
- 1gradle缓存位置及拷贝jar到maven资源库_.gradle/caches/
- 2Zookeeper+Hadoop+Spark+Flink+Kafka+Hbase+Hive 完全分布式高可用集群搭建(保姆级超详细含图文)_如何完成hadoop、kafka、flink服务部署
- 3Java 8判断日期是早于还是晚于另一个日期_java中时间大于是早还是晚、
- 4中职计算机的怎么参加高考,中职学生如何参加新高考?
- 5河北职高计算机专业高考分数线,河北职高对口本科大学录取分数线
- 6AIDL实现远程调用的小例子_aidl 反响调用
- 7红队攻击:初始访问_appvlp
- 8【LabVIEW FPGA入门】FPGA中的数据流
- 9【Jetbrains】常用技巧: Pycharm/IDEA/Goland/CLion等_pycharm、datagrip、goland、idea
- 10androidstudio无法识别华为真机解决方式_androidstudio 读不出来华为手机
LoRA原理解析_lora论文讲解
赞
踩
前言
随着模型规模的不断扩大,微调模型的所有参数(所谓full fine-tuning)的可行性变得越来越低。以GPT-3的175B参数为例,每增加一个新领域就需要完整微调一个新模型,代价和成本非常高!
论文:LORA: LOW-RANK ADAPTATION OF LARGE LANNGUAGE MODELS
代码:https://github.com/microsoft/LoRA
现有方案存在的问题
Adapter Tuning
简单来说,adapter就是固定原有的参数,并添加一些额外参数用于微调。上图中会在原始的transformer block中添加2个adapter,一个在多头注意力后面,另一个这是FFN后面。
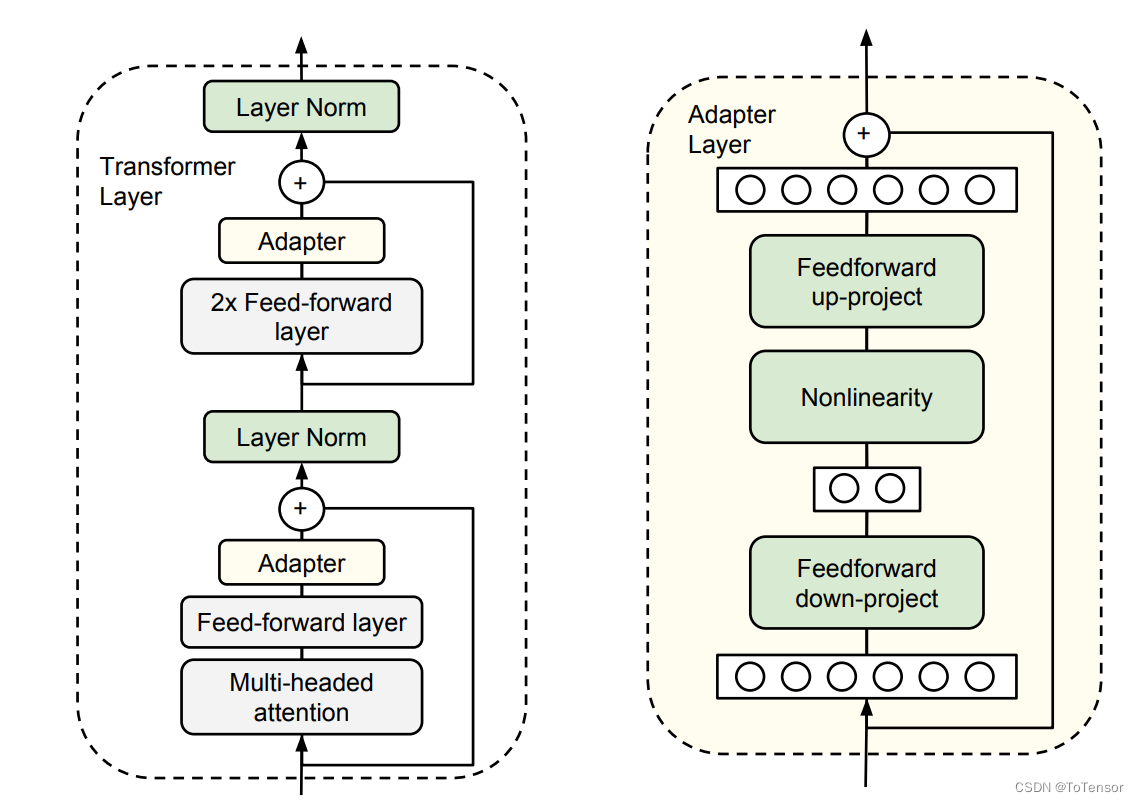
从图中可以看出,Adapter增加了模型的层数,导致模型推理速度变慢
Prefix Tuning
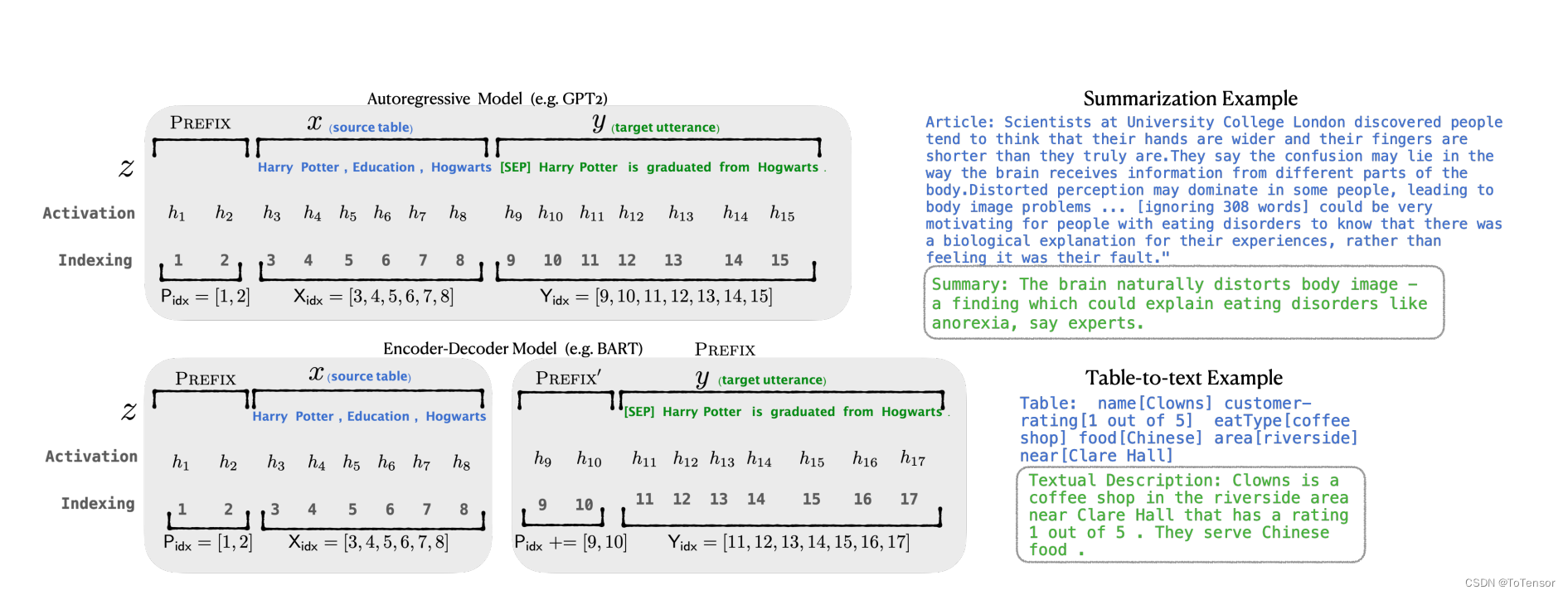
具体来说,对于transformer中的每一层,都在句子表征前面插入可训练的virtual token embedding。对于自回归模型(GPT系列),在句子前添加连续前缀,即 Z = [PREFIX; x; y].
对于Encoder-Decoder模型(T5),则在Ecoder和Decoder前都添加连续前缀 Z = [PREFIX; x | PREFIX; y].
