- 1Stable diffusion报Torch is not able to use GPU; add --skip-torch-cuda-test to COMMANDLINE_ARGS variab_runtimeerror: torch is not able to use gpu; add --
- 2【C语言】八道经典指针笔试题(详解)_c语言指针例题及解析
- 3硬件越跑越快,软件越陷越慢
- 4can 常见面试题_can总线面试问题
- 5【Java前端技术栈】ES6-ECMAScript6.0
- 6LLM之RAG理论(四)| RAG高级数据索引技术
- 7解决pip超时的问题_pip-23.2.1-py3-none-any.whl
- 8python:threading.Thread类的使用详解_python-threading
- 9远程连接ECS服务器提示了Connection refused,怎么办?_远程桌面connection refused
- 10debian10安装x ui失败_debian 10x-ui安装命令
Stable Diffusion部署
赞
踩
Stable Diffusion简介
-
stable diffusion是一种能够根据文本描述生成图像的深度学习模型,于2022年发布,由创业公司Stability AI开发和维护。它可以用来生成各种风格和主题的图像,也可以用来修改已有的图像或者填补低分辨率或者缺失细节的图像。它的代码和模型权重都是公开的,可以在大多数配备了至少8GB显存的GPU上运行。
stable diffusion是一种潜在扩散模型(latent diffusion model),这是一种深度生成神经网络。它的原理是通过不断地去噪随机噪声,直到达到设定的步数,从而生成目标图像。在这个过程中,它会受到一个文本编码器(text encoder)的指导,这个编码器可以将文本描述转换成图像的语义信息。
stable diffusion有三个主要部分:变分自编码器(variational autoencoder),U-Net和一个可选的文本编码器。变分自编码器可以将图像从像素空间压缩到一个更小维度的潜在空间,捕捉图像的更本质的语义含义。