
- 1目标检测应用化之web页面(YOLO、SSD等)
- 2docker-compose详讲_docker-compose ports
- 3关于YOLOv5的学习经验总结(保姆级讲解)
- 4element ui多选下拉组件(el-select)tag数量过多处理解决办法(二次封装)_element下拉框数据过多
- 5flutter更新后[VERBOSE-2:FlutterDarwinContextMetalImpeller.mm(35)] Using the Impeller rendering backend,_[error:flutter/shell/platform/darwin/graphics/flut
- 6基于JSDoc实现TypeScript类型安全的实践报告_jsdoc 断言
- 7springboot常用注解详解_spring boot注解
- 8数据分析系列3—matplotlib使用_import as plt
- 9SQL Developer 小贴士:PL/SQL语法分析
- 10Antd 级联下拉列表_ant design 级联如何可以选第一级
mysql-锁_mysql锁
赞
踩
一、基础概念
1.为什么需要锁
锁是数据库系统区分与文件系统的一个关键特性,作为多用户共享的资源,当出现并发访问的时候,数据库需要合理地控制资源的访问规则,保证数据一致性,所以必须有锁的介入。
数据库系统使用锁是为了支持对共享资源进行并发访问,提供数据的完整性和一致性。
mysql锁主要是为了解决并发写数据时的一种安全机制。
2.lock与latch
这里还要区分锁中容易令人混淆的概念lock与 latch。在数据库中,lock与 latch都可以被称为“锁”。但是两者有着截然不同的含义,本章主要关注的是lock。
latch一般称为闩锁(轻量级的锁),因为其要求锁定的时间必须非常短。若持续的时间长,则应用的性能会非常差。在 InnoDB存储引擎中, latch又可以分为 mutex(互斥量)和 rwlock(读写锁)。
其目的是用来保证并发线程操作临界资源的正确性,并且通常没有死锁检测的机制。
lock的对象是事务,用来锁定的是数据库中的对象,如表、页、行。
