
- 1微信小程序消息推送,实现未完成计划的在微信内的定时提醒功能_微信小程序定时提醒功能
- 2京津冀协同发展:北京·光子1号金融算力中心——智能科技新高地
- 3Linux_192.168.66.1
- 4andorid 检测内存泄露及解决办法_android oom 内存泄漏 内存溢出
- 5DSPE-PEG-MAL,474922-22-0,DSPE-PEG-Maleimide_dspe-peg-mal结构式
- 6python np linspace_Python numpy.linspace() 使用实例
- 72023 华为 Datacom-HCIE 真题题库 06/12--含解析_网络管理员真题
- 8红黑树原理简单解析_红黑树的原理
- 9HDC2021技术分论坛:ArkUI 3.0让多设备开发更简单_arkui 设置组件宽高比
- 10JAVA实现websocket_websocket java
人工智能里程碑ChatGPT之最全详解图解_chatgpt的算法架构图
赞
踩
人工智能里程碑ChatGPT之最全详解图解

1. ChatGPT的前世今生
2022年11月30日,美国硅谷的初创公司OpenAI推出了名为ChatGPT的AI聊天机器人,已经拥有超过一百万的用户,受到热烈的讨论,短短几天就火爆全网。它既能完成包括写代码,查BUG,翻译文献,写小说,写商业文案,写游戏策划,作诗等一系列常见文字输出型任务,也可以在和用户对话时,记住对话的上下文,给人一种仿佛是在与真人对话的错觉。ChatGPT的出现成为了人工智能里程碑式的事件。
尽管业内人士认为,ChatGPT仍存在数据训练集不够新、不够全等问题,但在人工智能将走向何方,人工智能与人类的关系将如何发展?这些问题,任然是有待我们思考的问题。
1.1 ChatGPT演化路线
| 模型 | 发布时间以及参数量 |
|---|---|
| GPT-1 | 2018年6月 1.17亿 |
| GPT-2 | 2019年2月 15亿 |
| GPT-3 | 2020年11月 1750亿 |
| ChatGPT | 2022年11月 千亿级 |
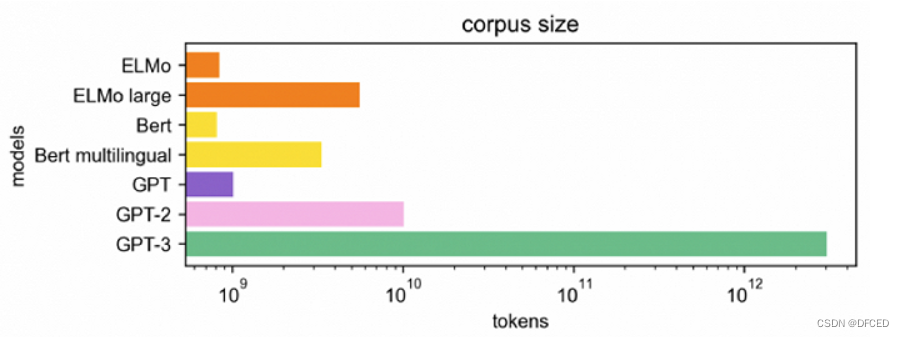 不同模型的数据集规模 不同模型的数据集规模 |
1.2技术推进路线
| 时间 模型 | 相关论文 |
|---|---|
| 2017年6月 Transformer模型 | 《Attention is all you need》 GPT发展的基础 |
| 2018年6月 GPT模型(Generative Pre-Training) | 《Improving Language Understanding by Generative Pre-Training》 通过生成式预训练提升语言理解能力 |
| 2019年2月 GPT-2模型 | 《Language Models are Unsupervised Multitask Learners》 提出了一个无监督多任务学习者 |