U-Net是一种卷积神经网络,可以将潜在空间中的向量还原成图像。文本编码器可以根据文本描述生成一个向量,作为潜在空间中的先验分布,引导U-Net生成符合文本描述的图像。
要使用stable diffusion生成图像,你需要给它一个文本描述,例如“一只猫坐在沙发上”或者“一幅风景画”。你也可以给它一些风格或者细节上的指示,例如“卡通风格”或者“有雪山和湖泊”。stable diffusion会根据你给出的文本描述,在潜在空间中寻找一个最合适的向量,并用U-Net将它转换成图像。你可以看到生成过程中每一步的结果,也可以调整参数来改变生成效果。
stable diffusion是一个非常强大和灵活的图像生成模型,它可以让你用语言来创造你想象中的任何图像。你可以用它来做艺术创作、设计、教育、娱乐等各种用途。如果你想了解更多关于stable diffusion的信息,你可以访问它的官方网站或者查看它的源代码。
硬件配置
| 硬件 | 配置 |
|---|---|
| 操作系统 | windows11 |
| CPU | i5-10400F |
| 内存 | 64G |
| 显卡 | RTX 2070(8G)最低显卡2G |
显卡的大小对跑图的速度影响较大
- 1
部署
采用秋葉大佬的整合包v4
秋葉大佬百度盘链接会到期,放到了自己的网盘
链接: https://pan.baidu.com/s/1rg5dTkOGsmQAby8ErXIZ1g?pwd=zgds
- 1
- 2
秋葉大佬B站地址
