
- 1OpenAI 为 GPT-3.5 Turbo 推出微调功能 (fine-tuning)_fine-tuning openai's gpt 3.5 for langchain agents
- 2华为鸿蒙系统支持什么手机_什么样的手机可以刷鸿蒙系统?看看你的手机支持吗?...
- 3安卓连接java_从零学习安卓自动化(java+appium方向):手机连接Appium(二)
- 4基于FPGA的UDP协议栈设计第四章_UDP层设计
- 5yolov5训练高精度非机动车驾驶检测_非机动车数据集
- 6modelsim仿真验证后,修改代码,不用重新关闭打开的调试技巧_modelsim仿真改原文件后
- 7【证明】对极几何:本质矩阵内在性质_本质矩阵的内在性质
- 8Unity开发(六) Prefab加载自动化管理引用计数管理器_unity assetbundle 和 gameobject的 引用计数
- 9怎么样去处理样本不平衡问题 | (文后分享大量检测+分割框架)
- 10【无人机综合题】+题解
详谈大模型训练和推理优化技术_大模型训练和推理的区别
赞
踩
详谈大模型训练和推理优化技术
作者:王嘉宁,转载请注明出处:https://wjn1996.blog.csdn.net/article/details/130764843
ChatGPT于2022年12月初发布,震惊轰动了全世界,发布后的这段时间里,一系列国内外的大模型训练开源项目接踵而至,例如Alpaca、BOOLM、LLaMA、ChatGLM、DeepSpeedChat、ColossalChat等。不论是学术界还是工业界,都有训练大模型来优化下游任务的需求。
然而,大量实验证明,在高质量的训练语料进行指令微调(Instruction-tuning)的前提下,超过百亿参数量的模型才具备一定的涌现能力,尤其是在一些复杂的推理任务上,例如下图:
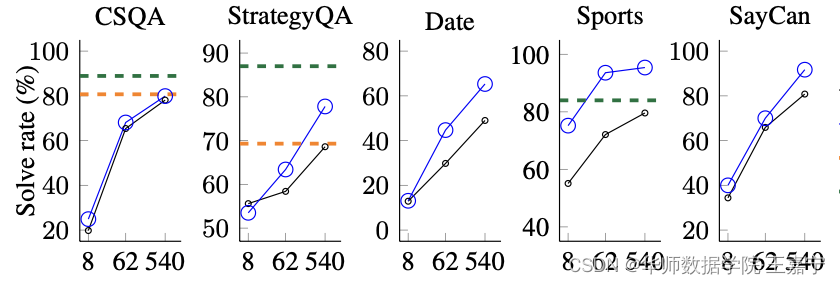
图来自论文《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》
也就是说,如果我们需要通过大模型技术来提升业务指标,不得不要求我们去训练一个百亿规模的模型。
然而,一般情况下,我们不具备如此大规模的计算资源,尤其是对于学校里一般的科研团队,也许只有少量V100(32G),运气好可能会有几台A100。因此在有限的算力条件下训练或推理一个百亿量级的大模型是不太现实的。因此,无疑要在训练和推理两个阶段采用一些优化策略来解决此类问题。
本篇博文主要整理一系列大模型在训练和推理两个阶段的优化技术,以满足我们在有限的计算资源的条件下训练自己的大模型,下面列出本文主要介绍的一些优化技术:
- 混合精度训练:FP16+FP32 或 BF16+FP32;
- DeepSpeed分布式训练:ZeRO-1、ZeRO-2、ZeRO-3;
- Torch FSDP + CPU Offloading;
- 3D并行;
- INT8模型量化:对称/非对称量化、量化感知训练;
- 参数有效性学习(Parameter-Efficient Learning):LoRA、Adapter、BitFit、P-tuning;
- 混合专家训练(Mixed-of Experts,MoE):每次只对部分参数进行训练;
- 梯度累积(Gradient Accumulation):时间换空间
