
- 1CoverDesignAI——快速生成图书封面和Midjourney提示词_ai专辑封面提示词
- 2chatglm常用参数 :Top-k, Top-p, Temperature_chatglm temperature
- 3用通俗易懂的方式讲解:大模型微调方法总结_大模型怎么用问答对去微调
- 4关于在winform中使用chart一些总结_winform chart
- 5Kernel Log
- 6vue使用axios发送post请求(data为json格式)_前端axios post请求json格式入参
- 7Android-gradle配置详解_gradle unittests.returndefaultvalues
- 8使用opencv 进行图像美化_opencv窗口美化
- 9Zookeeper_nn2 active
- 10统计学——几种常见的假设检验_假设检验类型
李宏毅——终身学习lifelong learning_lifelong learning的例子
赞
踩
导读
人从小大大用同一个脑袋学习
但每个作业都训练同一个神经网络
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-di6RM4AY-1569768951050)(evernotecid://C7EDAE3B-B0B5-43D7-9120-9EA71A1AFF71/appyinxiangcom/23815745/ENResource/p83)]](https://img-blog.csdnimg.cn/20190929225725691.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3NoYW95dWUxMjM0,size_16,color_FFFFFF,t_70)
为什么不用同一个网络学习不同的任务呢?
终身学习的不同称呼
LLL(life long learning)
continuous learning
never ending learning
incremental learning
可以做不同的任务
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3t4lJvqA-1569768951050)(evernotecid://C7EDAE3B-B0B5-43D7-9120-9EA71A1AFF71/appyinxiangcom/23815745/ENResource/p84)]](https://img-blog.csdnimg.cn/20190929225738806.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3NoYW95dWUxMjM0,size_16,color_FFFFFF,t_70)
要解决的问题
1、学过的旧东西记下来,但要能学新的
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SBmpE8Tg-1569768951051)(evernotecid://C7EDAE3B-B0B5-43D7-9120-9EA71A1AFF71/appyinxiangcom/23815745/ENResource/p85)]](https://img-blog.csdnimg.cn/20190929225756224.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3NoYW95dWUxMjM0,size_16,color_FFFFFF,t_70)
例子:手写数字辨识
在一个三层的网络中学习第一个有噪音的任务,在任务1学到的东西可以用在任务2上。任务1的正确率甚至没有任务2高,这个可以视为迁移学习。
让机器学任务2后,任务2的准确率更高,但是任务1的准确率下降
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MST77xk1-1569768951051)(evernotecid://C7EDAE3B-B0B5-43D7-9120-9EA71A1AFF71/appyinxiangcom/23815745/ENResource/p93)]](https://img-blog.csdnimg.cn/20190929225819783.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3NoYW95dWUxMjM0,size_16,color_FFFFFF,t_70)
是否是因为网络过于简单?不是的,因为同时学任务1和任务2,能够学的比较好
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sxFuzjEx-1569768951051)(evernotecid://C7EDAE3B-B0B5-43D7-9120-9EA71A1AFF71/appyinxiangcom/23815745/ENResource/p94)]](https://img-blog.csdnimg.cn/20190929225834860.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3NoYW95dWUxMjM0,size_16,color_FFFFFF,t_70)
例子:问答系统。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YrtmBVvM-1569768951051)(evernotecid://C7EDAE3B-B0B5-43D7-9120-9EA71A1AFF71/appyinxiangcom/23815745/ENResource/p95)]](https://img-blog.csdnimg.cn/20190929225919849.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3NoYW95dWUxMjM0,size_16,color_FFFFFF,t_70)
机器学习的训练资料是:文章、问题、答案
bAbi训练集有20种不同的题型
机器从第一个任务开始学习,学到第20个。
看机器对题型5的回答,只有刚学完题型5时正确率比较高。
对于其他题型也是这样的。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vfjMjME8-1569768951052)(evernotecid://C7EDAE3B-B0B5-43D7-9120-9EA71A1AFF71/appyinxiangcom/23815745/ENResource/p96)]](https://img-blog.csdnimg.cn/20190929225941575.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3NoYW95dWUxMjM0,size_16,color_FFFFFF,t_70)