| 2020年5月 GPT-3模型 | 《Language Models are Few-Shot Learners》 少样本下的学习模型 |
| 2022年2月底 Instruction GPT模型 | 《Training language models to follow instructions with human feedback》 使用反馈指令流来控制模型 |
| 2022年11月30日 ChatGPT模型 | ChatGPT发布 |
2.ChatGPT主要功能及应用领域
2.1 主要功能
- ChatGPT以质疑不正确的问题。例如被询问 “哥伦布 2015 年来到美国的情景” 的问题时,机器人会说明哥伦布不属于这一时代并调整输出结果。
- ChatGPT可以承认自身的无知,承认对专业技术的不了解。
- ChatGPT能够进行持续的多轮对话
- 能够主动承认错误并指出用户的错误,ChatGPT能够听取意见并优化答案。

 (以上图片来自于网络)
(以上图片来自于网络)
2.2 应用领域
移动互联网领域 - 围绕ChatGPT打造硬件生态,可能产生新的生态。毕竟已经有网友表示愿意为ChatGPT每月付费1千美元,而且这样的个性化助理一旦与用户适配,切换难度极高。 为了强调个人助理的作用,手机或许会重新改名为PDA(个人数字化助手)。 当然,由于谷歌、DeepMind、Meta等公司都会产生这一技术,OpenAI未必一家独大。还可能出现“个人助理专家组”。例如各家助理给苹果提供API,苹果作为委员会组长,收集整合各家意见后再提供给用户。
- 创作诗歌-ChatGPT对素材收集整理、改写、扩充、摘要都有帮助,写作的质量和效率都能得到全方位提升。AI辅助写作极有可能成为写作的主流方式。随着UGC成为AIGC,文字作品的内容质量也能更上一层楼,AI创作剧本/动画也很近了。 对于实用型写作,例如:严肃新闻、科学书籍等,AI能起到辅助效果。 对于虚构类写作,AI能发挥扩展素材、辅助想象甚至直接创作的作用。 对于评论,例如:网评、书评、书摘、商品评价、甚至乐评、影评等。AI会为创作者提供全新的视角,甚至是更为”中立客观“的评价,但也会带来一定混乱。有中立客观的模型,就能有偏颇混乱的模型,训练数据或几个参数的调整就能做到。虽然可以把这种混乱的矛头指向内容分发环节,但也和内容生产不无关系。 对于各类研报/文案/手册,由于这些文档会成为人类行为的指导。因此从这个角度来说,AI会深刻影响各方面的人类行为。 代码:写代码、改代码、调试代码,都不在话下。
- 教育培训ChatGPT在教育培训领域的应用,主要集中在中英口语和作文辅导上,这与ChatGPT背后基于海量数据生成的AI大模型息息相关。它把能获取的人类书籍、学术论文、新闻、高质量的各种信息作为学习内容,并根据人类反馈强化学习。该技术的突破也使得ChatGPT的对话更贴近人类,语段间逻辑关联度显著提升。ChatGPT还可以作为有效的教学辅导工具,发挥其强大的“智能”作用,帮助老师为学生提供个性化的教学辅导,进一步提高老师教学、学生学习的效率。ChatGPT扮演着类似“班主任”的管理身份,一是可以帮助学生尽快地学习这堂课里面的所有的精髓要点,二是能够完整地跟踪学生的自己的学习的一个进度和学习的这种对知识的掌握程度,给学生可以进行练习和提问,这样就加大了这学生对课程的一种掌握能力。
