
- 1zabbix企业应用之监控磁盘读写状态_磁盘读入状态
- 2淡黄的炼丹炉(篇二):Esxi 6.5 安装,Ubuntu安装,显卡直通,虚拟机克隆_esxui-signed-12086396.vib
- 3ubuntu备份与还原_ubuntu backups
- 4安卓之BroadcastReceiver的应用与展望
- 5【数据库】键值型数据库 Redis_键值数据库
- 6springBoot打包成 war包并部署tomcat_springboot修改成war包并在tomcat部署
- 7【项目实战】YOLOV5 +实时吸烟目标检测+手把手教学+开源全部
- 8Python多线程只运行一个线程的问题_python多线程只能一个
- 9Mac OS如何安装IDEA_macair4g 能装idea
- 10Java整合百度云实现人脸识别_java 实现人脸识别登录百度云ai 是免费的么
kafka架构详解
赞
踩
概述
Apache Kafka 是分布式发布 - 订阅消息系统,在 kafka 官网上对 kafka 的定义:一个分布式发布 - 订阅消息传递系统。
Kafka 最初由 LinkedIn 公司开发,Linkedin 于 2010 年贡献给了 Apache 基金会并成为顶级开源项目。Kafka 的主要应用场景有:日志收集系统和消息系统。
kafaka架构
kafaka架构比较简单,是显式分布式架构,主要由producer(生产者),broker(kafka集群)和 er(生产者)consumer(消费者)组成。
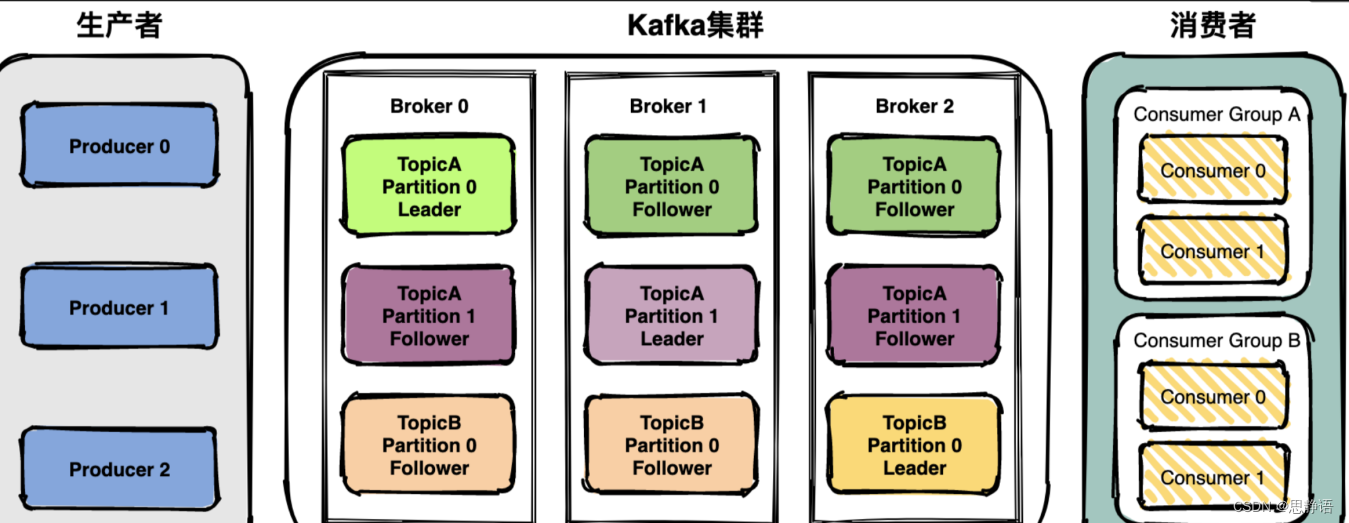
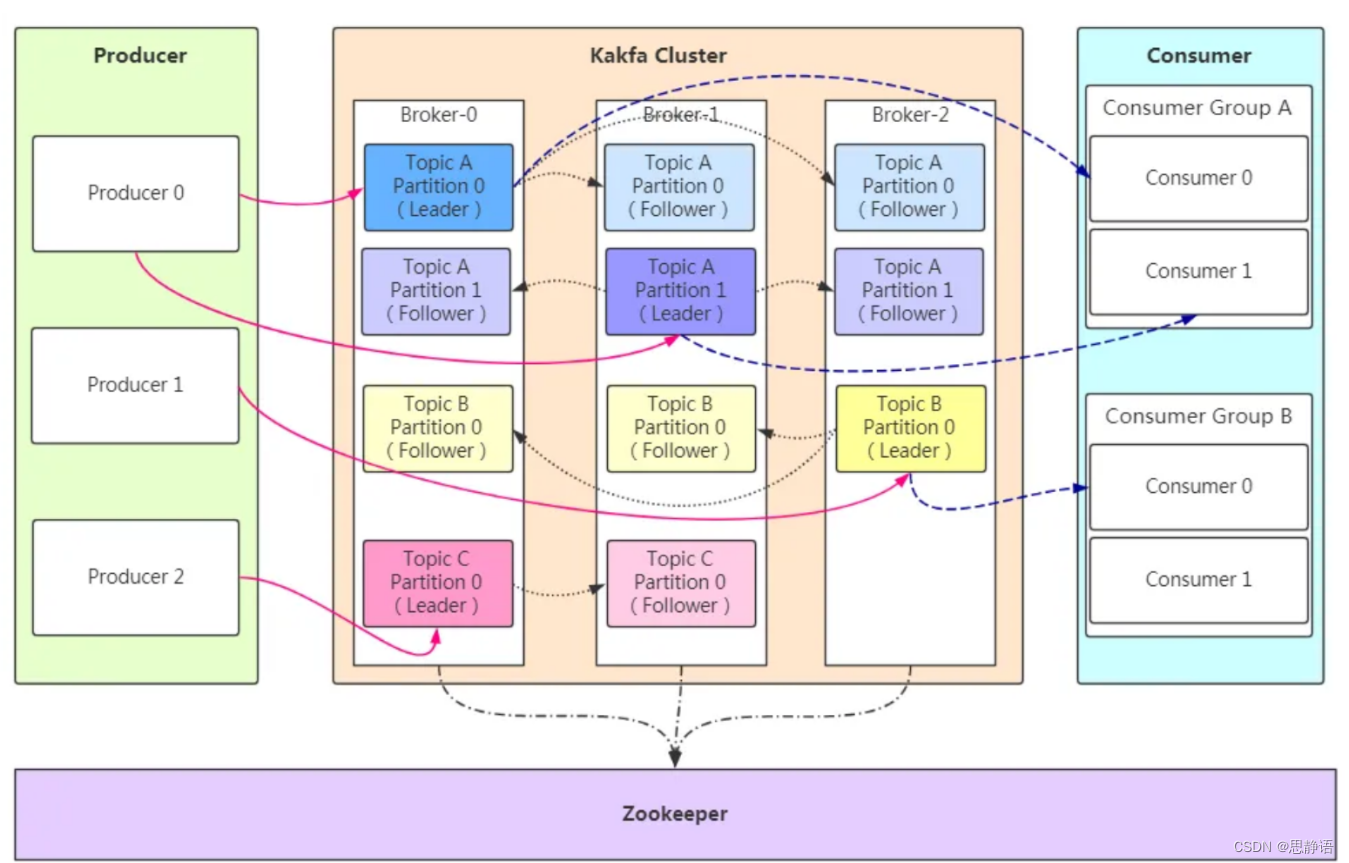
整个架构中包括三个角色。
生产者(Producer):消息和数据生产者。
代理(Broker):缓存代理,Kafka 的核心功能。
消费者(Consumer):消息和数据消费者。
Kafka 给 Producer 和 Consumer 提供注册的接口,数据从 Producer 发送到 Broker,
