(K-Means++算法可以用来解决这个问题,其可以有效地选择初始点) -
总结:K-Means算法步骤:
- 从数据中选择k个对象作为初始聚类中心;
- 计算每个聚类对象到聚类中心的距离来划分;
- 再次计算每个聚类中心
- 计算标准测度函数,直到达到最大迭代次数,则停止,否则,继续操作。
- 确定最优的聚类中心
-
K-Means算法应用
- 1)如果不是二维的,是多维的,如5维的,那么,就只能用计算机来计算了。
- 2)二维坐标点的X,Y 坐标,其实是一种向量,是一种数学抽象。现实世界中很多属性是可以抽象成向量的,比如,我们的年龄,我们的喜好,我们的商品,等等,能抽象成向量的目的就是可以让计算机知道某两个属性间的距离。如:我们认为,18岁的人离24岁的人的距离要比离12岁的距离要近,鞋子这个商品离衣服这个商品的距离要比电脑要近,等等。
-
分类和聚类的区别
- Classification (分类),对于一个classifier,通常需要你告诉它“这个东西被分为某某类”这样一些例子,理想情况下,一个 classifier 会从它得到的训练集中进行“学习”,从而具备对未知数据进行分类的能力,这种提供训练数据的过程通常叫做supervised learning (监督学习),
- Clustering (聚类),简单地说就是把相似的东西分到一组,聚类的时候,我们并不关心某一类是什么,我们需要实现的目标只是把相似的东西聚到一起。因此,一个聚类算法通常只需要知道如何计算相似度就可以开始工作了,因此 clustering 通常并不需要使用训练数据进行学习,这在Machine Learning中被称作unsupervised learning (无监督学习).
-
常见的分类和聚类算法
- 所谓分类,简单来说,就是根据文本的特征或属性,划分到已有的类别中。如在自然语言处理NLP中,我们经常提到的文本分类便就是一个分类问题,一般的模式分类方法都可用于文本分类研究。常用的分类算法包括:决策树分类法,朴素贝叶斯分类算法(native Bayesian classifier)、基于支持向量机(SVM)的分类器,神经网络法,k-最近邻法(k-nearestneighbor,kNN),模糊分类法等等。
- 分类作为一种监督学习方法,要求必须事先明确知道各个类别的信息,并且断言所有待分类项都有一个类别与之对应。但是很多时候上述条件得不到满足,尤其是在处理海量数据的时候,如果通过预处理使得数据满足分类算法的要求,则代价非常大,这时候可以考虑使用聚类算法。
- 而K均值(K-mensclustering)聚类则是最典型的聚类算法(当然,除此之外,还有很多诸如属于划分法K中心点(K-MEDOIDS)算法、CLARANS算法;属于层次法的BIRCH算法、CURE算法、CHAMELEON算法等;基于密度的方法:DBSCAN算法、OPTICS算法、DENCLUE算法等;基于网格的方法:STING算法、CLIQUE算法、WAVE-CLUSTER算法;基于模型的方法)。
KMeans(n_clusters=8, init='k-means++', n_init=10, max_iter=300, tol=0.0001, precompute_distances='auto', verbose=0, random_state=None, copy_x=True, n_jobs=1, algorithm='auto')
- 重要参数:
n_clusters:聚类的个数
- 重要属性:
clustercenters : [n_clusters, n_features]的数组,表示聚类中心点的坐标
labels_ : 每个样本点的标签
- 1
- 2
- 3
- 4
- 5
- 6
- 案例:聚类实例
# 1、导包,使用make_blobs生成随机点cluster_std import numpy as np import pandas as pd from pandas import Series,DataFrame import matplotlib.pyplot as plt %matplotlib inline from sklearn.datasets import make_blobs X, y = make_blobs(n_samples=150, n_features=2, centers=3, cluster_std=2) #2、建立模型,训练数据,并进行数据预测,使用相同数据 from sklearn.cluster import KMeans # n_clusters 表示要聚类的个数 km = KMeans(n_clusters=3) # 无监督学习,没有标签 #km.fit(X) #y_ = km.predict(X) # 无监督学习都实现了如下方法,可以同时学习并预测(次品转换tfidfvectorizer也是无监督) y_ = km.fit_predict(X) # 3、封装函数绘制散点图 def show_result(X, y, y_, suptitle): # X 待聚类的样本集 # y 样本集的真实标签 # y_ 聚类得到的预测标签 figure = plt.figure(figsize=(24,12)) ax1 = plt.subplot(1,2,1) ax1.set_title("True") ax1.scatter(X[:,0], X[:,1], c=y) ax2 = plt.subplot(1,2,2) ax2.set_title("Predict") ax2.scatter(X[:,0], X[:,1], c=y_) figure.suptitle(suptitle, fontsize=30, color="green") #4 、聚类实践与常见错误 # 第一种错误,k值不合适,make_blobs默认中心点三个 kmean = KMeans(n_clusters=5) y_ = kmean.fit_predict(X) show_result(X, y, y_, "n_cluster error") #第二种错误,数据偏差 trans = [[0.6,-0.6],[-0.4,0.8]] X2 = np.dot(X,trans) kmeans = KMeans(n_clusters=3) y_ = kmeans.fit_predict(X2) show_result(X, y, y_,"data trans") #第三个错误:标准偏差不相同cluster_std X, y = make_blobs(n_samples=150, n_features=2, centers=3, cluster_std=[1,3,8]) plt.scatter(X[:,0], X[:,1], c=y) kmean = KMeans(n_clusters=3) y_ = kmean.fit_predict(X) show_result(X, y, y_, "different cluster std") #第四个错误:样本数量不同 X, y = make_blobs(n_samples=1500, n_features=2, centers=3) X1 = X[y==0][:100] X2 = X[y==1][:40] X3 = X[y==2][:10] y = [0]*100 + [1]*40 + [2]*10 train = np.concatenate((X1, X2, X3)) kmeans = KMeans(n_clusters=3) y_ = kmeans.fit_predict(train) show_result(train, y, y_, "different samples")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
k值不合适