- 梯度检查点(Gradient checkpointing):时间换空间
- Flash Attention
一、Transformer模型算力评估
在介绍优化技术之前,首先介绍一下如何评估大模型的算力。众所周知,现如今的预训练语言模型均是基于Transformer结构实现的,因此大模型的参数主要来源于Transformer的Self-Attention部分。EleutherAI团队近期发布一篇博客来介绍如何估计一个大模型的算力成本,公式如下:
C
=
τ
T
≈
6
P
D
C=\tau T\approx 6PD
C=τT≈6PD
其中:
C C C 表示Transformer需要的计算量,单位是FLOP;
P P P 表示Transformer模型包含的参数量;
D D D 表示训练数据规模,以Token数量为单位;
τ \tau τ 表示吞吐量,单位为FLOP
T T T 表示训练时间;
该公式的原理如下:
C
=
C
forward
+
C
backward
C=C_{\text{forward}}+C_{\text{backward}}
C=Cforward+Cbackward:表示训练过程中的前后向传播;
C
forward
≈
2
P
D
C_{\text{forward}}\approx2PD
Cforward≈2PD:前向传播计算成本约等于两倍的参数量乘以数据规模;
C
backward
≈
4
P
D
C_{\text{backward}}\approx4PD
Cbackward≈4PD:反向传播计算成本约等于四倍的参数量乘以数据规模;
C C C 是一个量化计算成本的单位,通常用FLOP表示,我们也可以用一些新的单位来表示:
- FLOP/s-s:表示每秒浮点运算数 × \times ×秒;
- PetaFLOP/s-days:表示实际情况下每秒浮点运算数 × \times ×天。
下图展示了不同规模的预训练语言模型的算力成本:
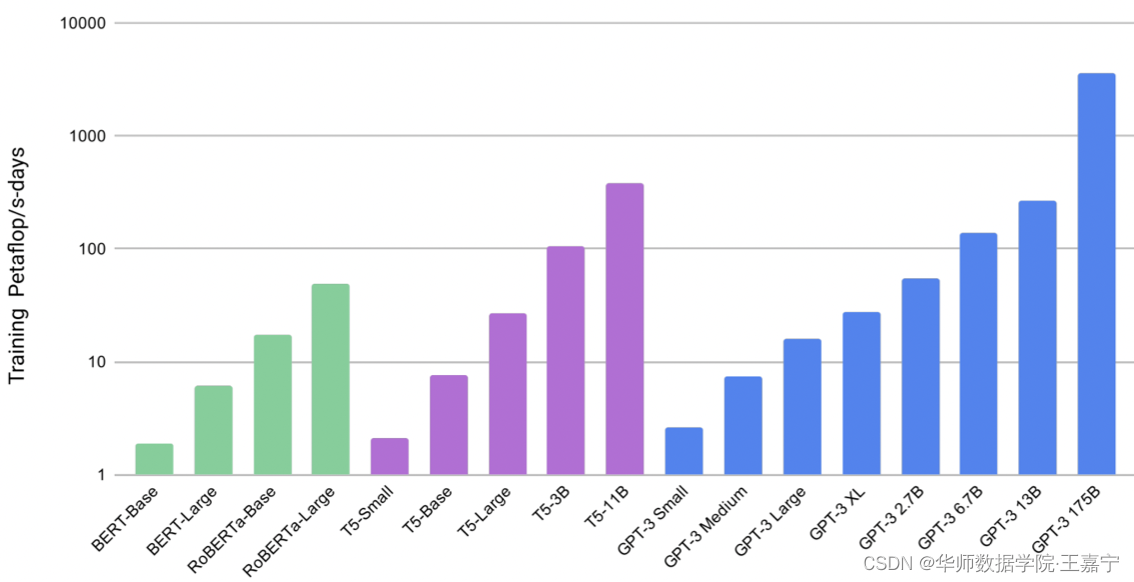
可知,随着规模的增大,其算力成本会呈现指数级别的增长。
二、混合精度训练
混合精度训练是一个很常用的显存优化技术,其适用于单机单卡或多卡并行场景。
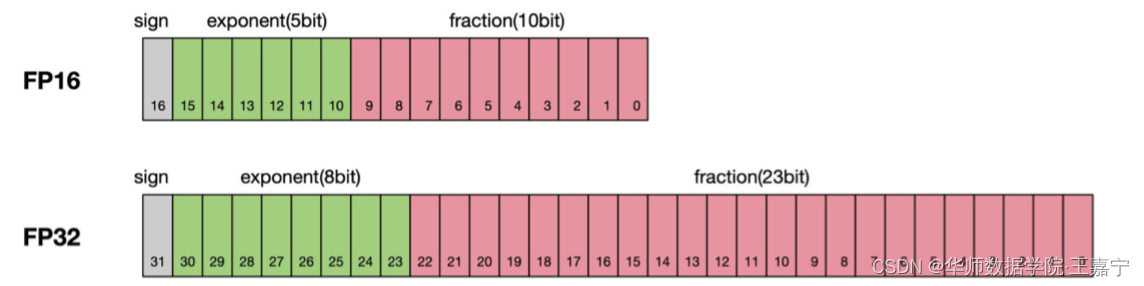
一般情况下,计算机在进行浮点运算时所采用的是FP32(单精度),其中8位用于存储整数部分,23位存储小数部分,因此其可以存储高精度浮点数。
因此在显存优化场景下,牺牲浮点运算的精度可以降低存储量。例如采用FP16进行浮点运算时,只需要一半的存储空间即可,因此成为半精度浮点运算。但是FP16的整数为只能最大到65536,很容易出现溢出问题,为此,BF16是另一种半精度浮点运算表示,其相较于FP16来说,增大了整数部分的存储位,避免计算溢出问题,但是也牺牲了一定的精度。
在实际的训练时,通常是将单精度与半精度进行混合实现浮点运算的。典型代表是动态混合精度法(Automatic Mixed Precision,AMP),如下图所示:
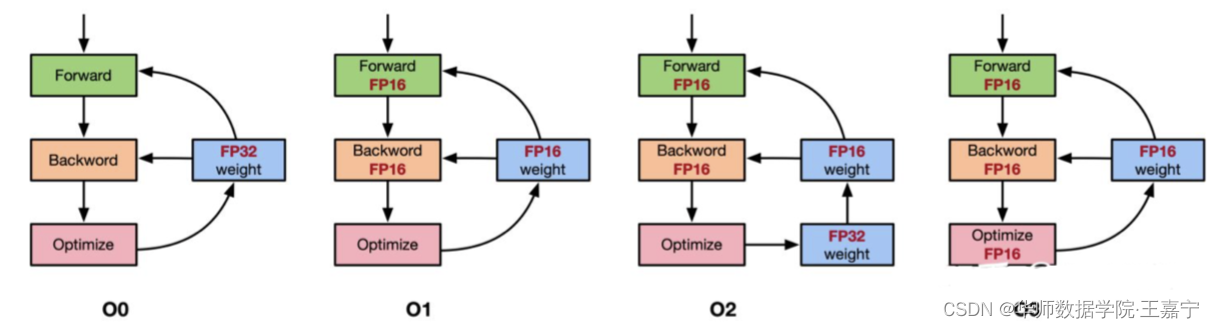
- O0:表示最原始的FP32浮点运算;
- O1:除了优化器部分为FP32,其余都使用FP16;
- O2:在O1的基础上,额外使用FP32保存了一份参数用于参数更新;
- O3:所有参数全部为半精度;
