
- 1python中时间戳(epoch)和日期的相互转换_extract(epoch from repeat_end_time) * 1000
- 2计算并输出给定正整数n的所有因子(不包括1和自身)之和_计算并输出给定整数n的所有因子(不包括1与自身)之和
- 3EMQX+PolarDB-X构建一站式物联网数据解决方案_emqx 怎么做物联
- 4GPU计算能力远超CPU!NVIDIA Tesla技术深入解析
- 5深度学习:卷积神经网络CNN变体_卷积神经网络cnn的变体
- 6【Vuejs】1345- 封装几个有用的 Vue3 组合式API
- 7【深度学习】纯干货之如何使用pytorch训练自己的数据(一)_pytorch训练自己的数据集
- 8FatTree胖树拓扑结构_fattree拓扑结构
- 9第三十三篇:Win8.1中USB xHCI驱动的符号列表_usbxhclsys
- 10Android studio在线调用华为HarmonyOS系统虚拟机_android studio 模拟器华为
十六、数据变换和数据离散化_数据泛化是数据变换策略嘛
赞
踩
1.数据归约的概念
数据变换的概念和数据离散化
在数据预处理过程中,不同的数据适合不同的数据挖掘算。数据变换是一种将原始数据变换成较好数据格式的方法,以便作为数据处理前特定数据挖掘算法的输入。
- 数据离散化是一种数据变换形式。
- 数据变换策略概述
- 通过规范化变换数据-
- 通过分箱离散化
- 通过直方图分析离散化
- 通过聚类、决策树和相关分析离散化
- 标称数据的概念分层产生
2 数据变换策略概述
在数据变换中,数据被变换或统一成适合于挖掘的形式。数据变换策略包括如下几种:
- 光滑(smoothing):去掉数据中的噪声。这类技术包括分箱、回归和聚类。
- 属性构造:可以由给定的属性构造新的属性并添加到属性集中,以帮助挖掘过程。
- 聚集:对数据进行汇总或聚集。例如,可以聚集日销售数据,计算月和年销售量。。
- 规范化:把属性数据按比例缩放,使之落入一个特定的小区间,如0.0~1.0。
- 离散化:数值属性(例如,年龄)的原始值用区间标签(例如,0~10,11~20等)。
- 由标称数据产生概念分层:属性,如street,可以泛化到较高的概念层,如city或country。
3 通过规范化变数据
3.1 最小-最大规范化:对原始数据进行线性变换
令minA和maxA表示属性A的最小值和最大值,最小—最大值标准化将值vi映射为vi’(范围是[new_minA, new_maxA]:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GA9NM4Do-1583973479287)(01.png)]](https://img-blog.csdnimg.cn/20200312084123252.png)
最小—最大值标准化保留了原有数据值的关系。如果后来的输入的标准化的数据落在了原有数据区间的外面,将会发生过界的错误。
3.2 最小-最大规范化:例子
假定收入属性的最小值和最大值分别是$12,000和$98,000. 将收入属性映射到范围[0.0, 1.0]上。则一个值为$73,600的收入标准化为。
3.3 z-分数标准化
属性A的值,基于平均值和标准差来标准化。计算公式:
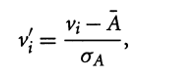
其中A¯和σA是属性A的均值和标准差。这种方法在实际的最小值和最大值未知时很有用,或者离群点主导了最小—最大值的标准化。
3.2.4 z-分数标准化——例子*
假定income属性的均值和标准差是$54,000和$16,000。使用z-分数标准化,则$73,600被转换为: 。
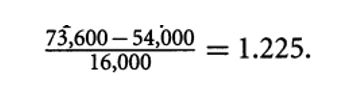
4 数据离散化
4.1 通过分箱离散化
分箱并不使用类信息,因此是一种非监督的离散化技术,对用户制定的箱个数很敏感,也容易受离群点的影响。
4.2 通过直方图分箱离散化
直方图分析也是一种非监督离散化技术,因为它不使用类信息。
4.3 通过聚类、决策树和相关分析离散化
聚类将数据划分成簇或组;离散化的决策树方法是监督的,它们使用了类标号(分类)。
5. 标称数据的概念分层产生
5.1 标称数据的数据变化
现在,我们考察标称数据的数据变换。特别地,我们研究标称属性的概念分层产生。标称属性具有有穷多个不同值(但可能很多),值之间无序。例如地理位置、工作类别和商品类型。
1、对于用户和领域专家而言,人工定义概念分层是一项乏味和耗时的任务。幸运的是,许多分层结构都隐藏在数据库的模式中,并且可以在模式定义级自动地定义。
2、概念分层可以用来把数据变换到多个粒度层。例如,关于销售的数据挖掘模式除了在单个分店挖掘之外,还可以针对指定的地区或国家挖掘。
5.2 根据每个属性的不同值个数产生概念分层
假设用户从数据库中选择了一个关于location的属性集country(15), province_or_state(365),city(3567), street(674339),但没有指出这些属性之间的分层次序。