快速开始使用 → https://www.bilibili.com/read/cv22661198
新手最全教程 → https://www.bilibili.com/read/cv22159609
- 1
- 2
开始安装
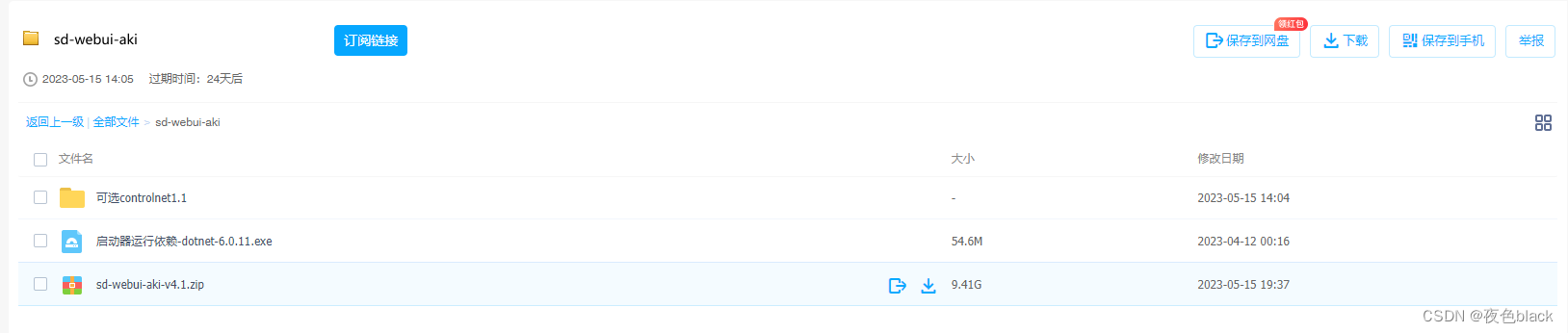
下载下来这几个包如图
解压sd-webui-aki-v4.1
安装环境依赖
启动器运行依赖-dotnet-6.0.11.exe
安装完成后打开sd-webui-aki-v4\sd-webui-aki-v4 目录
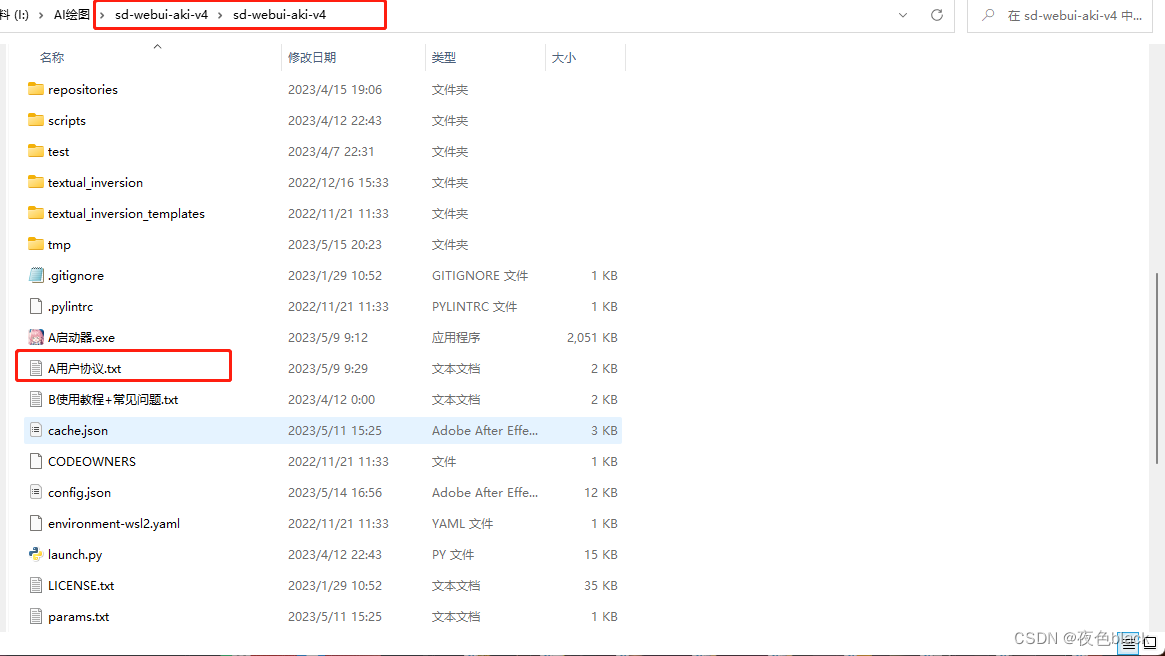
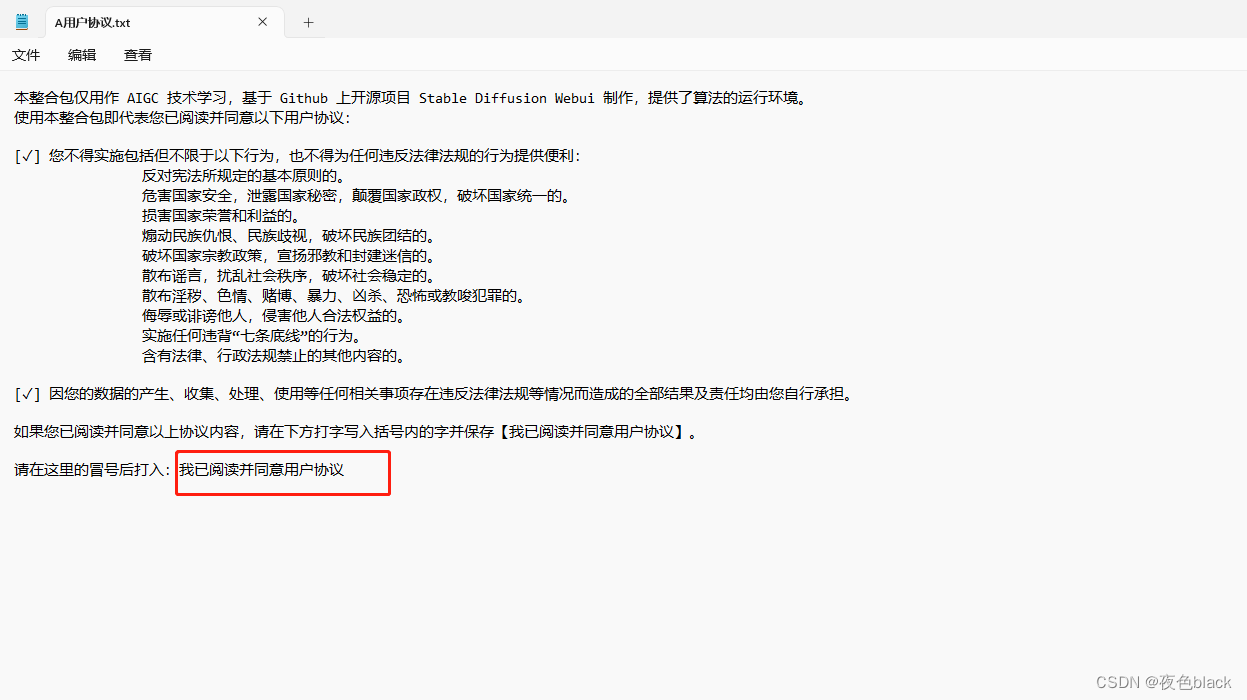