AMP采用的是混合FP32+FP16,在不同的训练阶段动态地指定那些部分转换为半精度进行训练。AMP典型的是使用上图的O2部分,即使用混合精度训练不仅可以提高乘法运算过程中的效率问题,还有效避免累加时的舍入误差问题。
Pytorch1.5版本后继承了AMP的实现,调用AMP进行混合精度训练的例子如下:
from torch.cuda.amp import autocast, GradScaler
# FP32模型
model = Net().cuda()
optimizer = optim.SGD(model.parameters(), ...)
scaler = GradScaler()
for epoch in epoches:
for input, target in data:
optimizer.zero_grad()
with autocast():
output = model(input)
loss = loss_fn(output, target)
scaler.scale(loss).backward()
scaler.step(optimizer)
scale.update()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
三、DeepSpeed分布式训练
一张32G的GPU上可能无法塞得下100亿模型的权重、梯度、优化器等参数,但是我们或许可以将这些参数按照一定规则拆分到多张卡上,这便是分布式并行优化的思想。
DeepSpeed是由微软开源的分布式训练加速框架,其使用了一种称为零冗余(ZeRO)的显存优化技术。本质上,它是一种数据并行的分布式训练策略,重点优化了数据并行中的显存占用问题。在ZeRO数据并行中,每个GPU上虽然拥有完整的网络,但是每个GPU只保存一部分的权重,梯度和优化器状态信息,这样就就可以将权重,梯度,优化器状态信息平均分配到多个GPU上。
下图展示了DeepSpeed的3种ZeRO stage。假设需要训练的模型占用显存位120G,集群内有 N d = 64 N_d=64 Nd=64张GPU:
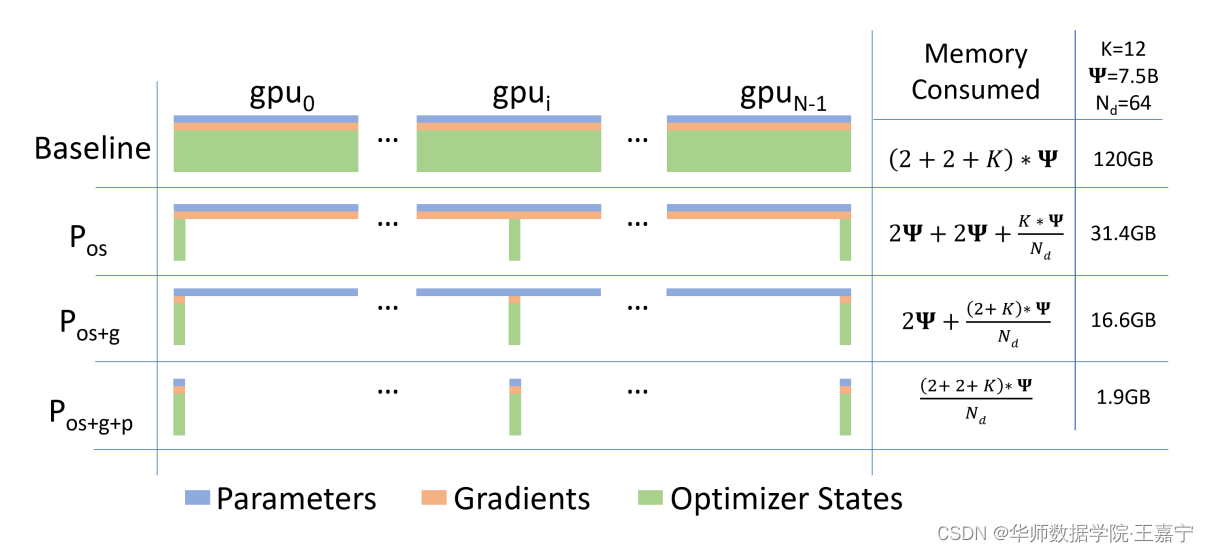
- Baseline:传统的数据并行策略,每张GPU上存储全部模型的权重、梯度和优化器等参数,每张卡上并行训练不同的数据,并实现参数汇聚更新。该情况下,每张卡依然要加载120G参数,显然是无法在一般机器上实现的;
- ZeRO Stage1——优化器并行:在训练过程中,优化器状态参数占用的显存空间是非常大的,因此将优化器状态参数分发到不同的GPU上,此时单张卡上的显存占用会大大降低;
- ZeRO Stage2——梯度+优化器并行:在ZeRO Stage1的基础上,额外对梯度进行了分布式存储,可以发现120G的显存占用直接降低到16G;
- ZeRO Stage3——权重+梯度+优化器并行:模型的所有参数都进行分布式存储,此时一张卡上只有1.9G占用。
基于ZeRO在训练过程中的原理,有博主分享比较精妙的图,来源于[多图,秒懂]如何训练一个“万亿大模型”?。假设有2张卡,训练一个2层的Transformer模型:
(1)传统的数据并行:
每张卡上都完整的存放模型全部参数(橘黄色部分),包括权重、梯度和优化器。在前向传播过程中,每张卡上独立地对喂入的数据进行计算,逐层获得激活值(Transformer模型中的FeedForward模块的输出):
