
- 1运算放大器的理解与应用_电压控制电路的运放作用csdn
- 2基于先验驱动深度神经网络的图像复原去噪_神经网络恢复图像算法
- 3Android 中的广播机制_android 广播
- 4Docker入门学习教程_c# docker
- 5深度学习图解 - 具备高中数学知识就能从入门到精通的神书 Andrew W· Trask
- 6使用move_base规划路径后,小车接近目的地后原地打转的原因分析_movebase导航原地打转
- 7pytorch自定义loss损失函数
- 8JavaScript面试题看这一篇就够了,简单全面一发入魂(持续更新 step2)_javascript 面试题
- 9ArkTS基础学习笔记_arkts文档
- 10手把手教你DouZero项目的环境配置及运行,使用注意事项(否则会退出)
让你COPY 自己的声音,GPT-SoVits 人声模型训练_做声音模型的程序
赞
踩
前言
今天刷b站突然刷到一个视频,视频中,著名歌手孙燕姿唱着一首《泪桥》,我心想着:WTF,这不是我最爱的伍佰老师的歌曲吗?后来看评论区才知道,原来这是通过AI来模拟人声的一个恶搞视频。这极大地激发了我的兴趣。但是在了解后发现,网络上大多数都是一些模型优化不怎么好的,要么就是动辄需要几千上万的音频,要么就是需要为爱发电的,但是身为一个穷苦大学生的我,怎么淘的出来$呢,于是乎,我开始疯狂刷Git hub,终于,皇天不负有心人,我终于到了一个最快速、方便的声音copy模型,一个强大的少量语音转换和文本转换到语音 WebUI——GPT-SoVITS!
介绍
首先GPT-SoVITS是一个开源的TTS项目,官方声称只需要1分钟的音频文件就可以克隆声音,并且支持将汉语、英语、日语三种语言的文本转为克隆声音。
GPT-SoVits
另外,官方还给了一个中国地区用户可以使用AutoDL Cloud Docker在线体验的功能
特点
- 零样本 TTS:输入 5 秒语音样本并体验即时文本到语音转换。
- Few-shot TTS:仅用 1 分钟的训练数据即可微调模型,以提高语音相似度和真实感。
- 跨语言支持:用与训练数据集不同的语言进行推理,目前支持英语、日语和中文。
- WebUI工具:集成工具包括语音伴奏分离、自动训练集分割、中文ASR和文本标注,帮助初学者创建训练数据集和GPT/SoVITS模型。
安装
测试环境
- Python 3.9、PyTorch 2.0.1、CUDA 11
- Python 3.10.13、PyTorch 2.1.2、CUDA 12.3
注意:numba==0.56.4 需要 py<3.11
另外,因为我自己没有mac,Linux系统的电脑,所以本文仅介绍Windows系统的安装步骤,MAC,Linux用户可以自行前往官网查询。
Windows 用户(使用 win>=10 进行测试),可以直接下载预打包的发行版并双击go-webui.bat启动 GPT-SoVITS-WebUI。
运行
解压完下载好的压缩包后,得到这样一个文件夹
然后双击go-webui.bat批处理文件

等他加载完成后,我们得到一个网址

在网页打开它后,我们的web界面就已经运行成功了!!!

开始炼丹——训练自己的声音
准备工作
找一出安静的地方,用录音设备录制一段自己的声音,随便找一篇小学课外来阅读都行。如果周围声音很嘈杂的话,就必须使用到项目自带的声音处理工具
加载一会儿就会弹出一个新的web界面
 可以看到我们output文件夹里面已经出现了处理后的音频(我的不一样,正常的应该有两个,一个是vocal开头的,一个是instrument开头的,我们保留vocal开头的)
可以看到我们output文件夹里面已经出现了处理后的音频(我的不一样,正常的应该有两个,一个是vocal开头的,一个是instrument开头的,我们保留vocal开头的)
干声提取成功后,这个界面就可以关掉了(很占运存!)
音频切割
并不是所有人都是4090,所以,对于我们这些显存只有6g的还是都要做这一步的。

设置就默认就行。
可以看见,我们的音频被分为了很多个小片段

打标签
利用自带的打标签工具就可以自动为我们的音频片段转换为对应的文字
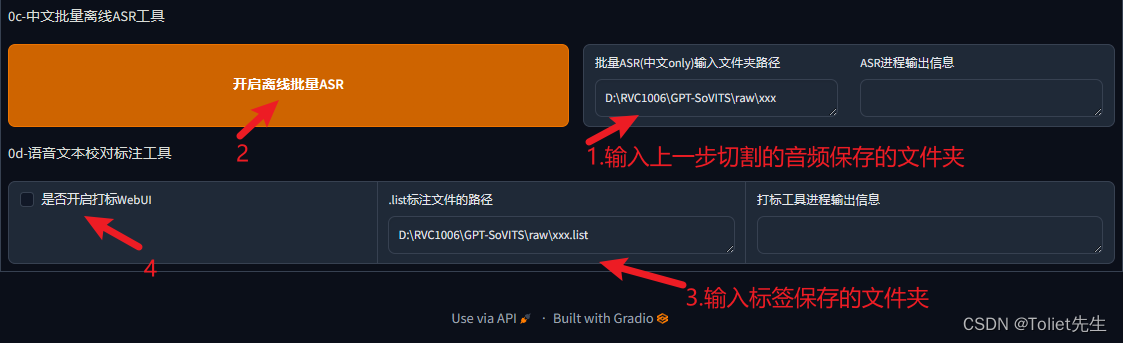
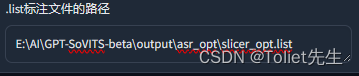
标签一般保存在output/asr_opt里面
点击开启打标webui后,弹出(因为上一步是自动做的,可能有些识别的不准,所以人工校对一下,追求完美可以校对,如果对自己普通话很有信心则可以跳过这一步,系统自动识别的已经很准确了。)
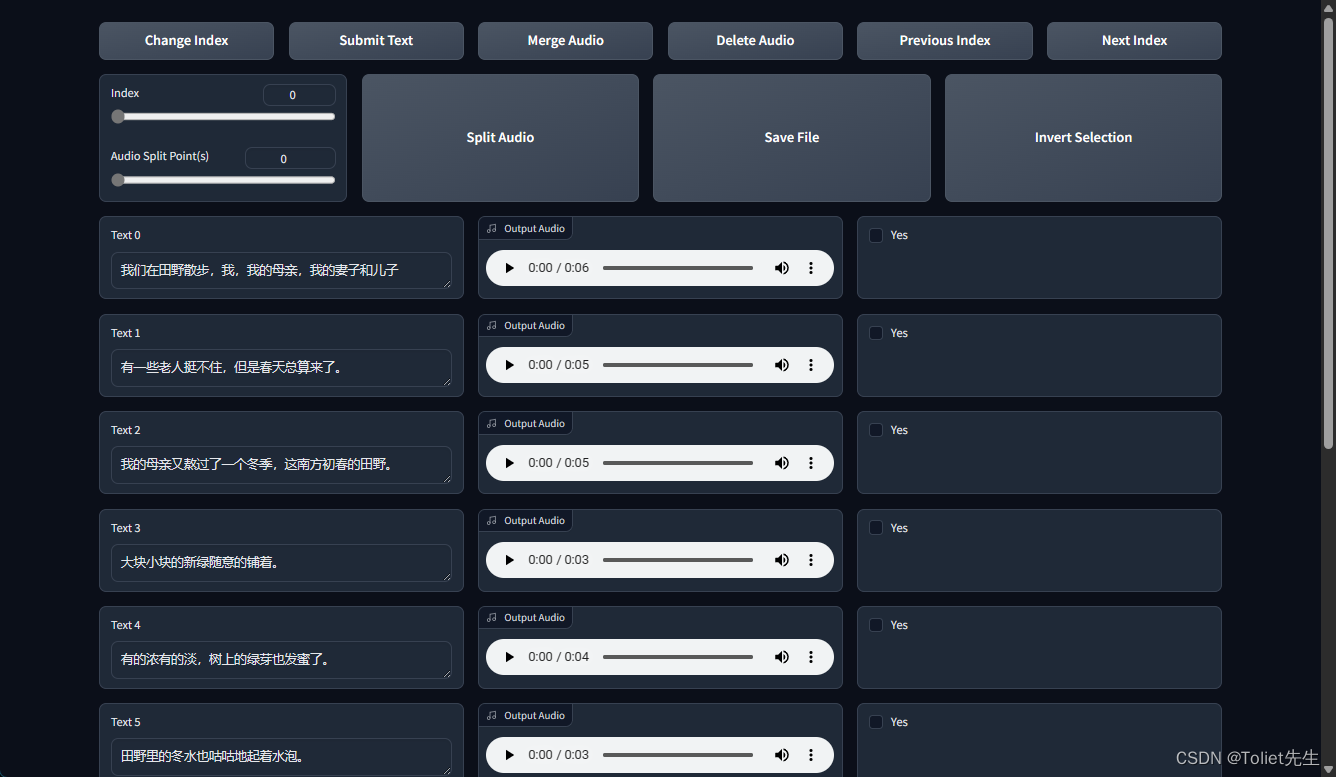
如果有错别字需要更改,按照以下步骤来
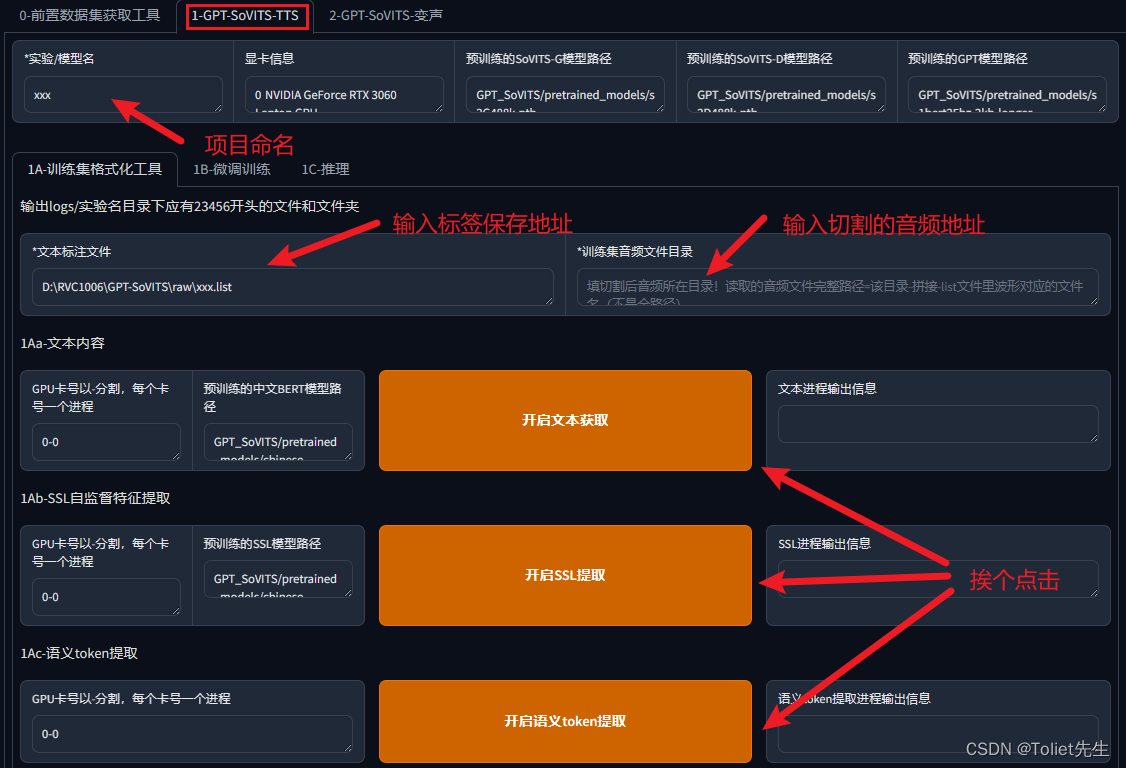
处理数据
填写完成后,分别点击下面三个按钮,每个按钮点完后,等待执行结束再点击下一个。
模型训练
建议就保持默认
填写模型名称,设置batch size,建议batch_size设置为自己显存的一半,如果高了的话会爆显存!!