并且一般lock的对象仅在事务 commit或 rollback后进行释放(不同事务隔离级别释放的时间可能不同)。此外,lock,正如在大多数数据库中一样,是有死锁机制的。下表显示了lock与latch的不同。

3.锁范围
根据加锁的范围,MySQL 里面的锁大致可以分成全局锁、表级锁和行锁三类。
1.全局锁
顾名思义,全局锁就是对整个数据库实例加锁。MySQL 提供了一个加全局读锁的方法,命令是 Flush tables with read lock (FTWRL)。当你需要让整个库处于只读状态的时候,可以使用这个命令,之后其他线程的以下语句会被阻塞:数据更新语句(数据的增删改)、数据定义语句(包括建表、修改表结构等)和更新类事务的提交语句。
全局锁的典型使用场景是,做全库逻辑备份。也就是把整库每个表都 select 出来存成文本。
以前有一种做法,是通过 FTWRL 确保不会有其他线程对数据库做更新,然后对整个库做备份。注意,在备份过程中整个库完全处于只读状态。
但是让整库都只读,听上去就很危险:
- 如果你在主库上备份,那么在备份期间都不能执行更新,业务基本上就得停摆;
- 如果你在从库上备份,那么备份期间从库不能执行主库同步过来的 binlog,会导致主从延迟。
看来加全局锁不太好。但是细想一下,备份为什么要加锁呢?我们来看一下不加锁会有什么问题。
假设你现在要维护“极客时间”的购买系统,关注的是用户账户余额表和用户课程表。
现在发起一个逻辑备份。假设备份期间,有一个用户,他购买了一门课程,业务逻辑里就要扣掉他的余额,然后往已购课程里面加上一门课。
如果时间顺序上是先备份账户余额表 (u_account),然后用户购买,然后备份用户课程表 (u_course),会怎么样呢?你可以看一下这个图:
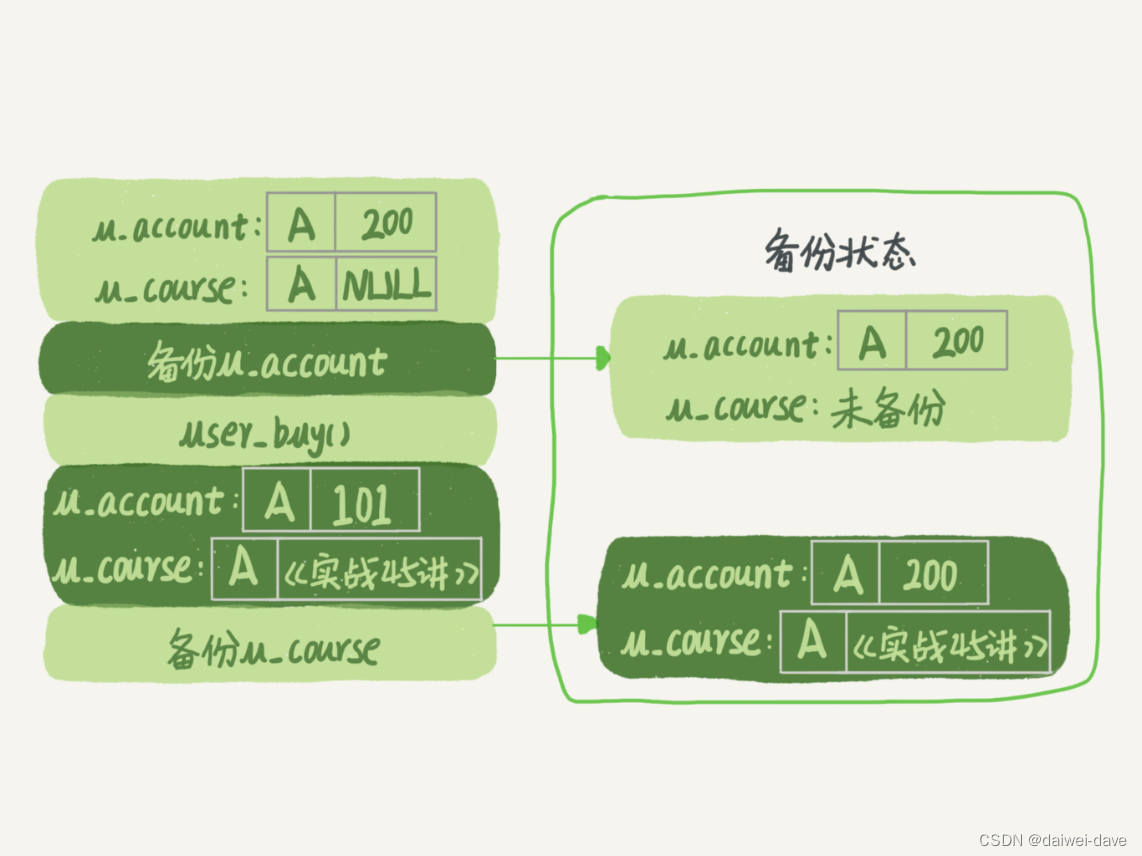
图 1 业务和备份状态图
可以看到,这个备份结果里,用户 A 的数据状态是“账户余额没扣,但是用户课程表里面已经多了一门课”。如果后面用这个备份来恢复数据的话,用户 A 就发现,自己赚了。
作为用户可别觉得这样可真好啊,你可以试想一下:如果备份表的顺序反过来,先备份用户课程表再备份账户余额表,又可能会出现什么结果?