打开用户协议进行编辑,输入我已阅读并同意用户协议后保存退出
点击A启动器.exe运行软件
等待检测完成后进入界面
启动器设置
- 打开启动器,进入界面
2.点击设置,进行配置
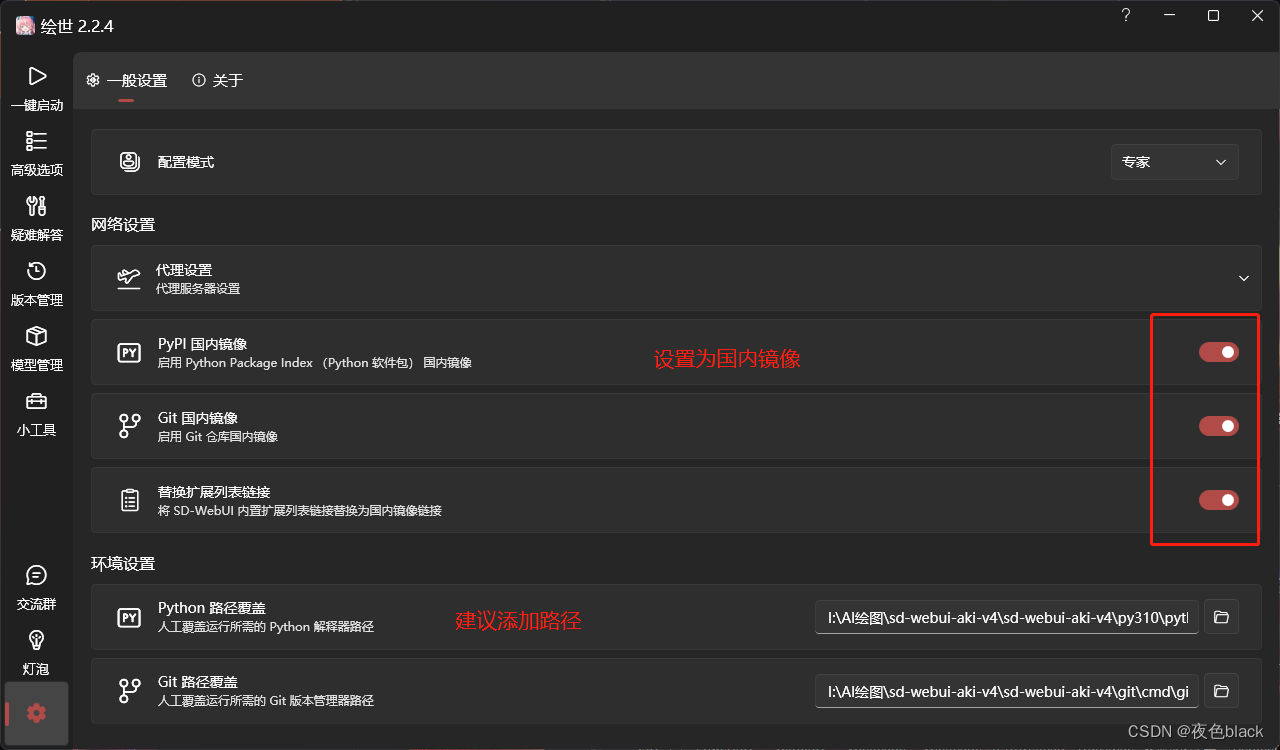
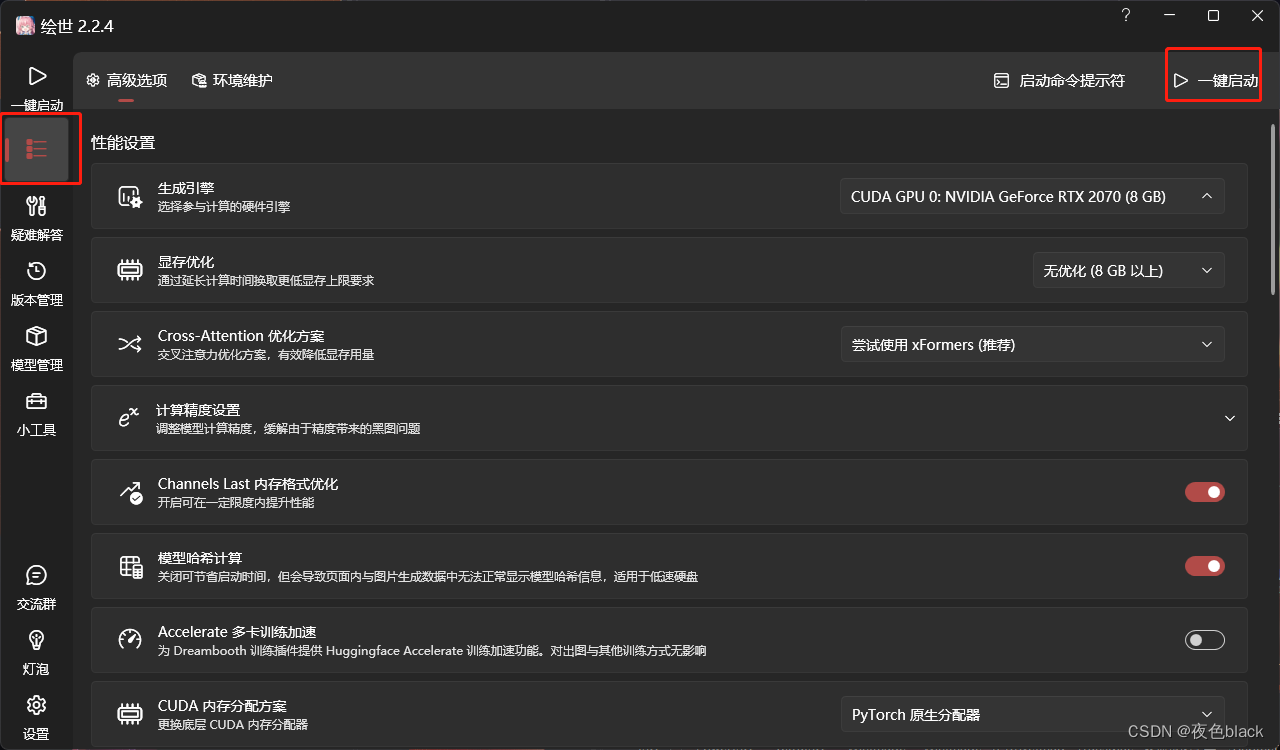
3.点击高级选项进行配置
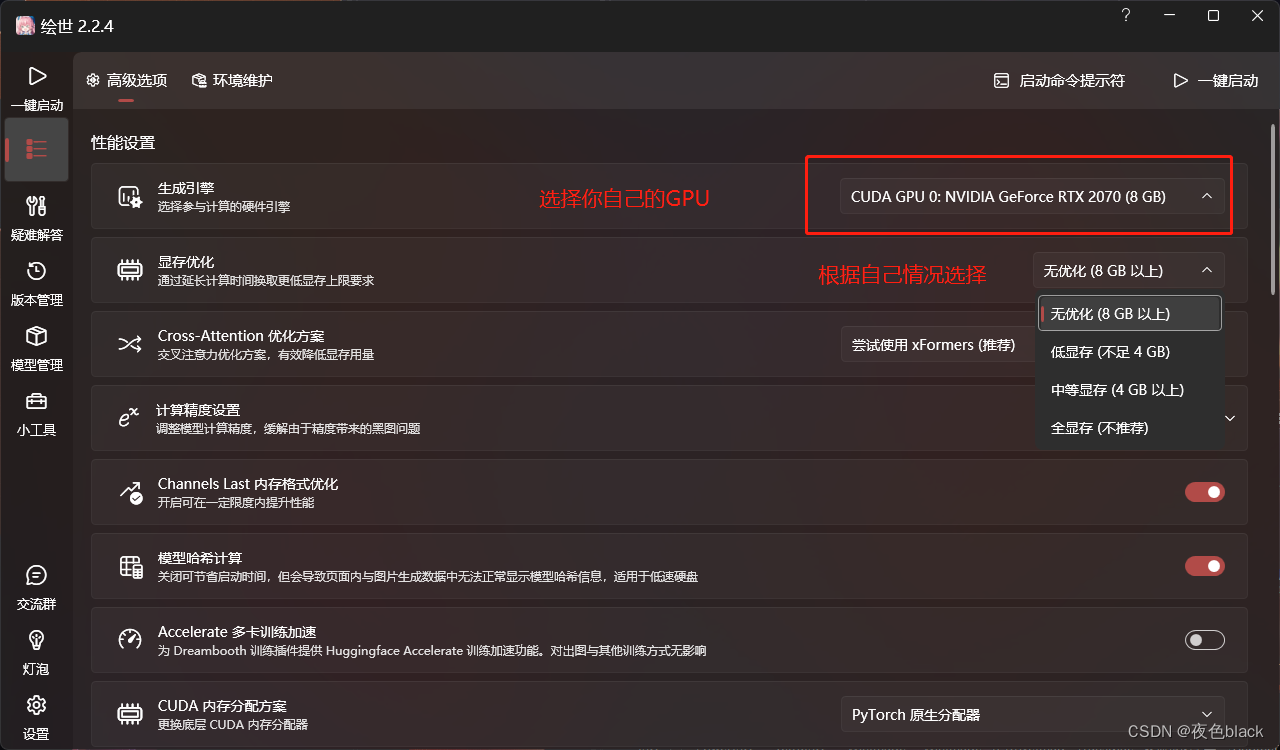
4.查看自己显卡信息
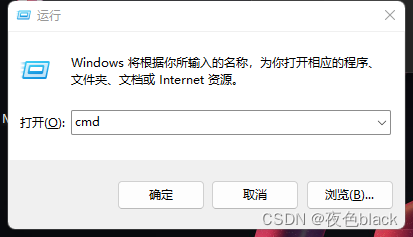
方法一:快捷按键 win+r 输入cmd