接着设置轮数(total epoch),SoVITS模型轮数,可以设置的高一点,GPT模型轮数不能高于20
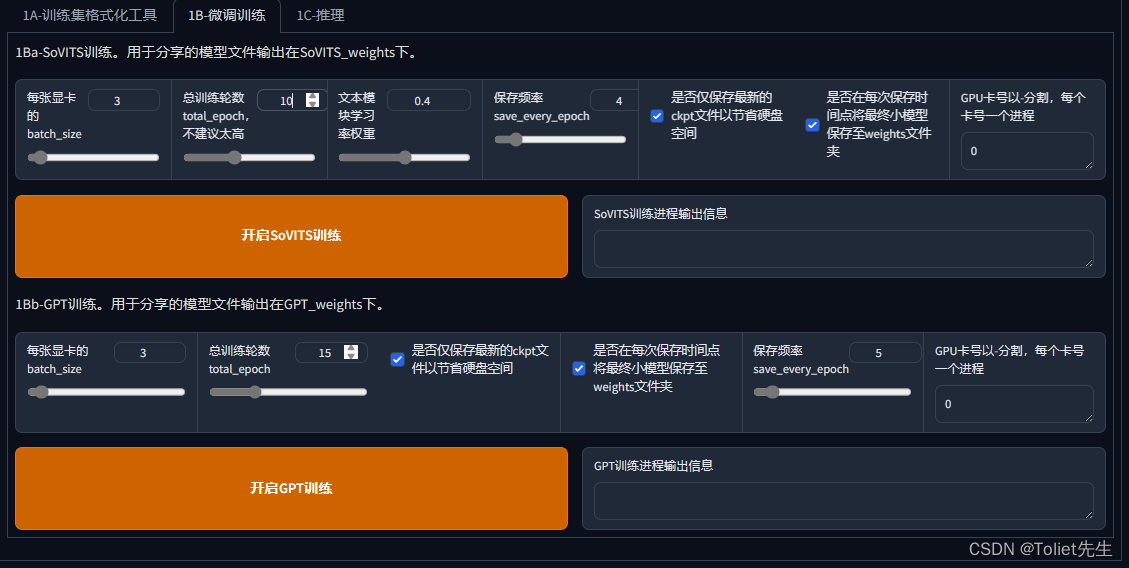
点击Start SoVITS traing之后,就可以看到已经开始训练了。

训练的时候可以查看显卡占用,爆显存了就调低batch size,或者存在过长的音频,需要在切割音频环节将过长音频再次切割。