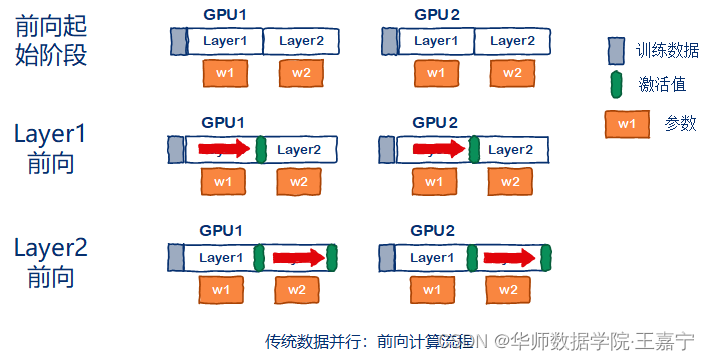

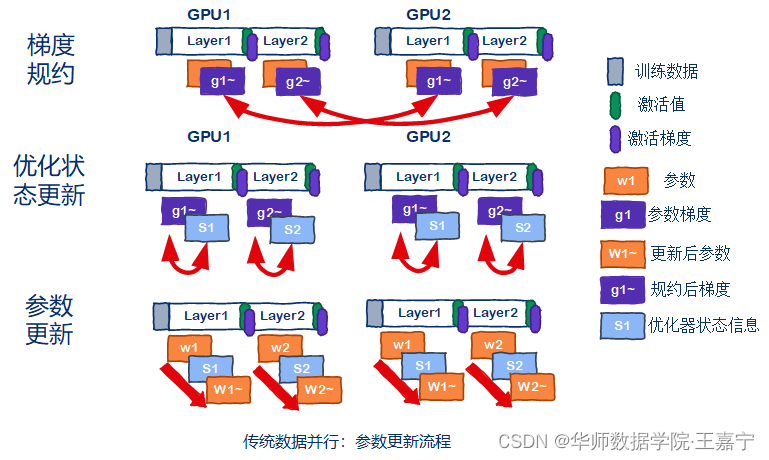
(2)DeepSpeed ZeRO并行训练:
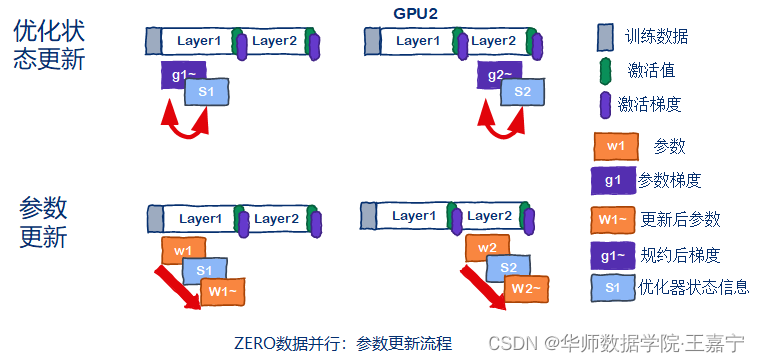
DeepSpeed则是在数据并行的基础上,对权重、梯度和优化器状态也进行了分布式存储,下面几张图展示ZeRO Stage3的情况。在初始时,假设两张卡分别只存储一层Transformer。当某一张卡在进行前向传播时,如果此时参数不存在,则需要朝有该参数的卡上借用该参数进行前向计算。例如在GPU1上计算第2层Transformer时,需要GPU2上的参数拷贝给GPU1实现第2层Transformer的计算。
这也是为什么在使用ZeRO的时候,GPU的显存会不断变化。


目前HuggingFace的Transformers库已经集成了DeepSpeed框架,只需要配置ZeRO文件即可,下面列出博主常用的一些配置:
(1)ZeRO Stage1:
{
"train_micro_batch_size_per_gpu": "auto",
"zero_optimization": {
"stage": 1,
"cpu_offload": false
},
"fp16": {
"enabled": "auto"
},
"steps_per_print": 1000
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
(2)ZeRO Stage2:
{ "train_micro_batch_size_per_gpu": "auto", "zero_optimization": { "stage": 2 }, "fp16": { "enabled": "auto", "loss_scale": 0, "loss_scale_window": 1000, "initial_scale_power": 16, "hysteresis": 2, "min_loss_scale": 1 }, "steps_per_print": 1000, "optimizer": { "type": "AdamW", "params": { "lr": "auto", "betas": "auto", "eps": "auto", "weight_decay": "auto" } } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
(3)ZeRO Stage3:
{ "fp16": { "enabled": "auto", "loss_scale": 0, "loss_scale_window": 1000, "initial_scale_power": 16, "hysteresis": 2, "min_loss_scale": 1 }, "bf16": { "enabled": "auto" }, "optimizer": { "type": "AdamW", "params": { "lr": "auto", "betas": "auto", "eps": "auto", "weight_decay": "auto" } }, "zero_optimization": { "stage": 