- 自然语言处理这是ChatGPT的看家本领,由于ChatGPT具有良好的语言理解能力,当前NLP应用的的所有应用领域,都将得到极大的增强。例如语音助手、医疗。几乎所有任务,包括分词句法等底层任务、信息抽取、机器翻译、智能写作。小样本、迁移学习等研究方向。所有领域都面临重新思考。这比5年前BERT产生的影响大一个数量级。 用于自然语言生成:由于ChatGPT具有良好的语言理解能力,它可以被用于生成各种文本类型的内容,包括新闻文章、脚本、音频剧本等。 用于文本摘要:ChatGPT可以用于从大量文本中提取摘要信息,帮助人们快速了解文本内容。 用于机器翻译:ChatGPT可以用于翻译大量的文本内容,并且比传统机器翻译系统更快更准确。 用于对话系统:ChatGPT可以模拟人类对话,并生成自然语言回复。它可以用于客服系统、聊天机器人等应用场景。
3.1ChatGPT原理
3.1 ChatGPT基石之Transformer
ChatGPT全称Generative Pre-Training Transfomer,我们来拆解一下,Generative:可生成的,生成式的
Pre-Training:预训练
Transfomer:专有名词不译为好。直译:变换器 意译:依靠自注意机制将输入嵌入序列转换为输出嵌入序列,不依赖卷积或循环神经网络的一种神经网络结构。
3.1.1Transformer结构图
如下图所示,Transformer由self-Attenion和Feed Forward Neural Network组成
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mepP8jcS-1677679582854)(null)]Trans](https://img-blog.csdnimg.cn/61c066ef4b3644e58d0c96d4afc885ca.png)
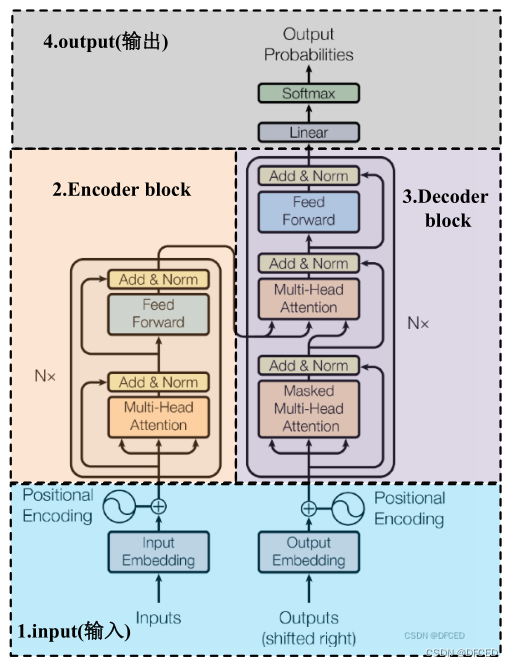
3.1.2 Transformer结构图
如下图所示,Transformer由四部分组成
- Input(输入)
- Encoder block
- Decoder block
- output(输出)
* 关于Transformer的详细原理请关注我的文章
3.2 ChatGPT训练过程
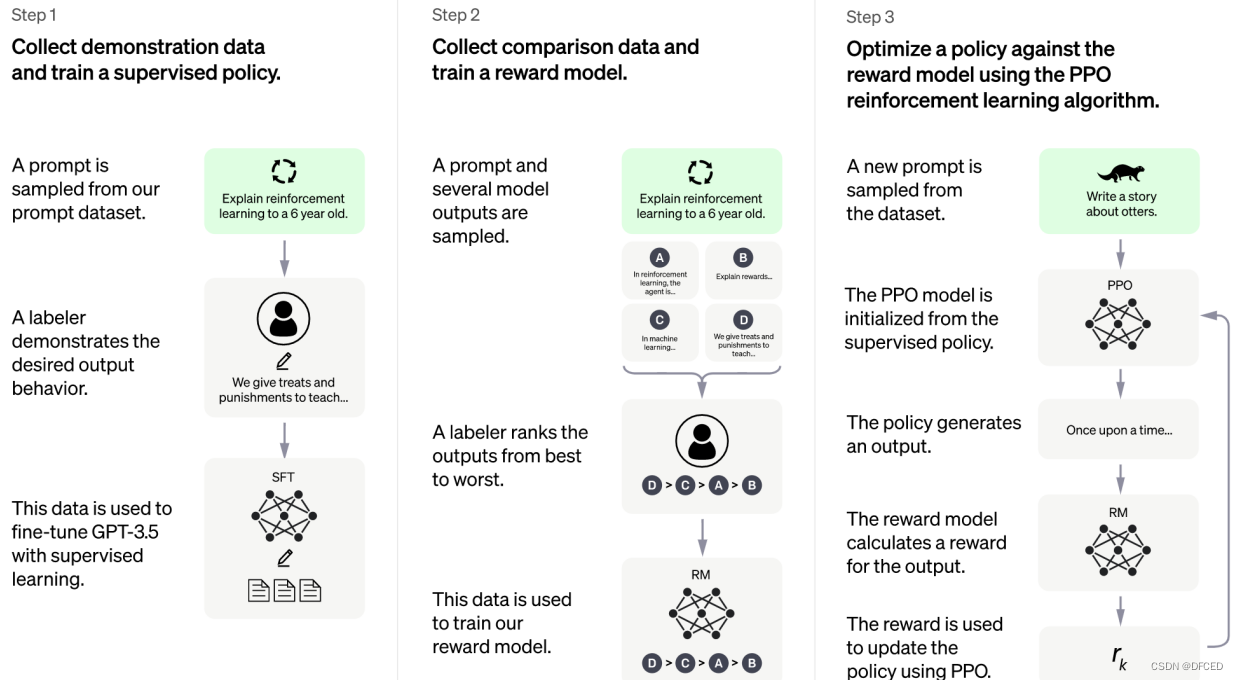
3.2.1 训练监督策略模型
GPT 3.5本身很难理解人类不同类型指令中蕴含的不同意图,也很难判断生成内容是否是高质量的结果。为了让GPT 3.5初步具备理解指令的意图,首先会在数据集中随机抽取问题,由专业的人类标注人员,给出每个问题(prompt)的高质量答案,形成(prompt,answer)问答对,然后用这些人工标注好的数据来微调 GPT-3.5模型(获得SFT模型, Supervised Fine-Tuning)。
