

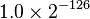 ,它与绝对值次小的规约浮点数之间的距离为
,它与绝对值次小的规约浮点数之间的距离为 。如果不采用渐进式下溢出,那么绝对值最小的规约浮点数与0的距离是相邻的小浮点数之间距离的
。如果不采用渐进式下溢出,那么绝对值最小的规约浮点数与0的距离是相邻的小浮点数之间距离的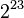 倍!可以说是非常突然的下溢出到0。这种情况的一种糟糕后果是:两个不等的小浮点数X与Y相减,结果将是0.训练有素的数值分析人员可能会适应这种限制情况,但对于普通的程序员就很容易陷入错误了。采用了渐进式下溢出后将不会出现这种情况。例如对于单精度浮点数,指数部分实际最小值是(-126),对应的尾数部分从
倍!可以说是非常突然的下溢出到0。这种情况的一种糟糕后果是:两个不等的小浮点数X与Y相减,结果将是0.训练有素的数值分析人员可能会适应这种限制情况,但对于普通的程序员就很容易陷入错误了。采用了渐进式下溢出后将不会出现这种情况。例如对于单精度浮点数,指数部分实际最小值是(-126),对应的尾数部分从 ,
, 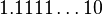 一直到
一直到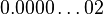 ,
,  ,相邻两小浮点数之间的距离(gap)都是
,相邻两小浮点数之间的距离(gap)都是 并且尾数的
并且尾数的 到
到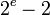
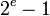
《C++标准转换运算符dynamic_cast》http://www.cnblogs.com/ider/archive/2011/08/01/2123298.html
《C++标准转换运算符static_cast 》http://www.cnblogs.com/ider/archive/2011/07/31/2122385.html
《C++标准转换运算符reinterpret_cast》http://www.cnblogs.com/ider/archive/2011/07/30/2121953.html