3, "offload_optimizer": { "device": "cpu", "pin_memory": true }, "offload_param": { "device": "cpu", "pin_memory": true }, "overlap_comm": true, "contiguous_gradients": true, "sub_group_size": 1e9, "reduce_bucket_size": "auto", "stage3_prefetch_bucket_size": "auto", "stage3_param_persistence_threshold": "auto", "stage3_max_live_parameters": 1e9, "stage3_max_reuse_distance": 1e9, "stage3_gather_16bit_weights_on_model_save": true }, "gradient_accumulation_steps": "auto", "gradient_clipping": "auto", "steps_per_print": 2000, "train_batch_size": "auto", "train_micro_batch_size_per_gpu": "auto", "wall_clock_breakdown": false }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
基于HuggingFace的Transformer库在使用时,可直接指定配置文件即可,例如:
–deepspeed=./ds_config_fp16_z1.json \
四、Torch FSDP + CPU Offloading
Fully Sharded Data Paralle(FSDP)和 DeepSpeed 类似,均通过 ZeRO 等分布优化算法,减少内存的占用量。其将模型参数,梯度和优化器状态分布至多个 GPU 上,而非像传统的分布式训练在每个GPU上保留完整副本。
CPU offload 则允许在一个 back propagation 中,将参数动态地在GPU和CPU之间相互转移,从而节省GPU显存。
Huggingface 这篇博文解释了 ZeRO 的大致实现方法:https://huggingface.co/blog/zero-deepspeed-fairscale
借助 torch 实现 FSDP,只需要将 model 用 FSDPwarp 一下;同样,cpu_offload 也只需要一行代码:https://pytorch.org/blog/introducing-pytorch-fully-sharded-data-parallel-api/
在这个可以查看 FSDP 支持的模型:https://pytorch.org/docs/stable/fsdp.html
在 Huggingface Transformers 中使用 Torch FSDP:https://huggingface.co/docs/transformers/v4.27.2/en/main_classes/trainer#transformers.Trainin
五、3D并行
上述降到的DeepSpeed、FSDP等都是数据并行,事实上也有模型并行以及流水线并行。关于3D并行的方法可参考文献:https://zhuanlan.zhihu.com/p/617087561