数据偏差

标准偏差不相同

样本数量不同

- 案例:世界足球队的表(显示聚类中心点kmeans.cluster_centers)
# 1、获取数据并分析 df = pd.read_csv('../data/AsiaZoo.txt', header=None) df.columns = ["国家","2006世界杯","2010世界杯","2007亚洲杯"] #2、使用模型训练数据 # 把亚洲球队分成三个组 kmeans = KMeans(n_clusters=3) train = df.loc[:,"2006世界杯":"2007亚洲杯"] y_ = kmeans.fit_predict(train) ==> array([0, 1, 1, 2, 2, 0, 0, 0, 2, 0, 0, 0, 2, 2, 0]) #3、导包,3D图像需导包: centers = kmeans.cluster_centers_ ==> array([[ 50. , 47.5, 7.5], [ 22.5, 12. , 3.5], [ 34.6, 38.4, 7.6]]) from mpl_toolkits.mplot3d import Axes3D plt.figure(figsize=(12,8)) ax = plt.subplot(projection = '3d') ax.scatter3D(train.iloc[:,0], train.iloc[:,1], train.iloc[:,2], s=80, c=y_) ax.scatter3D(centers[:,0], centers[:,1], centers[:,2], c="red", s=100, alpha=1) ax.set_xlabel("2006-world-cup") ax.set_ylabel("2010-wrold-cup") ax.set_zlabel("2007-asia-cup")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26

- 案例:图片压缩(核心思想:把图片颜色数据聚类分析成N个类别,用中心点颜色替换其他颜色)
img = plt.imread('meizi.jpg') #把jpg格式的图片变为png img1 = img.astype(np.float32)/255 # 保留第三维数据,把一张图片看成是若干个像素的样本集 train = img.reshape(-1, 3) from sklearn.cluster import KMeans # n_clusters 表示要聚类的个数 km = KMeans(n_clusters=5) y_ = kmeans.fit_predict(train) # 获取聚类中心 colors = kmeans.cluster_centers_/255 ==> array([[ 0.74193717, 0.67788181, 0.65664397], [ 0.97098806, 0.97478961, 0.97778226], [ 0.57589037, 0.50163799, 0.49412296], [ 0.8664354 , 0.86114772, 0.86019593], [ 0.28507747, 0.25176661, 0.3081087 ]]) # 使用聚类中心点去填充照片 new_img = colors[y_].reshape(img.shape) plt.imshow(new_img)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
原图

