
- 1深度学习在目标检测中的革命性应用与进展
- 2Linux开发项目(一)
- 3手工微调embedding模型,让RAG应用检索能力更强_rag基于用户反馈的embedding模型微调方法
- 4一键进阶ComfyUI!懂AI的设计师现在都在用的节点式Stable Diffusion!_comfyui高阶
- 5无法找到该证书的颁发者_计算机专业应该考这些证书!
- 6C++STL容器——string类(2)——成员函数详解_c++ string reserve
- 7数据库-DDL(操作数据库和表)&DML(增删改表中数据)&DQL(查询表中数据)&DCL(管理用户,授权)详解_pg库dba用户查询dml记录
- 8PostgreSQL事件触发器实战教程_pssql 事件
- 9python tfidf特征变换_Spark MLlib机器学习开发指南(4)--特征提取--TF-IDF
- 10Flarum部署:从源码到docker到放弃
swin-transformer_swin transformer
赞
踩
面向视觉任务的transfomer
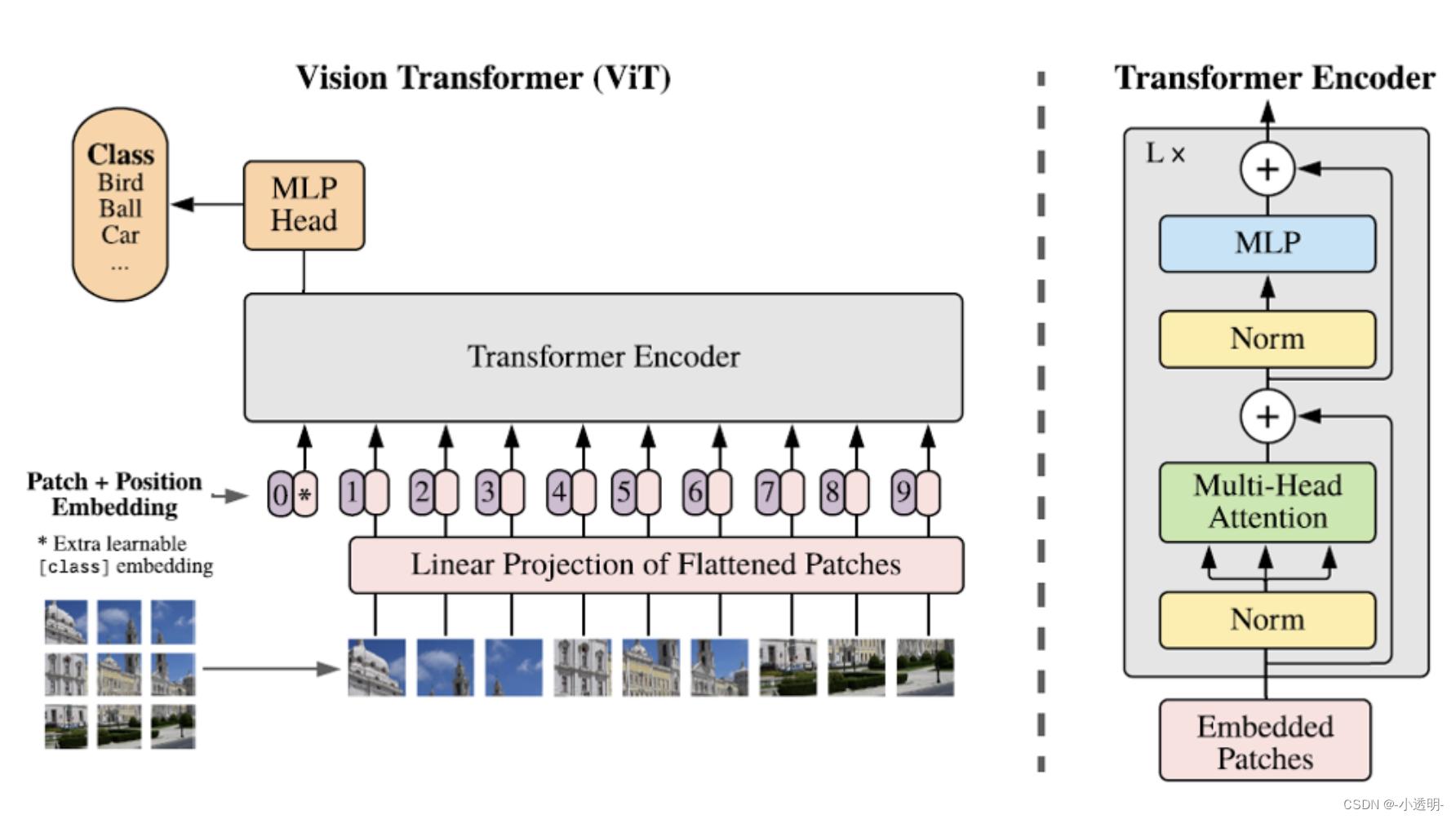
Vision Transformer(ViT)在视觉任务中的局限性
-
需求数据量巨大
CNN中是图像整体输入,并且经过多年的演变,发展出了多个不同的优化策略。从而在学习时能够在一定先验知识的前提下拟合数据。
而transformer是将图像切割成若干较小的patch,并拉伸成向量。从而难以获得图像关联信息,缺少大量先验知识。
对此,需要从大量数据中学习这些先验知识。大量例子证明,在数据量足够充分的前提下,transformer能够获得比CNN更好的效果。