六、INT8量化
深度学习模型量化是一个面向模型参数的显存优化技术,其与FP16比较类似,都是为了损失一些精度来降低空间。但不同于FP16的是,INT8量化是一种间接的精度转换方法。在介绍INT8量化之前,需要引入一些基本概念:
- 定点数:常用的定点数有两种表示形式:如果小数点位置约定在最低数值位的后面,则该数只能是定点整数;如果小数点位置约定在最高数值位的前面,则该数只能是定点小数。
- 浮点数:在存储时,一个浮点数所占用的存储空间被划分为两部分,分别存放尾数和阶码。尾数部分通常使用定点小数方式,阶码则采用定点整数方式。尾数的长度影响该数的精度,而阶码则决定该数的表示范围。
为了节省内存,计算机中数值型数据的小数点的位置是隐含的,且小数点的位置既可以是固定的,也可以是变化的。
如果小数点的位置事先已有约定,不再改变,此类数称为“定点数”。相比之下,如果小数点的位置可变,则称为“浮点数”。
> 对称量化(Scale Quantization)
这里我们用
r
r
r表示浮点实数,以及最大最小值
r
m
a
x
,
r
m
i
n
r_{max}, r_{min}
rmax,rmin,
q
q
q 表示量化后的定点整数,其最大最小值为
q
m
a
x
,
q
m
i
n
q_{max}, q_{min}
qmax,qmin(在INT8中,最大最小值为-128, 127),
S
S
S表示量化因子(scale),即由浮点数到整型数的比例,
Z
Z
Z表示浮点数中0对应量化后的整型数。
当
r
m
a
x
=
r
m
i
n
=
α
r_{max}=r_{min}=\alpha
rmax=rmin=α时,则为对称量化,此时则有:
S
=
2
a
q
m
a
x
−
q
m
i
n
S=\frac{2a}{q_{max} - q_{min}}
S=qmax−qmin2a
因为是对称量化,所以浮点数0对应的定点整型数也是0,即:
Z
=
0
Z=0
Z=0
则对于浮点数
r
r
r,其量化后的结果是
q
=
r
o
u
n
d
(
r
S
)
q=round(\frac{r}{S})
q=round(Sr);
对于一个整型数,其反量化后的结果是
r
=
S
q
r=Sq
r=Sq。
对称量化的优缺点:
- 优势:推理速度快,量化方式简单;
- 缺点:对于一些特殊的值(例如激活函数后的值),往往均大于0,此时会浪费掉INT8的一些空间,使得量化后的结果不均匀。
> 非对称量化(Affine Quantization)
这里我们用
r
r
r表示浮点实数,以及最大最小值
r
m
a
x
,
r
m
i
n
r_{max}, r_{min}
rmax,rmin,
q
q
q 表示量化后的定点整数,其最大最小值为
q
m
a
x
,
q
m
i
n
q_{max}, q_{min}
qmax,qmin(在INT8中,最大最小值为-128, 127),
S
S
S表示量化因子(scale),即由浮点数到整型数的比例,
Z
Z
Z表示浮点数中0对应量化后的整型数。因此有:
S
=
r
m
a
x
−
r
m
i
n
q
m
a
x
−
q
m
i
n
S=\frac{r_{max} - r_{min}}{q_{max} - q_{min}}
S=qmax−qminrmax−rmin