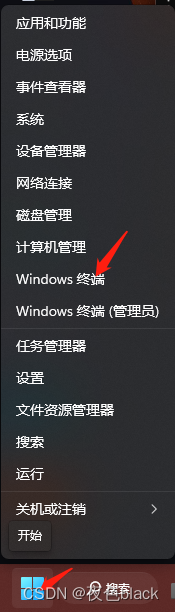
方法二:点击win图标,选择windows终端,输入nv-d-a-smi如图
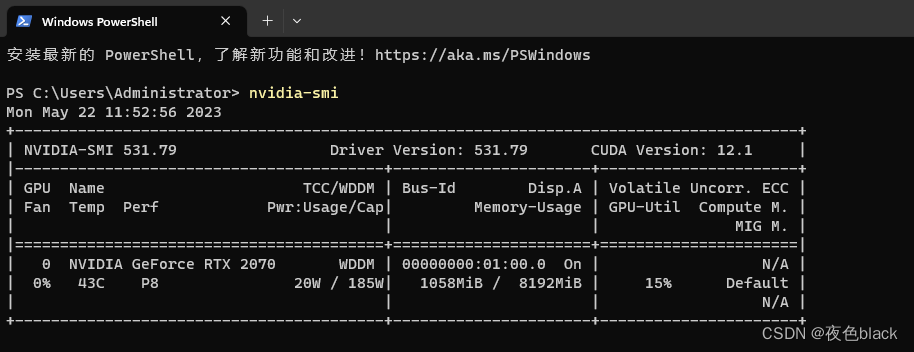
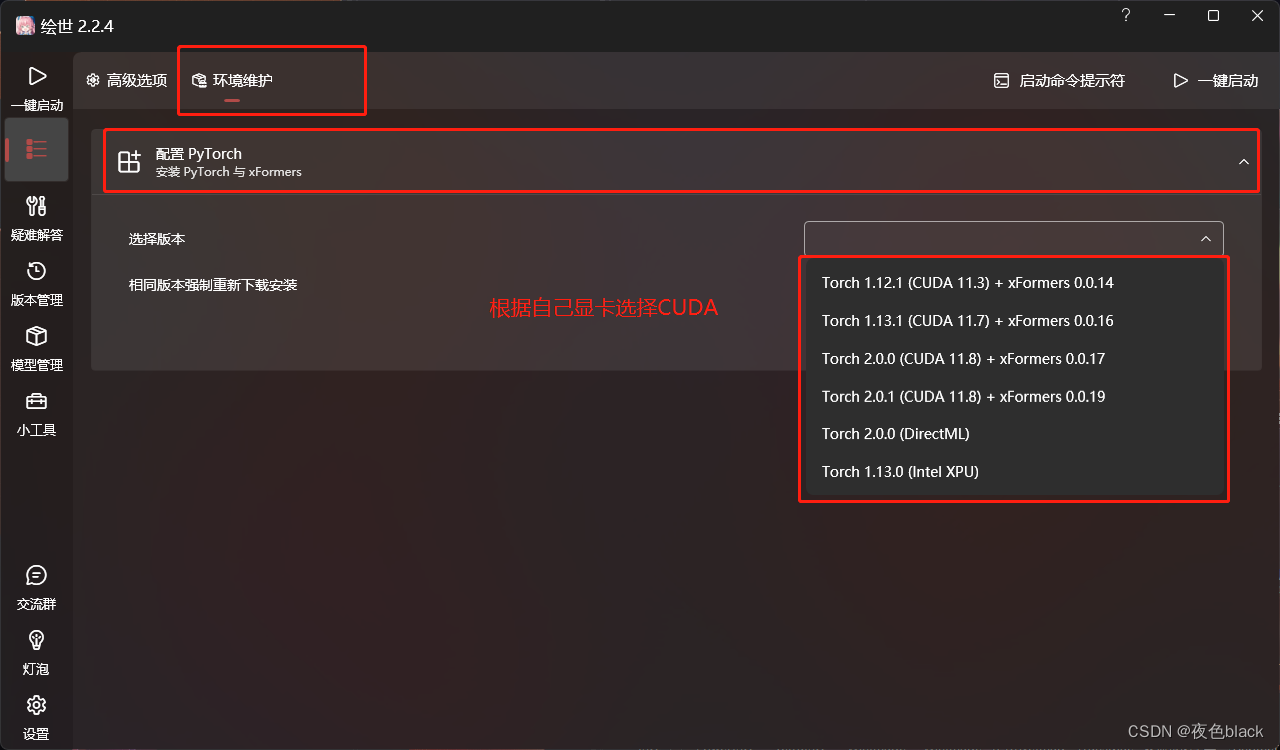
5.高级选择——环境维护配置
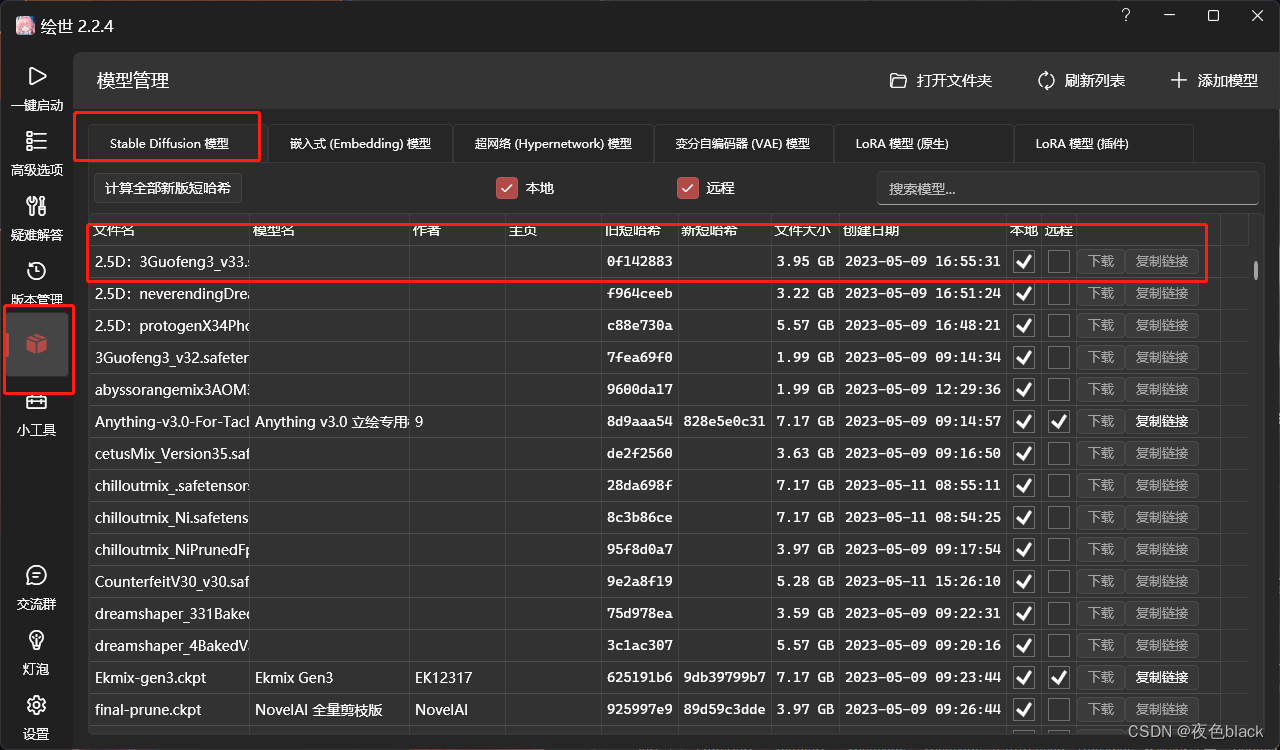
6.下载一个模型如图
7.进入高级模式点击一键启动
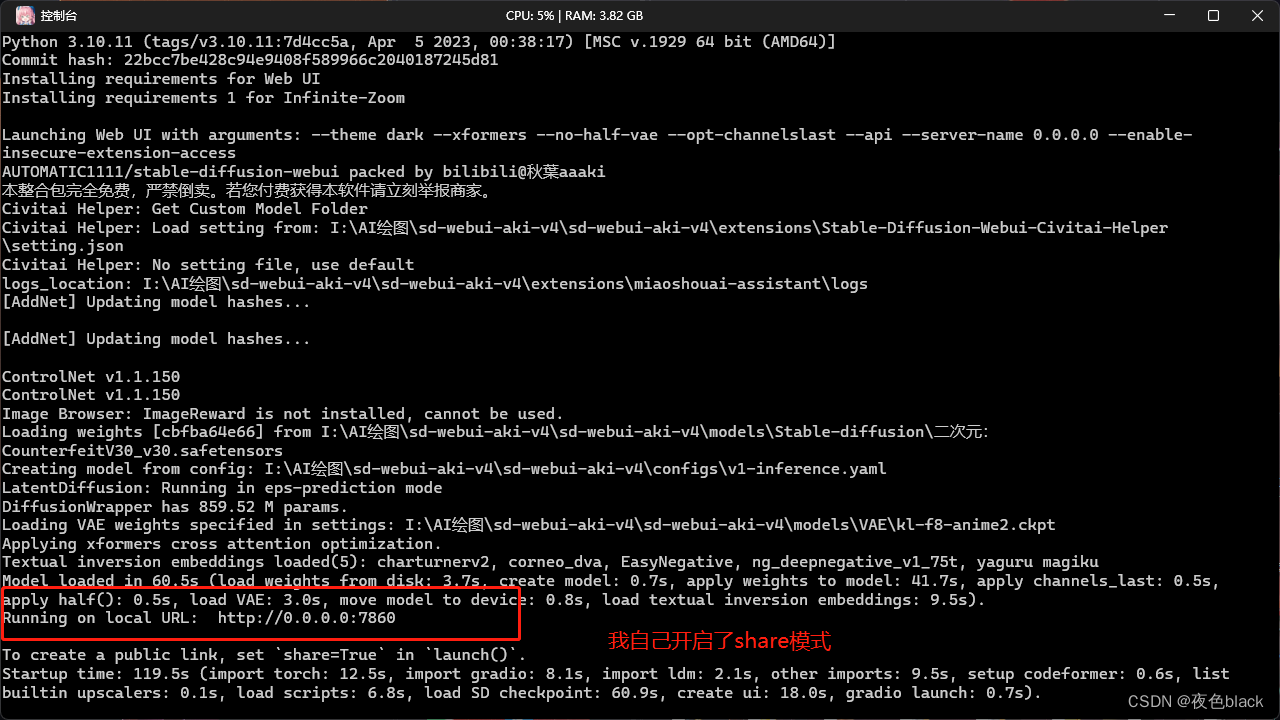
8.第一次启动会比较慢,等待出现127.0.0.1:7860,启动成功
9.浏览器输入地址,进入sd