聚类后的图像

特征工程
- 什么是特征工程?
数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。
特征工程,其本质是一项工程活动,特征工程是机器学习里面非常重要的一个部分,机器学习主要就是根据我们从数据中获取到的特征数据,来得到对结果的预测,一般来说对结果影响最大的特征,需要重点观察,而对结果影响不大的特征属性需要排除出来,避免对预测结果产生不利影响。 - 特征工程的作用:
- 从数据中抽取出对预测结果有用的信息
- 从数据中构建出对结果有用的信息
- 更好的特征能更高效的实现
- 更好的特征能在比较简单的模型中也能得到比复杂模型都好的拟合能力
数据挖掘流程

数据预处理
数据预处理是特征工程的核心
- from sklearn.preprocessing
缺失值计算(Imputer)
- from sklearn.preprocessing import Imputer
- 格式
Imputer(missing_values='NaN', strategy='mean', axis=0, verbose=0, copy=True)
#参数:
strategy 缺失值的填充方式,mean,median,most_frequent 默认取一列的平均值
axis 配合stategy使用
- 1
- 2
- 3
- 4
- 例子
from sklearn.preprocessing import Imputer
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
data = np.random.randint(0,100,size=(5,3))
df = DataFrame(data=data, columns=list("ABC"))
df.loc[0] = np.nan
Imputer(strategy="median").fit_transform(df)
#0行空值被该列的中位数填充
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
对定量特征 的二值化
定量特征二值化的核心在于设定一个阈值,大于阈值的赋值为1,小于等于阈值的赋值为0
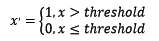
- 例子
from sklearn.preprocessing import Binarizer
from sklearn.datasets import load_iris
X, y = load_iris(return_X_y=True)
Binarizer(threshold=2).fit_transform(X)
#array([[ 1., 0., 1., ..., 0., 1., 1.],
# [ 1., 0., 1., ..., 0., 1., 1.],...])
- 1
- 2
- 3
- 4
- 5
- 6
对定性特征的哑编码
#将学生的性别转换为0或1
sex_data = LabelEncoder().fit_transform(student["sex"])
#
student["Mjob"].unique() ==>array(['at_home', 'health', 'other', 'services', 'teacher'], dtype=object)
# 转化为0,1,2,3,4,
sex_data = LabelEncoder().fit_transform(student["Mjob"])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 独热编码
注意:待转换的数据需要以列向量的方式表示
#实现方法 #1.使用pandas的get_dummies方法 df = DataFrame({"A":['a','b','c'],'B':['b','a','c'],"C":[1,2,3]}) pd.get_dummies(df,prefix=["col1","col2"]) ==> C col1_a col1_b col1_c col2_a col2_b col2_c 0 1 1 0 0 0 1 0 1 2 0 1 0 1 0 0 2 3 0 0 1 0 0 1 # sklearn实现 from sklearn import preprocessing enc = preprocessing.OneHotEncoder() enc.fit([[0, 0, 3], [1, 1, 0], [0, 2, 1], [1, 0, 2]]) # fit来学习编码 enc.transform([[0, 1, 3]]).toarray() # 进行编码 输出:array([[ 1., 0., 0., 1., 0., 0., 0., 0., 1.]]) 数据矩阵是4*3,即4个数据,3个特征维度。 0 0 3 观察左边的数据矩阵,第一列为第一个特征维度,有两种取值0\1. 所以对应编码方式为10 、01 1 1 0 同理,第二列为第二个特征维度,有三种取值0\1\2,所以对应编码方式为100、010、001 0 2 1 同理,第三列为第三个特征维度,有四中取值0\1\2\3,所以对应编码方式为1000、0100、0010、0001 1 0 2 再来看要进行编码的参数[0 , 1, 3], 0作为第一个特征编码为10, 1作为第二个特征编码为010, 3作为第三个特征编码为0001. 故此编码结果为 1 0 0 1 0 0 0 0 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