SoVITS训练完成,可以点击"Start GPT traing"开始GPT训练了,同样点完等待。
开始推理声音
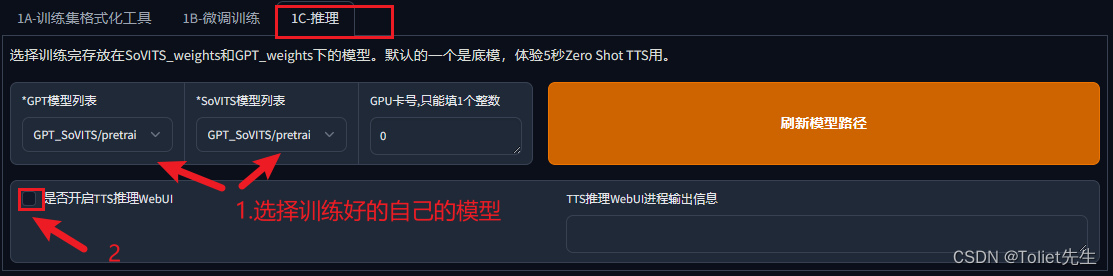
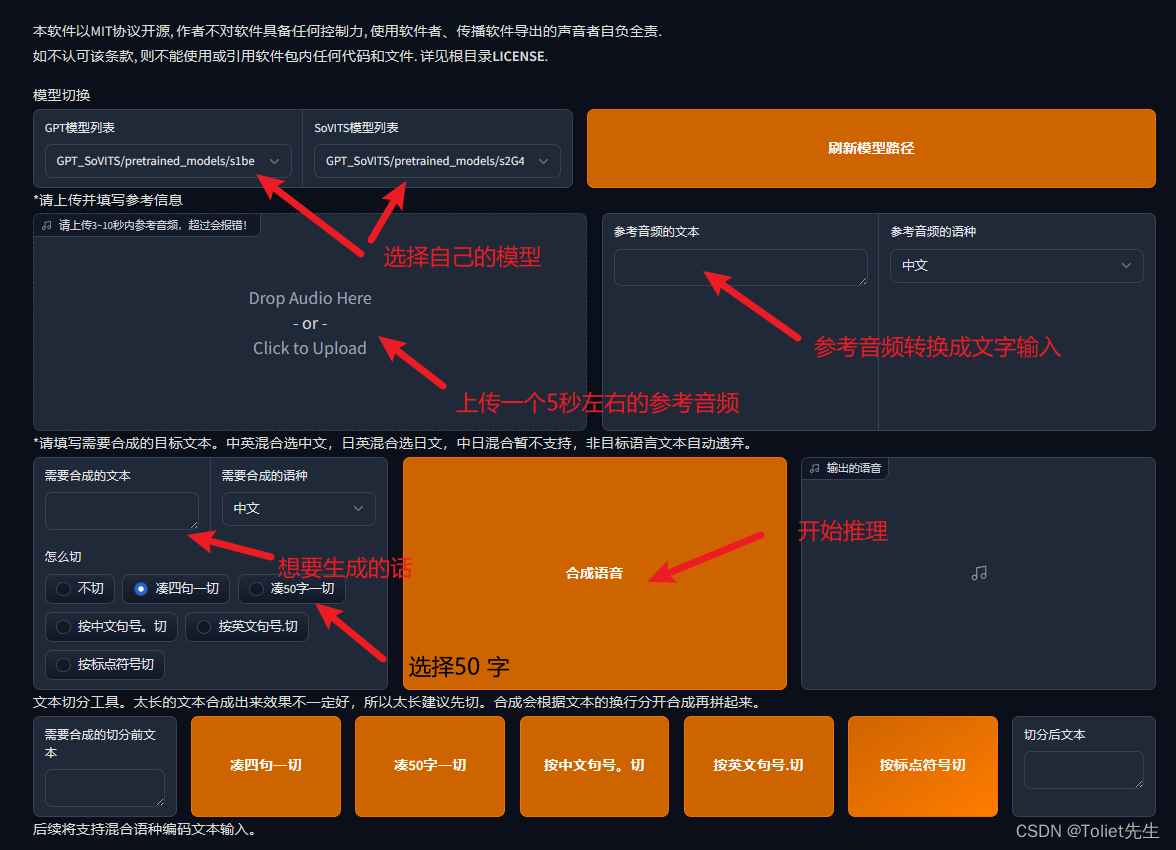
上面参考音频,建议是数据集中的音频。最好5秒。参考音频很重要!会学习语速和语气,请认真选择!!!

