
- 1鸿蒙2.0和安卓的区别,华为鸿蒙二代和安卓有什么区别?鸿蒙2.0和安卓系统区别介绍...
- 2vue Element UI走马灯组件重写_vue走马灯组件
- 3mainfestPlaceholders配置不同的变量的妙用_manifestplaceholders meta
- 4安卓studio的结业总结_android studi实训报告结束语
- 526.RocketMQ之生产者发送消息源码
- 6Android开发随手记_com.android.internal.widget.actionbarcontextview c
- 7项目管理:职业生涯的一个阶段(转)
- 8清北学霸都在用的记笔记方法,学习效率直接Max!
- 9Python GUI教程:在PyQt5中使用数据库_pyqt qsqlquerymodel
- 10Android Canvas绘图描述Android Canvas 方法总结_android canvas 图片放大两倍绘制
目标检测——YOLOv4算法解读
赞
踩
论文:YOLOv4:Optimal Speed and Accuracy of Object Detection
作者:Alexey Bochkovskiy, Chien-Yao Wang, Hong-Yuan Mark Liao
链接:https://arxiv.org/pdf/2004.10934.pdf
代码:https://github.com/AlexeyAB/darknet
YOLO系列其他文章:
1、算法概述
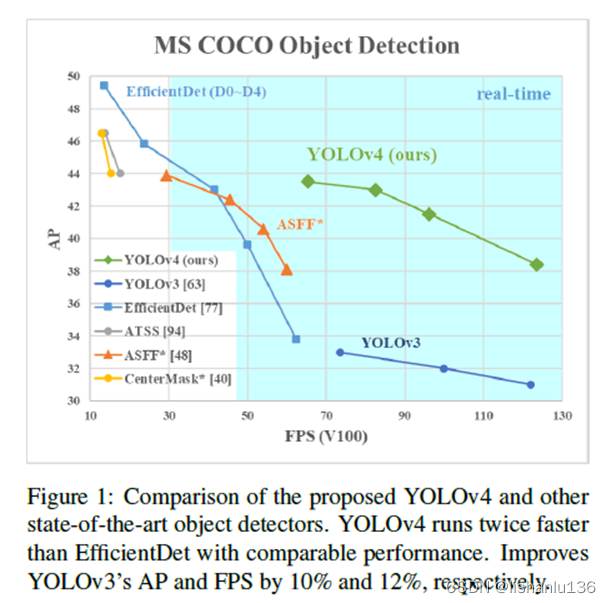
到2020年,有大量的改进手段和优化方式对提升网络精度有帮助,但有些只针对于特定数据集有用,有些改进却是针对所有数据集、所有任务通用的,比如:batch-normalization和残差连接。YOLOv4正是采用这些通用特征如:带权重的残差连接(Weighted-Residual-Connections, WRC),跨阶段部分连接(Cross-Stage-Partial-connections, CSP),跨小批量归一化(Cross mini-Batch Normalization, CmBN)、自我对抗训练(Self-adversarial-training, SAT),Mish激活函数,马赛克数据增强(Mosaic data augmentation),DropBlock regularization和CIoU损失函数,结合这一系列改进措施在Tesla V100显卡上实现了在MS COCO数据集上43.5%AP(65.7% AP50)的性能,并且推理速度为65FPS。相比YOLOv3在AP指标上有了非常大的提升。如图:
YOLOv4的主要贡献如下:
1、构建了一个简单高效的目标检测算法,降低了训练门槛,可以使用1080Ti或2080Ti GPU就能训练起来;
2、验证了直到本算法提出之前的最先进的Bag-of-Freebies和Bag-of-Specials方法的有效性。
3、修改了最先进的方法,使其更有效,更适合单GPU训练,包括CBN,PAN,SAM等。
在这之前先解释一下Bag-of-Freebies和Bag-of-Specials
- Bag-of-Freebies:按照字面翻译是免费包的意思,指通过开发更好的训练策略或只增加训练成本的方法,使目标检测器在不增加推理成本的情况下获得更好的精度。目标检测方法中经常采用的符合免费包定义的是数据增强,有图像几何变换(随机缩放,裁剪,旋转),Cutmix,Mosaic等;网络正则化:Dropout,Dropblock等;损失函数的设计:比如边界框回归的损失函数改进CIoU。
- Bag-of-Specials:指那些只增加少量推理成本,却能显著提高目标检测精度的插件模块和后处理方法,作者称之为“特品包”。一般来说,这些插件模块是为了增强模型中的某些属性,如扩大接受野SPP、ASPP等;引入注意机制SE、SAM模块;增强特征集成能力PAN、BiFPN;激活函数的改进Swish、Mish等;后处理方法改进如soft NMS、DIoU NMS对模型预测结果进行筛选。
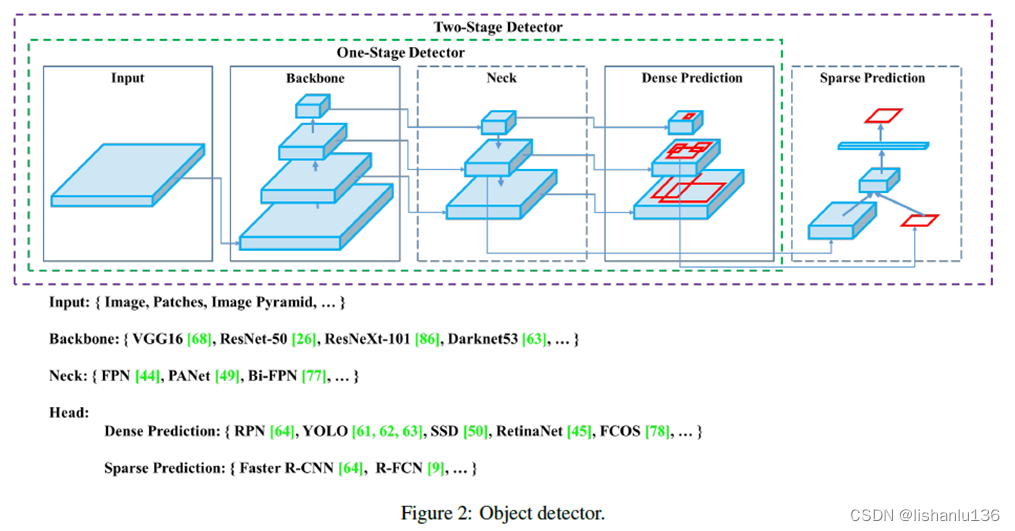
其次作者总结了现如今检测算法的网络结构,给一阶段算法(比如YOLO, SSD, RetinaNet等)和二阶段算法(比如R-CNN系列)画了统一的网络结构图,很有参考意义,如下所示:
2、YOLOv4细节
2.1 Selection of architecture

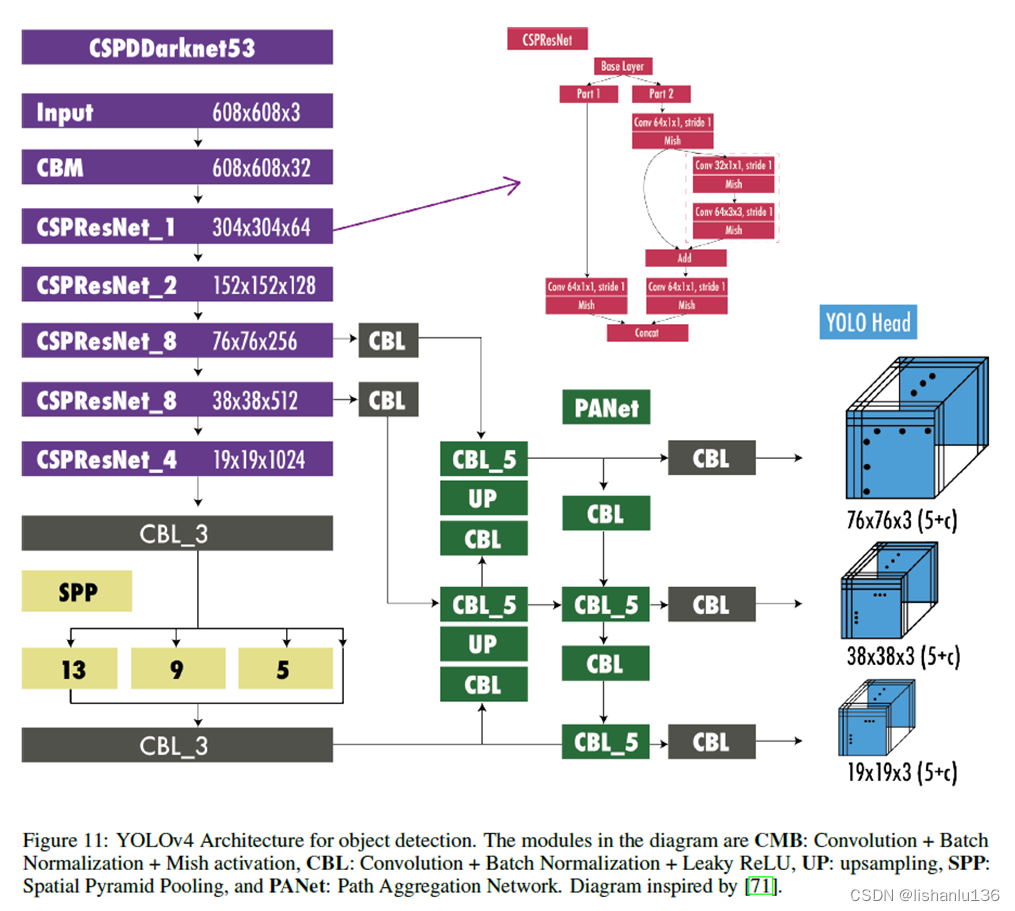
虽然CSPResNext50分类性能比CSPDarknet53要好,但对于检测任务而言,后者比前者表现更好;对于感受野而言,CSPDarknet53虽然没有EfficientNet-B3大,但比后者推理速度快3倍左右。综合来看,作者最后选择了CSPDarknet53[1]作为主干网络,在主干最后加上SPP[2]扩大感受野,通过PAN[3]增强特征融合再接上YOLOv3[4]的检测头最后得到YOLOv4。其完整结构如下图[5]所示:
2.2 Mosaic data augmentation
马赛克数据增强是将4张图片合成一张图片,相对于CutMix只是混合了两张图片,这可以使得网络一次性在一张图片上见到更多的信息,也使得可以设置小的batchsize,从而使得单张显卡一次迭代可以见到之前4倍batchsize数量的图片信息。

2.3 Self-Adversarial Training (SAT)
自我对抗训练也代表了一种新的数据增强技术,可以在两个前向后向传播阶段操作。在第一阶段,神经网络改变原始图像,不改变网络权重。通过这种方式,神经网络对自己进行对抗性攻击,改变原始图像以制造图像上没有期望对象的欺骗。在第二阶段,训练神经网络以正常方式检测修改后的图像上的物体。
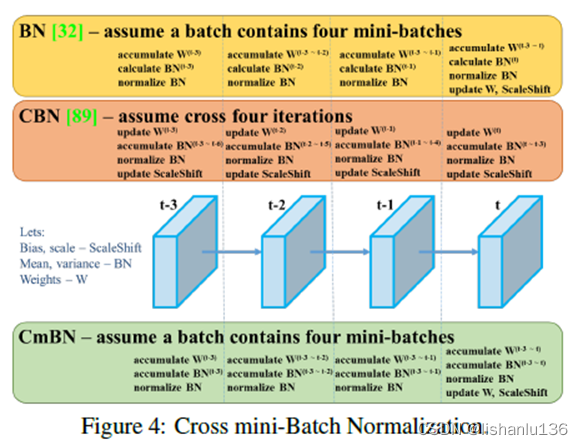
2.4 CmBN
CmBN是CBN[6]修改后的版本,全称为Cross mini-Batch Normalization(CmBN)。BN是对当前mini-batch进行归一化。CBN是对当前以及当前往前数3个mini-batch的结果进行归一化,而CmBN则是仅仅在这个Batch中进行累积。如下图所示:
2.5 修改SAM和PAN结构
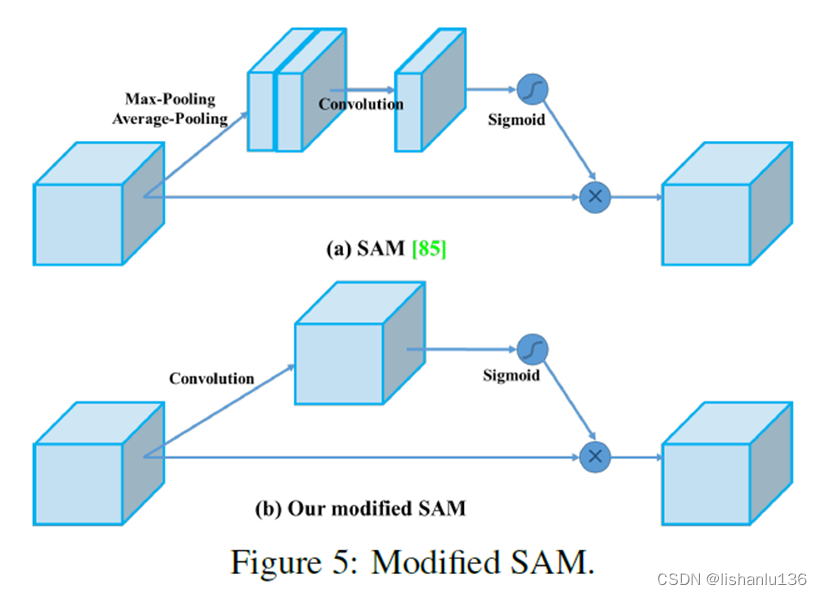

2.6 使用的BoF和BoS
- Backbone使用的BoF:CutMix和Mosaic数据增强,DropBlock正则化,类别标签平滑(Class label smoothing)
- Backbone使用的BoS:Mish激活函数,CSP连接,多输入加权残差连接(Multi-input weighted residual connections, MiWRC)
- Detector使用的BoF:CIoU-loss,CmBN,DropBlock正则化,Mosaic数据增强,自对抗训练,消除网格敏感性(参考https://github.com/ultralytics/yolov3),一个gt框匹配多个anchor,余弦退火学习策略(Cosine annealing scheduler),采用遗传算法选择最优超参数,随机训练尺寸
- Detector使用的BoS:Mish激活函数,SPP模块,SAM模块,PAN模块,DIoU-NMS
3、实验
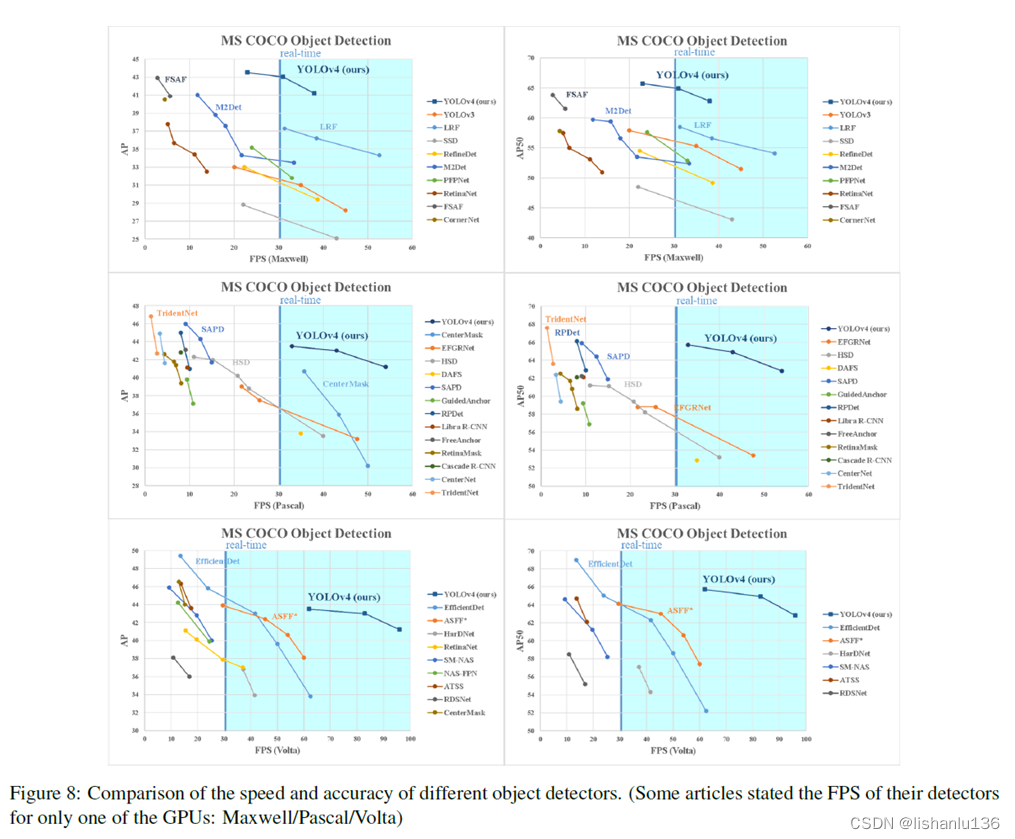