无量纲化
为什么要做无量纲化处理:
数据的量级不同,在很多算法中,会影响算法的准确度,往往量级越大,对结果的影响也越大,这可能与真实情况不符。
所以应该消除这个量级对算法结果的影响
- 区间缩放法(列方向缩放)
利用了边界值信息,将特征的取值区间缩放到某个特点的范围,例如[0, 1]等
返回值为缩放到[0, 1]区间的数据
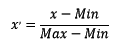
from sklearn.datasets import load_wine
X, y = load_wine(return_X_y=True)
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier()
knn.fit(X, y)
knn.score(X, y) ==>0.7865168539325843
#区间缩放处理
from sklearn.preprocessing import MinMaxScaler
X1 = MinMaxScaler().fit_transform(X)
knn.fit(X1, y)
knn.score(X1, y) ==>0.97752808988764039
# 算法的评分有了明显的提升
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 标准化(列方向)
标准化的前提是特征值服从正态分布,标准化后,其转换成标准正态分布。
标准化需要计算特征的均值和标准差
其中S为标准差
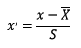
from sklearn.preprocessing import StandardScaler
X2 = StandardScaler().fit_transform(X)
knn.fit(X2, y)
knn.score(X2, y) ==>0.97752808988764039
- 1
- 2
- 3
- 4
- 归一化(行方向)
标准化是依照特征矩阵的列处理数据,其通过求z-score的方法,将样本的特征值转换到同一量纲下。归一化是依照特征矩阵的行处理数据,其目的在于样本向量在点乘运算或其他核函数计算相似性时,拥有统一的标准,也就是说都转化为“单位向量”。
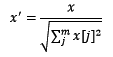
from sklearn.preprocessing import Normalizer
X3 = Normalizer().fit_transform(X)
knn.fit(X3, y)
knn.score(X3, y) ==>0.8820224719101124
- 1
- 2
- 3
- 4
- 5
特征选择
-
按照特征是否发散选择
如果一个特征不发散,例如方差接近于0,也就是说样本在这个特征上基本上没有差异,这个特征对于样本的区分并没有什么用。 -
按照特征与目标的相关性强弱选择
-
依据经验选择
实现方式:
- 基于方差选择
特征提取 一般指在原始特征上进行的经验选择
特征选择 一般指算法选择,可以应用在原始特征上和非原始特征上
from sklearn.feature_selection import VarianceThreshold from sklearn.datasets import load_iris import pandas as pd from pandas import Series,DataFrame import numpy as np import matplotlib.pyplot as plt %matplotlib inline iris = load_iris() data = iris.data target = iris.target feature_names = iris.feature_names df = DataFrame(data=data, columns=feature_names) df.describe() #删除所有低方差特性的特性选择器,参数threshold为方差的阈值 data1 = VarianceThreshold(threshold=0.6).fit_transform(data) plt.scatter(data1[:,0], data1[:,1], c=target)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16

