
- 1Rasa的前期配置(2.x)_rasa 使用显卡
- 2【超全详解一文搞懂】Scala基础
- 3KafKa 开启 SASL 验证_kafka sasl
- 4想进BAT?这些测试面试题助你一臂之力(附答案)_有一天早上打车高峰,滴滴服务端挂了大概30分钟,工程师抢修之后,马上上线,之后又挂
- 5你不知道的18个顶级人工智能平台,你更不知道的顶级认知智能平台!道翰天琼认知智能机器人API平台接口为您揭秘。_在世上最顶级的平台之上探讨人工智能意见
- 6html(四):span标签、img标签、a标签、列表(ul标签、ol标签、dl标签)_ul标签li标签可以用什么代替
- 7【论文阅读】Vision Mamba:双向状态空间模型的的高效视觉表示学习_vision mamba原理
- 8ping带时间戳_ping记录日志和时间戳
- 9【开题报告】基于SpringBoot的童装销售商城的设计与实现_[10] 杨晟;罗奇. 基于spring boot的在线商城系统设计[j]. 科技创新与应用, 20
- 10springboot投票统计管理系统的设计与实现 计算机毕设源码73598_简单投票管理系统
谷歌用新AI超越自己:让Imagen能够指定生成对象,风格还能随意转换
赞
踩
羿阁 发自 凹非寺
量子位 | 公众号 QbitAI
给Imagen加上“指哪打哪”的能力,会变得有多强?
只需上传3-5张指定物体的照片,再用文字描述想要生成的背景、动作或表情,就能让指定物体“闪现”到你想要的场景中,动作表情也都栩栩如生。

不止是动物,其他物体像墨镜、书包、花瓶,也都能做出几乎以假乱真的成品:

属于是发朋友圈也不会被别人看出破绽的那种。(手动狗头)
这个神奇的文字-图像生成模型名叫DreamBooth,是谷歌的最新研究成果,基于Imagen的基础上进行了调整,一经发布就在推特上引发热议。
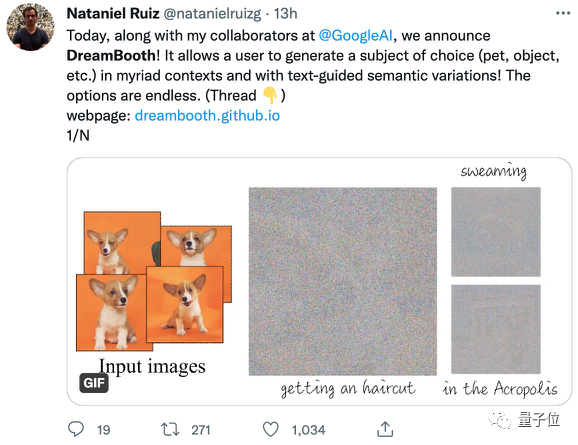
有网友调侃:这简直是最先进的梗图生成器。


目前相关研究论文已上传至arXiv。

几张照片就能“环游世界”
在介绍原理前,让我们先来看看DreamBooth的各种能力,包括换景、指定动作表情服饰、更迭风格等。
如果你是个“铲屎官”,有了这个模型的“换景能力”,就能足不出户送自家狗子走出家门,凡尔赛宫里、富士山脚下……通通不在话下。