Broker 承担一个中间缓存和分发的作用,负责分发注册到系统中的 Consumer。
Producer :消息生产者,就是向 kafka broker 发消息的客户端。
Consumer :消息消费者,向 kafka broker 取消息的客户端。
Topic :可以理解为一个队列,一个 Topic 又分为一个或多个分区,
Consumer Group:这是 kafka 用来实现一个 topic 消息的广播(发给所有的 consumer)和单播(发给任意一个 consumer)的手段。一个 topic 可以有多个 Consumer Group。
Broker :一台 kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个broker 可以容纳多个 topic。
Partition:为了实现扩展性,一个非常大的 topic 可以分布到多个 broker上,每个 partition 是一个有序的队列。partition 中的每条消息都会被分配一个有序的id(offset)。将消息发给 consumer,kafka 只保证按一个 partition 中的消息的顺序,不保证一个 topic 的整体(多个 partition 间)的顺序。
Offset:kafka 的存储文件都是按照 offset.kafka 来命名,用 offset 做名字的好处是方便查找。例如你想找位于 2049 的位置,只要找到 2048.kafka 的文件即可。当然 the first offset 就是 00000000000.kafka。
Kafka的设计时什么样的
Kafka将消息以topic为单位进行归纳
将向Kafka topic发布消息的程序成为producers.
将预订topics并消费消息的程序成为consumer.
Kafka以集群的方式运行,可以由一个或多个服务组成,每个服务叫做一个broker.
producers通过网络将消息发送到Kafka集群,集群向消费者提供消息
Kafka 将消息以 topic 为单位进行归纳
将向 Kafka topic 发布消息的程序成为 producers.