- 递归特征消除法
递归消除特征法使用一个基模型来进行多轮训练,每轮训练后,消除若干权值系数的特征,再基于新的特征集进行下一轮训练。
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
#递归特征消除法,返回特征选择后的数据
#参数estimator为基模型
#参数n_features_to_select为选择的特征个数
#【注意】不同的算法,可能得到的重要特征也不一致,所以应该多参考
RFE(estimator=DecisionTreeClassifier(max_depth=2), n_features_to_select=2).fit_transform(data, target)
RFE(estimator=LogisticRegression(),n_features_to_select=2).fit_transform(data,target)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 基于惩罚项的特征选择法
使用带惩罚项的基模型,除了筛选出特征外,同时也进行了降维。
from sklearn.feature_selection import SelectFromModel
# 越小,对误差的宽容度越小,越容易过拟合
SelectFromModel(LogisticRegression(penalty='l2', C=0.1)).fit_transform(data, target)
- 1
- 2
- 3
- 4
- 基于树模型的特征选择法
树模型中GBDT也可用来作为基模型进行特征选择,使用feature_selection库的SelectFromModel类结合GBDT模型
gbdt = GradientBoostingClassifier()
gbdt.fit(data, target)
gbdt.feature_importances_.mean() ==>0.23166666666666669
from sklearn.ensemble import GradientBoostingClassifier
#以均值作为阈值,大于 feature_importances_的均值的列就选择
SelectFromModel(GradientBoostingClassifier(),threshold="mean").fit_transform(data, target)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
参数调整
网格搜索
自动调参
# 使用GridSearchCV自动调参 网格验证
from sklearn.model_selection import GridSearchCV
svc = SVC()
paramas = {
'kernel':('linear','rbf'),
'C':[0.001,0.005,0.1,1,10,100,1000],
'gamma':[0.01,0.1,1,10,100,100,10000]
}
clf1 = GridSearchCV(svc,param_grid=paramas)
# 训练
clf1.fit(data,target)
# 获取最优解
clf1.best_estimator_
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 案例:鸢尾花数据
from sklearn.datasets import load_iris from sklearn.svm import SVC from sklearn.model_selection import GridSearchCV #1、构建GidSearchCV算法 svc = SVC() # 第一次调参可以把参数范围放大 # 第二次\第三次依次去缩小参数的范围 pramas = { "kernel":["linear","rbf"], "gamma":[0.1,1,10,20], "C":[0.01, 0.1, 1 , 2, 10, 100] } # gscv就可以当成一个算法模型来使用 gscv = GridSearchCV(svc, param_grid=pramas) #2、训练数据 X, y = load_iris(return_X_y=True) gscv.fit(X, y) ## 获取最优参数解 gscv.best_params_ #获取评分 gscv.score(X, y)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
交叉验证( KFold)
在机器学习建模过程中,通行的做法通常是将数据分为训练集和测试集。测试集是与训练独立的数据,完全不参与训练,用于最终模型的评估。在训练过程中,经常会出现过拟合的问题,就是模型可以很好的匹配训练数据,却不能很好在预测训练集外的数据。如果此时就使用测试数据来调整模型参数,就相当于在训练时已知部分测试数据的信息,会影响最终评估结果的准确性。通常的做法是在训练数据再中分出一部分做为验证(Validation)数据,用来评估模型的训练效果。
验证数据取自训练数据,但不参与训练,这样可以相对客观的评估模型对于训练集之外数据的匹配程度。模型在验证数据中的评估常用的是交叉验证,又称循环验证。它将原始数据分成K组(K-Fold),将每个子集数据分别做一次验证集,其余的K-1组子集数据作为训练集,这样会得到K个模型。这K个模型分别在验证集中评估结果,最后的误差MSE(Mean Squared Error)加和平均就得到交叉验证误差。交叉验证有效利用了有限的数据,并且评估结果能够尽可能接近模型在测试集上的表现,可以做为模型优化的指标使用。
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import KFold