Z = r o u n d ( q m a x − r m a x S ) Z=round(q_{max} - \frac{r_{max}}{S}) Z=round(qmax−Srmax)
对于浮点数
r
r
r,其量化后的结果是
q
=
r
o
u
n
d
(
r
S
+
Z
)
q=round(\frac{r}{S} + Z)
q=round(Sr+Z);
对于一个整型数,其反量化后的结果是
r
=
S
(
q
−
Z
)
r=S(q-Z)
r=S(q−Z)。
量化过程中,由于存在round算子,因此会造成精度损失,但是反量化不会造成精度损失;
浮点数0不存在精度损失。
(1)Absmax Quantization(最大量化)
该方法的一个典型的是absmax quantization技术。将一个FP32(单精度4字节)的float类型数据转换为INT8。由于INT8只有-127~127,因此可以通过对FP32值乘以一个量化因子,将浮点数转换为整型数。如下所示:
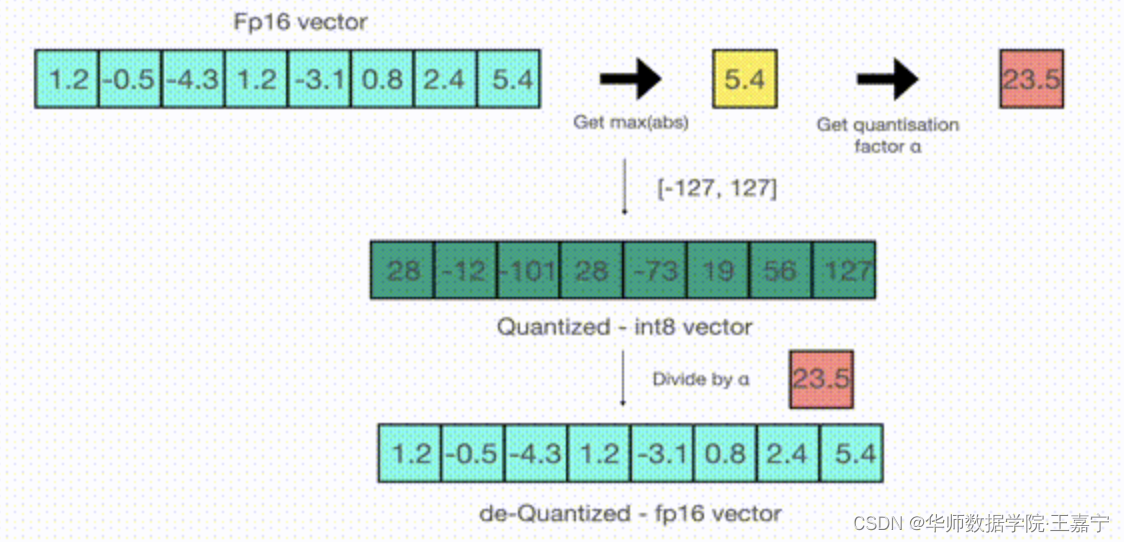
给定一个数组,首先找到该数组中的最大值5.4,然后计算127/5.4=23.5,因此量化因子则为23.5(相当于当前浮点数中最大值放大至-127~127区间内的最大值)。数组中的数乘以量化因子得到的值进行四舍五入估计,即可得到整型数组。
解码时,则将整型数除以量化因子即可。由于期间进行了四舍五入估计,因此量化时会有损失。

(2)基于threshold的量化(量化裁剪)
在浮点数范围内,设置两个阈值,记作
l
l
l和
u
u
u(
l
<
u
l<u
l<u),因此当给定一个浮点数
x
x
x时,可以定义一个裁剪函数:

只保留在区间
[
l
,
r
]
[l, r]
[l,r]范围内的浮点数,其余的则抛弃。
该方法又称为饱和量化,由于通过阈值去掉了一些不重要的元素,可以有效解决不均匀问题。

当浮点数的分布均匀时,absmax量化精度损失较小。但当浮点数分布不均匀时,按照最大最小值映射,则实际有效的int8动态范围就更小了,精度损失变大。
因此,如果将最大值换为阈值,即超出阈值的部分舍去,在阈值范围内的进行量化,可以降低精度误差。
因此核心的问题是如何寻找最优的阀值T使得精度的损失最小。通过实验发现,在range和precision之间的trade-off关系如下图所示:
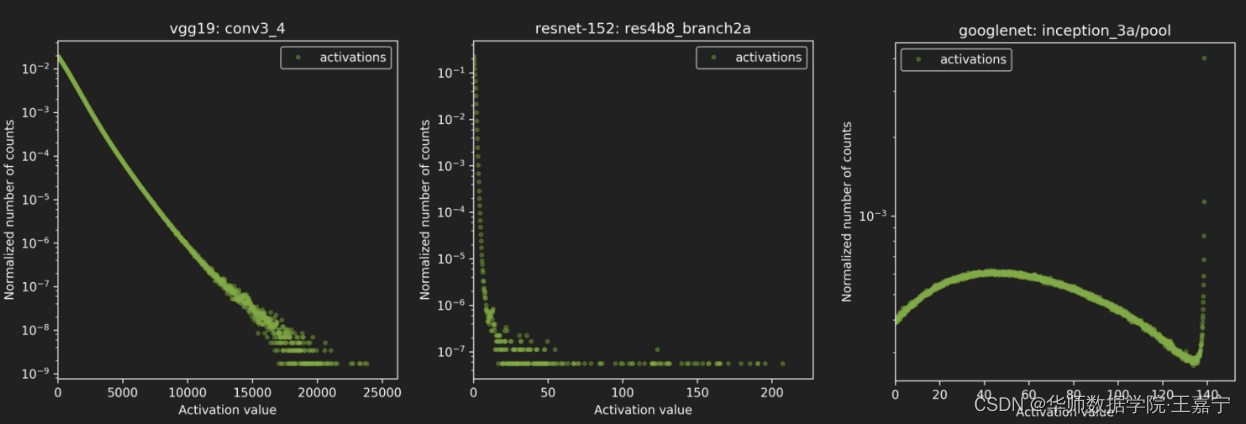
NVIDIA选择的是KL-divergence实现量化校准,其实就是相对熵,那为什么要选择相对熵呢?而不是其他的别的什么呢?因为相对熵表述的就是两个分布的差异程度,放到我们的情境里面来就是INT8量化前后两个分布的差异程度,差异最小就是最好的了。因此问题转换为求相对熵的最小值!
NVIDIA的量化校准流程如下:
- 收集激活值的直方图;
- 基于不同的阀址产生不同的量化分布;
- 然后计算每个分布与原分布的相对熵,然后选择KL散度最小的一个。
> 量化感知训练(Quantization-aware Training)
上述讲到的是模型推理过程中使用INT8量化,可以加速推理速度。INT8依然也可以用在训练过程中。
在训练过程中引入伪量化的操作,用于模拟量化过程带来的误差(这一框架无论在resnet这种大模型,还是mobilenet这种本身比较精简的网络上效果都不错)。
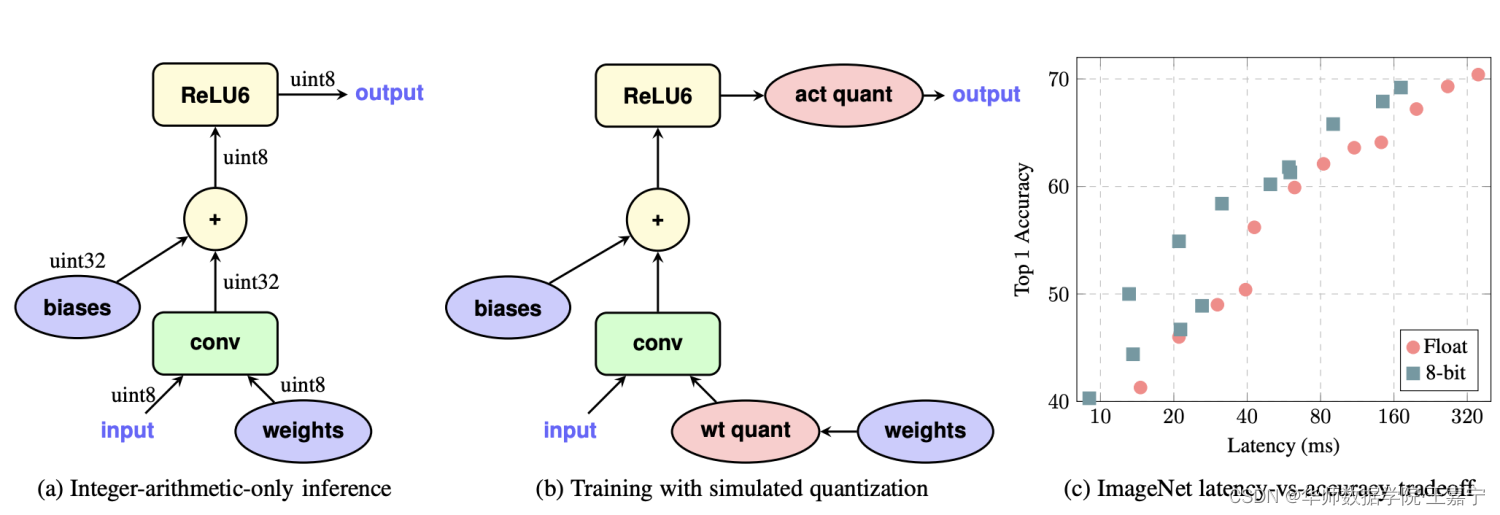