△光照也比较自然
不仅如此,宠物的动作和表情也都能随意指定,属实是把“一句话P图”的细节拿捏到位了。
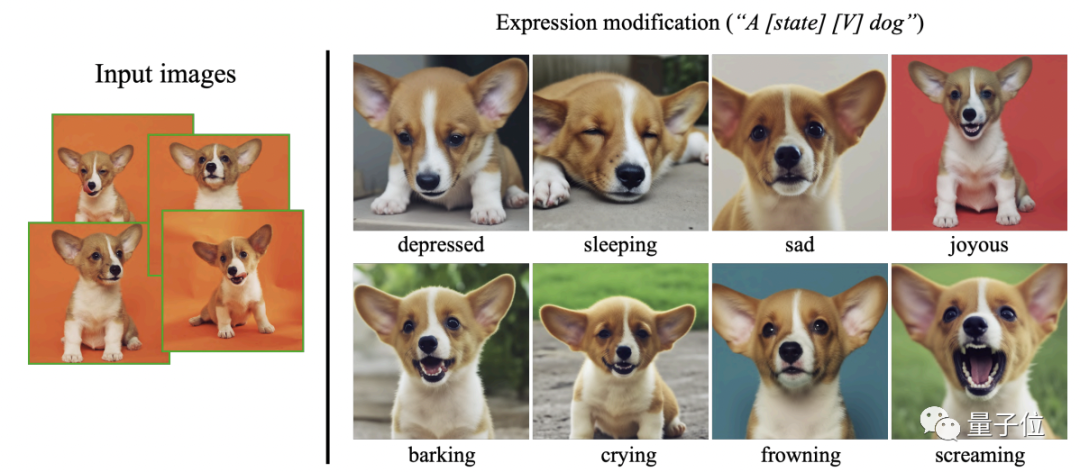
除了上面的“基操”以外,DreamBooth甚至还能更换各种照片风格,也就是所谓的“加滤镜”。
例如,各种“世界名画”画风、各种视角的狗子,简直不要太艺术:

至于给它们加上装饰?各种cosplay的小道具,也是小菜一碟。

除此之外,无论是更换颜色:

还是更魔幻一点,更换物种,这只AI也都能做到。

那么,如此有趣的效果背后的原理是什么呢?
给输入加个“特殊标识符”
研究人员做了个对比,相较于其他大规模文本-图像模型如DALL-E2、Imagen等,只有采用DreamBooth的方法,才能做到对输入图像的忠实还原。
如下图所示,输入3张右边表盘上画着黄色“3”的小闹表,其中DreamBooth生成的图像完美保留了钟表的所有细节,但DALL-E2和Imagen几次生成的钟都与原来的钟“有那么点差异”。

