
- 1在shell脚本中创建动态变量,并引用存储在动态变量中的值_shell 动态变量
- 2vue2.0 -- 打包后打开为空白页::::_vue2.0打包后页面空白
- 3如何在win10设置gcc编辑器环境变量_gcc添加环境变量
- 4HBuilderX安卓离线打包教程全一览——5+app_hbuilderx离线打包
- 5java 实现蓝桥杯模拟空地长草 DFS_蓝桥杯:长草 dfs
- 6【web安全】——XXE漏洞快速入门_web常见漏洞之xxe(靶场篇)-阿里云开发者社区
- 7C++类-构造函数的重载_c++构造函数重载
- 8Mac版Jmeter安装与使用&模拟分布式环境
- 9中专学计算机可以考清华吗,职高能考清华吗 职高怎么考清华
- 10LeetCode.21. 合并两个有序链表_本题要求实现一个合并两个有序链表的简单函数mergelists,函数参数list1和list2是
MySQL到PolarDB-X数据迁移和同步_mysql 迁移polodb
赞
踩
简述
CloudCanal 近期支持了 PolarDB-X 对端, 目前开放的链路为 MySQL 到 PolarDB-X 。
本链路特点包括
- 完整支持结构迁移、全量迁移、增量同步、数据校验
- 支持 PolarDB-X 云版本 API 级对接(自动获取实例、添加白名单)
- 支持 PolarDB-X 开源自建版
PolarDB-X 前身 DRDS (内部产品名称 TDDL),经过 10 几年发展, 很好解决了 ToC 端业务对数据库超高并发、严苛事务的需求,并且近几年也努力尝试解决企业级数据需求(复杂SQL、分布式事务、在线数据的实时计算),而这样的一个产品,目前有云版本,同时近期也进行了开源。所以我们认为有必要对其生态做良好支撑。
技术点
结构迁移
PolarDB-X 是分布式数据库领域产品,所以存在 partition 概念 ,提供了两种拆分模型:sharding(即分库分表)和partitioning。 前者按用户自定义拆分,后者对应用透明。可以通过类似 create database d1 partition_mode="sharding" 或create database d1 partition_mode="partitioning" 指定。
sharding模式下,具体创建语句和算法可参考 官方文档
对于响应时间、RPS 要求的严苛应用场景(相对较窄),设定业务感知的分库分表算法是合理的,这也是为何很多分布式数据库在类似 sysbench 或 tpcc 或 天猫双十一 场景中达到难以置信性能的朴素原理。
