
- 1从瀑布到敏捷--漫画解读软件开发模式变迁。
- 2【论文解读】Parameter-Efficient Transfer Learning for NLP
- 3Python爬取去哪网旅游景点保存到csv文件_中国旅游数据csv
- 4词嵌入(Word Embedding)_词嵌入(word embeddings)
- 5人工智能的基本原理_人工智能原理
- 6AI作画,国风油画风随心定制~ Stable Diffusion模型使用,三步就上手_openvino stable diffusion
- 7《动手学深度学习》(PyTorch版)代码注释 - 53 【Find_synonyms&analogies】_pytorch获取近义词
- 8自然语言处理(NLP)技术_自然语言处理nlp的技术实现
- 9Ubuntu20.04卸载cuda12.0
- 10前端在el-dialog中嵌套多个el-dialog_el-dialog嵌套el-dialog
华为诺亚实验室最新研究进展 | AIGC时代的ImageNet,百万生成图片助力AI生成图片检测器研发_aigc benchmark
赞
踩

Title: GenImage: A Million-Scale Benchmark for Detecting AI-Generated Image
Paper: https://arxiv.org/abs/2306.08571
Code: https://github.com/GenImage-Dataset/GenImage
导读
在这个 AIGC 爆发的时代,人人都可以利用AI算法生成高质量的文本,图像,音频内容。其中,由Midjourney, Stable Diffusion等图像生成方法制作的图像,其逼真程度让人赞叹。人眼已经难以对其真假进行区分了。这不禁唤起了人们的隐忧:大量虚假图片将会在互联网上广泛传播。虚假图片的泛滥会引发多种社会安全问题。例如,虚假新闻会扰乱社会秩序,混淆视听。恶意的人脸图片造假则会引发金融欺诈,造成信任危机。
例如,下图为Midjourney生成的特朗普被捕图片。这类图片在社交媒体上广泛传播,对政治领域造成了不良影响。因此,对这些AI生成的图像进行有效监管是非常有必要的。