如果同时学20个任务的话,正确率还行。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BW0DJ5Yx-1569768951052)(evernotecid://C7EDAE3B-B0B5-43D7-9120-9EA71A1AFF71/appyinxiangcom/23815745/ENResource/p97)]](https://img-blog.csdnimg.cn/20190929225952215.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3NoYW95dWUxMjM0,size_16,color_FFFFFF,t_70)
证明网络有能力学完这些东西,但是没有做到。
这种现象叫做灾难遗忘。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TfLcWmpM-1569768951052)(evernotecid://C7EDAE3B-B0B5-43D7-9120-9EA71A1AFF71/appyinxiangcom/23815745/ENResource/p98)]](https://img-blog.csdnimg.cn/2019092923000150.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3NoYW95dWUxMjM0,size_16,color_FFFFFF,t_70)
如何解决
1、多任务学习
很难实现,要保存所有的旧资料才行,学习可能很久(存储、计算问题)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JetuvK80-1569768951052)(evernotecid://C7EDAE3B-B0B5-43D7-9120-9EA71A1AFF71/appyinxiangcom/23815745/ENResource/p99)]](https://img-blog.csdnimg.cn/20190929230017133.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3NoYW95dWUxMjM0,size_16,color_FFFFFF,t_70)
遗忘问题
Elastic Weight Consolidation(EWC)
基本思想
有一些weight重要,但是有一些不重要;保护重要weight,只调不重要的额。
做法:对于每一个theta,有一个守卫参数b
修改loss,计算当前参数与之前的参数之间的距离。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lLzsO6TB-1569768951053)(evernotecid://C7EDAE3B-B0B5-43D7-9120-9EA71A1AFF71/appyinxiangcom/23815745/ENResource/p100)]](https://img-blog.csdnimg.cn/20190929230054257.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3NoYW95dWUxMjM0,size_16,color_FFFFFF,t_70)
b用来表示保护theta的程度
可以将theta视为一种regularization
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UUNuQ2Ky-1569768951053)(evernotecid://C7EDAE3B-B0B5-43D7-9120-9EA71A1AFF71/appyinxiangcom/23815745/ENResource/p101)]](https://img-blog.csdnimg.cn/20190929230111994.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3NoYW95dWUxMjM0,size_16,color_FFFFFF,t_70)
理解
假设有两个任务,网络有两个参数theta,颜色越深,说明loss越小
学习任务1时,参数从theta0学到thetab,再学习任务2时,继续训练,学习到theta* ,此时任务2的loss变小,但是任务2的变大
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5DUrfgD9-1569768951053)(evernotecid://C7EDAE3B-B0B5-43D7-9120-9EA71A1AFF71/appyinxiangcom/23815745/ENResource/p103)]](https://img-blog.csdnimg.cn/20190929230128655.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3NoYW95dWUxMjM0,size_16,color_FFFFFF,t_70)
在EWC中,可以使用某种方法算重要性,比如算微分,theta1比较小,也就是说在theta1上,改变参数,对结果影响不大,b1可以设为比较小的值,但是theta2微分比较大,b2设置的比较大
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iviLl9xC-1569768951054)(evernotecid://C7EDAE3B-B0B5-43D7-9120-9EA71A1AFF71/appyinxiangcom/23815745/ENResource/p105)]](https://img-blog.csdnimg.cn/2019092923014922.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3NoYW95dWUxMjM0,size_16,color_FFFFFF,t_70)
移动时,尽量不要动theta2
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Syd1dwTf-1569768951054)(evernotecid://C7EDAE3B-B0B5-43D7-9120-9EA71A1AFF71/appyinxiangcom/23815745/ENResource/p106)]](https://img-blog.csdnimg.cn/20190929230211742.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3NoYW95dWUxMjM0,size_16,color_FFFFFF,t_70)
当然求导不是唯一的方法,可以用其他的方法。
原始EWC的实验结果
分别训练A,B,C,横轴表示在不同任务上的表现,纵轴表示训练阶段
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qI0XmEaj-1569768951054)(evernotecid://C7EDAE3B-B0B5-43D7-9120-9EA71A1AFF71/appyinxiangcom/23815745/ENResource/p107)]](https://img-blog.csdnimg.cn/20190929230236788.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3NoYW95dWUxMjM0,size_16,color_FFFFFF,t_70)
EWC的变形
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6SVcr3Bq-1569768951054)(evernotecid://C7EDAE3B-B0B5-43D7-9120-9EA71A1AFF71/appyinxiangcom/23815745/ENResource/p108)]](https://img-blog.csdnimg.cn/20190929230255593.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3NoYW95dWUxMjM0,size_16,color_FFFFFF,t_70)
其他方法
生成数据
生成数据,来缓解数据过多占用内存的问题
先让机器学task1,然后学task2,同时要训练generator,学会生成task1的数据,此时就可以把task1的data丢掉,用生成的数据和task2的放在一起训练。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VsKQJmAt-1569768951055)(evernotecid://C7EDAE3B-B0B5-43D7-9120-9EA71A1AFF71/appyinxiangcom/23815745/ENResource/p109)]](https://img-blog.csdnimg.cn/20190929230314343.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3NoYW95dWUxMjM0,size_16,color_FFFFFF,t_70)
但是目前靠机器生成复杂数据,能不能做的起来尚待研究
新增类
如果训练任务需要不同的网络呢?比如类增量问题
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cX9GeMCn-1569768951055)(evernotecid://C7EDAE3B-B0B5-43D7-9120-9EA71A1AFF71/appyinxiangcom/23815745/ENResource/p110)]](https://img-blog.csdnimg.cn/20190929230330474.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3NoYW95dWUxMjM0,size_16,color_FFFFFF,t_70)
knowledge transfer
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yocblAG7-1569768951055)(evernotecid://C7EDAE3B-B0B5-43D7-9120-9EA71A1AFF71/appyinxiangcom/23815745/ENResource/p112)]](https://img-blog.csdnimg.cn/20190929230403888.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3NoYW95dWUxMjM0,size_16,color_FFFFFF,t_70)
不为每个任务训练模型,让不同模型之间互通有无,也可以节省模型开销空间
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QfjK32Vc-1569768951055)(evernotecid://C7EDAE3B-B0B5-43D7-9120-9EA71A1AFF71/appyinxiangcom/23815745/ENResource/p111)]](https://img-blog.csdnimg.cn/20190929230412122.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3NoYW95dWUxMjM0,size_16,color_FFFFFF,t_70)
life-long vs transfer
不同点:在transfer时,只在乎任务2,不在乎任务1点表现,但是life-long希望都表现好
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qnH3Fu8o-1569768951056)(evernotecid://C7EDAE3B-B0B5-43D7-9120-9EA71A1AFF71/appyinxiangcom/23815745/ENResource/p113)]](https://img-blog.csdnimg.cn/20190929230426535.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3NoYW95dWUxMjM0,size_16,color_FFFFFF,t_70)
如何衡量life-long learning
通常用matrix,每个row代表学习的阶段,column表示在任务X上的表现。
Accuracy是最后一行的平均
多不会遗忘:backward Transfer,学到某个阶段时减去刚学过时的表现,求平均
(通常为负)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4GAyP9s8-1569768951056)(evernotecid://C7EDAE3B-B0B5-43D7-9120-9EA71A1AFF71/appyinxiangcom/23815745/ENResource/p114)]](https://img-blog.csdnimg.cn/20190929230451222.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3NoYW95dWUxMjM0,size_16,color_FFFFFF,t_70)
forward Transfer:表示能transfer到没学的任务的表现
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fOARiixU-1569768951056)(evernotecid://C7EDAE3B-B0B5-43D7-9120-9EA71A1AFF71/appyinxiangcom/23815745/ENResource/p115)]](https://img-blog.csdnimg.cn/20190929230501287.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3NoYW95dWUxMjM0,size_16,color_FFFFFF,t_70)
GEM
gradient Episodic Memory
在新的任务算出gradient,再计算之前的Gradient的方向。算出现在移动的方向。这个方向不会伤害到原有的任务,而且和当前gradient的方向越近越好。
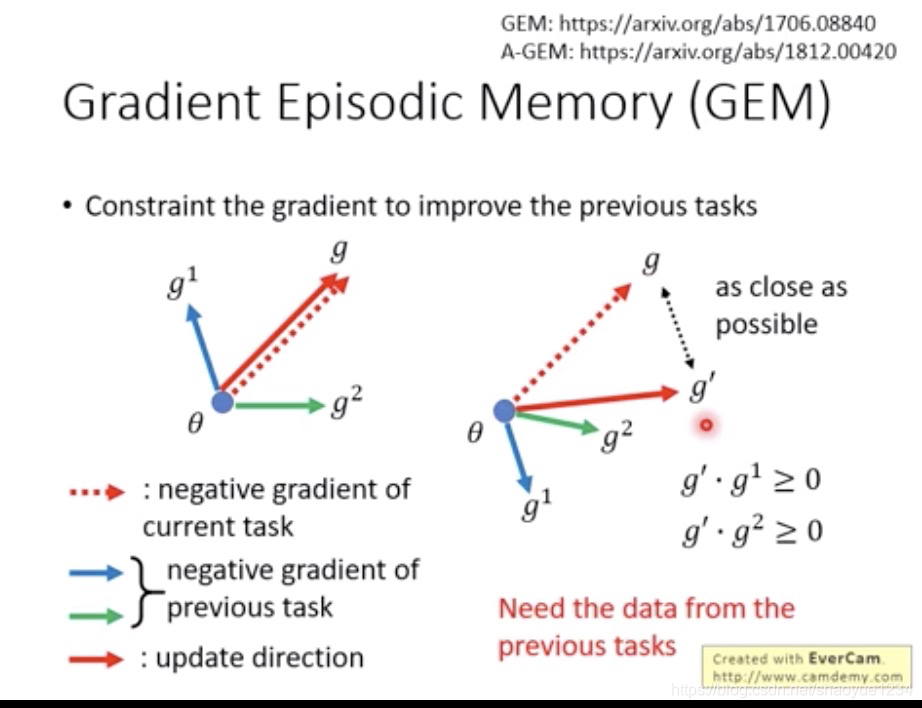
这种需要存一些过去的数据。
它的表现:后续的学习不会影响之前的任务,甚至能有所改善
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-k2X5tdhX-1569768951057)(evernotecid://C7EDAE3B-B0B5-43D7-9120-9EA71A1AFF71/appyinxiangcom/23815745/ENResource/p117)]](https://img-blog.csdnimg.cn/20190929230616945.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3NoYW95dWUxMjM0,size_16,color_FFFFFF,t_70)
Model Expansion
有可能真的学不下了,能不能扩张模型
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-z4Rr1dps-1569768951057)(evernotecid://C7EDAE3B-B0B5-43D7-9120-9EA71A1AFF71/appyinxiangcom/23815745/ENResource/p118)]](https://img-blog.csdnimg.cn/2019092923065428.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3NoYW95dWUxMjM0,size_16,color_FFFFFF,t_70)
模型扩张的速度应该比任务来的速度慢。这个是个尚待研究的问题,没有太多研究。
Progressive Neural Network
一个网络做任务1,网络1的输出当作网络2的输入,网络1、2的输出都当作网络3的输入
实操上做不了太多任务
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NzlaioIc-1569768951057)(evernotecid://C7EDAE3B-B0B5-43D7-9120-9EA71A1AFF71/appyinxiangcom/23815745/ENResource/p119)]](https://img-blog.csdnimg.cn/20190929230704506.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3NoYW95dWUxMjM0,size_16,color_FFFFFF,t_70)
expert gate
每个task训练一个网络,每个新任务进来,看和哪个旧任务最像,希望做到knoledege transfer。这里模型扩张的速度和新任务到来的速度一样,在任务较多的时候也是会有比较多的模型
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-n8YkVkqi-1569768951057)(evernotecid://C7EDAE3B-B0B5-43D7-9120-9EA71A1AFF71/appyinxiangcom/23815745/ENResource/p120)]](https://img-blog.csdnimg.cn/20190929230717176.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3NoYW95dWUxMjM0,size_16,color_FFFFFF,t_70)
Net2Net
让网络长宽
直接加neuron的话,可能会加噪声,所以如何加神经元,但是不引入噪声很重要
做法:把神经元分裂,w仍然是c和d,但是分裂后变为f/2,但是问题是加入的神经元的gradient都一样,所以要加一个小小的noise
也不是每进来一个任务就加网络,而是看训练效果怎么样,决定是否expand
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-46DJiMKV-1569768951058)(evernotecid://C7EDAE3B-B0B5-43D7-9120-9EA71A1AFF71/appyinxiangcom/23815745/ENResource/p121)]](https://img-blog.csdnimg.cn/20190929230731557.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3NoYW95dWUxMjM0,size_16,color_FFFFFF,t_70)
curiculum learning
在未来可能会有的问题
这些任务的顺序怎么排序
例子中,先学任务1,再学任务2,效果不好
但是先学任务2,再学任务1时,一开始任务1效果不好,但是没有忘记
所以说明,是否发生遗忘,和任务排序有非常重要的关系。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xMBcS4w9-1569768951058)(evernotecid://C7EDAE3B-B0B5-43D7-9120-9EA71A1AFF71/appyinxiangcom/23815745/ENResource/p122)]](https://img-blog.csdnimg.cn/20190929230745420.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3NoYW95dWUxMjM0,size_16,color_FFFFFF,t_70)
已有的研究
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pZ3un5IH-1569768951058)(evernotecid://C7EDAE3B-B0B5-43D7-9120-9EA71A1AFF71/appyinxiangcom/23815745/ENResource/p123)]](https://img-blog.csdnimg.cn/201909292307549.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3NoYW95dWUxMjM0,size_16,color_FFFFFF,t_70)