CloudCanal 目前自动创建 database 为 sharding 模型,并且通过产品化方式支持这个能力-选择相应的算法和字段。
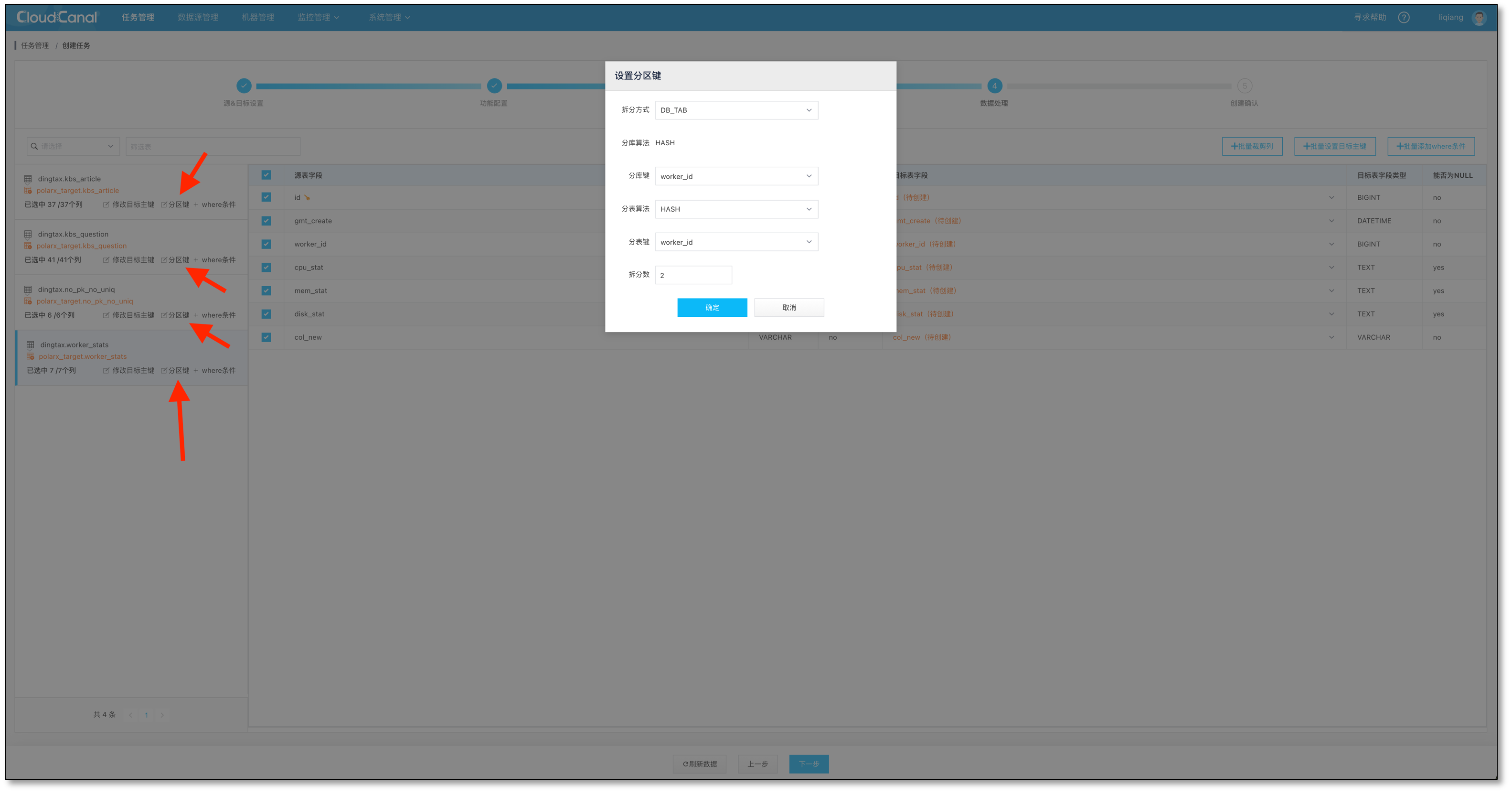
目前支持分库分表类型包括
- DB(只分库不分表)
- DB_TAB(既分库又分表)
- NONE(单表)
设定分库分表字段的时候,支持的算法包括
- HASH
- WEEK
- MM
- DD
- MMDD
一张普通的表,如果应用 DB_TAB 分库分表类型,并且选择常用的 HASH 算法,字段都选择worker_id, 经过 CloudCanal 结构迁移,会在 PolarDB-X 中生成如下表
CREATE TABLE `worker_stats` (
`id` bigint(20) NOT NULL AUTO_INCREMENT BY GROUP,
`gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`worker_id` bigint(20) NOT NULL,
`cpu_stat` text,
`mem_stat` text,
`disk_stat` text,