作者在ImageNet(ILSVRC 2012 val)数据集上做分类测试,在MS COCO(test-dev 2017)数据集上做检测测试。分类数据集主要用于前期的数据增强消融实验,检测数据集用于评估检测指标。如下图所示,是YOLOv4与当前最新水平的检测算法对比结果
参考文献:
[1] Chien-Yao Wang, Hong-Yuan Mark Liao, Yueh-Hua Wu, Ping-Yang Chen, Jun-Wei Hsieh, and I-Hau Yeh. CSPNet: A new backbone that can enhance learning capability of cnn. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshop (CVPR Workshop),2020.2,7
[2] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun.Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 37(9):1904–1916, 2015. 2, 4, 7
[3] Shu Liu, Lu Qi, Haifang Qin, Jianping Shi, and Jiaya Jia. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 8759–8768, 2018.1, 2, 7
[4] Joseph Redmon and Ali Farhadi. YOLOv3: An incremental improvement. arXiv preprint arXiv:1804.02767, 2018. 2, 4, 7, 11
[5] Terven J, Cordova-Esparza D. A comprehensive review of YOLO: From YOLOv1 and beyond. arXiv 2023[J]. arXiv preprint arXiv:2304.00501
[6] Zhuliang Yao, Yue Cao, Shuxin Zheng, Gao Huang, and Stephen Lin. Cross-iteration batch normalization. arXiv preprint arXiv:2002.05712, 2020.1,6

