
热门标签
热门文章
- 1【人工智能】人工智能是什么?如何入门人工智能?我们为什么要学人工智能?_人工智能:一种现代的方法 深度学习 统计学习方法
- 2个人主机折腾日记_gt710 uhd630
- 3Lesson 1. 线性回归模型的一般实现形式_线性回归模型训练过程
- 4SSA-BP回归预测|Matlab基于sine混沌映射改进的麻雀算法优化BP神经网络实现风电预测附代码
- 5硬件工程师发展(部分转发)_硬件工程师发展情况
- 6angular中的NgModules的作用以及简单介绍_angular中 ngmoudle作用
- 7微信小程序在设置图片长按保存过程中踩过的坑及解决方法_微信小程序实现长按图片报错
- 82024年手把手教CleanMyMac X v4.14.6破解版安装激活图文教程_cleanmymac x 4.14.6 for mac
- 9【Axure】使用中继器实现登陆注册功能_axure注册登录页面
- 10Java知识:IO流_java bufferedreader(new inputstreamreader)java.io.
当前位置: article > 正文
问题:Spark SQL 读不到 Flink 写入 Hudi 表的新数据,打开新 Session 才可见
作者:繁依Fanyi0 | 2024-02-23 09:10:53
赞
踩
问题:Spark SQL 读不到 Flink 写入 Hudi 表的新数据,打开新 Session 才可见
 | 博主历时三年精心创作的《大数据平台架构与原型实现:数据中台建设实战》一书现已由知名IT图书品牌电子工业出版社博文视点出版发行,点击《重磅推荐:建大数据平台太难了!给我发个工程原型吧!》了解图书详情,京东购书链接:https://item.jd.com/12677623.html,扫描左侧二维码进入京东手机购书页面。 |
问题描述
使用 Flink 向 Hudi 表中写入数据,使用 Spark SQL 的 Shell 查询 Hudi 表(使用的是 Hudi HMS Catalog 统一管理和同步 Hudi 表的元数据),结果在 Spark 中只能查询到打开 Shell 之前表中的数据,之后通过 Flink 写入的数据不可见,但重新打开一个新的 Spark SQL Shell,就可以看到了。
原因分析
这个问题并不是一个 Bug, 在 Hudi 的 Issues 列表中有反馈和讨论:https://github.com/apache/hudi/issues/7452,简单说就是:Spark SQL 的 Shell 所启动的 Session 会 cache 一些表和文件的元数据,在只通过 Spark SQL 这一个“渠道”操作 Hudi 表时是不会有问题的,但这里 Flink 对 Hudi 表的操作完全不在 Spark SQL 的“感知”范围内,Spark SQL 会继续使用自己 Cache 中已经过期的元数据数据,所以没有及时反映出 Flink 对 Hudi 表数据的更改。
解决方法
有两种方法可以“修正”这个问题:
-
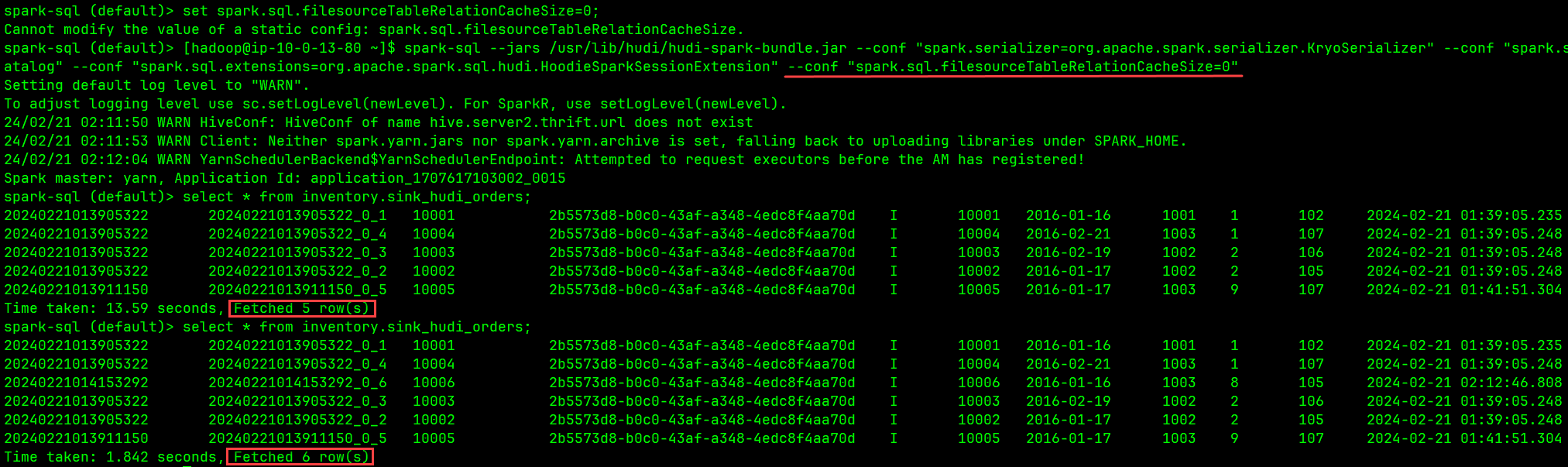
显式地执行一次 refresh table 操作 ,但这个方法不态实用,除非我们在编写 SQL 时能确定应在何时 refresh。下图是一个测试:

-
显式地设置
spark.sql.filesourceTableRelationCacheSize=0,禁止 Spark 缓存相关的元数据,这个是持续生效的,但需要提醒的是该配置项为静态配置,不能在 SQL 中用 set 语句设置,只能在启动 Spark SQL Shell 时通过--conf参数配置,就像这样:spark-sql --jars /usr/lib/hudi/hudi-spark-bundle.jar \ --conf "spark.serializer=org.apache.spark.serializer.KryoSerializer" \ --conf "spark.sql.catalog.spark_catalog=org.apache.spark.sqlatalog" \ --conf "spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension" \ --conf "spark.sql.filesourceTableRelationCacheSize=0"- 1
- 2
- 3
- 4
- 5
下图是一个测试:
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/繁依Fanyi0/article/detail/135255
推荐阅读
相关标签