`col_new` varchar(255) NOT NULL DEFAULT '123',
PRIMARY KEY (`id`),
KEY `auto_shard_key_worker_id` USING BTREE (`worker_id`)
) ENGINE = InnoDB AUTO_INCREMENT = 278489 DEFAULT CHARSET = utf8mb4 DEFAULT COLLATE = utf8mb4_0900_ai_ci dbpartition by hash(`worker_id`) tbpartition by hash(`worker_id`) tbpartitions 4
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
任务对分库分表的处理
与普通单机数据库不同, 如果需要达到 PolarDB-X 最好的写入性能, 增量同步需要处理分库分表字段,对于 update 和 delete 操作, 带上拆分字段。数据校验进行对端数据获取时,也需要带上拆分字段,并且保证数据的获取效率。
if (col.isKey() || (partitionKeys != null && partitionKeys.contains(col.getName()))) {
if (col.isUpdated()) {
// put before column in it , PK/UKs may be change.
pkCols.add(SqlUtilCommon.pickBeforeColumn(rowData, col.getName()));
} else {
pkCols.add(col);
}
if (firstPk) {
where.append("`").append(col.getName()).append("`= ?");
firstPk = false;
} else {
where.append(" AND `").append(col.getName()).append("`= ?");
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
另外,如同变更主键,如果变更拆分字段值, 目前 PolarDB-X 能够自行处理这种变化,无需用户自己删除老数据,插入新数据。
举个例子
前置条件:
- CloudCanal 社区版部署完毕,参见CloudCanal社区版安装文档
- PolarDB-X 开源版已经安装,参见PolarDB-X 集群部署文档