但是在小规模数据中,由于无法有效学习到数据的先验知识,反而会比CNN更低。
-
计算量大
事实上,transformer所包含的参数通常要大于CNN。
其主要原因在于:transformer的模型结构就导致学习数据非常的难,因此需要更多的hidden layer来学习数据的本质分布。
为了达到这一目的,通常要累加很多层transoformer结构,因此也更加的庞大。
在视觉领域中的具体困难
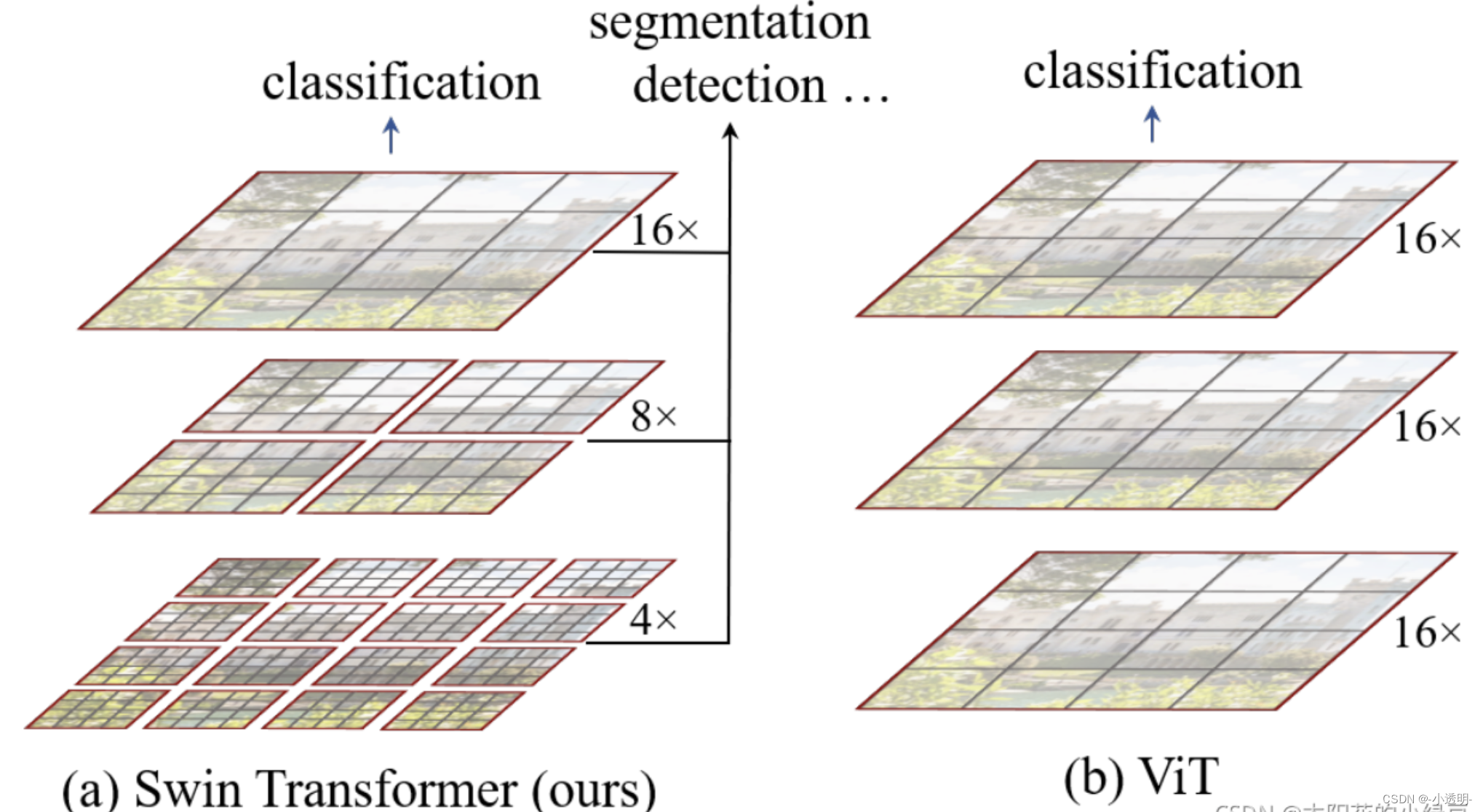
1. 大尺寸图像计算量爆炸
2. 尺度固定为16*16
Swin transformer的解决之道:用CNN的精神
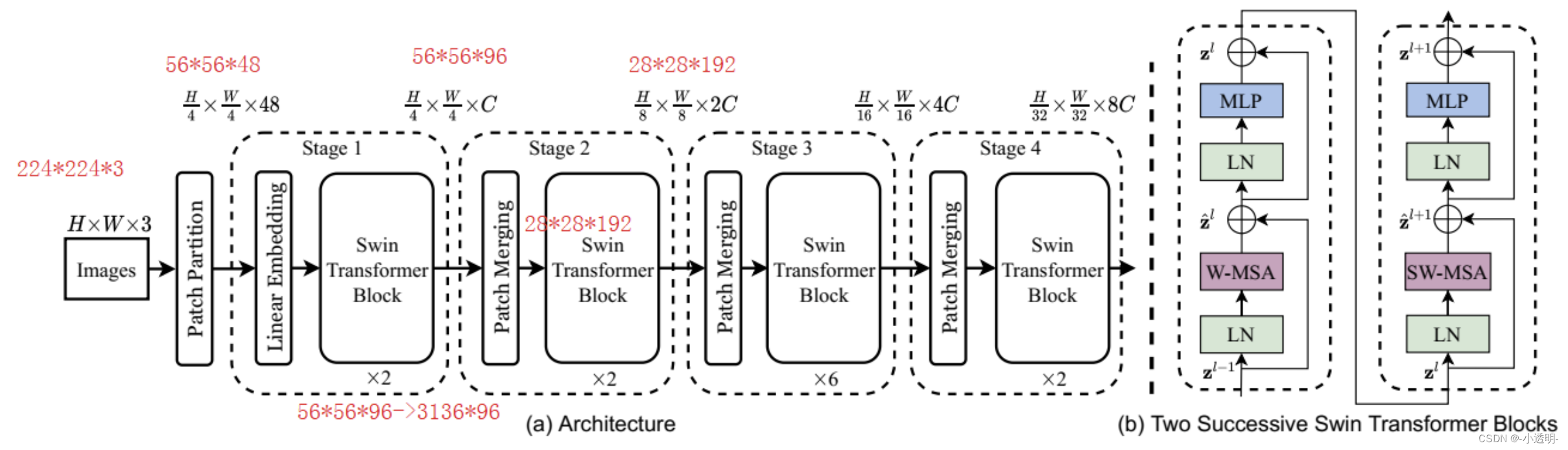
swin-transformer结构图
按照"长宽各减一半,channel数增加一倍"的‘规则’进行
transformer需要大量数据原因之一:因为将先验知识(序列或图片切成小patch拉成一个向量)结构被破坏,因此需要更多的数据去训练。
swin与vit不同的是:不与所有的token做相关性,而是跟它相近的(周边邻域(4个或5个))token做相关性,感受野逐渐扩大,与cnn神似;
线性变换降维:通过mlp或1*1卷积进行降维
patch partition:将图片分割成小块block(如:win size: 7*7),在通过1*1卷积将通道数3变为48
swin transformer用CNN的方式去构建网络,用卷积局部化的思想,基于self-attention的方式去搭建网络,实现图像编码
其中主要包含3个主要内容:
-
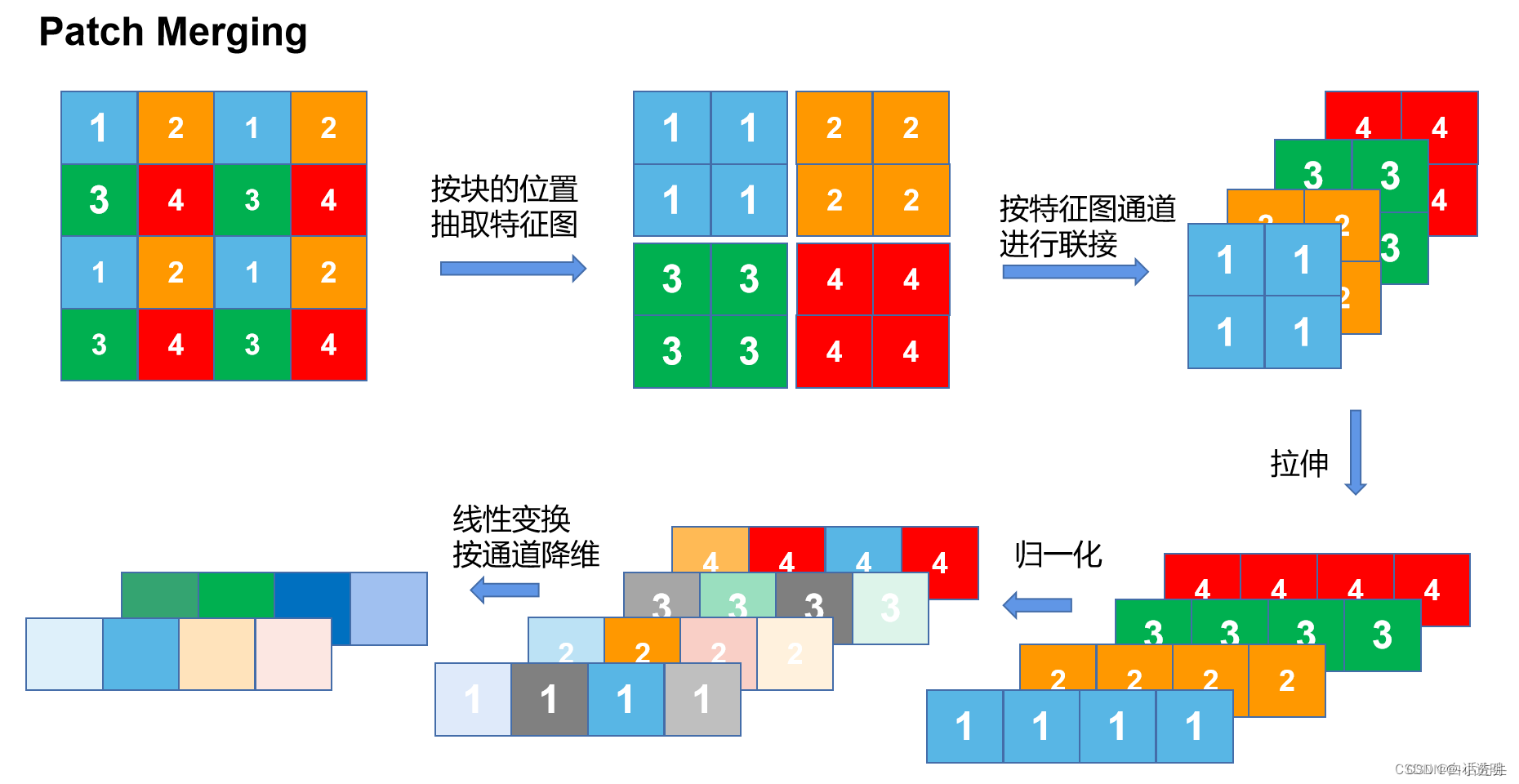
patch partition: 类似于池化
-
shift操作:令不同token之间有通信,减少计算量
-
相对位置编码:进一步加强token之间的上下文关系
patch partition
MSA和WMSA
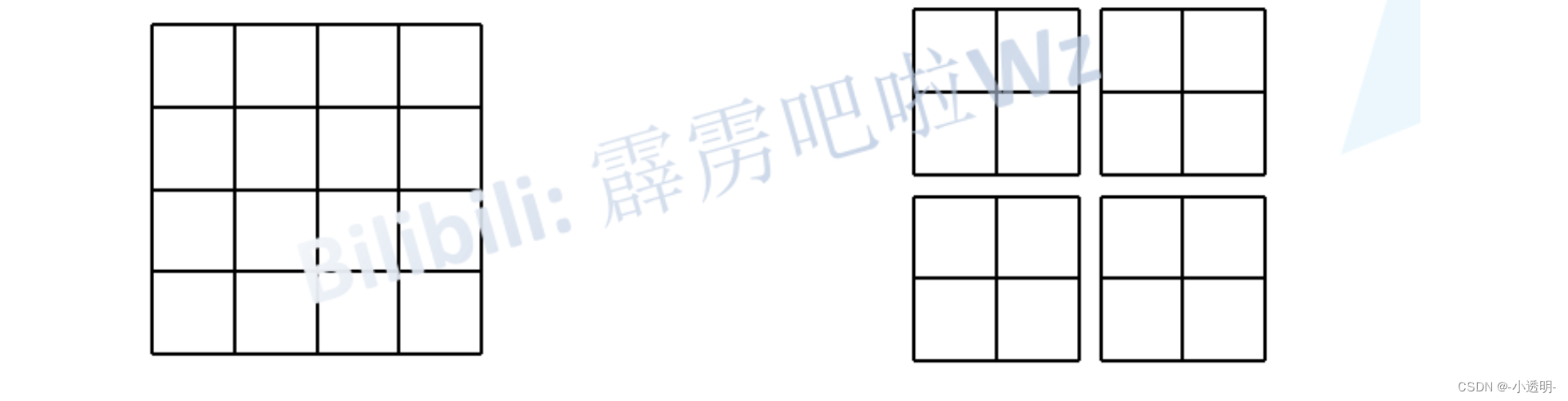
复杂度比较
对于MSA的复杂度大约为:

对于W MSA来说

M:切割后的尺寸,如上图:M=2 ,但每个block之间没有关联起来,解决:shift
shift操作
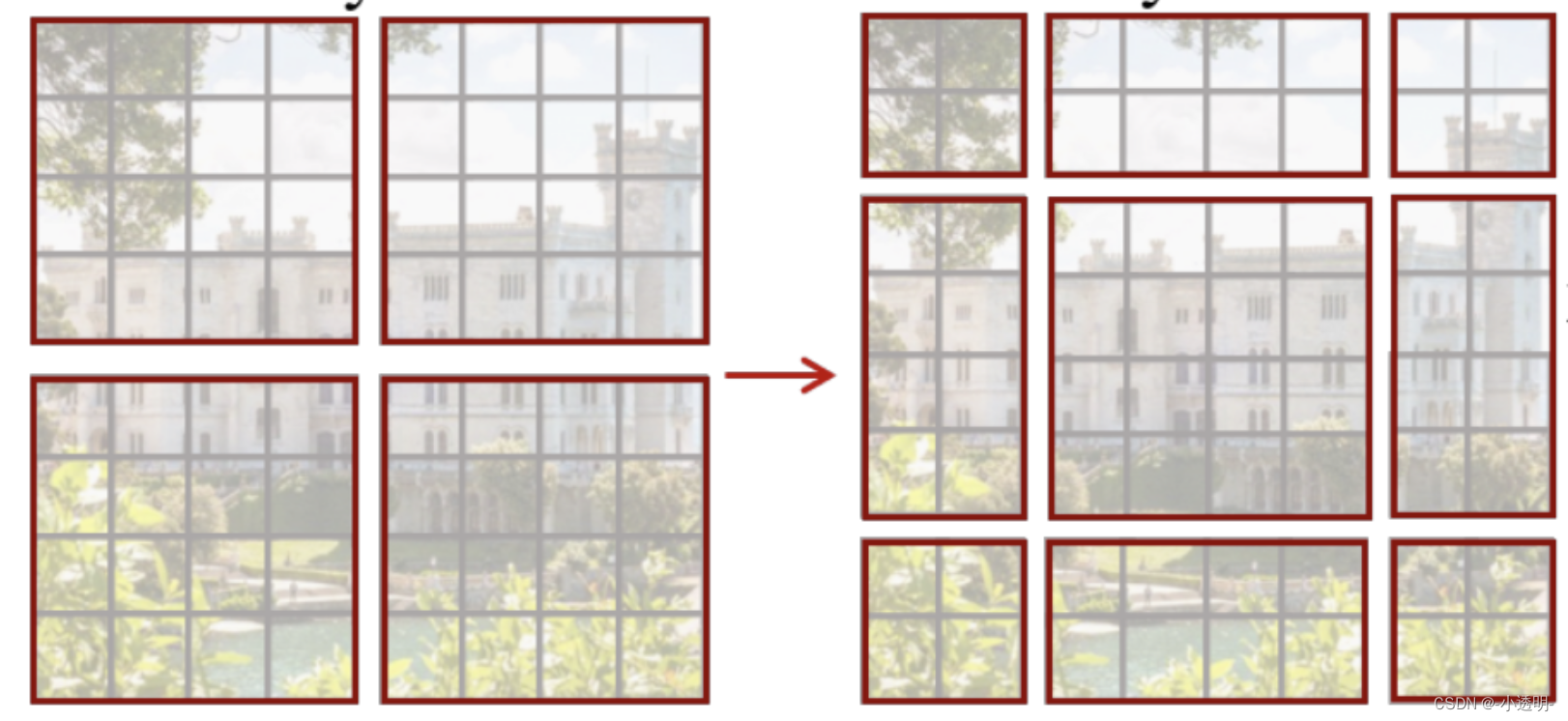
问题:原来4个token,现在变成9个token了
解决:挪动一些token
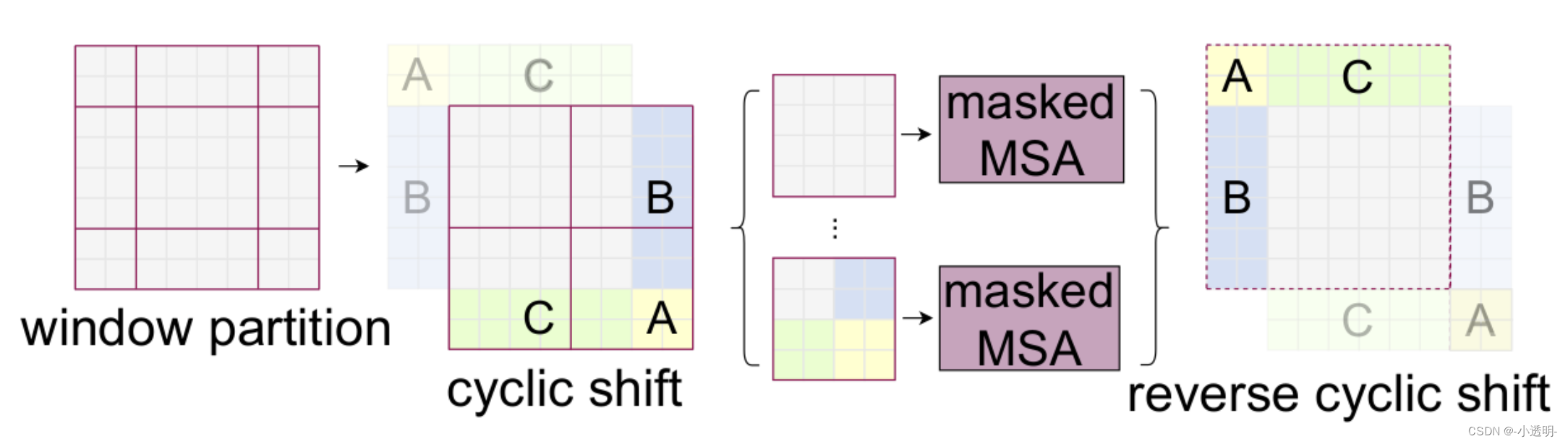
新问题:特征乱窜
解决: 加mask
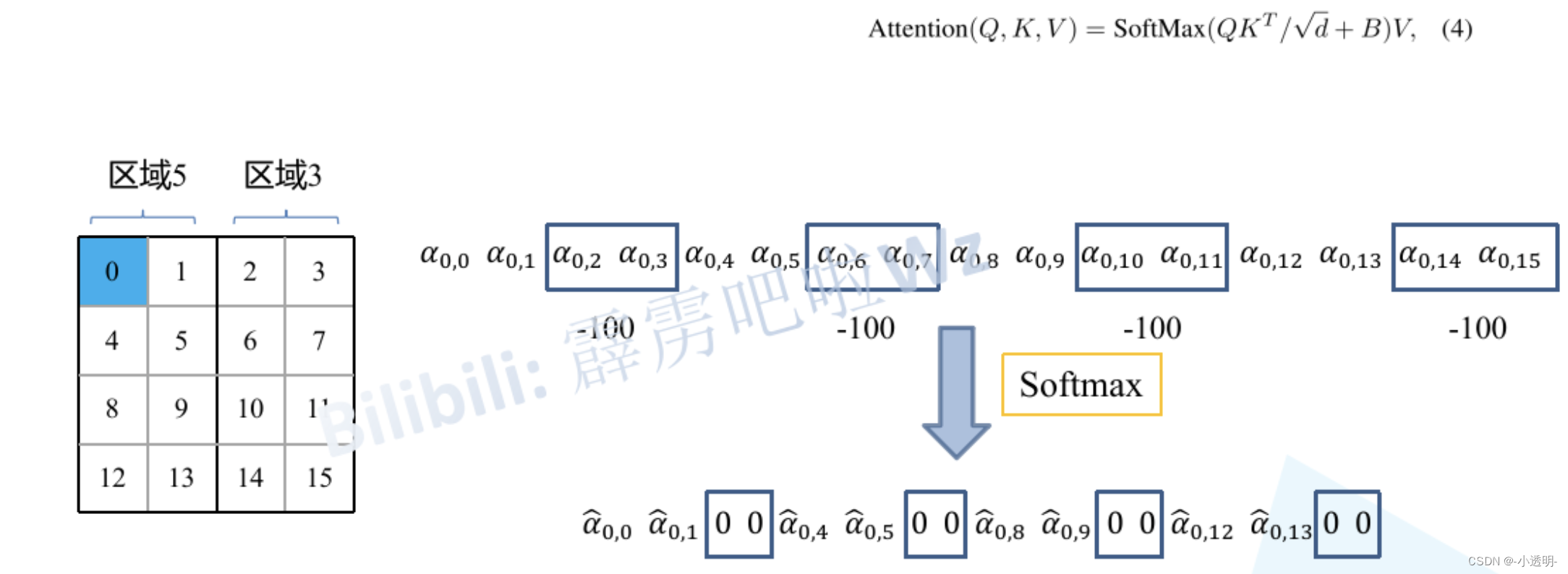
位置偏置
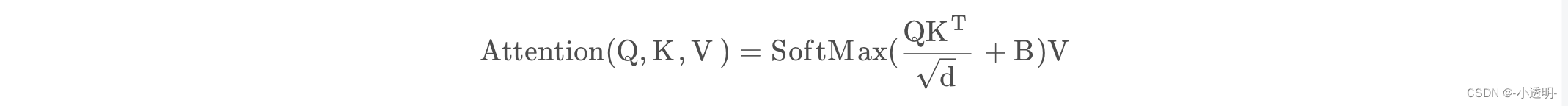
位置偏置就是将位置信息作为偏置,加入向量。
imagenet上加入位置偏置可以有3%的提升。
具体步骤为:
-
计算每个token的相对位置坐标
-
拉伸后合并成一个矩阵
-
合并成一维位置向量(全部加上M-1,行再乘以2M-1,行列相加)
-
可训练参数B作为偏置value的索引,查表将偏置作为归一化后的偏置信息
B:位置编码(增加每个token的位置信息)
总体架构
Token
在计算机视觉中,Token通常指的是一种用于表示图像或文本中的最小单位的符号或标记。这些符号或标记可以是像素、单词、字符或其他更高级的语义单位。
在图像处理中,Token可以是图像的像素、图像块、特征点或其他表示图像信息的单位。例如,在图像分类或目标检测任务中,可以将图像划分为不同的图像块,并将每个图像块视为一个Token来进行处理。
在自然语言处理中,Token通常指的是将文本分割成单词、字符或其他语义单位的过程。这些Token可以用于文本的分析、语义理解、机器翻译等任务。例如,在文本分类任务中,可以将文本分割成单词并将每个单词视为一个Token来进行处理。
Token在计算机视觉中的应用非常广泛,可以用于图像处理、目标识别、图像分割、文本处理等各种任务中。通过将图像或文本分割成Token,可以更好地理解和处理图像或文本数据,从而提高计算机视觉任务的性能和效果。