经过这个过程,可以认为SFT初步具备了理解人类问题中所包含意图,并根据这个意图给出相对高质量回答的能力,但是很明显,仅仅这样做是不够的,因为其回答不一定符合人类偏好。
3.2.2 训练奖励模型
这个阶段主要是通过人工标注训练数据,来训练奖励模型(Reward Mode)。在数据集中随机抽取问题,使用第一阶段训练得到的模型,对于每个问题,生成多个不同的回答。人类标注者对这些结果综合考虑(例如:相关性、富含信息性、有害信息等诸多标准)给出排名顺序。这一过程类似于教练或老师辅导。
接下来,使用这个排序结果数据来训练奖励模型。对多个排序结果,两两组合,形成多个训练数据对。奖励模型接受一个输入,给出评价回答质量的分数。这样,对于一对训练数据,调节参数使得高质量回答的打分比低质量的打分要高。
3.2.3 使用强化学习来增强模型的能力
PPO(Proximal Policy Optimization,近端策略优化)强化学习模型的核心思路在于将Policy Gradient中On-policy的训练过程转化为Off-policy,即将在线学习转化为离线学习,这个转化过程被称之为Importance Sampling。PPO由第一阶段的监督策略模型来初始化模型的参数,这一阶段利用第二阶段训练好的奖励模型,靠奖励打分来更新预训练模型参数。具体而言,在数据集中随机抽取问题,使用PPO模型生成回答,并用上一阶段训练好的奖励模型给出质量分数。把奖励分数依次传递,由此产生策略梯度,通过强化学习的方式以更新PPO模型参数。
如果我们不断重复第二和第三阶段,通过迭代,会训练出更高质量的ChatGPT模型。
4.如何使用ChatGPT
关于如何注册ChatGPT请关注我的文章
4.1 回复邮件或回信
每隔一段时间,我们的邮箱总是会收到很多积压邮件,其中很多商务性质的邮件需要我们一一回复。这些商务邮件的回复涉及人情世故,要仔细把握语气,认真遣词造句,非常费神。这些工作不如交给ChatGPT来代笔,比如让ChatGPT “帮我写商务邮件回信,告知对方需求已经收到,我们正在全力跟进”。
在给别人回信时,也可以使用ChatGPT来回复,比如感谢朋友的来信,让ChatGPT写一封感谢朋友并邀请朋友来家做客的信件。
4.2 修改代码
可以使用ChatGPT修复代码中的错误并获得调试帮助,同时也可以让ChatGPT写带有注释的代码,极大简化了程序员的工作流程
4.3 写作/写文章
可以使用ChatGPT生成初稿,提高工作效率,同时也可以将其作为素材使用。当然,在闲暇之余,还可以使用ChatGPT写几首诗陶冶陶冶自己的情操,并且可以问ChatGPT几个有趣的问题娱乐一下,放松放松心情。
5.ChatGPT的不足与挑战
5.1 ChatGPT的不足
5.1.1 训练数据可能存在偏差