- 带有增量流量的 MySQL 运行中
造数据
- 混合负载,IUD 比例 2:7:1


添加数据源
- 登录 CloudCanal 平台
- 数据源管理->新增数据源
- 分别选择 自建 部署模式下的 PolarDB-X 和 MySQL 并添加

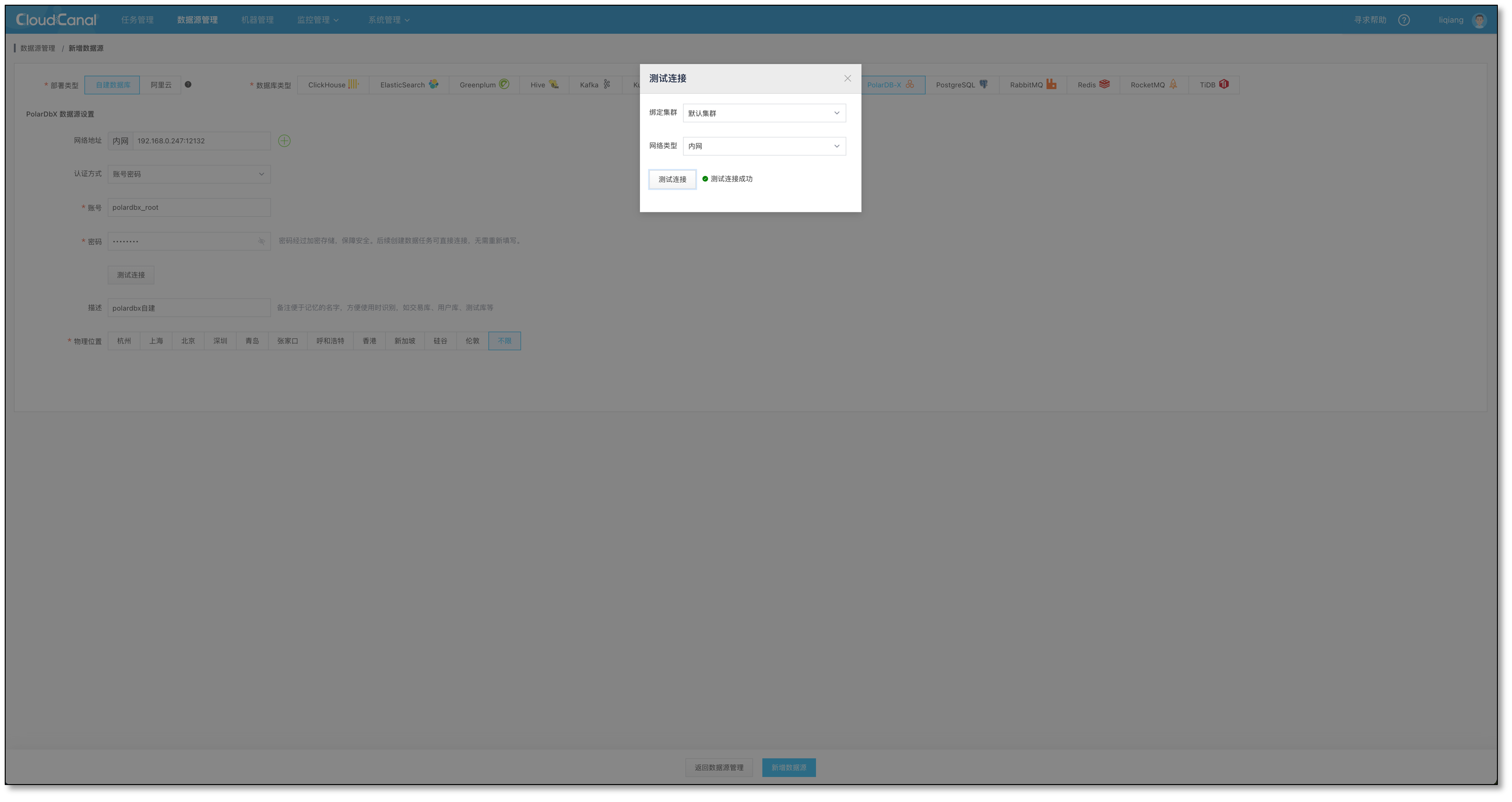
任务创建
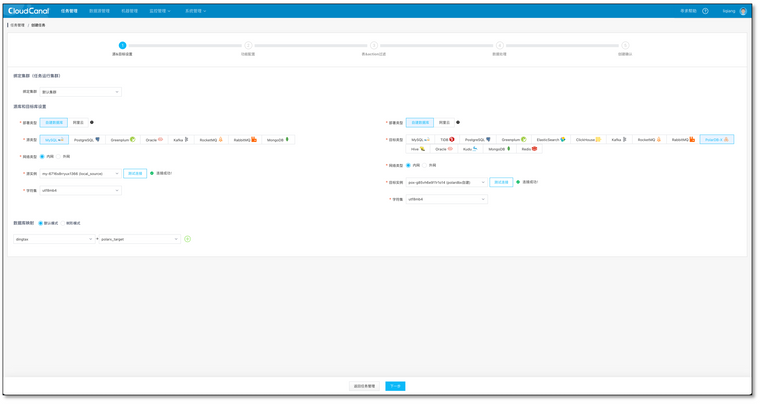
- 任务管理->任务创建
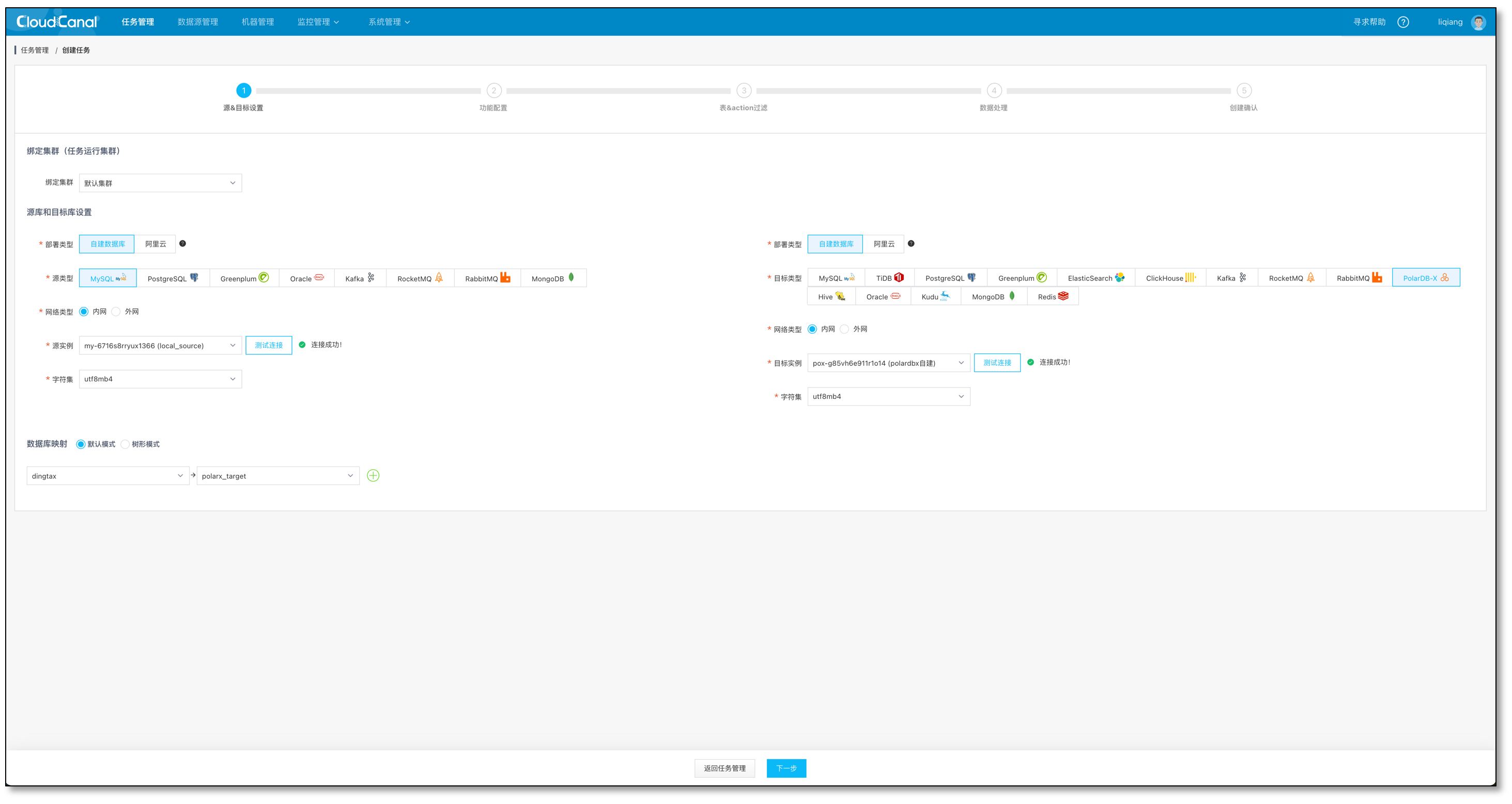
- 选择源和目标数据源
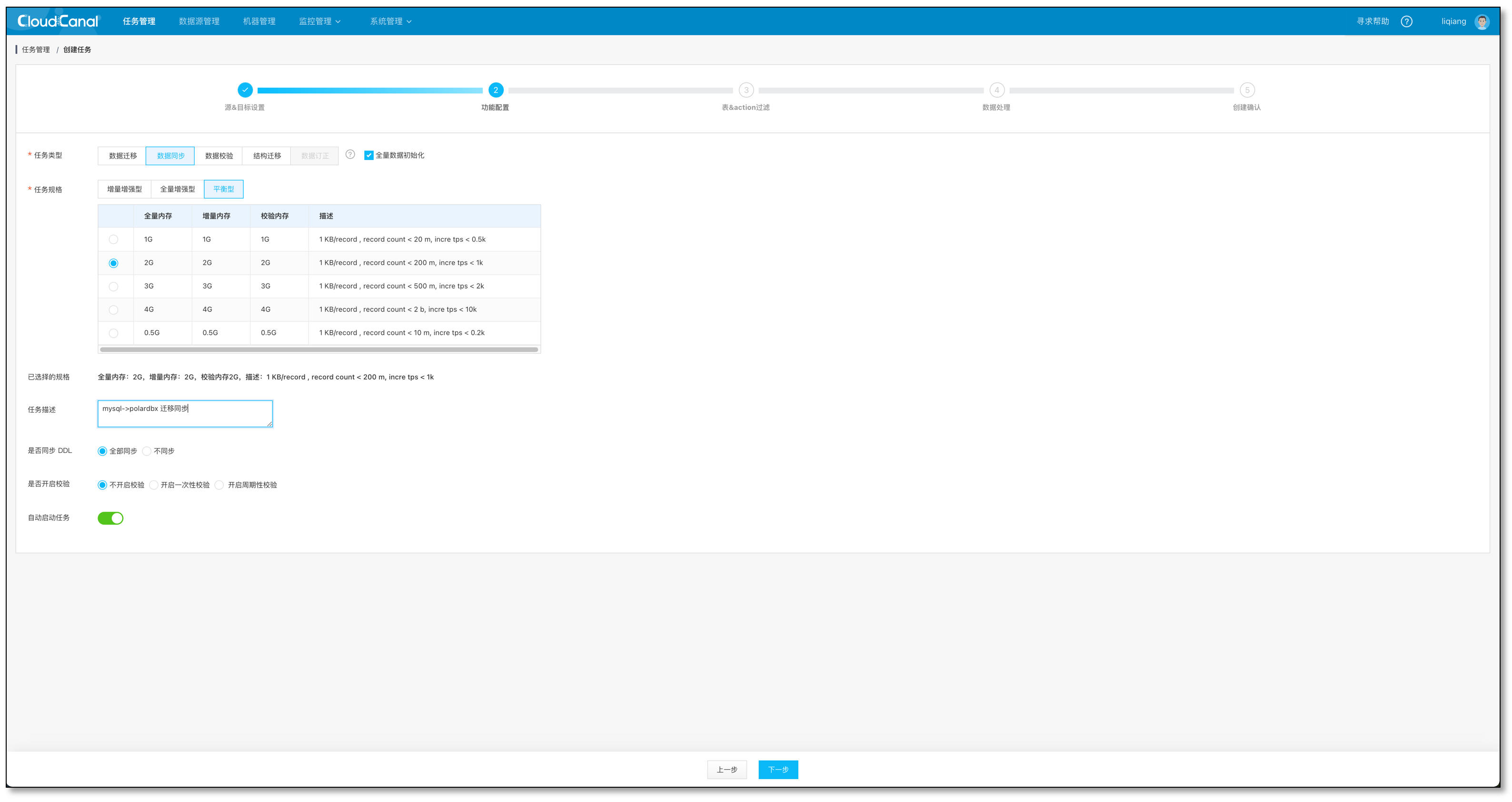
- 选择数据同步,并勾选 全量数据初始化, 其他选项默认
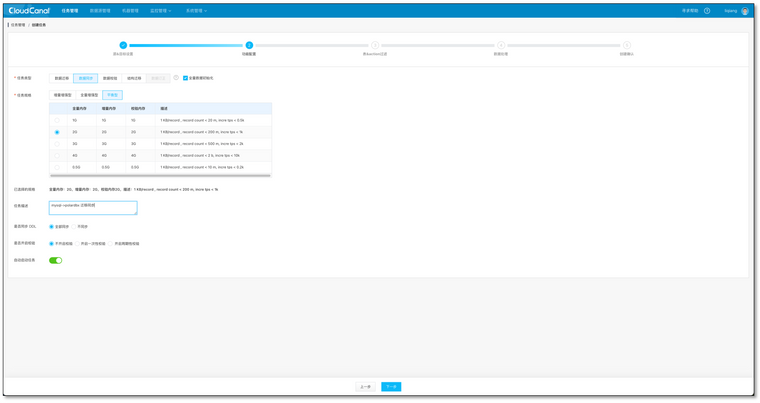
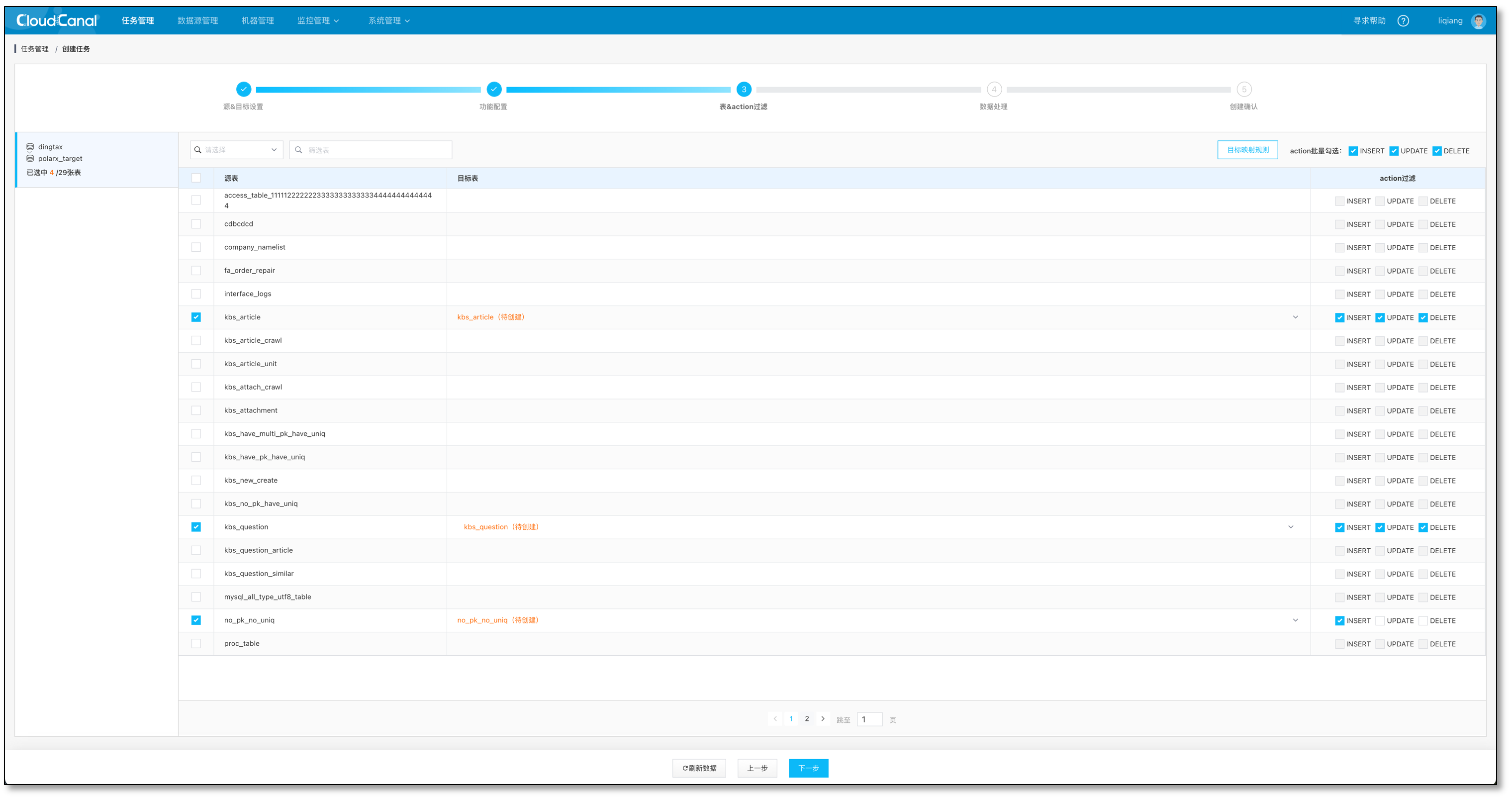
- 选择需要迁移同步的表

- 选择列,默认全选
- 设定分库分表算法和字段
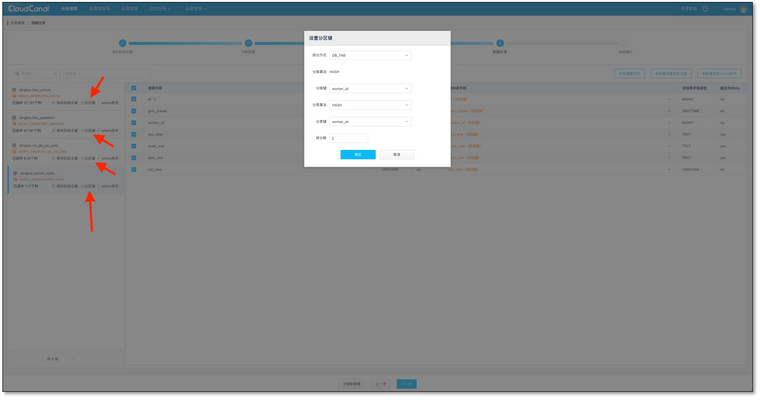
- 确认创建,并自动运行
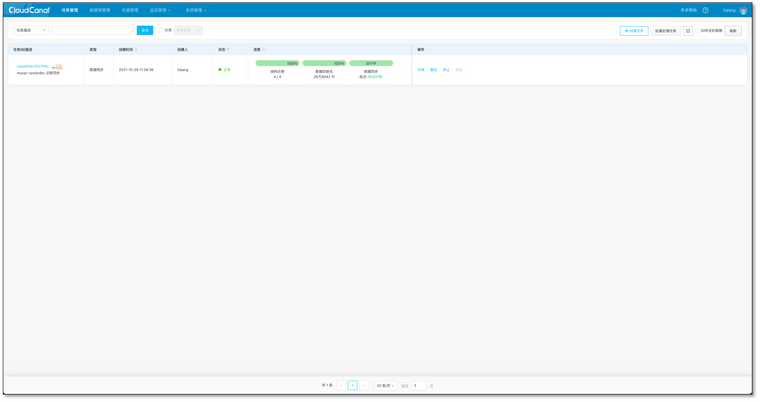