添加前缀的过程如上图
虽然,prefix-tuning并没有添加太多的额外参数;但是,prefix-tuning难以优化,且会减少下游任务的序列长度。
LoRA
LoRA的几个关键优势:
- 预训练的模型可以共享,节省硬盘开销
- 切换任务时,只需要更换LoRA权重,成本低
- 训练时只需训练LoRA权重,内存消耗低
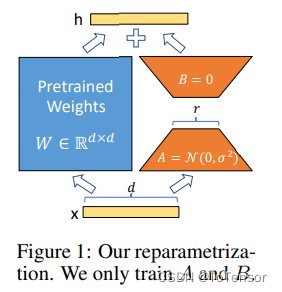
简单理解:在模型的Linear层的旁边,增加一个“旁支”,这个“旁支”的作用,就是代替原有的参数矩阵W进行训练。
结合上图,我们来直观地理解一下这个过程,输入
x
x
x,具有维度
d
d
d,举个例子,在普通的transformer模型中,这个
x
x
x可能是embedding的输出,也有可能是上一层transformer layer的输出,而
d
d
d一般就是768(大多数Bert的输出维度是768)。按照原本的路线,它应该只走左边的部分,也就是原有的模型部分。
而在LoRA的策略下,增加了右侧的“旁支”,也就是先用一个Linear层A,将数据从 d d d维降到 r r r维,这个 r r r也就是LORA的秩,是LoRA中最重要的一个超参数。一般会远远小于 d d d (见的比较多的是4、8),尤其是对于现在的大模型, d d d已经不止是768或者1024,例如LLaMA-7B,每一层transformer有32个head,这样一来 d d d就达到了4096.
接着再用第二个Linear层B,将数据从
r
r
r变回
d
d
d维。最后再将左右两部分的结果相加融合,就得到了输出的hidden_state。
对于左右两个部分,右侧看起来像是左侧原有矩阵 W W W的分解,将参数量从 d ∗ d d * d d∗d变成了 d ∗ r + r ∗ d d * r + r * d d∗r+r∗d,也就是 2 ∗ d ∗ r 2 * d * r 2∗d∗r,在 r < < d r << d r<<d的情况下,参数量就大大地降低了。
在Albert中,作者考虑到词表的维度很大,所以将Embedding矩阵分解成两个相对较小的矩阵,用来模拟Embedding矩阵的效果,这样一来需要训练的参数量就减少了很多。(实际上也就减少了10M左右,Albert参数量较少的主要原因跨层参数共享)

LoRA也是类似的思想,并且它不再局限于Embedding层,而是所有出现大矩阵的地方,理论上都可以用到这样的分解。
但是与Albert不同的是,Albert直接用两个小矩阵替换了原来的大矩阵,而LoRA保留了原来的矩阵W,但是不让W参与训练,所以需要计算梯度的部分就只剩下旁支的A和B两个小矩阵。
从论文中的公式来看,全参微调时,模型训练的优化表示为(以自回归语言模型为例):
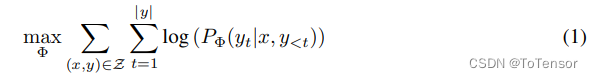
即最大化条件概率
其中,模型的参数用 Φ \Phi Φ表示。
全参微调的一个主要缺点是,对于每个下游任务,都需要学习一组不同的参数,如果预训练的模型很大,如GPT3(1750亿参数),存储和部署许多独立的微调模型实例可能是一项挑战。
而加入了LoRA之后,模型的优化表示为:
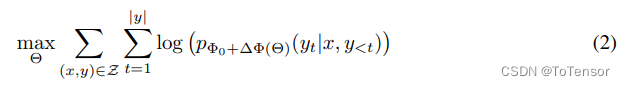
其中,模型原有的参数是
Φ
0
\Phi_0
Φ0 ,LoRA新增的参数是
Δ
Φ
(
Θ
)
\Delta \Phi\left(\Theta\right)
ΔΦ(Θ)。
从第二个式子可以看到,尽管参数看起来增加了(多了 Δ Φ ( Θ ) \Delta \Phi\left(\Theta\right) ΔΦ(Θ)),但是从前面的max的目标来看,需要优化的参数只有 Θ \Theta Θ,而根据假设, Θ < < Φ Θ << \Phi Θ<<Φ,这就使得训练过程中,梯度计算量少了很多,所以就在低资源的情况下,我们可以只消耗 Θ \Theta Θ这部分的资源,这样一来就可以在单卡低显存的情况下训练大模型了。
训练完之后只保存lora部分的参数(就是可训练的参数)进行推理时可以先把这些参数加到原始模型上形成新的模型(图1中顶部的大+号部分),然后再加载进行推理,这样和原模型相比不会增加任何额外的推理时间开销。
目前的LLM都是由上亿级别的数据训练而成,LoRA通过保持原模型的梯度,可以避免预训练泛化能力的坍塌。这是因为在预训练过程中,模型已经学习到了大量的语言知识和结构,这些知识和结构可以被应用到各种下游任务中。但是,在完全微调的过程中,模型的所有参数都被重新训练,这可能会导致模型忘记之前学习到的知识和结构,从而降低了模型的泛化能力。
相比之下,LoRA只对部分参数进行微调,而保持了原模型的梯度。这样做的好处是,LoRA可以在保持原模型的语言知识和结构的同时,对特定任务进行微调,从而提高模型的性能。此外,LoRA的低秩矩阵注入方法可以进一步提高模型的泛化能力,因为低秩矩阵可以捕捉到数据中的共性和规律,从而减少了过拟合的风险。
因此,通过保持原模型的梯度,LoRA可以避免预训练泛化能力的坍塌,并提高模型的泛化能力和性能。
官方实现
这里只贴出Lora在Linear层的实现。全部代码参阅:https://github.com/microsoft/LoRA
