
热门标签
热门文章
- 1使用 getopt 处理命令行长参数
- 2【linux】虚拟机安装 BCLinux-R8-U4-Server-x86_64_bclinux在虚拟机中安装
- 335岁程序员被公司辞退,生活压力太大痛哭,中年危机如何自救?_36程序员 辞退后
- 4html中图片自动循环滚动代码,实现长图片自动循环滚动效果
- 5利用AI技术自动测试游戏_卡牌类游戏ai算法
- 6基于opencv答题卡识别_opencv实现答题卡识别
- 7openvpn (用户名密码模式)
- 8ubuntu22.04安装nvidia驱动_虚拟机安装英伟达驱动
- 9前端初级工程师面试题_通常在编写程序时,按键盘上的( )键实现语句的缩进。
- 10大模型训练:文件保存类型与优化策略_大模型训练文件
当前位置: article > 正文
每日AIGC最新进展(29):复旦大学提出通过人类反馈来优化语音生成模型SpeechAlign、浙江大学提出跟踪3D空间中的任何2D像素SpatialTracker、西安交大提出动态场景的语义流
作者:笔触狂放9 | 2024-07-10 11:22:47
赞
踩
speechalign
SpeechAlign: Aligning Speech Generation to Human Preferences
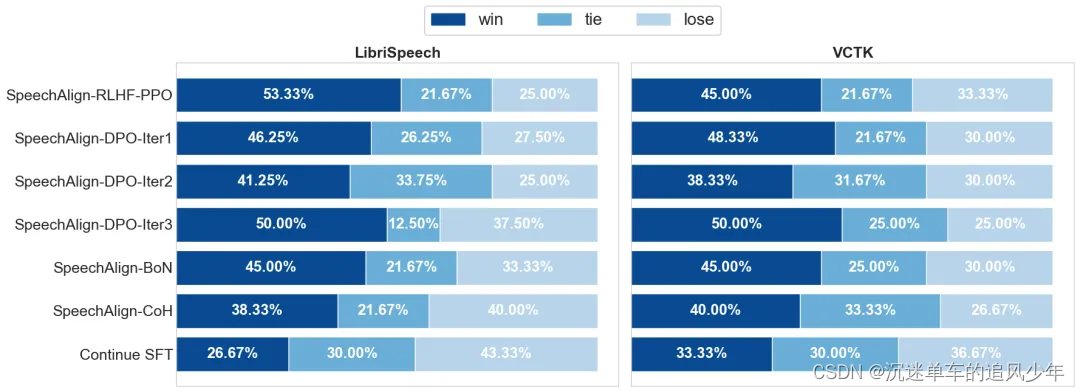
本文介绍了一种名为SpeechAlign的方法,旨在通过人类反馈来优化语音生成模型,使其更符合人类偏好。作者首先分析了当前语音语言模型中存在的分布差距问题,指出这导致了训练和推理阶段之间的不一致性,进而影响了模型性能。为了解决这一问题,作者提出了一种迭代自我改进策略,通过构建对比真实和合成编码令牌的偏好数据集,并进行偏好优化,从而将弱模型转变为强模型。
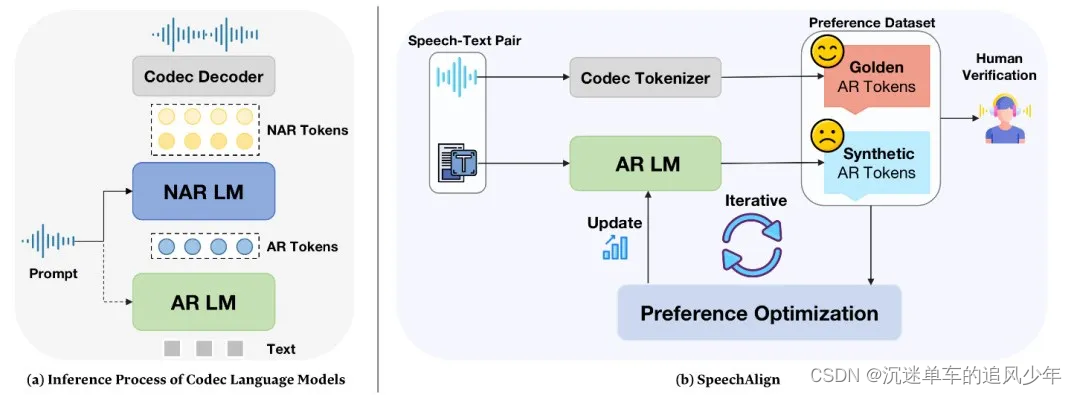
SpeechAlign方法通过构建一个偏好编解码器数据集来开始,该数据集将高质量的真实编码令牌与合成令牌进行对比。然后,利用这个数据集进行偏好优化,以改善编解码器语言模型。这一过程包括多种策略,如Chain-of-Hindsight、直接偏好优化(DPO)、基于人类反馈的强化学习&#
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/笔触狂放9/article/detail/806072
推荐阅读
相关标签

