
- 1Could not initialize class org.gradle.internal.classloader.FilteringClassLoader求助
- 22022牛客多校3补题_e.pushu_back({a,b})
- 3AnimateDiff搭配Stable diffution制作AI视频_animatediff csdn
- 4计算机系统基础 第二章_计算机系统基础逻辑运算
- 5linux mount命令_mount remount
- 6解决CUDA driver version is insufficient for CUDA runtime version
- 7Hive SQL必刷练习题:连续问题 & 间断连续(*****)
- 8Android Gradle 7.x新版本的依赖结构变化_android gradle7 工程下的allprojects选项已经被移植到settings.gr
- 9EMQX+PolarDB-X构建一站式物联网数据解决方案_emqx 怎么做物联
- 10GAN及其衍生网络中生成器和判别器常见的十大激活函数(2024最新整理)
万能分割神器——Segment Anything(Meta AI)图片和影像的万能分割_seganything
赞
踩
想必大家之前都做过抠图或者图片任务提取等任务,这有点想目前我们手机当中可以直接点击图片,然后将其复制到其它地方,就会自动出现这个任务图像一样。这里我们可以直接登录这个网站去尝试一下这个图像分割的魅力Segment Anything | Meta AI
这里面是官方的展示,这里我们需要选择添加分割的区域来实现影像分割, 或者使用其它左侧工具栏中的盒子工具以及自动的everything,就是自动识别的结果。
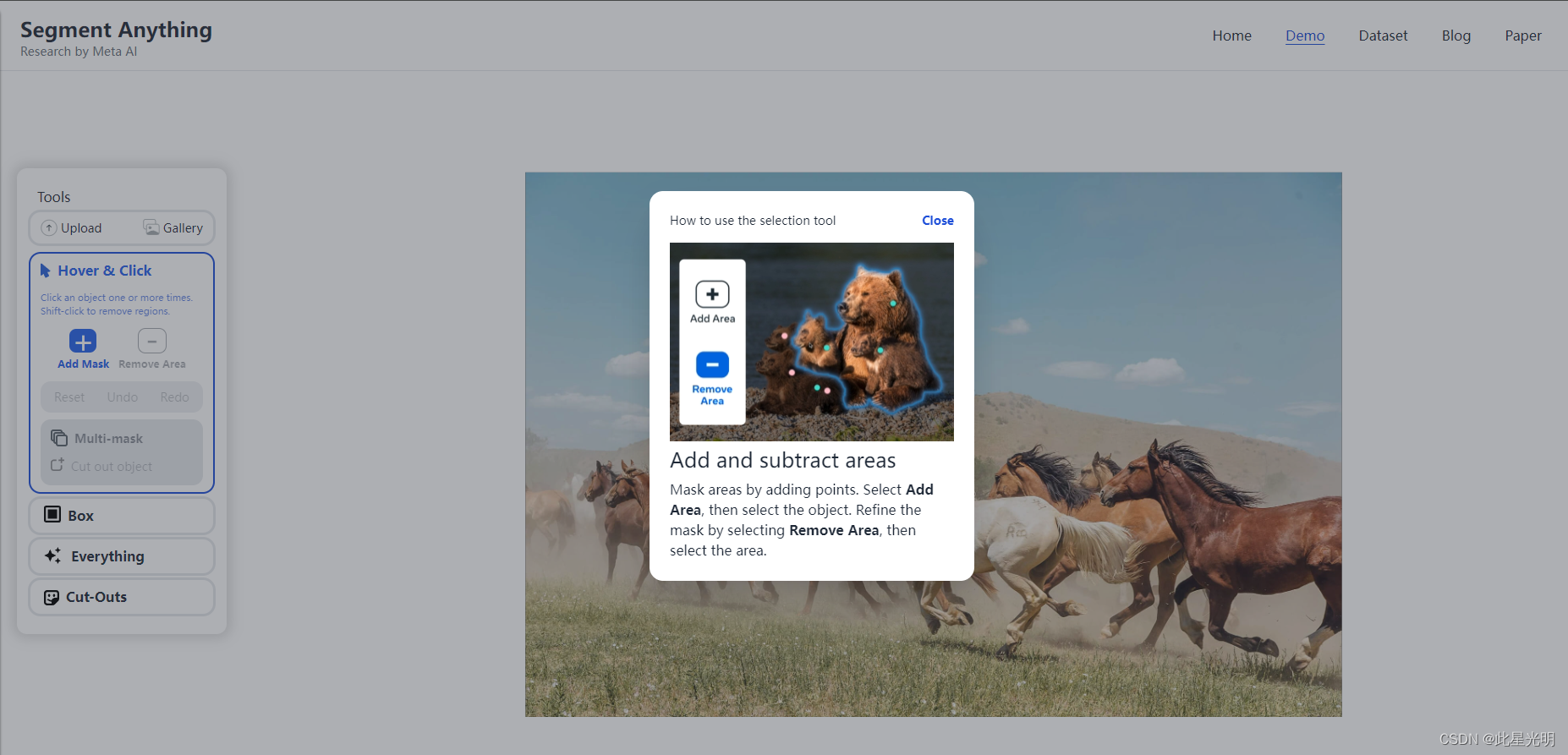 添加和减去区域
添加和减去区域
通过添加点来屏蔽区域。选择添加区域,然后选择对象。选择 "删除区域",然后选择区域,细化遮罩。
我们直接采用全自动分割来提取影像的结果

这里我们也可以通过上传我们自己的影像来进行影像提取,但是这里并不能将分割后的影像copy出来,所以这里的问题就在于如果你需要进行其它影像格式,除了图片格式外,以及如何导出所提取的矢量文件都需要利用代码来进行实现。
简介
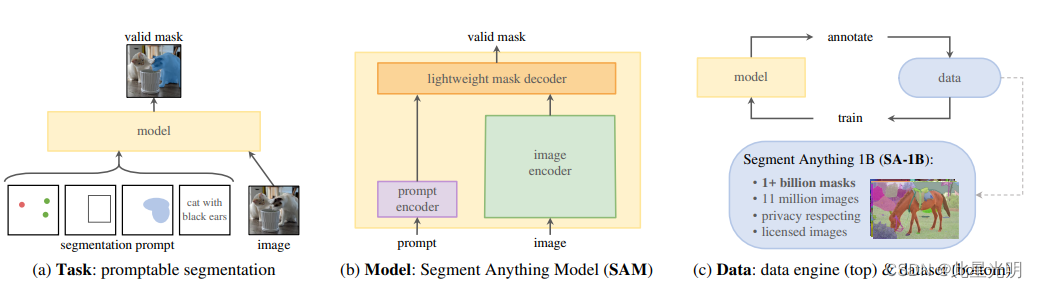
Segment Anything Model (SAM):Meta AI 公司推出的新型人工智能模型,只需点击一下,就能在任何图像中 "切出 "任何物体。SAM 是一个可提示的分割系统,对不熟悉的物体和图像进行零点泛化,无需额外训练即可进行分割。
Segment Anything (SA) 项目:一个用于图像分割的新任务、模型和数据集。通过在数据收集循环中使用我们的高效模型,我们建立了迄今为止最大的分割数据集(迄今为止),其中包含 1100 万张授权图像上的 10 亿多个掩码,并且尊重隐私。该模型的设计和训练具有可提示性,因此它可以在新的图像分布和任务中进行零转移。我们在大量任务中评估了它的能力,发现它的零镜头性能令人印象深刻--通常可与之前的完全监督结果相媲美,甚至更胜一筹。我们在 https URL 上发布了 Segment Anything Model(SAM)和包含 1B 个遮罩和 1,100 万张图像的相应数据集(SA-1B),以促进计算机视觉基础模型的研究。
这里再创建这个模型前有三个假设条件:
1. What task will enable zero-shot generalization?
2. What is the corresponding model architecture?
3. What data can power this task and model?
1. 什么任务能实现零点概括?
2. 相应的模型架构是什么?
3. 哪些数据可以支持这项任务和模型?
模型解析
我们首先将提示的概念从 NLP 转化为分割,提示可以是一组前景/背景点、一个粗略的方框或遮罩、自由形式的文本,或者,一般来说,表明要分割图像中哪些内容的任何信息。图像中要分割的内容。因此,可提示分割任务就是在给出任何提示的情况下,返回一个有效的分割掩码。对 "有效 "掩码的要求简单来说就是,即使提示模棱两可,可能指向多个对象,输出也应该是至少其中一个对象的合理掩码。这一要求类似于期望语言模型能对一大堆提示输出连贯的反应。我们之所以选择这项任务,是因为它带来了一种自然的预训练算法,以及一种通过提示将零镜头转移到下游分割任务的通用方法。

我们新推出的 SA-1B 数据集中带有叠加遮罩的示例图像。SA-1B 包含 1,100 万张不同的 高分辨率、授权和隐私保护图像,以及 1.1B 个高质量分割掩码。这些掩码 由 SAM 全自动标注,我们通过人工评分和大量实验验证了其高质量和多样性。 多样性。为便于可视化,我们按每张图像的掩码数量对图像进行分组(平均每张图像有 100 个掩码)。

预训练和处理
可提示分割任务建议采用 自然的预训练算法,该算法可以为每个训练样本模拟一连串的提示(如点、方框、遮罩 提示(如点、方框、遮罩),并将模型的遮罩预测与实际情况进行比较。地面实况。我们从交互式分割[109, 70]中借鉴了这一方法,但与交互式分割不同的是,交互式分割的目的是在足够多的用户输入后最终预测出有效的掩码。不同的是,交互式分割的目的是在足够多的用户输入后最终预测出一个有效的掩码,而我们的目的是始终预测出一个有效的掩码
我们的目标是,即使提示模棱两可,也能为任何提示预测出有效的掩码。这 这就确保了预训练模型在涉及模糊性的使用案例(包括自动注释)中的有效性。这就确保了预训练模型在涉及模棱两可的用例(包括我们的数据引擎 §4 所要求的自动注释)中的有效性。我们注意到
这项任务具有挑战性,需要专门的建模和训练损失选择。和训练损失的选择,我们将在第 3 节中讨论这一点。
Zero-shot transfer零点转移
直观地说,我们的预训练任务赋予了模型在推理时对任何提示做出适当反应的能力。 任何提示的能力,因此下游任务 可以通过设计适当的提示来解决。例如,如果有一个猫的边界框检测器,就可以通过向我们的模型提供检测器的边界框输出作为提示来解决猫的实例分割问题。一般来说,大量实用的 一般来说,一系列实际的分割任务都可以作为提示任务。除了自动数据集标注,我们还在实验中探索了 在第 7 节的实验中,我们探讨了五种不同的示例任务。
Related tasks相关任务
相关任务。分割是一个广泛的领域:有交互式分割、边缘检测、超级像素化、对象建议生成、前景分割、语义分割、实例分割、全景分割等。我们的可提示分割任务的目标是生成一个具有广泛能力的模型,该模型可以通过提示工程适应许多(尽管不是全部)现有的和新的分割任务。这种能力是任务泛化的一种形式。请注意,这与之前的多任务分割系统工作不同。在多任务系统中,单个模型执行一组固定的任务,例如联合语义分割、实例分割和全视角分割,但训练任务和测试任务是相同的。我们工作中的一个重要区别是,为可提示分割而训练的模型在推理时可以通过作为更大系统中的一个组件来执行不同的新任务,例如,为了执行实例分割,可提示分割模型与现有的物体检测器相结合。
讨论
提示和组合是强大的工具,可以使单一模型以可扩展的方式使用,从而完成模型设计时未知的任务。这种方法类似于其他基础模型的使用方式,例如 CLIP 是 DALL-E 图像生成系统的文本-图像对齐组件。我们预计,与专门针对固定任务集进行训练的系统相比,由提示工程等技术驱动的可组合系统设计将带来更广泛的应用。从合成的角度来比较提示式分割和交互式分割也很有趣 交互式分割模型是以人类用户为中心而设计的,而为可提示分割训练的模型也可以组成一个更大的算法系统。正如我们将演示的那样。
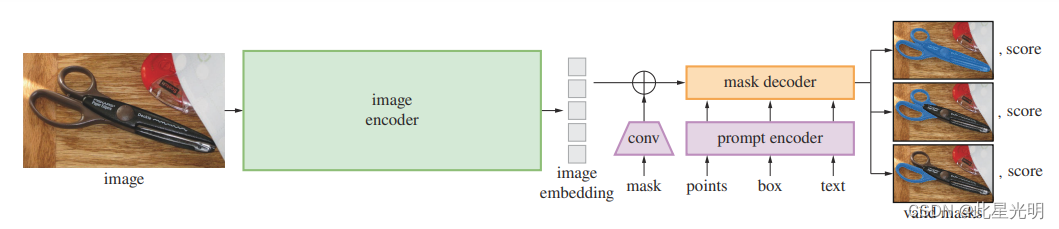