ChatGPT的训练数据是基于互联网世界海量文本数据的,如果这些文本数据本身不准确或者带有某种偏见,目前的ChatGPT是无法进行分辨的,因此在回答问题的时候会不可避免的将这种不准确以及偏见传递出来。
5.1.2 训练成本高昂
ChatGPT属于NPL领域中的非常大的深度学习模型,其训练参数以及训练数据都非常巨大,因此如果想训练ChatGPT就需要使用大型数据中心以及云计算资源,以及大量的算力和存储空间来处理海量的训练数据,简单来说训练和使用ChatGPT的成本还是非常高的。
5.1.3 适用场景局限
目前ChatGPT主要可以处理自然语言方面的问答以及任务,在其他领域比如图像识别、语音识别等还不局必然相应的处理能力,但是相信在不远的将来可能会有结合图片,视频,音频的GPT,让我们拭目以待。
5.2 ChatGPT面临的挑战
5.2.1 语料库获取途径问题
如果ChatGPT通过抓取互联网上的信息获得其训练数据,可能并不合法。网站上的隐私政策条款本身表明数据不能被第三方收集,ChatGPT抓取数据会涉及违反合同。在许多司法管辖区,合理使用原则在某些情况下允许未经所有者同意或版权使用信息,包括研究、引用、新闻报道、教学讽刺或批评目的。但是ChatGPT并不适用该原则,因为合理使用原则只允许访问有限信息,而不是获取整个网站的信息。在个人层面,ChatGPT需要解决未经用户同意大量数据抓取是否涉及侵犯个人信息的问题。
5.2.2 数据安全
用户在使用ChatGPT时会输入信息,由于ChatGPT强大的功能,一些员工使用ChatGPT辅助其工作,这引起了公司对于商业秘密泄露的担忧。因为输入的信息可能会被用作ChatGPT进一步迭代的训练数据。
5.2.3 删除权限
ChatGPT用户必须同意公司可以使用用户和ChatGPT产生的所有输入和输出,同时承诺ChatGPT会从其使用的记录中删除所有个人身份信息。然而ChatGPT未说明其如何删除信息,而且由于被收集的数据将用于ChatGPT不断的学习中,很难保证完全擦除个人信息痕迹。
6.总结
ChatGPT可以说是人工智能发展史上的里程碑之作,它使得人类距离通用人工智能,强人工智能更近了一步,ChatGPT强大的功能令人瞠目结舌,同时它也面临着诸多挑战,但是我们可以相信,在不远的将来,ChatGPT一定会迈上新的台阶,强人工智能时代也终将会到来,那时的人类社会一定会发生前所未有的新变化,也终将迎来第五次工业革命,人工智能也终将成为人类发展史上璀璨的明珠
7.欢迎大家加入 ChatGPT智库(知识星球 or 专栏)
7.1 这是我跟我的朋友们一起创建的星球,里面有很多全球top20硕博以及海内外行业大佬,知识分享不易,希望大家多多支持!万分感谢

![[ 云计算 | AWS ] ChatGPT 竞争对手 Claude 3 上线亚马逊云,实测表现超预期](https://img-blog.csdnimg.cn/direct/73f803739ca04eefb804ccda18780f38.png?x-oss-process=image/resize,m_fixed,h_300,image/format,png)