也就是说,不加锁的话,备份系统备份的得到的库不是一个逻辑时间点,这个视图是逻辑不一致的。
官方自带的逻辑备份工具是 mysqldump。当 mysqldump 使用参数–single-transaction 的时候,导数据之前就会启动一个事务,来确保拿到一致性视图。而由于 MVCC 的支持,这个过程中数据是可以正常更新的。
你一定在疑惑,有了这个功能,为什么还需要 FTWRL 呢?一致性读是好,但前提是引擎要支持这个隔离级别。比如,对于 MyISAM 这种不支持事务的引擎,如果备份过程中有更新,总是只能取到最新的数据,那么就破坏了备份的一致性。这时,我们就需要使用 FTWRL 命令了。
所以,single-transaction 方法只适用于所有的表使用事务引擎的库。如果有的表使用了不支持事务的引擎,那么备份就只能通过 FTWRL 方法。这往往是 DBA 要求业务开发人员使用 InnoDB 替代 MyISAM 的原因之一。
业务的更新不只是增删改数据(DML),还有可能是加字段等修改表结构的操作(DDL)。不论是哪种方法,一个库被全局锁上以后,你要对里面任何一个表做加字段操作,都是会被锁住的。
但是,即使没有被全局锁住,加字段也不是就能一帆风顺的,因为你还会碰到接下来我们要介绍的表级锁。
2.表级锁
表级锁在后面文章细讲。
3.行锁
行锁在后面文章细讲。
4.表级锁
MySQL 里面表级别的锁有两种:一种是表锁,一种是元数据锁(meta data lock,MDL)。
1.表锁
表锁的语法是 lock tables … read/write。与 FTWRL 类似,可以用 unlock tables 主动释放锁,也可以在客户端断开的时候自动释放。需要注意,lock tables 语法除了会限制别的线程的读写外,也限定了本线程接下来的操作对象。
举个例子, 如果在某个线程 A 中执行 lock tables t1 read, t2 write; 这个语句,则其他线程写 t1、读写 t2 的语句都会被阻塞。同时,线程 A 在执行 unlock tables 之前,也只能执行读 t1、读写 t2 的操作。连写 t1 都不允许,自然也不能访问其他表。
在还没有出现更细粒度的锁的时候,表锁是最常用的处理并发的方式。而对于 InnoDB 这种支持行锁的引擎,一般不使用 lock tables 命令来控制并发,毕竟锁住整个表的影响面还是太大。
2.MDL
MDL是一种元数据锁(meta data lock,MDL),是表级锁中的一种。
在 MySQL 5.5 版本中引入了 MDL,当对一个表做增删改查操作的时候,加 MDL 读锁;当要对表做结构变更操作的时候,加 MDL 写锁。
-
读锁之间不互斥,因此你可以有多个线程同时对一张表增删改查。
-
读写锁之间、写锁之间是互斥的,用来保证变更表结构操作的安全性。因此,如果有两个线程要同时给一个表加字段,其中一个要等另一个执行完才能开始执行。
MDL 不需要显式使用,在访问一个表的时候会被自动加上。MDL 的作用是,保证读写的正确性。你可以想象一下,如果一个查询正在遍历一个表中的数据,而执行期间另一个线程对这个表结构做变更,删了一列,那么查询线程拿到的结果跟表结构对不上,肯定是不行的。
虽然 MDL 锁是系统默认会加的,但却是你不能忽略的一个机制。比如下面这个例子,我经常看到有人掉到这个坑里:给一个小表加个字段,导致整个库挂了。
你肯定知道,给一个表加字段,或者修改字段,或者加索引,需要扫描全表的数据。在对大表操作的时候,你肯定会特别小心,以免对线上服务造成影响。而实际上,即使是小表,操作不慎也会出问题。我们来看一下下面的操作序列,假设表 t 是一个小表。
备注:这里的实验环境是 MySQL 5.6。

我们可以看到 session A 先启动,这时候会对表 t 加一个 MDL 读锁。由于 session B 需要的也是 MDL 读锁,因此可以正常执行。
之后 session C 会被 blocked,是因为 session A 的 MDL 读锁还没有释放,而 session C 需要 MDL 写锁,因此只能被阻塞。
如果只有 session C 自己被阻塞还没什么关系,但是之后所有要在表 t 上新申请 MDL 读锁的请求也会被 session C 阻塞。前面我们说了,所有对表的增删改查操作都需要先申请 MDL 读锁,就都被锁住,等于这个表现在完全不可读写了。
如果某个表上的查询语句频繁,而且客户端有重试机制,也就是说超时后会再起一个新 session 再请求的话,这个库的线程很快就会爆满。
你现在应该知道了,事务中的 MDL 锁,在语句执行开始时申请,但是语句结束后并不会马上释放,而会等到整个事务提交后再释放。
基于上面的分析,我们来讨论一个问题,如何安全地给小表加字段?
首先我们要解决长事务,事务不提交,就会一直占着 MDL 锁。在 MySQL 的 information_schema 库的 innodb_trx 表中,你可以查到当前执行中的事务。如果你要做 DDL 变更的表刚好有长事务在执行,要考虑先暂停 DDL,或者 kill 掉这个长事务。
但考虑一下这个场景。如果你要变更的表是一个热点表,虽然数据量不大,但是上面的请求很频繁,而你不得不加个字段,你该怎么做呢?