# 自定制拆分数据集的个数
kfold = KFold(n_splits=10)
# 使用交叉验证函数按照自定制的拆分格式进行验证
results = cross_val_score(knn,data,target,cv=kfold)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 案例:
# 多次拆分不同的样本集,来获取同一个算法模型的不同数据集上的评分 # 重点在于 要多次对样本集进行拆分 from sklearn.model_selection import cross_val_score from sklearn.neighbors import KNeighborsClassifier # k折线拆分法 from sklearn.model_selection import KFold, train_test_split #knn模型的评分 kf = KFold(n_splits=10) res = cross_val_score(KNeighborsClassifier(), X, y, cv=kf) res.mean() ==>0.9333333333333333 res.std() ==>0.08432740427115676 # Logistic模型的评分 from sklearn.linear_model import LogisticRegression res1 = cross_val_score(LogisticRegression(solver="lbfgs", multi_class="auto"), X, y, cv=kf) res1.mean() ==>0.9466666666666667 res1.std() ==>0.0581186525805423
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
降维
-
降维、缩减系数、特征选择的区别:
- 缩减系数:
- 算法复杂度会降低
- 减少无用特征对预测结果的影响
- 数据可视化
通过算法计算,把不重要的特征的系数清0
- 特征选择:
- 经验选择
- 根据特征的重要程度,对特征进行选择, 通过算法实现(feature_importes_)
- 降维:
通过算法实现,把多个特征进行计算,得到更少的特征
会产生新的特征,但是会消除旧特征。
高维度—低维度 数据中包含的信息损失很少(可以控制损失) - SVM
低维度—高纬度
-
降维的作用:
1. 降低时间复杂度和空间复杂度- 节省了提取不必要特征的开销
- 去掉数据集中夹杂的噪
- 当数据能有较少的特征进行解释,我们可以更好 的解释数据,使得我们可以提取知识。
- 实现数据可视化
主成分分析法(PCA)
PCA通过线性变换将原始数据变换为一组各维度线性无关的表示,可用于提取数据的主要特征分量,常用于高维数据的降维
from sklearn.decomposition import PCA
# n_components=int 要降维的最终的维度
# n_components= 0.0~1.0之间的小数,表示要保留原始信息的完整度
pca = PCA(n_components=2)
from sklearn.datasets import load_iris
data = load_iris().data
target = load_iris().target
feature_names = load_iris().feature_names
# 无监督学习,不需要标签的参与
data1 = pca.fit_transform(data)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 比较降维和特征选择的优劣
# 获取GBDT计算的重要程度最高的两个特征 from sklearn.ensemble import GradientBoostingClassifier from sklearn.feature_selection import SelectFromModel gbdt = GradientBoostingClassifier() data2 = SelectFromModel(gbdt, threshold="mean").fit_transform(data, target) # 绘图展示 # data1 # pca得到的 # data2 # GBDT得到的 import matplotlib.pyplot as plt %matplotlib inline plt.figure(figsize=(12,5)) ax1 = plt.subplot(1,2,1) ax1.set_title("PCA_FEATURES") ax1.scatter(data1[:,0], data1[:,1], c=target) ax2 = plt.subplot(1,2,2) ax2.set_title("GBDT_IMPORTANCES") ax2.scatter(data2[:,0], data2[:,1], c=target) #评分 from sklearn.neighbors import KNeighborsClassifier # PCA的评分 knn = KNeighborsClassifier() knn.fit(data1, target) knn.score(data1, target) ==>0.97999999999999998 knn = KNeighborsClassifier() knn.fit(data2, target) knn.score(data2, target) ==>0.95999999999999996
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30