class Linear(nn.Linear, LoRALayer): # LoRA implemented in a dense layer def __init__( self, in_features: int, out_features: int, r: int = 0, lora_alpha: int = 1, lora_dropout: float = 0., fan_in_fan_out: bool = False, # Set this to True if the layer to replace stores weight like (fan_in, fan_out) merge_weights: bool = True, **kwargs ): nn.Linear.__init__(self, in_features, out_features, **kwargs) LoRALayer.__init__(self, r=r, lora_alpha=lora_alpha, lora_dropout=lora_dropout, merge_weights=merge_weights) self.fan_in_fan_out = fan_in_fan_out # Actual trainable parameters if r > 0: self.lora_A = nn.Parameter(self.weight.new_zeros((r, in_features))) self.lora_B = nn.Parameter(self.weight.new_zeros((out_features, r))) self.scaling = self.lora_alpha / self.r # Freezing the pre-trained weight matrix self.weight.requires_grad = False self.reset_parameters() if fan_in_fan_out: self.weight.data = self.weight.data.transpose(0, 1) def reset_parameters(self): nn.Linear.reset_parameters(self) if hasattr(self, 'lora_A'): # initialize A the same way as the default for nn.Linear and B to zero nn.init.kaiming_uniform_(self.lora_A, a=math.sqrt(5)) nn.init.zeros_(self.lora_B) def train(self, mode: bool = True): def T(w): return w.transpose(0, 1) if self.fan_in_fan_out else w nn.Linear.train(self, mode) if mode: if self.merge_weights and self.merged: # Make sure that the weights are not merged if self.r > 0: self.weight.data -= T(self.lora_B @ self.lora_A) * self.scaling self.merged = False else: if self.merge_weights and not self.merged: # Merge the weights and mark it if self.r > 0: self.weight.data += T(self.lora_B @ self.lora_A) * self.scaling self.merged = True def forward(self, x: torch.Tensor): def T(w): return w.transpose(0, 1) if self.fan_in_fan_out else w if self.r > 0 and not self.merged: result = F.linear(x, T(self.weight), bias=self.bias) if self.r > 0: result += (self.lora_dropout(x) @ self.lora_A.transpose(0, 1) @ self.lora_B.transpose(0, 1)) * self.scaling return result else: return F.linear(x, T(self.weight), bias=self.bias)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
从实现代码中也可以看出,LoRA冻结了PLM的参数,实际需要训练的参数只有lora_A,lora_B,并且,在训练的时候,PLM权重是需要参与计算的,因此LoRA并非是训练高效的。
总结
-
LoRA只是参数高效、而并非训练高效,也就是可训练的参数确实是少了很多,但是在单卡上训练速度并没有明显提升。
在LoRA中,需要整个PLM参与反向传播的计算,而不仅仅是反向传播旁路的部分参数。这是因为LoRA的低秩矩阵注入方法需要使用整个PLM的梯度信息来计算注入矩阵的梯度。具体来说,LoRA的梯度计算包括两个步骤:首先,需要计算整个PLM的梯度;然后,需要使用这些梯度来计算注入矩阵的梯度。
-
在多卡训练中,LoRA的速度优势主要体现在两个方面:
-
计算效率:由于LoRA只需要计算和优化注入的低秩矩阵,因此它的计算效率比完全微调更高。在多卡训练中,LoRA可以将注入矩阵的计算和优化分配到多个GPU上,从而加速训练过程。
-
通信效率:在多卡训练中,通信效率通常是一个瓶颈。由于LoRA只需要通信注入矩阵的参数,因此它的通信效率比完全微调更高。在多卡训练中,LoRA可以将注入矩阵的参数分配到多个GPU上,从而减少通信量和通信时间。
因此,LoRA在多卡训练中通常比完全微调更快。具体来说,LoRA可以将硬件门槛降低多达3倍,从而提高训练的效率。
-
参阅:

