- 1【HarmonyOS NEXT】Base64Helper解码后中文乱码
- 2python研究生志愿填报辅助系统flask-django-php-nodejs
- 3CentOS7网络配置——nmcli命令集
- 4时序预测 | MATLAB实现贝叶斯优化CNN-LSTM时间序列预测(股票价格预测)_贝叶斯时间序列分析用于股票市场波动性预测
- 5Java 技术栈_java 简历需要的技术栈
- 6stable-diffusion-webui一些问题记录
- 7记录 | ubuntu使用防火墙报错sudo: firewall-cmd:找不到命令_firewall-cmd linux 未找到命令
- 8iOS 微信、支付宝、银联支付组件的进一步设计_ios开发 微信支付宝支付
- 9[uni-app]微信小程序隐私保护指引设置的处理记录_openprivacycontract直接跳转到微信指引
- 10掌握AI写作工具:引领内容创作潮流
计算机体系结构----指令级并行的开发(五)--基于编译器_vliw 需要的寄存器数量
赞
踩
本文严禁转载,仅供学习使用。参考资料来自中国科学院大学计算机体系结构课程PPT以及《Digital Design and Computer Architecture》、《超标量处理器设计》、同济大学张晨曦教授资料。如有侵权,联系本人修改。
开发指令级并行的方法很多,除了硬件机制外,编译器也承担了相当一部分工作。我们将编译器所使用的指令级并行开发方法称做“软件方法”。与硬件方法相比,由于编译时能够“虚拟”出一个很大的指令窗口,软件方法有潜力开发出更多的指令级并行。但是,缺乏必要的运行时的信息(如寄存器的值、访存指令的延迟、分支转移的方向等)又使得软件方法的实际效果大打折扣,因此软件方法通常需要与一定的硬件机制结合在一起使用。
5.1 基本指令调度和循环展开
5.1.1 指令调度的基本方法
为了充分发挥流水线的作用,必须设法让它满负荷地工作,这就要求充分开发指令之间存在的并行性,找出不相关的指令序列,让它们在流水线上重叠并行执行,这一工作就是指令调度。本小节讨论这种通过编译器来开发指令级并行的方法。
编译器完成指令调度的能力受限于两个特性:①程序固有的指令级并行: ②流水线功能部件的执行延迟。在本节中,假设浮点流水线的延迟如表 6.1 所示。
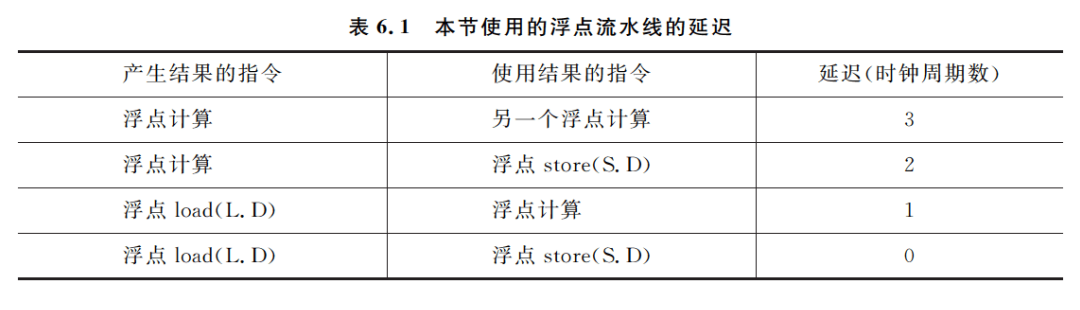
需要说明的是,由于浮点 load 指令的结果可以通过定向路径及时地送给浮点 store 指令,所以延迟为 0(就是不用插入停顿)。与以前一样,仍假设是采用本系列博文计算机体系结构----流水线技术(三)中的 5 段整数流水线,分支的延迟和整数 load 指令的延迟都是一个时钟周期,并假设整数运算部件是全流水的或者重复设置了足够多的份数,因而每个时钟周期都能流出一条整数指令。
下面通过一个实例对指令调度进行研究和性能分析。
例 6.1 对于下面的源代码,转换成 MIPS 汇编语言,在不进行指令调度和进行指令调度两种情况下,分析其代码一次循环所需的执行时间。
for (i=1000; i>0; i--)
x[i] = x[i] + s;
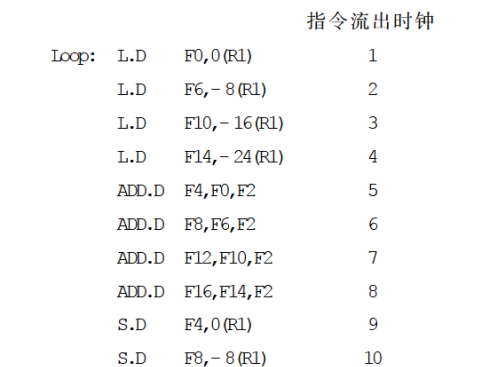
- 1
- 2

其中,整数寄存器 R1 用于指向向量中的当前元素,其初值指向第一个元素,8(R2)指向最后一个元素,浮点寄存器 F2 用于保存常数 s。
在不进行指令调度的情况下,根据表 6.1 中给出的浮点流水线中指令执行的延迟,程序的实际执行情况如下。
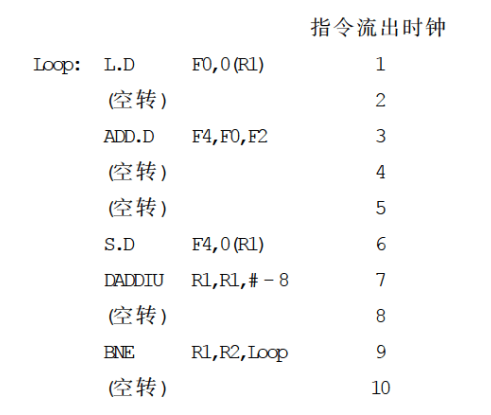
可以看出,每完成一个元素的操作需要 10 个时钟周期,其中有 5 个是空转周期。在用编译器对上述程序进行指令调度以后,程序的执行情况如下。
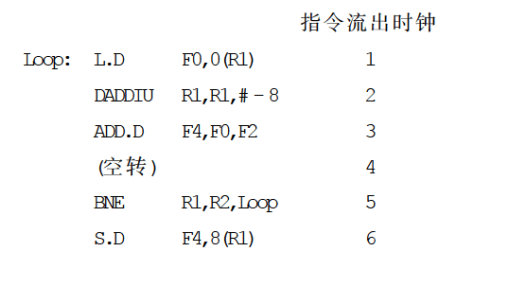
这里,把 DADDIU指令调度到了 L.D 指令和 ADD.D 指令之间的“空转”拍。把 S.D指放到了分支指令的延迟槽中。由于修改指针的 DADDIU 指令被调度到了 S.D 指令之前提前对指针进行了减 8 的操作,所以要对 S.D 指令中的偏移量进行修正,即把“0(R1)”改为“8(R1)”。
经过这样的指令调度后,一个元素的操作时间从 10 个时钟周期减少到了 6 个时钟周期,其中 5 个周期是有指令执行的,只剩下一个空转周期。
从这个例子可以看出,编译时指令调度并不会真正消除指令间的相关,而是通过重新安排指令的流出顺序(如 DADDIU、S.D 指令),使得指令间的相关尽可能少地引起流水线空转,从而减少整个指令序列在流水线上的执行时间。另一个需要注意的地方是,按照本小节个绍的基本指令调度方法,指令调度不能跨越分支指令,本例中 S.D 指令被调度到 BNE 指令的分支延迟槽中,不属于跨越分支指令的情况。
进一步分析上面的例子可以发现,虽然对一个元素的操作时间从 10 个时钟周期减少到了 6 个时钟周期,但是其中只有 L.D、ADD.D 和 S.D 这三条指令是我们需要的有效操作。占用三个时钟周期,而 DADDIU、空转和 BEN 这三个时钟周期都是为了控制循环和解决数据相关等待而附加的,因此整个执行过程中有效操作的比例并不高。这是因为每个循环迭代中只有 5 条指令,进行指令调度的余地很小,必须想办法增加每个循环迭代中的指令数循环展开(Loop Unrolling)就是解决这一问题的有效方法之一。
5.1.2 循环展开(Loop Unrolling)
在前面讲过,增加指令间并行性最简单和最常用的方法,是开发循环级并行性(LoopLevel Parallelism,LLP)—循环的不同迭代之间存在的并行性。所谓循环展开(LoopUnrolling)就是指把循环体的代码复制多次并按顺序排放,然后相应地调整循环的结束条件。通过循环展开,多个循环迭代的代码可以合到一起调度,给编译器进行指令调度带来了更大的空间,而且还能够消除中间的分支指令和循环控制指令引起的开销。通过下面的例子,可以更清楚地看到循环展开技术所带来的好处。
例 6.2 将上述例子中的循环展开 3 次得到 4 个循环体,然后对展开后的指令序列在不调度和调度两种情况下,分析代码的性能。假定 R1的初值为 32 的倍数,即循环次数为4的倍数。消除冗余的指令,并且不要重复使用寄存器。


这里把展开后的前三个循环体中的 DADDIU 指令删除了,并对 L.D 指令中的偏移量进行了相应的修正。对最后留下的 DADDIU 指令中的立即数也进行了相应的调整。这个循环每遍共使用了 28 个时钟周期,有 4 个循环体,完成 4 个元素的操作,平均每个元素使用 28/4=7个时钟周期。与原代码的每个元素需要 10 个时钟周期相比较。节省了不少的时间。这主要是从减少循环控制的开销中获得的。但是在展开后的循环体中,实际指令只有 14条.其他 13 个周期都只是空转,可见效率并不高。下面对指令序列进行优化调度,以减少空转周期。

这个循环由于没有数据相关引起的空转等待,整个循环仅仅使用了 14 个时钟周期,平均每个元素使用 14/4=3.5 个时钟周期。
从上述例子中可以知道,通过循环展开、寄存器重命名(注:使用多个寄存器来消除名称依赖name dependence)和指令调度,可以有效地开发出指令级并行。
循环展开和指令调度时要注意以下几个方面:
(1) 保证正确性。在循环展开和调度过程中尤其要注意两个地方的正确性:循环控制,操作数偏移量的修改。
(2) 注意有效性。只有找到不同循环体之间的无关性,才能够有效地使用循环展开。
(3) 使用不同的寄存器。如果使用相同的寄存器,或者使用较少数量的寄存器,就可能导致新的冲突。
(4) 删除多余的测试指令和分支指令,并对循环结束代码和新的循环体代码进行相应的修正。
(5) 注意对存储器数据的相关性进行分析。例如,对于 load 指令和 store 指令,如果它们在不同的循环迭代中访问的存储器地址是不同的,它们就是相互独立的,可以相互对调。
(6) 注意新的相关性。由于原循环不同次的迭代在展开后都到了同一次循环体中,因此可能带来新的相关性。
循环展开更详细的叙述和与静态超标量流水线结合的知识在这篇博文计算机体系结构补充篇----静态超标量流水线及循环展开(一)
5.2 静态多指令流出:VLIW(Very Long Instruction Word)技术
超标量处理器在运行时动态确定指令窗口中哪些指令可以被流出执行(或者叫发射issue),为此它必须准确识别出指令窗口内的指令以及流水线上的所有指令之间存在哪些相关。在动态调度的超标量处理器中,这些工作基本都是由硬件完成的。而在静态调度的超标量处理器中,部分相关检测和指令调度工作交由编译器完成,大大降低了硬件实现的复杂度。
与超标量处理器不同,VLIW(超长指令字)处理器在编译时静态确定哪些指令能够同时流出。进一步降低了流水线硬件的实现复杂度,这有助于提高它的主频。VLIW 能够把后时流出的或者满足特定约束的一组操作打包在一起,得到一条更长(64 位、128 位或更长)的指令,这就是 VLIW 名字的由来。每个操作被放在 VLIW 指令的一个(slot)内。VLIW处理器执行这样一条长指令就相当于超标量处理器同时执行多条指令,从而实现了多流出由于所有开发指令级并行的任务都交由编译器完成,VLIW 处理器需要更加“智能”的编译器。
只有从应用程序中挖掘出足够多的并行指令打包到 VLIW 指令中,才能提高 VLIW 处理器中功能单元的利用率,充分发挥 VLIW 处理器的性能优势。使用 5.1 节介绍的基本指令调度和循环展开技术(该技术本章前面介绍了)以及全局指令调度技术(该技术本博文为介绍)都能够有效识别哪些指令可以并行执行。下面通过一个例子来看看 VLIW 技术的效果。
例 6.3 假设某 VLIW 处理器每个时钟周期可以同时流出 5 个操作,包括 2 个访存操作,2 个浮点操作以及 1 个整数或分支操作。将例 6.1 中的代码循环展开,并调度到该VLIW 处理器上执行。循环展开次数不定,但至少要能够保证消除所有流水线“空转”周期,同时不考虑分支延迟。
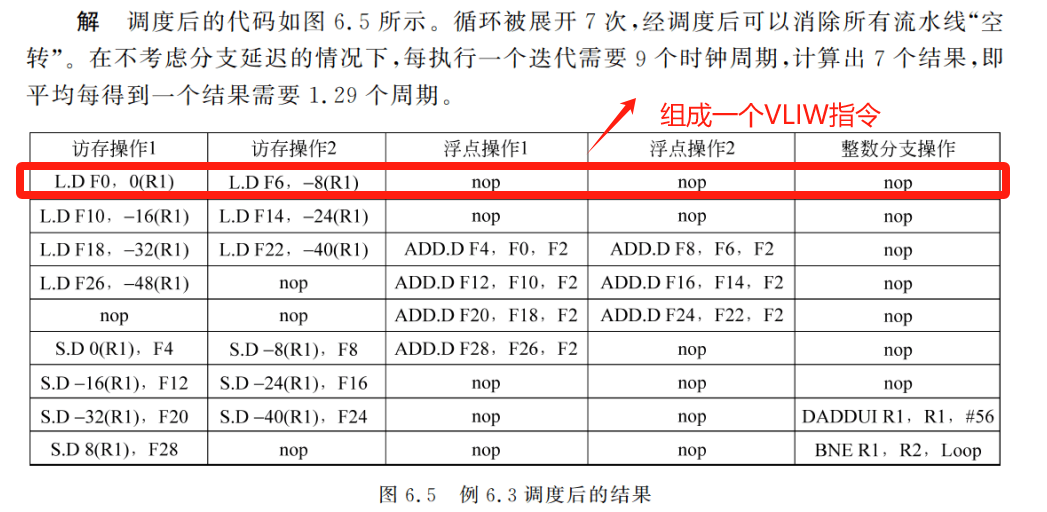
如图 6.5 所示的代码中含有 9 条指令,最多可容纳 45 个操作,但实际上只包含 23 个操作,其余 22 个均为空操作(nop)(注:nop 即是 no option),编码效率仅比 50%略高一些,可见 VLIW 处理器目标代码的体积比超标量的大得多。此外,与单流出 MIPS 处理器相比,在 VLIW 处理器上执行这段代码所需要的寄存器数量也大大增加—本例中需要至少 8 个浮点寄存器,而例 6.1和例 6.2 中在 MIPS 处理器上循环展开前仅需要 2 个浮点寄存器。即使循环展开后.也只需要5个。这就是说,尽管 VLIW 处理器不像超标量处理器那样需要复杂的硬件指令流出逻辑,但它必须提供更加丰富的资源,用以消除指令间 RAW 和 WAW 类型的数据相关。
造成 VLIW 目标代码编码效率低的原因主要有两个:①为了消除流水线“空转”需要增加循环展开的次数,如例 6.3 中循环被展开了 7 次,而例 6.2 中只需展开 5 次即可,这增加了目标代码的体积;②很难从应用程序中找到足够多的并行指令填满 VLIW 指令中的每一个槽,如例 6.3 中的空操作接近半数,实际应用中还经常会出现一条 VLIW 指令中所有操作都是 nop 的情况。使用代码压缩/还原技术可以减少 VLIW 目标代码体积过大带来的性能损失:VLIW 目标代码被压缩后保存在硬盘中,只保留指令中非 nop 操作的信息;程序运行时,当代码被加载到指令 Cache 或译码时再将其解压缩,还原出所含的 nop 操作。
为了简化硬件实现,很多 VLIW 处理器中没有实现任何相关检测逻辑,而是靠互锁机制保证执行结果的正确。当一个功能单元暂停时,互锁机制将暂停整个流水线,从而保证所有功能单元的同步。使用互锁机制的主要原因是一些操作的延迟在编译时无法确定,比如load 操作,由于编译时无法确定它访问 Cache 是否命中,因而无法确定其延迟。出于性能上的考虑,编译时通常会假定这类操作的延迟为可能的最小值,如 load 操作的延迟是 Cache的命中时间。这样,若运行时访问 Cache 不命中,互锁机制将暂停整个流水线,直至 load 操作完成。当 VLIW 指令中含有较多数量的操作槽且应用程序中的访存操作较多时,这种简单的互锁机制将造成较大的开销。现有的一些高性能 VLIW 处理器通常采用软硬件结合的方式解决这一问题:编译器负责保证同时流出的操作间没有相关,而流水线硬件则负责确保正在运行的指令在不满足上述同步约束的情况下也能得到正确的执行结果。
目标代码兼容性差是 VLIW 的另一个严重缺陷,极大地制约了 VLIW 的推广与应用VLIW 的指令格式与操作类型、功能单元的数量以及延迟等体系结构参数密切相关,当这些参数发生变化时,VLIW 的指令格式也将相应地发生变化。(注:这个缺点导致VLIW指令在不同的机器上要重新编译才能运行)要在同一系列不同代的处理器之间实现目标代码兼容,VLIW 比超标量困难得多。二进制翻译或仿真是解决 VLIW 目标代码兼容问题的可行方法之一。二进制翻译(Binary Translation)是指将某个硬件平台的二进制目标代码翻译为另一个平台的目标代码的过程,是目前在不同平台之间实现目标代码兼容的主要手段之一。借助这种技术,可以在一个平台上执行另一个平台的应用程序,如在 MIPS 上执行 x86 应用程序。二进制翻译可以在编译时静态完成,也可以在运行时动态完成。是目前计算系统虚拟化研究的主要内容之一。
如何开发出大量的指令级并行仍然是所有多流出处理器面临的最大挑战。对于一个浮点应用程序而言,如果通过简单的循环展开能够开发出足够多的指令级并行,那么该应用程序在向量处理器上也极有可能高效地运行。虽然目前尚不清楚这些应用程序在多流出处理器上的性能是否一定优于在向量处理器上的性能,但可以肯定的是:与向量处理器相比,多流出处理器至少具有以下两个优势。①即使对于一些结构不规则的代码,多流出处理器也能从中挖掘出一些指令级并行;②多流出处理器对存储系统没有过高的要求,价格较便宜由 Cache 和主存构成的多层次存储子系统即可满足其对性能的要求。正因为如此,多流出处理器已成为当前实现指令级并行的主要选择,而向量处理器则通常作为协处理器集成到计算机系统中,以加速特定类型的应用程序。
5.3 软流水(Sofrware Pipelining)
前面介绍的循环展开是通过扩大基本块的体积来开发更多的指令级并行。本小节将讨论另一种比较常用的循环优化技术—软流水。
软流水(Software Pipelining)技术的核心思想是从循环的不同迭代中抽取一部分指令(循环控制指令除外)拼成一个新的循环迭代。以便将同一迭代中的相关指令分布到不同的迭代中,或将不同迭代中的相关指令封装到同一迭代中。之所以不考虑循环控制指令,是因为在软流水处理之前和之后的循环中都需要这些指令对整个循环的控制流进行处理。
软流水的工作原理如图 6.6 所示,其中阴影部分表示得到的新迭代,它包含了原循环迭代 0~4 中的指令,执行这个新的迭代就同时执行了原循环中的迭代 0~4,只不过每个迭代只有一部分指令被执行,而且各不相同,或者说每个迭代处于不同的执行阶段,就像在图 3.17 中的 5 级流水线中同时执行的 5 条指令一样。这项技术构造了一条虚拟的“流水线”,它以流水的方式同时执行循环中的多个不同迭代,这就是“软流水”这一名称的由来与硬件流水线一样,这条软件“流水线”也需要一定时间才能充满(或排空),但与硬件流水线不同的是,用于充满(或排空)软件“流水线”的指令无法被封装到任何一个新的迭代中,只能放在新循环之前(或之后)。