
- 1springboot vue婚纱摄影师作品展示网站系统javaweb项目_图片展示网站vue源码
- 2cookie设置_设置cookie
- 3win10内网穿透实现远程桌面连接(超详细) win10+樱花Frp_樱花远程桌面
- 4Podman 安装
- 5【已解决】本地计算机上的mysql服务启动停止后,某些服务在未由其他服务或程序使用时将自动停止_mysql服务启动后停止,某些程序在未有应用
- 6WiFi无法连接?解决macOS Big Sur / Mojave / Catalina上的Wi-Fi问题_mac book pro a1278 catalina后无wifi
- 7dubbo学习笔记(4):dubbo调用机制和容错策略_dubboreference(methods)
- 8【指针面试题】-还在为学过指针的理论只是不会实践吗??赶紧来看看这里讲解了许多指针的面试题,带你更好掌握指针!!!
- 9车载电子电器架构 —— 电气架构开发计划
- 10html语言设计表单实例,40多个漂亮的网页表单设计实例_HTML/Xhtml_网页制作
CVPR2022 |小红书首创多图交互建模挑战热门研究课题,大幅提升行人重识别性能_多模态行人重识别
赞
踩
在CVPR2022上,小红书多模态算法组提出一种新颖的用于行人重识别的网络Neighbor Transformer (NFormer),区别于传统的行人重识别网络仅仅对单张图片进行建模,NFormer对通过transformer对多张输入图像进行交互式建模以获得鲁棒的特征表达,除此之外,NFormer还提出了Landmark Agent Attention 和Reciprocal Neighbor Softmax模块来降低多张图片交互建模时的计算复杂度。实验表明NFormer在多个数据集上性能表现SOTA(state-of-the-art)!

在小红书,大规模图像检索技术应用于搜同款穿搭、相似图片等多项业务中,行人重识别(Person re-identification)作为图像检索中的的一个重要子问题,是指利用用计算机视觉技术判断图像或者视频序列中是否存在特定行人的技术。在真实场应用场景中,由于行人外观易受穿着、尺度、遮挡、姿态和视角等影响,以及不同摄像设备之间成像效果的差异,使得行人重识别成为计算机视觉研究领域中一个极具挑战性的热门课题。

得益于深度学习,尤其是卷积神经网络(Convolutional neural network, CNN)的快速发展,目前主流的行人重识别的方法均基于表征学习框架,即基于Metric Learning技术,来学习行人的向量化表征。在训练时,网络要求将属于同一ID的行人特征聚集的同时将不同ID的行人的特征区分开。在检索时,首先利用网络提取数据库中所有行人的特征构成底库,再将待查询的行人特征与底库特征进行匹配来实现检索。
在传统方法中,网络仅仅考虑从单张图片中获取表征,忽略了图片间潜在的关联, 然而我们认为这种关联能帮助单个图片获得更好的表征。在论文NFormer: Robust Person Re-identification with Neighbor Transformer中,我们提出Neighbor Transformer来对大量输入图片进行交互式建模,以得到更好的图像表征,实验证明该方法能够达到了目前行人重识别的SOTA, 并且可以很容易地和现有方法结合并实现性能提升。

行人重识别旨在跨不同摄像机和场景检索高度变化的环境中的人员,其中行人的表征学习至关重要。大多数研究都考虑从单个图像中学习表征,忽略它们之间的任何潜在交互。然而,由于每个行人类内的高度变化,忽略这种交互通常会导致一些异常离群特征。为了解决这个问题,我们提出了Neighbor Transformer Network, 它显式地对所有输入图像之间的交互进行建模,从而抑制异常特征并获得整体上更鲁棒的表示。
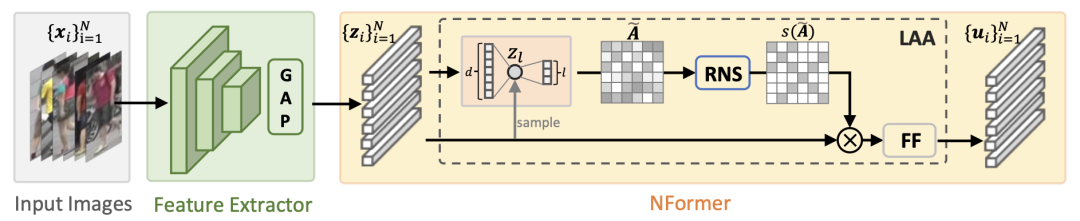
如上图所示。输入一系列待检索的行人图片,我们用卷积网络作为特征提取器来获取每张输入图片的深度特征。然后我们计算图片特征之间的相似度矩阵,并利用得到的相似度矩阵来进行特征融合,得到最终融合后的特征并用于图片检索。
由于在行人重识别任务中输入图片的数量往往很多,直接利用transformer模型对大量图像之间的交互进行建模是一项艰巨任务。因此 NFormer 引入了两个新颖的模块:Landmark Agent Attention 和Reciprocal Neighbor Softmax。具体来说,Landmark Agent Attention 通过在特征空间中使用一些landmark进行低秩分解,有效地对图像之间的关系图进行建模。此外,Reciprocal Neighbor Softmax 实现了对相关(而不是所有)相邻输入图片的稀疏关系矩阵表示。以上两个模块大大降低了transformer中注意力模型的计算量,更加适用于行人重识别任务。