考虑到人眼已经难以对真假图片进行区分,我们急需一种AI生成图像检测器以区分AI制作的图像和真实的图像。然而,现在大规模数据集的缺失妨碍了检测器的开发。因此,我们提出了百万量级的GenImage数据集,致力于构建AIGC时代的ImageNet。
数据集介绍
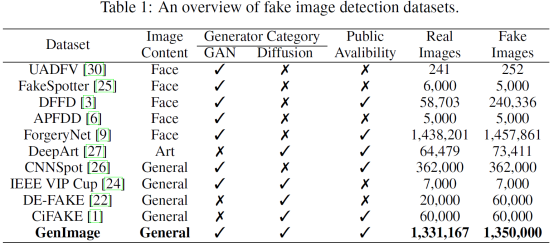
过去业界也有推出一些数据集。他们主要有三个特点。第一个是数据规模小,第二个是都是基于GAN的,第三个是局限于人脸数据。随着时间推移,数据规模慢慢地在增加,生成器也从GAN时代过渡到Diffusion时代,数据的范围也在增加。但是一个大规模的,以Diffusion模型为主的,涵盖各类通用图像的数据集仍然是缺失的。
基于此,我们提出一个对标imagenet的genimage数据集。真实的图片采用了ImageNet。虚假的图片采用ImageNet的标签进行生成。我们利用了八个先进的生成器来生成,分别是Midjourney, Stable Diffusion V1.4, Stable Diffusion V1.5, ADM, GLIDE, Wukong,VQDM和BigGAN。这些生成器生成的图片总数基本与真实图片一致。每个生成器生成的图片数量也基本一致。每一类生成的图片数量基本一致。
这个数据集具有以下优势:
- 大量的数据:超过百万对图片对。
- 丰富的图片内容:利用ImageNet进行构建,具有丰富的标签
- 先进的生成器:覆盖Midjourney, Stable Diffusion等Diffusion生成器。
在真实世界中检测器往往会遇到各种各样的困难。我们经过实验发现,检测器往往在两种情况下性能下降严重。第一种是面对训练集中未出现的生成器生成的图片时。第二种是面对退化的图像。例如,CNNSpot在Stable Diffusion V1.4上训练后,在Midjourney上测试仅有52.8的准确率。当训练和测试生成器同为Stable Diffusion V1.4,在面对模糊的图像时,CNNSpot准确率仅仅为77.9。基于此,我们在这个数据集基础上对检测器提出两个挑战:
- 交叉生成器:检测器在一种生成器生成的数据上训练,在其他生成器生成的数据上验证。这个任务目的是考察检测器在不同生成器上的泛化能力。
- 退化图像识别:检测器需要对于低分辨率,模糊和压缩图像进行识别。这个任务主要考察检测器在真实条件(如互联网上传播)中面对低质量图像时的泛化问题。
我们相信这个数据集的提出将大大有助于人们开发AI生成图片检测器。
实验
我们做了一些实验来考察这个数据集,我们发现在某个生成器上训练的ResNet-50模型在其他的测试准确率会明显降低。然而在真实情况下我们难以得知遇到的图像的生成器是什么。因此检测器对于不同生成器生成图片的泛化能力很重要。
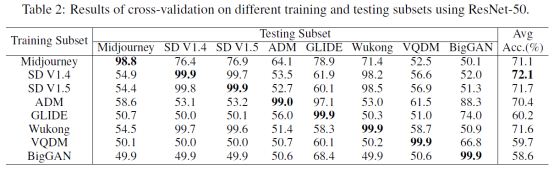
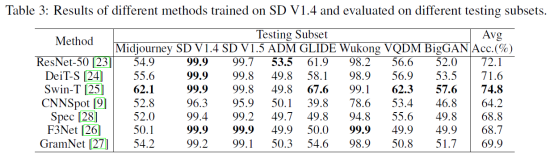
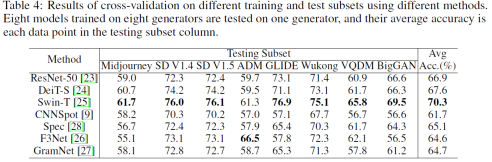
我们对比了现有方法在Stable Diffusion V1.4上训练,然后在各种生成器上测试的结果,见图3。我们也评测了各种生成器上训练,然后在各种生成器上测试的结果。见图4。图4中,Testing Subset那一列中的每一个数据点,都是在八个生成器上训练,然后在一个生成器上测试得到的平均结果。然后我们将这些测试集上的结果平均,得到最右侧的平均结果。
我们对测试集进行退化处理,采用不同参数下的低分辨率,JPEG压缩和高斯模糊,评
测结果如下
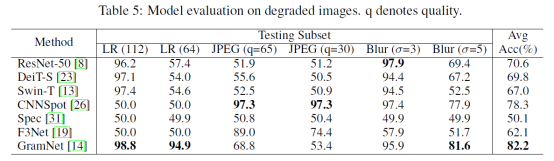
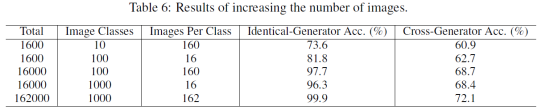
那么采集这么多数据是不是有用呢?我们做了相关实验,证明通过提升数据类比和每类的图片数量,我们是可以提高性能的。
针对GenImage数据集对于不同图片的泛化能力,我们发现他对于人脸和艺术类图片也能达到很好的效果。


总结
随着AI生成图片能力的不断提升,对于AI生成的图片实现有效检测的需求将会越来越迫切。本数据集致力于为真实环境下的生成图片检测提供有效训练数据。我们使用ResNet-50在本数据集中训练,然后在真实推文中进行检测。如下图4,ResNet-50能够有效识别真图和假图。这个结果证明了GenIamge可以用于训练模型以判别真实世界的虚假信息。我们认为,该领域未来值得努力的方向是不断提升检测器在GenImage数据集上的准确率,并进而提升其在真实世界面对虚假信息的能力。