△李逵和“李鬼”
而这也正是DreamBooth最大的特点——个性化表达。
用户可以给定3-5张自己随意拍摄的某一物体的图片,就能得到不同背景下的该物体的新颖再现,同时又保留了其关键特征。
当然,作者也表示,这种方法并不局限于某个模型,如果DALL·E2经过一些调整,同样能实现这样的功能。
具体到方法上,DreamBooth采用了给物体加上“特殊标识符”的方法。
也就是说,原本图像生成模型收到的指令只是一类物体,例如[cat]、[dog]等,但现在DreamBooth会在这类物体前加上一个特殊标识符,变成[V][物体类别]。
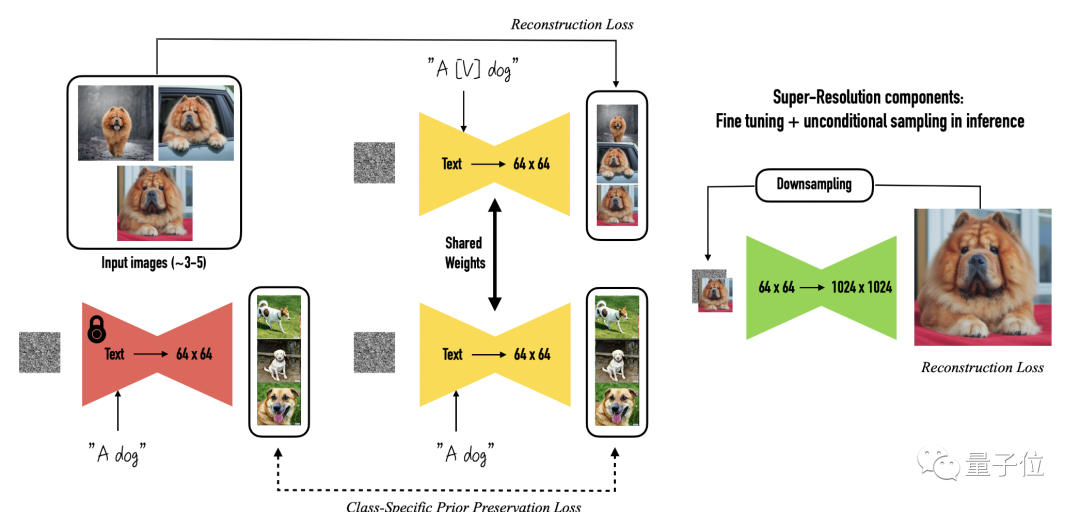
以下图为例,将用户上传的三张狗子照片和相应的类名(如“狗”)作为输入信息,得到一个经过微调的文本-图像扩散模型。
该扩散模型用“a [V] dog”来特指用户上传图片中的狗子,再把其带入文字描述中,生成特定的图像,其中[V]就是那个特殊标识符。
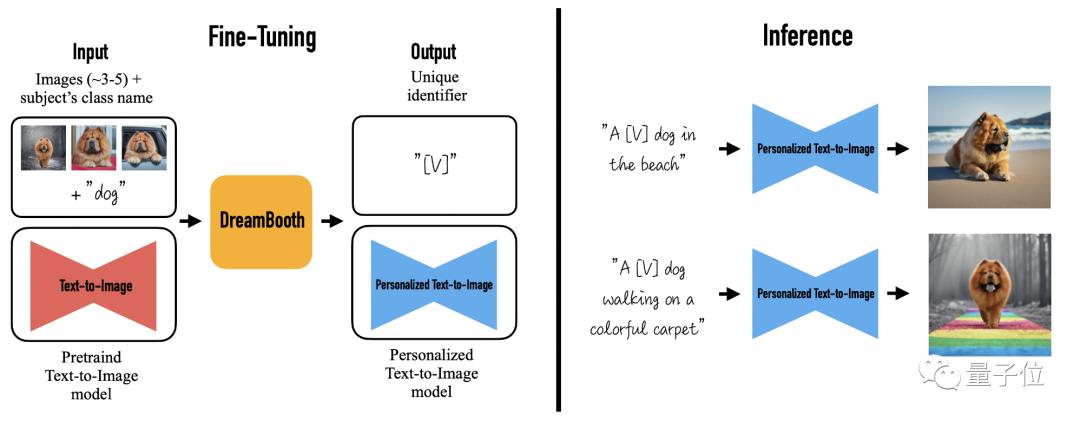
至于为什么不直接用[V]来指代整个[特定物体]?
作者表示,受限于输入照片的数量,模型无法很好地学习到照片中物体的整体特征,反而可能出现过拟合。
因此这里采用了微调的思路,整体上仍然基于AI已经学到的[物体类别]特征,再用[V]学到的特殊特征来修饰它。
以生成一只白色的狗为例,这里模型会通过[V]来学习狗的颜色(白色)、体型等个性化细节,加上模型在[狗]这个大的类别中学到的狗的共性,就能生成更多合理又不失个性的白狗的照片。
为了训练这个微调的文本-图像扩散模型,研究人员首先根据给定的文本描述生成低分辨率图像,这时生成的图像中狗子的形象是随机的。
然后再应用超分辨率的扩散模型进行替换,把随机图像换成用户上传的特定狗子。
研究团队
DreamBooth的研究团队来自谷歌,第一作者是Nataniel Ruiz。
Nataniel Ruiz是波士顿大学图像和视频计算组的四年级博士生,目前在谷歌实习。主要研究方向是生成模型、图像翻译、对抗性攻击、面部分析和模拟。

论文链接附在文末,感兴趣的小伙伴们赶紧来看看吧~
论文地址:
https://arxiv.org/abs/2208.12242
参考链接:
[1]https://dreambooth.github.io/
[2]https://twitter.com/natanielruizg/status/1563166568195821569
[3]https://natanielruiz.github.io/
— 完 —
「人工智能」、「智能汽车」微信社群邀你加入!
欢迎关注人工智能、智能汽车的小伙伴们加入我们,与AI从业者交流、切磋,不错过最新行业发展&技术进展。
PS. 加好友请务必备注您的姓名-公司-职位哦 ~

点这里 本文内容由网友自发贡献,转载请注明出处:https://www.wpsshop.cn/w/繁依Fanyi0/article/detail/307698
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