上图为Landmark Agent Attention(左) 和Reciprocal Neighbor Softmax(右)的示意图。当输入N个维度为d的特征时,我们从中采样得到l个landmark,并利用这l个landmark将输入特征从d维空间映射到l维空间。然后我们在l维空间中进行特征的相似度计算并得到相似度矩阵A。由于l的值远小于d,相似度计算的复杂度大大降低了。在得到相似度矩阵A后,传统的transformer会用softmax函数将affinity变成probability,如右图(a)所示。由于输入图片的数量很多,并且其中绝大部分的图片都是不相关的,直接用softmax处理会使得输出的概率分布过于平滑,并且概率会被占大多数的无关输入主导。因此,我们提出了RNS函数,在softmax的过程中只保留少量相关度高的值,在去除干扰项的同时降低了特征融合的计算复杂度。

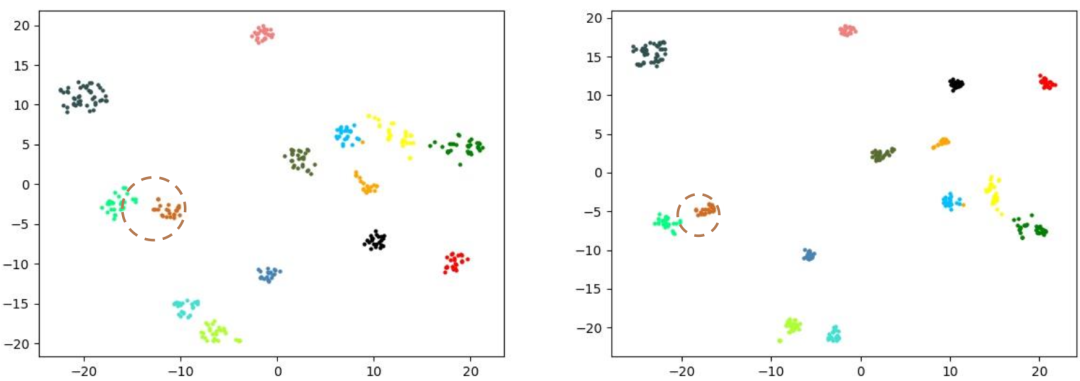
上图为图片特征在经过NFormer之前(左)和之后(右)的t-SNE可视化图,可以看出,经过NFormer的处理后,行人的表征在特征空间的聚合度更好,离群值更少,更有利于后续的重识别过程。

我们在四个公开数据集上测试了NFormer的性能。实验结果表明,我们的方法达到了目前的SOTA。此外,NFormer可以与多个现有方法结合并提升其性能。

上图为NFormer的结果与Baseline模型结果的可视化对比(每一组对比中上面一行为baseline模型结果,下面一行为NFormer结果)。其中红色的框表示检索错误的图片。可以看出,NFormer可以有效减少检索结果中的负样本。

本文通过对多张输入图像进行联合建模来获得鲁棒的特征表达,并提出了Landmark Agent Attention和Reciprocal Neighbor Softmax模块来减少多图联合建模带来的计算量激增问题。实验表明NFormer可以大幅度提升行人重识别性能,并在多个数据集上达到SOTA。图像检索以及多模态检索技术在小红书存在广阔的应用场景,在未来,我们将继续深耕大规模图像检索和多模态检索技术,为用户带来更便捷,更有趣的搜索和消费体验!
论文地址:https://arxiv.org/abs/2204.09331

王昊臣
多模态算法组实习生,本硕毕业于北航,现博士就读于阿姆斯特丹大学VISLab。曾在CVPR, ECCV,ACMMM等计算机视觉顶级会议发表论文6篇。
主要研究方向:视频目标分割,视频表征学习。
亚顿
小红书多模态算法组算法工程师,曾在IJCV,ICCV,NIPS等计算机视觉顶级会议/期刊发表论文5篇
主要研究方向:多模态表征学习,大规模图像检索等。

多模态算法组是小红书内容理解的技术最前线,拥有海量的数据、完善的技术架构、高速发展的业务。通过研发业界领先的大规模多模态模型,支撑起社区搜推、社区生态、安全审核、电商内容等众多核心业务线。整个团队技术氛围浓厚,期待追求卓越的你加入我们,与团队众多的业界知名技术大牛一起用技术推动行业变革。
视觉算法高级工程师-人脸方向
职位描述
负责小红书各业务线的人脸识别技术研发与落地,包含但不限于内容安全、搜索、广告、电商等业务场景;
负责人脸相关算法研发与也业务落地,包括但不限于人脸检测、关键点、属性、识别等;
参与人脸、计算机视觉和人工智能等领域相关前沿技术的跟踪及研究;
负责对各业务场景下人脸相关技术问题进行分析、算法设计、研发以及推动上线,提升业务效果。
职位要求
1年以上图像/视频识别检索等视觉算法研发与项目经验;
编程功底扎实,熟悉深度学习模型的训练和部署,熟悉服务部署上线;
在计算机视觉某个领域有较深入的研究,包括但不限于图像/视频分类、图像分割、目标检测跟踪、人脸识别、OCR、NAS、模型量化剪枝、多模态识别检索、无监督和自监督学习等;
有较强的研究能力,在国际顶尖会议或期刊(包括但不限于CVPR, ICCV, ECCV, NeurIPS, ICML, ICLR, AAAI, IJCAI, ACMMM, TIP, TPAMI, IJCV等)上发表过论文者优先;
有人脸检测、人脸识别等相关研究及开发经验者优先;
有较强的业务问题到算法模型的建模能力,有强烈的求知欲、自驱力和进取心,能及时关注和学习业界最佳实践。
欢迎感兴趣的朋友发送简历至: REDtech@xiaohongshu.com;
并抄送至: tianbuyi@xiaohongshu.com。