分段模型(SAM)概述。重量级图像编码器输出的图像嵌入可以 然后通过各种输入提示进行高效查询,以摊销后的实时速度生成对象掩码。对于模棱两可的 的提示,SAM 可以输出多个有效的掩码和相关的置信度分数。
接下来,我们将介绍用于可提示分割的 "任意分割模型"(SAM)。SAM 由三个部分组成,分别是图像编码器、灵活的提示编码器和快速掩码解码器。我们以 Transformervision 模型为基础,对实时性能(摊销)进行了具体权衡。在此,我们将对这些组件进行高层次的描述,详情请参见第 A 节。
Image encoder图像编码器
图像编码器。在可扩展性和强大的预训练方法的激励下,我们使用 MAE 预训练的视觉变换器(Vision 变换器 (ViT)。输入。图像编码器每张图像运行一次 图像编码器每张图像运行一次,可在提示模型之前应用。
Prompt encoder提示编码器
提示编码器 我们考虑了两组提示:稀疏(点、方框、文本)和密集(掩码)。我们用位置编码 点和方框的位置编码与 我们使用 CLIP 的现成文本编码器对每种提示类型和自由格式文本进行位置编码。密集 提示(即掩码)使用卷积嵌入,并与图像 与图像嵌入元素相加。
Resolving ambiguity模糊性问题解决
解决模糊问题。该模型只有一个输出,如果给出一个模棱两可的提示,它就会平均预测出多个有效掩码。为了解决这个问题,我们修改了模型,以预测单个提示下的多个输出掩码(见图 3)。 我们发现3 个掩码输出足以应对大多数常见情况 (嵌套掩码通常最多有三种深度:整体、部分和 子部分)。在训练过程中,我们只对最小的损失。为了对掩码进行排序,模型会预测每个掩码的置信度得分(即估计 IoU)。
Efficiency效率
整体模型设计的主要动机是给定一个预先计算好的图像嵌入 提示编码器和掩码解码器在网络浏览器中运行,CPU运行时间为 50 毫秒。这种运行性能使我们的模型能够实现无缝、实时的交互式提示。
Losses and training损失和训练
损失和训练 我们使用 "焦点损失 "和 "骰子损失 "的线性组合对掩码预测进行监督。 我们使用几何提示(文本提示见第 7.5 节)的混合物来训练romptable分割任务。按照文献[92, 37],我们模拟了交互式设置,在每个掩码中随机抽取 11 轮提示,使 SAM 可以无缝集成到我们的数据引擎中。
由于互联网上的分割掩码并不丰富,我们建立了一个数据引擎,以便收集我们的 1.1B 掩膜数据集 SA-1B。数据引擎分为三个 阶段:(1) 模型辅助人工标注阶段,(2)半自动阶段,包括自动预测的掩码和模型辅助的 掩码和模型辅助注释相结合的半自动阶段,以及(3)全自动阶段,在这一阶段中,我们的模型无需注释输入即可生成掩码。 注释器输入。构建的数据库阶段整体上处于三个步骤第一个就是全手动收集,第二个半自动,第三个就是全自动数据收集。下面这张图是利用不同模型进行的分析。

 BSDS500 上零点边缘预测的其他可视化效果。回想一下,SAM 并未接受过预测边缘图的训练,在训练过程中也无法获得 BSDS 图像和注释。边缘图,并且在训练期间无法访问 BSDS 图像和注释。与 ViTDet 相比,SAM 能生成更高质量的遮罩。模型,SAM 没有机会学习特定的训练数据偏差。做出了模态预测,而 LVIS 中的地面实况则是模态的,因为 LVIS 中的掩码注释没有漏洞。
BSDS500 上零点边缘预测的其他可视化效果。回想一下,SAM 并未接受过预测边缘图的训练,在训练过程中也无法获得 BSDS 图像和注释。边缘图,并且在训练期间无法访问 BSDS 图像和注释。与 ViTDet 相比,SAM 能生成更高质量的遮罩。模型,SAM 没有机会学习特定的训练数据偏差。做出了模态预测,而 LVIS 中的地面实况则是模态的,因为 LVIS 中的掩码注释没有漏洞。

