
- 1Python实现自定义的压力测试框架及压测分析报告_python 数据库压力测试
- 2oracle里用管理员权限把A用户的表授权给B用户去使用_a用户表 给b用户 grant
- 3Android蓝牙socket实现视频实时传输,以及图片和文本传输_android蓝牙数据传输视频流
- 4SDL系列(三)—— SDL2.0 扩展库:SDL_image与SDL_mixer_sdl2 image
- 5信息安全从业者考试认证大全_信息化相关的证书_ciip-a
- 6卢威:大语言模型在软件编程领域的现状及挑战_代码语义增强
- 7java commons-lang3 包中 StringUtils 处理字符串的方法介绍_stringutils.repeat
- 8景联文科技:专业人像采集服务,助力人像采集在多领域应用
- 9neo4j 知识图谱_Neo4j 简介和底层存储格式剖析
- 10杭汽莅临天洑软件,共启综合智慧能源项目新篇章
LLama 3 跨各种 GPU 类型的基准测试
赞
踩

2024 年 4 月 18 日,AI 社区对 Llama 3 70B 的发布表示欢迎,这是一款最先进的大型语言模型 (LLM)。该型号是 Llama 系列的下一代产品,支持广泛的用例。该模型 istelf 在广泛的行业平台上表现良好,并提供了新功能,包括改进的推理。