线性判别分析法(LDA)
- LDA 降维和PCA降维的比较
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis lda = LinearDiscriminantAnalysis(n_components=2) # 有监督学习, 需要填充标签 data3 = lda.fit_transform(data, target) # 绘图 plt.figure(figsize=(12,4)) ax1 = plt.subplot(1,2,1) ax1.set_title("PCA FEATURES") ax1.scatter(data1[:,0], data1[:,1], c=target) ax2 = plt.subplot(1,2,2) ax2.set_title("LDA FEATURES") ax2.scatter(data3[:,0], data3[:,1], c=target) # 评分 # LDA降维 knn.fit(data3, target) knn.score(data3, target) ==>0.97333333333333338 # PCA降维 knn.fit(data1, target) knn.score(data1, target) ==>0.97999999999999998
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25

- 人脸识别案例
#1.导入数据 import numpy as np import pandas as pd from pandas import Series,DataFrame import matplotlib.pyplot as plt %matplotlib inline from sklearn.datasets import load_iris from sklearn.datasets import fetch_lfw_people faces = fetch_lfw_people() faces.target_names.size Series(faces.target).value_counts() # 读取至少有70张照片的数据样本 # resize压缩比设置为原始尺寸 faces = fetch_lfw_people(min_faces_per_person=70, resize=1.0) np.random.seed(90) plt.imshow(faces.images[np.random.randint(0,1288,size=1)[0]], cmap="gray") #2、训练数据 from sklearn.neighbors import KNeighborsClassifier from sklearn.linear_model import LogisticRegression from sklearn.ensemble import GradientBoostingClassifier from sklearn.svm import SVC train = faces.data target = faces.target #计算各个算法训练时间 %%time lr = LogisticRegression() lr.fit(train, target) lr.score(train, target) %%time knn = KNeighborsClassifier() knn.fit(train, target) %%time knn.score(train, target) %%time svc = SVC(kernel="linear") svc.fit(train, target) %%time svc.score(train, target) # 3、绘制人脸的主要特征 from sklearn.ensemble import ExtraTreesClassifier X = train[:50] y = target[:50] gbdt = ExtraTreesClassifier(n_estimators=1000, max_features=128) gbdt.fit(X, y) plt.imshow(gbdt.feature_importances_.reshape(125,94), cmap=plt.cm.hot) # 4、计算出最佳参数(网格搜索) from sklearn.model_selection import GridSearchCV svc = SVC() pramas = { "kernel":["linear","rbf"], "C":[0.01,0.1,1,10,100], "gamma":[0.001,0.01,0.1,1,10,100] } grid_cv = GridSearchCV(svc, pramas) grid_cv.fit(train, target) # 5、降维 from sklearn.decomposition import PCA pca = PCA(n_component=0.95) pca_train = pca.fit_transform(train)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
算法选择
集成学习
VC的预测结果,是其所有的算法模型投票产生的
- 原理分析
from sklearn.linear_model import LogisticRegression from sklearn.svm import SVC from sklearn.tree import DecisionTreeClassifier estimators=[] #列表 model1=LogisticRegression() model2=SVC() model3=DecisionTreeClassifier() estimators.append(("LogisticRegression",model1)) estimators.append(("SVC",model2)) estimators.append(("DecisionTreeClassifier",model3)) #VotingClassfier from sklearn.ensemble import VotingClassifier vc = VotingClassifier(estimators) import numpy as np X = np.random.randint(0,100,size=(10,2)) y = [0,1,1,1,0,0,0,1,1,0] vc.fit(X, y) vc.predict(X) ==>array([0, 1, 1, 1, 0, 0, 0, 1, 1, 0]) vc.estimators_[0].predict(X) ==>array([0, 1, 0, 1, 1, 0, 0, 0, 1, 0], dtype=int64) vc.estimators_[1].predict(X) ==>array([0, 1, 1, 1, 0, 0, 0, 1, 1, 0], dtype=int64) vc.estimators_[2].predict(X) ==>array([0, 1, 1, 1, 0, 0, 0, 1, 1, 0], dtype=int64)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 案例:使用集成学习分析小麦种类
#1、导包 import pandas as pd import numpy as np from sklearn.linear_model import LogisticRegression from sklearn.svm import SVC from sklearn.tree import DecisionTreeClassifier from sklearn import model_selection from sklearn.ensemble import VotingClassifier #集成学习 #2、读取数据 data = pd.read_table('seeds.csv',header=None) data.head() array=data.values X=array[:,0:7] Y=array[:,-1] #3、模型选择器,随机打乱 #模型选择器,随机打乱,用于筛选判断算法的强度 kfold=model_selection.KFold(n_splits=10,random_state=7) #4、继承学习,寻找最优解 estimators=[] #列表 model1=LogisticRegression() model2=SVC() model3=DecisionTreeClassifier() estimators.append(("LogisticRegression",model1)) estimators.append(("SVC",model2)) estimators.append(("DecisionTreeClassifier",model3)) #算法集成工具,集成学习 ensemble=VotingClassifier(estimators) results=model_selection.cross_val_score(ensemble,X,Y,cv=kfold) #集成 print(results,results.mean()) results.max() ensemble.fit(X,Y) ensemble.predict(X) ensemble.score(X,Y)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
模型评价指标
分类评价
-
score
预测正确的数据量与总预测数据量的比值。 -
f1_score
适用于二分类问题- 查准率(precision):正样本中,真实正样本的比例
- 查全率(recall):真实的正样本中,被正确预测的比例
- 分类结果混淆矩阵:

- P-R图

其中,对角线表示查准率==查全率时的取值,该线与PR曲线相交的点称为“平衡点(Break-Even-Point)简称BEP”
对于算法B的PR曲线完全包裹了C,说明B优于C
当不同模型的PR曲线出现A\B两条线相交的情况,无法判定,此时可以借助BEP来衡量算法优劣 - 公式:f1是BEP的进化版,能更好的衡量模型优劣
from sklearn.metrics import f1_score
f1_score(y_test, y1)
-
ROC与AUE
- 真正例率:TP/(TP+FN)
- 假正例率FPR:FP/(TN+FP)

回归器性能评价
from sklearn.metrics
这些函数都有一个参数“multioutput”,用来指定在多目标回归问题中,若干单个目标变量的损失或得分以什么样的方式被平均起来
它的默认值是“uniform_average”,他就是将所有预测目标值的损失以等权重的方式平均起来
如果你传入了一个shape为(n_oupputs,)的ndarray,那么数组内的数将被视为是对每个输出预测损失(或得分)的加权值,所以最终的损失就是按照你锁指定的加权方式来计算的
如果multioutput是“raw_values”,那么所有的回归目标的预测损失或预测得分都会被单独返回一个shape是(n_output)的数组中
-
explained_variance_score()

#explained_variance_score
from sklearn.metrics import explained_variance_score
y_true=[3,-0.5,2,7]
y_pred=[2.5,0.0,2,8]
print(explained_variance_score(y_true,y_pred))
y_true=[[0.5,1],[-1,1],[7,-6]]
y_pred=[[0,2],[-1,2],[8,-5]]
print(explained_variance_score(y_true,y_pred,multioutput="raw_values"))
print(explained_variance_score(y_true,y_pred,multioutput=[0.3,0.7]))
#结果
#0.957173447537
#[ 0.96774194 1. ]
#0.990322580645
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- mean_absolute_error()

#mean_absolute_error from sklearn.metrics import mean_absolute_error y_true=[3,0.5,2,7] y_pred=[2.5,0.0,2,8] print(mean_absolute_error(y_true,y_pred)) y_true=[[0.5,1],[-1,1],[7,-6]] y_pred=[[0,2],[-1,2],[8,-5]] print(mean_absolute_error(y_true,y_pred)) print(mean_absolute_error(y_true,y_pred,multioutput="raw_values")) print(mean_absolute_error(y_true,y_pred,multioutput=[0.3,0.7])) #结果 #0.5 #0.75 #[ 0.5 1. ] #0.85
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- mean_squared_error()
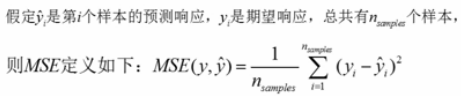
#mean_squared_error
from sklearn.metrics import mean_squared_error
y_true=[3,-0.5,2,7]
y_pred=[2.5,0.0,2,8]
print(mean_squared_error(y_true,y_pred))
y_true=[[0.5,1],[-1,1],[7,-6]]
y_pred=[[0,2],[-1,2],[8,-5]]
print(mean_squared_error(y_true,y_pred))
#结果
#0.375
#0.708333333333
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- r2_score()
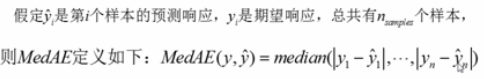
#median_absolute_error
from sklearn.metrics import median_absolute_error
y_true=[3,-0.5,2,7]
y_pred=[2.5,0.0,2,8]
print(median_absolute_error(y_true,y_pred))
#结果
#0.5
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 以上四个函数的相同点:
这些函数都有一个参数“multioutput”,用来指定在多目标回归问题中,若干单个目标变量的损失或得分以什么样的方式被平均起来
它的默认值是“uniform_average”,他就是将所有预测目标值的损失以等权重的方式平均起来
如果你传入了一个shape为(n_oupputs,)的ndarray,那么数组内的数将被视为是对每个输出预测损失(或得分)的加权值,所以最终的损失就是按照你锁指定的加权方式来计算的
如果multioutput是“raw_values”,那么所有的回归目标的预测损失或预测得分都会被单独返回一个shape是(n_output)的数组中