这时候 kill 可能未必管用,因为新的请求马上就来了。比较理想的机制是,在 alter table 语句里面设定等待时间,如果在这个指定的等待时间里面能够拿到 MDL 写锁最好,拿不到也不要阻塞后面的业务语句,先放弃。之后开发人员或者 DBA 再通过重试命令重复这个过程。
MariaDB 已经合并了 AliSQL 的这个功能,所以这两个开源分支目前都支持 DDL NOWAIT/WAIT n 这个语法。
|
| |
|
|
关于如何在线上执行ddl,我在另一篇文章有详细讲解。
1.1 锁的类型
基于锁的属性分类:共享锁、排他锁。
基于锁的粒度分类:行级锁(INNODB)、表级锁(INNODB、MYISAM)、页级锁(BDB引擎 )
基于锁的状态分类:意向共享锁、意向排它锁
1.共享锁与排它锁
Innodb存储引擎实现了如下2种标准的行级锁
共享锁(S lock),允许事务读取一行数据。
排它锁(X lock),允许事务删除或者更新一行数据。
当一个事务获取了行r的共享锁,那么另外一个事务也可以立即获取行r的共享锁,因为读取并未改变行r的数据,这种情况就是锁兼容。
但是如果有事务想获得行r的排它锁,则它必须等待事务释放行r上的共享锁。

简单的说,就是一个事务锁住了某行,其他事务可以读取该行,但不能做修改和删除等操作。
2.意向共享锁(IS Lock)和意向排它锁(IX Lock)
此外, InnoDB存储引擎支持多粒度(granular)锁定,这种锁定允许事务在行级上的锁和表级上的锁同时存在。
为了支持在不同粒度上进行加锁操作, InnoDB存储引擎支持一种额外的锁方式,称之为意向锁(Intention lock)。
意向锁是将锁定的对象分为多个层次,意向锁意味着事务希望在更细粒度(fine granularity)上进行加锁,如下图所示。

若将上锁的对象看成一棵树,那么对最下层的对象上锁,也就是对最细粒度的对象进行上锁,那么首先需要对粗粒度的对象上锁。
例如图6-3,如果需要对页上的记录r进行上X锁,那么分别需要对数据库A、表、页上意向锁IX,最后对记录r上ⅹ锁。
若其中任何一个部分导致等待,那么该操作需要等待粗粒度锁的完成。
举例来说,在对记录r加ⅹ锁之前,已经有事务对表1进行了S表锁,那么表1上已存在S锁,之后事务需要对记录r在表1上加上IX,由于不兼容,所以该事务需要等待表锁操作的完成。
InnoDB存储引擎支持意向锁设计比较简练,其意向锁即为表级别的锁。设计目的主要是为了在一个事务中揭示下一行将被请求的锁类型。其支持两种意向锁:
- 意向共享锁(IS Lock),事务想要获得一个表中某几行的共享锁。
- 意向排它锁(IX Lock),事务想要获得一个表中某几行的排它锁。
由于 InnoDB存储引擎支持的是行级别的锁,因此意向锁其实不会阻塞除全表扫以外的任何请求。故表级意向锁与行级锁的兼容性如下表所示。

思考
1.MySQL SELECT … FOR UPDATE 的Row Lock 与Table Lock
上面介绍过SELECT … FOR UPDATE 的用法,不过锁定(Lock)的数据是判别就得要注意一下了。对于主键或唯一索引,则上记录锁。其他索引上间隙锁,没有索引列将锁表
2.锁表的场景
查询到一部分结果后,然后对这些结果进行更新。如果更新的条件不是索引项,将锁表,那么其他线程在读写这张表时将会线程阻塞。
如移动端读取了某些消息后,又将这些消息置为已读,而这项操作是在一个事务上。
解决办法:更新或者删除等where条件尽量避免锁表,条件上尽量使用唯一索引或者主键索引。即查询结果从Db中反查一下获取到主键再进行更新。
3.select…for update和lock in share mode对比
SELECT … LOCK IN SHARE MODE走的是IS锁(意向共享锁)。