在之前的博客文章中,我们研究了使用推理引擎对 Llama 3 的量化和非量化版本执行推理的知名应用程序。我们在第 1 部分介绍了量化版本,在第 2 部分介绍了非量化版本。研究的重点是研究什么是最简单、性能最好的引擎,可以将 Llama 3 作为 API 端点。这篇文章着眼于此项目的下一次迭代,并着眼于不同 GPU 类型的性能。
经过测试的 GPU
在深入研究结果之前,让我们简要介绍一下我们测试过的 GPU:
- NVIDIA A6000:以其高内存带宽和计算能力而闻名,广泛用于专业图形和 AI 工作负载。
- NVIDIA L40:专为企业 AI 和数据分析而设计,提供均衡的性能。
- NVIDIA A100 PCIe:用于 AI 和高性能计算的多功能 GPU,采用 PCIe 外形尺寸。
- NVIDIA A100 SXM4:A100 的另一种变体,针对 SXM4 外形尺寸的最大性能进行了优化。
- NVIDIA H100 PCIe:该系列的最新产品,拥有更高的性能和效率,专为 AI 应用程序量身定制。
基准测试方法论
我们可以使用许多不同的引擎和技术来判断各种 GPU 的性能。我们决定利用 Hugging Face Text Generation Inference (TGI) 引擎作为为 Llama 3 提供服务的主要方式。这样做有一个主要原因。它是我们见过的唯一一个提供基准测试机制的推理引擎。