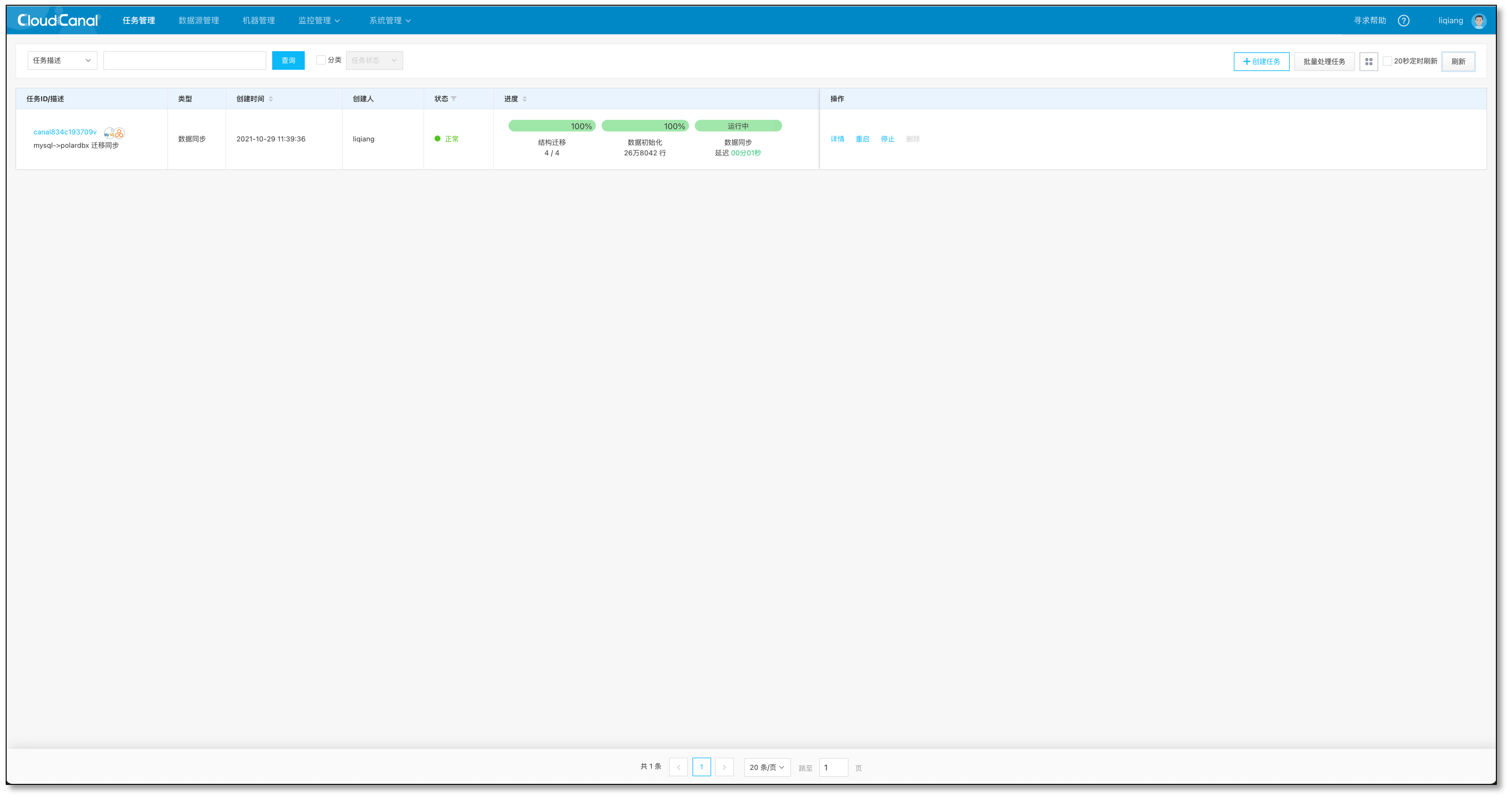
校验任务
- 停止增量负载
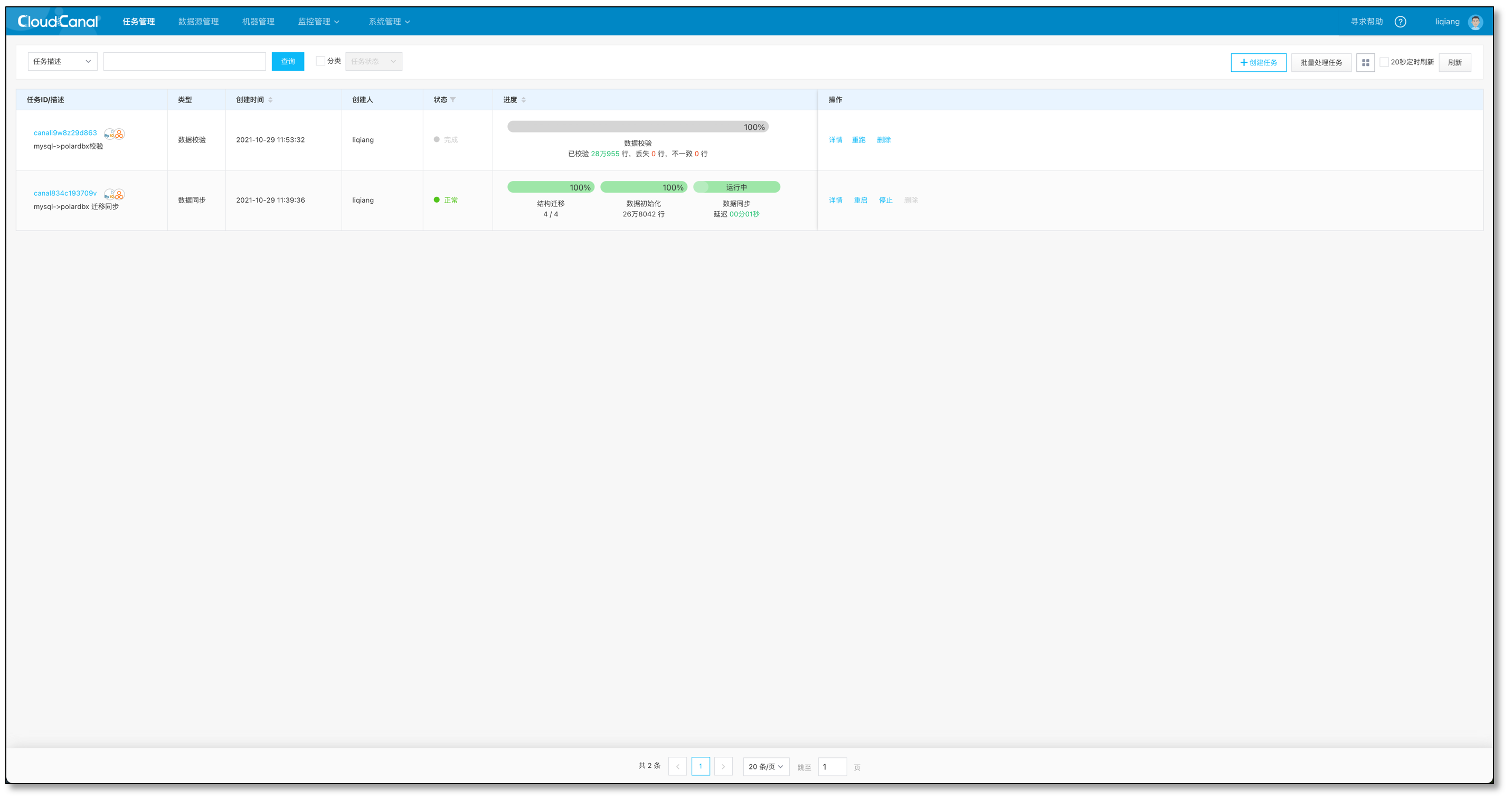
- 创建校验任务
- 目前类似任务创建开发中,暂时库表列选择和拆分选择请和同步任务保持一致
- 校验完毕数据一致
FAQ
是否会支持 PolarDB-X 源端?
目前 PolarDB-X 版本支持 CDC , 和 MySQL binlog 交互很相似(外在表现出些许差别),我们将在不久推出 PolarDB-X 源端,目标端仍首选 MySQL (让业务有去有回)。
是否会支持更多源端?
CloudCanal 新增数据源之后,后续相互打通相对简单,目前 Oracle 是首选源端。之后 PostgreSQL、SqlServer(开发中)都是候选。
目前这条链路还存在什么不足?
功能层面目前自动创建数据库未支持 PolarDB-X 的 partitioning 模式,另外已存在表,无法感知对端分库分表字段(急需修复)。性能层面则需要更多调优。
总结
本文简单介绍了使用 CloudCanal 进行 MySQL 到 PolarDB-X 的数据迁移同步。各位小伙伴,如果觉得还不错,请点赞、评论加转发吧。
更多精彩
- 异地多活基础之数据双向同步进阶篇-CloudCanal实战
- 5分钟搞定 MySQL 到 ClickHouse 实时数据同步进阶篇-CloudCanal实战
- 主流关系型数据库到 Kudu 实时数据同步-CloudCanal实战
- 5分钟搞定 MySQL 到 ElasticSearch 迁移同步-CloudCanal 实战
- 5分钟搞定 MySQL 到 MySQL 异构在线数据迁移同步-CloudCanal 实战
- MySQL 到 ElasticSearch 实时同步构建数据检索服务的选型与思考
- 构建基于Kafka中转的混合云在线数据生态-cloudcanal实战
- 5分钟搞定 MySQL 到 TiDB 的数据同步 - CloudCanal实战
社区快讯
- 我们创建 CloudCanal 微信粉丝群啦,在里面,你可以得到最新版本发布信息和资源链接,你能看到其他用户一手评测、使用情况,你更能得到热情的问题解答,当然你还可以给我们提需求和问题。快快加入吧。
- 扫描下方二维码,添加我们小助手微信拉您进群,接头语(“加CloudCanal交流群”)

- 扫描下方二维码,添加我们小助手微信拉您进群,接头语(“加CloudCanal交流群”)