即在符合条件的rows上都加了共享锁,这样的话,其他session可以读取这些记录,也可以继续添加IS锁,但是无法修改这些记录直到你这个加锁的session执行完成(否则直接锁等待超时)。
SELECT … FOR UPDATE 走的是IX锁(意向排它锁)。
即在符合条件的rows上都加了排它锁,其他session也就无法在这些记录上添加任何的S锁或X锁。
如果不存在一致性非锁定读的话,那么其他session是无法读取和修改这些记录的,但是innodb有非锁定读(快照读并不需要加锁),for update之后并不会阻塞其他session的快照读取操作,除了select …lock in share mode和select … for update这种显示加锁的查询操作。
二、行锁
1.定义
顾名思义,行锁就是针对数据表中行记录的锁。这很好理解,比如事务 A 更新了一行,而这时候事务 B 也要更新同一行,则必须等事务 A 的操作完成后才能进行更新。
2.两阶段锁协议
我先给你举个例子。在下面的操作序列中,事务 B 的 update 语句执行时会是什么现象呢?假设字段 id 是表 t 的主键。
这个问题的结论取决于事务 A 在执行完两条 update 语句后,持有哪些锁,以及在什么时候释放。你可以验证一下:实际上事务 B 的 update 语句会被阻塞,直到事务 A 执行 commit 之后,事务 B 才能继续执行。
知道了这个答案,你一定知道了事务 A 持有的两个记录的行锁,都是在 commit 的时候才释放的。
也就是说,在 InnoDB 事务中,行锁是在需要的时候才加上的,但并不是不需要了就立刻释放,而是要等到事务结束时才释放。这个就是两阶段锁协议。
知道了这个设定,对我们使用事务有什么帮助呢?那就是,如果你的事务中需要锁多个行,要把最可能造成锁冲突、最可能影响并发度的锁尽量往后放。我给你举个例子。
假设你负责实现一个电影票在线交易业务,顾客 A 要在影院 B 购买电影票。我们简化一点,这个业务需要涉及到以下操作:
-
从顾客 A 账户余额中扣除电影票价;
-
给影院 B 的账户余额增加这张电影票价;
-
记录一条交易日志。
也就是说,要完成这个交易,我们需要 update 两条记录,并 insert 一条记录。当然,为了保证交易的原子性,我们要把这三个操作放在一个事务中。那么,你会怎样安排这三个语句在事务中的顺序呢?
试想如果同时有另外一个顾客 C 要在影院 B 买票,那么这两个事务冲突的部分就是语句 2 了。因为它们要更新同一个影院账户的余额,需要修改同一行数据。
根据两阶段锁协议,不论你怎样安排语句顺序,所有的操作需要的行锁都是在事务提交的时候才释放的。所以,如果你把语句 2 安排在最后,比如按照 3、1、2 这样的顺序,那么影院账户余额这一行的锁时间就最少。这就最大程度地减少了事务之间的锁等待,提升了并发度。
好了,现在由于你的正确设计,影院余额这一行的行锁在一个事务中不会停留很长时间。但是,这并没有完全解决你的困扰。
如果这个影院做活动,可以低价预售一年内所有的电影票,而且这个活动只做一天。于是在活动时间开始的时候,你的 MySQL 就挂了。你登上服务器一看,CPU 消耗接近 100%,但整个数据库每秒就执行不到 100 个事务。这是什么原因呢?
这里,我就要说到死锁和死锁检测了,而关于死锁的知识会在下面的章节讲到。
3.行锁的三种算法
record lock,记录锁,单个行记录的锁
Gap Lock,间隙锁,锁定一个范围,但不包含记录本身,遵循左开右闭原则。
Next_key Lock:Gap Lock+ Record Lock,锁定一个范围,并且锁定记录本身。InnoDB默认加锁方式是Next_key Lock
注意:InnoDB行锁是通过给索引上的索引项加锁来实现的,只有通过索引条件检索数据,InnoDB才使用行级锁或者间隙锁,否则,InnoDB将使用表锁。
1.间隙锁
什么是间隙锁?
间隙锁是一个在索引记录之间的间隙上的锁。
间隙的范围
根据检索条件向下寻找最靠近检索条件的记录值A作为左区间,向上寻找最靠近检索条件的记录值B作为右区间,即锁定的间隙为(A,B)。

select * from t where number=6;那么间隙锁锁定的间隙为:(5,11),所以你再想插入,更新,删除5到11之间的数就会被阻塞。
间隙锁的作用
阻止多个事务将纪录插入到同一个范围内,保证某个间隙内的数据在锁定情况下不会发生任何变化。可以解决Phantom Problem(幻读)
用户可以通过以下两种方式来显式地关闭Gap Lock:
- 将事务的隔离级别设置为 READ COMMITTED
- 将参数 innodb_locks_unsafe_for_binlog设置为1
最后需再次提醒的是,对于唯一键值的锁定, Next-Key Lock降级为Record Lock仅存在于查询所有的唯一索引列。
若唯一索引由多个列组成,而查询仅是查找多个唯一索引列中的其中一个,那么查询其实是range类型查询,而不是 point类型查询,故InnoDB存储引擎依然使用 Next-Key Lock进行锁定。
三.数据库死锁
1.定义
当并发系统中不同线程出现循环资源依赖,涉及的线程都在等待别的线程释放资源时,就会导致这几个线程都进入无限等待的状态,称为死锁。
减少死锁的主要方向,就是控制访问相同资源的并发事务量。
这里我用数据库中的行锁举个例子。
场景一
AB-BA死锁

《MySQL技术内幕:InnoDB存储引擎(第2版)》
场景二
AB-BA死锁
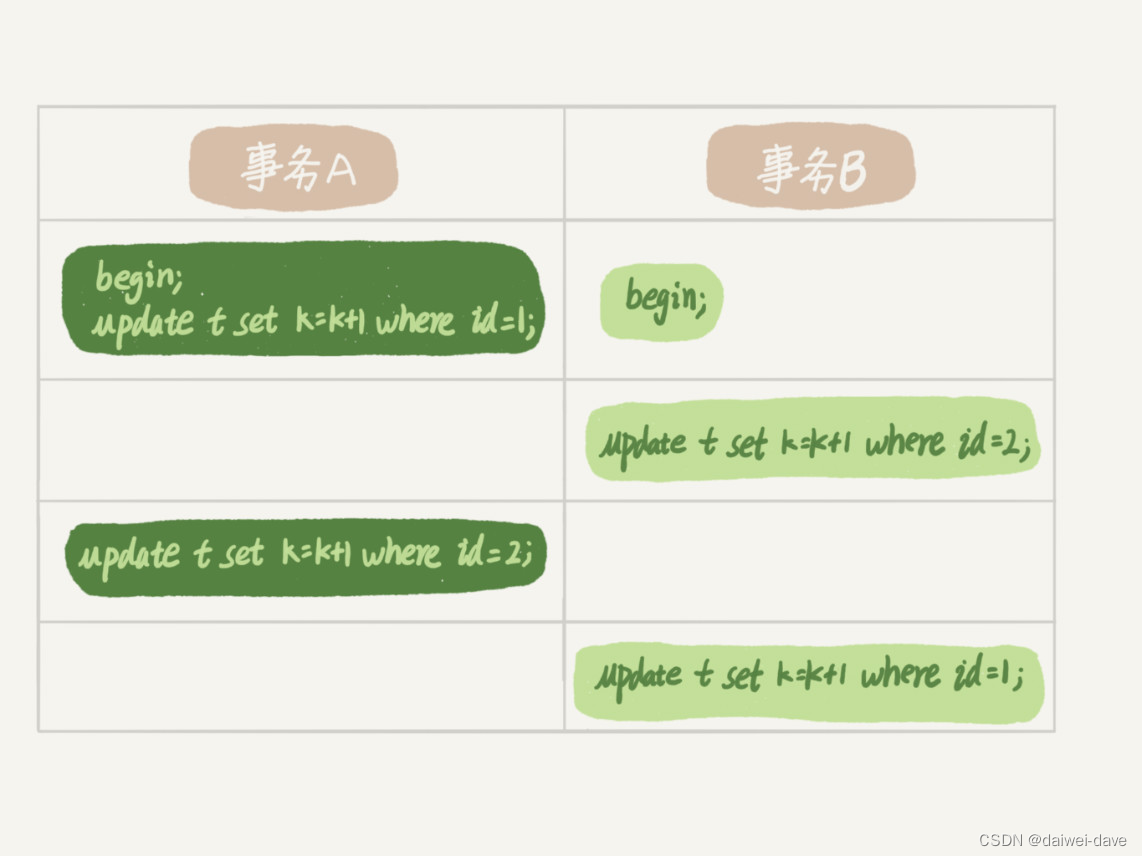
《MySQL实战45讲》
这时候,事务 A 在等待事务 B 释放 id=2 的行锁,而事务 B 在等待事务 A 释放 id=1 的行锁。 事务 A 和事务 B 在互相等待对方的资源释放,就是进入了死锁状态。
当出现死锁以后,有两种策略:
- 一种策略是,直接进入等待,直到超时。这个超时时间可以通过参数 innodb_lock_wait_timeout 来设置,在 InnoDB 中,innodb_lock_wait_timeout 的默认值是 50s
- 另一种策略是,发起死锁检测,发现死锁后,主动回滚死锁链条中的某一个事务,让其他事务得以继续执行。将参数 innodb_deadlock_detect 设置为 on,InnoDB 默认值就是 on表示,开启这个逻辑。
2.死锁等待
在 InnoDB 中,innodb_lock_wait_timeout 的默认值是 50s,意味着如果采用第一个策略,当出现死锁以后,第一个被锁住的线程要过 50s 才会超时退出,然后其他线程才有可能继续执行。对于在线服务来说,这个等待时间往往是无法接受的。
但是,我们又不可能直接把这个时间设置成一个很小的值,比如 1s。这样当出现死锁的时候,确实很快就可以解开,但如果不是死锁,而是简单的锁等待呢?所以,超时时间设置太短的话,会出现很多误伤。