TGI 提供的基准测试允许查看批量大小、预填充和解码步骤。这是查看每秒平均、最小和最大令牌以及 p50、p90 和 p99 结果的绝佳方式。如果您想了解更多关于如何通过 TGI 进行基准测试的信息,请联系我们,我们很乐意为您提供帮助。
结果
RTX A6000
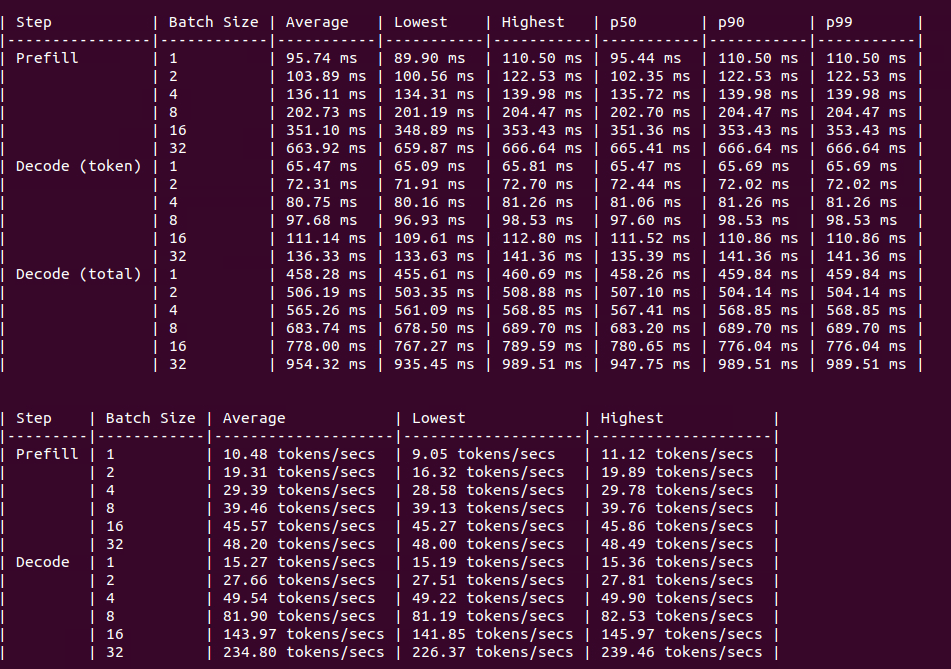
图:4xA6000 上的基准测试
L40型
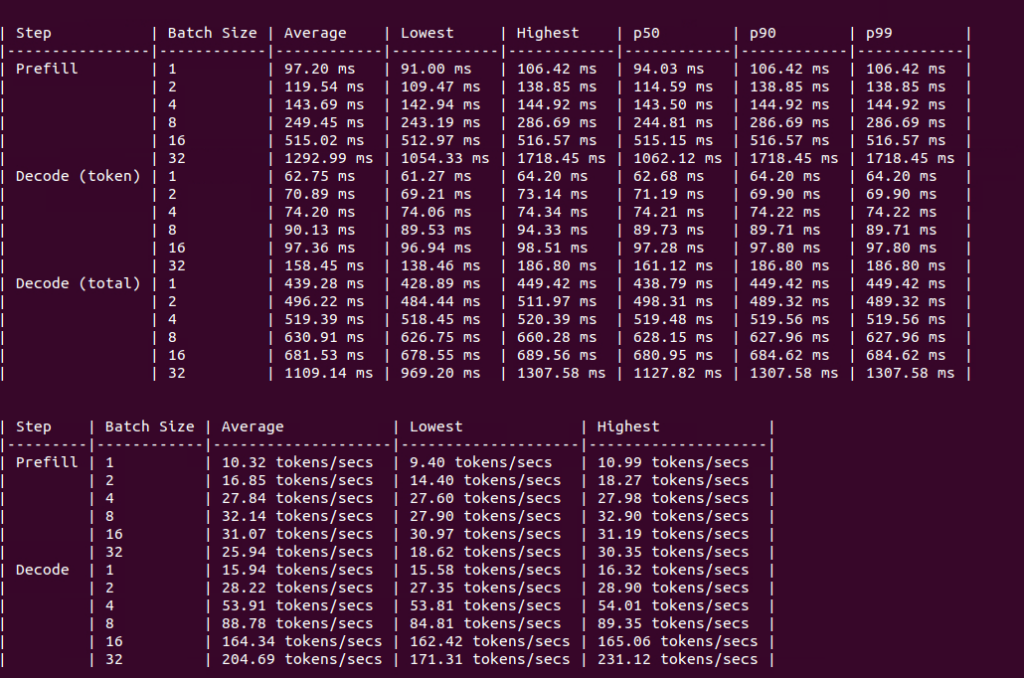
Figure: Benchmark on 4xL40
A100 PCIe
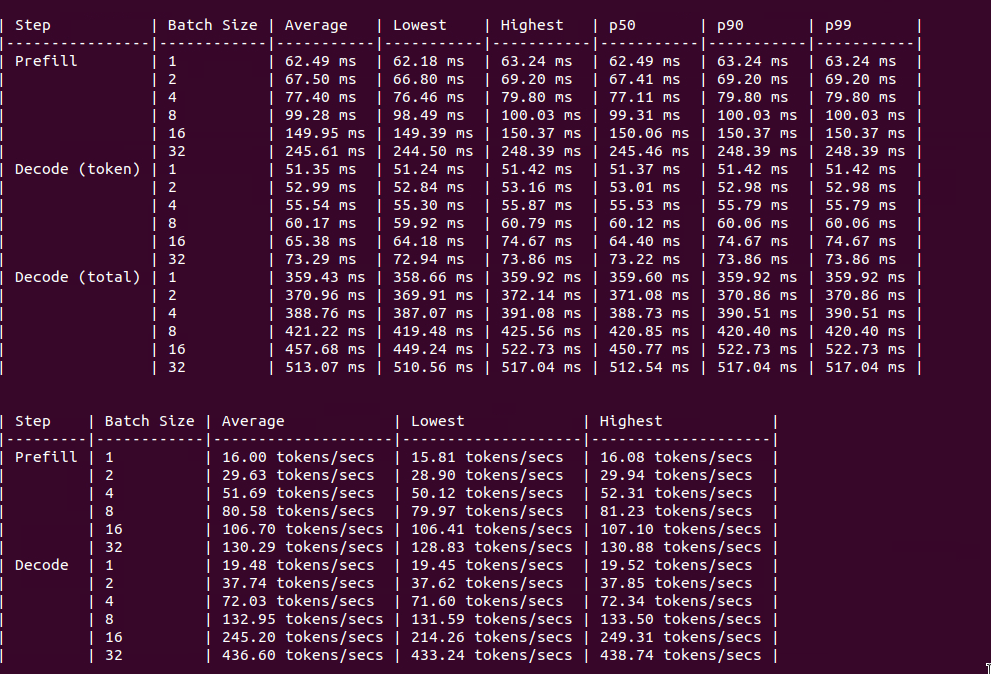
Figure: Benchmark on 2xA100
A100 SXM4
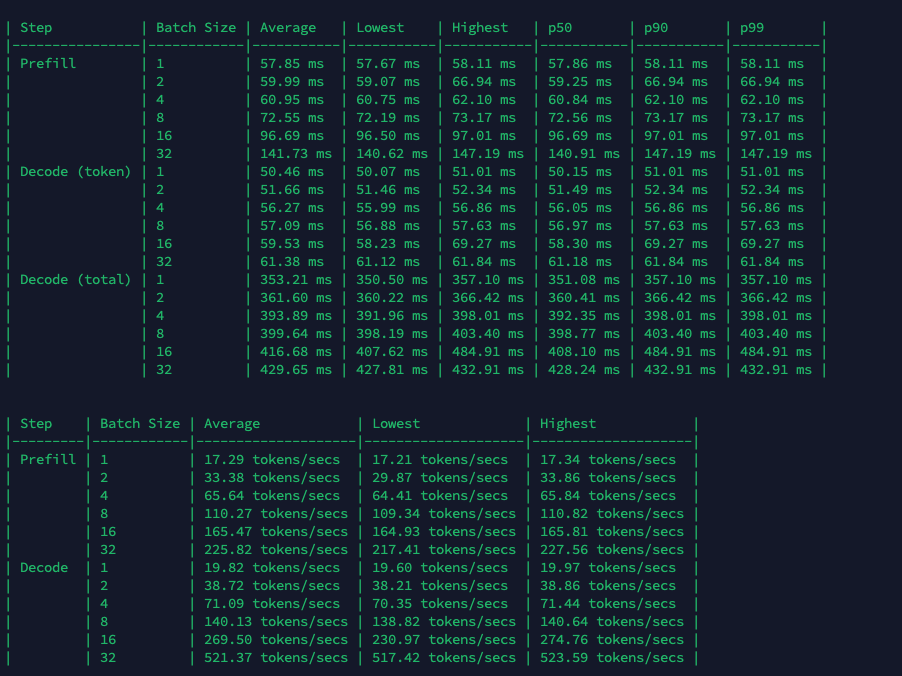
Figure: Benchmark on 2xA100
H100 PCIe
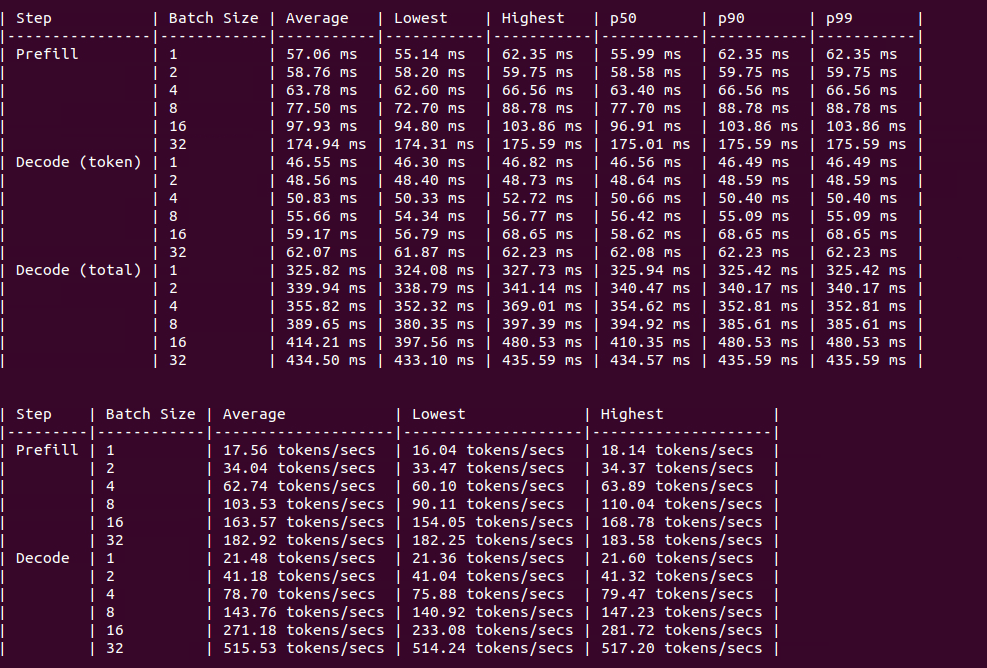
图:2xH100 上的基准测试
长期以来,A100 都被认为是在大模型生产系统中的不二之选。

结论
Hugging Face TGI 提供了一种一致的机制,可以在多种 GPU 类型上进行基准测试。根据这些结果的性能,我们还可以计算出最经济高效的 GPU 来运行 Llama 3 的推理端点。了解这些细微差别有助于在部署 Llama 3 70B 时做出明智的决策,确保您获得最佳性能和投资价值。