将预订 topics 并消费消息的程序成为 consumer.
Kafka 以集群的方式运行,可以由一个或多个服务组成,每个服务叫做一个 broker
producers 通过网络将消息发送到 Kafka 集群,集群向消费者提供消息
1.消息分类按不同类别,分成不同的Topic,Topic⼜拆分成多个partition,每个partition均衡分散到不同的服务器(提⾼并发访问的能⼒)
2.消费者按顺序从partition中读取,不⽀持随机读取数据,但可通过改变保存到zookeeper中的offset位置实现从任意位置开始读取
3.服务器消息定时清除(不管有没有消费)
4.每个partition还可以设置备份到其他服务器上的个数以保证数据的可⽤性。通过Leader,Follower⽅式
5.zookeeper保存kafka服务器和客户端的所有状态信息.(确保实际的客户端和服务器轻量级)
6.在kafka中,⼀个partition中的消息只会被group中的⼀个consumer消费;每个group中consumer消息消费互相独⽴;我们可以认为⼀个group是⼀个"订阅"者,⼀个Topic中的每个partions,只会被⼀个"订阅者"中的⼀个consumer消费,不过⼀个consumer可以消费多个partitions中的消息
7.如果所有的consumer都具有相同的group,这种情况和queue模式很像;消息将会在consumers之间负载均衡.
8.如果所有的consumer都具有不同的group,那这就是"发布-订阅";消息将会⼴播给所有的消费者
9.持久性,当收到的消息时先buffer起来,等到了⼀定的阀值再写⼊磁盘⽂件,减少磁盘IO.在⼀定程度上依赖OS的⽂件系统(对⽂件系统本身优化几乎不可能)
10.除了磁盘IO,还应考虑⽹络IO,批量对消息发送和接收,并对消息进行压缩。
11.在JMS实现中,Topic模型基于push⽅式,即broker将消息推送给consumer端.不过在kafka中,采用了pull⽅式,即consumer在和broker建⽴连接之后,主动去pull(或者说fetch)消息;这种模式有些优点,⾸先consumer端可以根据自己的消费能力适时的去fetch消息并处理,且可以控制消息消费的进度(offset);此外,消费者可以良好的控制消息消费的数量,batch fetch.
12.kafka无需记录消息是否接收成功,是否要重新发送等,所以kafka的producer是⾮常轻量级的,consumer端也只需要将fetch后的offset位置注册到zookeeper,所以也是⾮常轻量级的.
Zookeeper 在 Kafka 中的作用
Apache Kafka 的一个关键依赖是 Apache Zookeeper,它是一个分布式配置和同步服务。Zookeeper 是 Kafka 代理和消费者之间的协调接口。Kafka 服务器通过 Zookeeper 集群共享信息。Kafka 在 Zookeeper 中存储基本元数据,例如关于主题,代理,消费者偏移(队列读取器)等的信息。
由于所有关键信息存储在 Zookeeper 中,并且它通常在其整体上复制此数据,因此Kafka代理/ Zookeeper 的故障不会影响 Kafka 集群的状态。Kafka 将恢复状态,一旦 Zookeeper 重新启动。 这为Kafka带来了零停机时间。Kafka 代理之间的领导者选举也通过使用 Zookeeper 在领导者失败的情况下完成。
kafka 不能脱离 zookeeper 单独使用,因为 kafka 使用 zookeeper 管理和协调 kafka 的节点服务器。
Broker 注册 :在 Zookeeper 上会有一个专门用来进行 Broker 服务器列表记录的节点。
每个 Broker 在启动时,都会到 Zookeeper 上进行注册,即到 /brokers/ids 下创建属于
自己的节点。每个 Broker 就会将自己的 IP 地址和端口等信息记录到该节点中去
Topic 注册 : 在 Kafka 中,同一个 Topic 的消息会被分成多个分区并将其分布在多个
Broker 上,这些分区信息及与 Broker 的对应关系也都是由 Zookeeper 在维护。比如我
创建了一个名字为 my-topic 的主题并且它有两个分区,对应到 zookeeper 中会创建这
些文件夹:/brokers/topics/my-topic/Partitions/0、/brokers/topics/my
topic/Partitions/1
负载均衡 :上面也说过了 Kafka 通过给特定 Topic 指定多个 Partition, 而各个 Partition
可以分布在不同的 Broker 上, 这样便能提供比较好的并发能力。 对于同一个 Topic 的不
同 Partition,Kafka 会尽力将这些 Partition 分布到不同的 Broker 服务器上。当生产者
产生消息后也会尽量投递到不同 Broker 的 Partition 里面。当 Consumer 消费的时候,
Zookeeper 可以根据当前的 Partition 数量以及 Consumer 数量来实现动态负载均衡