所以,正常情况下我们还是要采用第二种策略,即:主动死锁检测。
3.死锁检测
主动死锁检测在发生死锁的时候,是能够快速发现并进行处理的,但是它也是有额外负担的。
你可以想象一下这个过程:每当一个事务被锁的时候,就要看看它所依赖的线程有没有被别人锁住,如此循环,最后判断是否出现了循环等待,也就是死锁。
那如果是我们上面说到的所有事务都要更新同一行的场景呢?
每个新来的被堵住的线程,都要判断会不会由于自己的加入导致了死锁,这是一个时间复杂度是 O(n) 的操作。假设有 1000 个并发线程要同时更新同一行,那么死锁检测操作就是 100 万这个量级的。虽然最终检测的结果是没有死锁,但是这期间要消耗大量的 CPU 资源。
因此,你就会看到 CPU 利用率很高,但是每秒却执行不了几个事务。
根据上面的分析,我们来讨论一下,怎么解决由这种热点行更新导致的性能问题呢?问题的症结在于,死锁检测要耗费大量的 CPU 资源。
一种头痛医头的方法,就是如果你能确保这个业务一定不会出现死锁,可以临时把死锁检测关掉。但是这种操作本身带有一定的风险,因为业务设计的时候一般不会把死锁当做一个严重错误,毕竟出现死锁了,就回滚,然后通过业务重试一般就没问题了,这是业务无损的。而关掉死锁检测意味着可能会出现大量的超时,这是业务有损的。
另一个思路是控制并发度。根据上面的分析,你会发现如果并发能够控制住,比如同一行同时最多只有 10 个线程在更新,那么死锁检测的成本很低,就不会出现这个问题。一个直接的想法就是,在客户端做并发控制。但是,你会很快发现这个方法不太可行,因为客户端很多。我见过一个应用,有 600 个客户端,这样即使每个客户端控制到只有 5 个并发线程,汇总到数据库服务端以后,峰值并发数也可能要达到 3000。
因此,这个并发控制要做在数据库服务端。如果你有中间件,可以考虑在中间件实现;如果你的团队有能修改 MySQL 源码的人,也可以做在 MySQL 里面。基本思路就是,对于相同行的更新,在进入引擎之前排队。这样在 InnoDB 内部就不会有大量的死锁检测工作了。
可能你会问,如果团队里暂时没有数据库方面的专家,不能实现这样的方案,能不能从设计上优化这个问题呢?
你可以考虑通过将一行改成逻辑上的多行来减少锁冲突。
还是以影院账户为例,可以考虑放在多条记录上,比如 10 个记录,影院的账户总额等于这 10 个记录的值的总和。这样每次要给影院账户加金额的时候,随机选其中一条记录来加。这样每次冲突概率变成原来的 1/10,可以减少锁等待个数,也就减少了死锁检测的 CPU 消耗
这个方案看上去是无损的,但其实这类方案需要根据业务逻辑做详细设计。如果账户余额可能会减少,比如退票逻辑,那么这时候就需要考虑当一部分行记录变成 0 的时候,代码要有特殊处理。
参考资料
1.《MySQL技术内幕:InnoDB存储引擎(第2版)》
2.《MySQL实战45讲》
3.MySQL技术内幕 https://blog.csdn.net/shenchaohao12321/category_8075653.html