伪量化是指将模拟量化操作引入训练过程中,如上图(b),在每个weight的输入后与output的输出前进行伪量化,将浮点量化到定点整型数,再反量化成浮点,用round过程中所产生的误差的浮点值进行前向运算。
- 伪量化的操作可以使权值、激活值的分布更加均匀,也就是方差更小;
- 相比直接进行后量化的精度损失能更小;
- 能够控制每层的输出在一定范围内,对溢出处理更有帮助;
- 值得注意的是,量化训练中都是采用浮点运算来模拟定点运算,所以训练过程中的量化结果与真实量化结果是有差异的。
相关文献:
https://zhuanlan.zhihu.com/p/509353790
https://zhuanlan.zhihu.com/p/58182172
其他常用的量化方法:
- PACT:https://arxiv.org/abs/1805.06085v2
- Dorefa:(PDF) DoReFa-Net: Training Low Bitwidth Convolutional Neural Networks with Low Bitwidth Gradients (researchgate.netL
- LSQ:Learned Step Size Quantization
- LSQ+:LSQ+: Improving low-bit quantization through learnable offsets and better initialization
类ChatGPT模型量化:
- GPTQ算法
- GPTQ-for-LLaMa
七、参数有效性学习
针对参数层面上的优化还有参数有效性学习(Parameter-Efficient Learning,PEL)。参数有效性学习旨在训练过程中指定少量参数参与梯度的计算和更新,从而在梯度和优化器参数上降低显存占用。
参数有效性学习有很多经典的方法,比如Adapter-tuning、Prefix-tuning、P-tuning、LoRA、BitFit等。本部分主要介绍LoRA方法,因为在很多类ChatGPT的训练中都采用LoRA进行参数有效性训练。
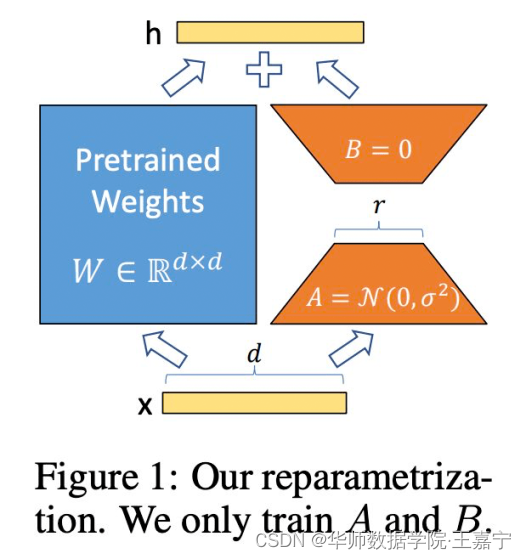
如上图所示,蓝色部分为原始的模型参数,其将输入
x
x
x通过一个FC层映射到
h
h
h。然而矩阵
W
∈
R
d
×
d
W\in\mathbb{R}^{d\times d}
W∈Rd×d的训练参数量为
d
×
d
d\times d
d×d。通过添加一个LORA层(红色部分),将输入
x
x
x先映射到低纬度空间,再映射回
d
d
d维度,此时需要的参数量只有
2
d
×
r
2d\times r
2d×r,其中
r
r
r为LORA的秩。在训练时,只需要对红色部分的参数进行训练和梯度计算保存,因此大大降低了训练过程中的开销。
引入LORA部分的参数,并不会在推理阶段加速,因为在前向计算的时候,红色部分的参数还是需要参与计算的,因此推理阶段应该比原来的计算量增大一点。
接下来给出采用LoRA进行训练的案例,例如选择OPT-6.7B模型进行参数有效性训练时,可以借助HuggingFace PEFT库实现:
原文https://github.com/huggingface/peft/blob/main/examples/int8_training/Finetune_opt_bnb_peft.ipynb
使用PEFT库进行训练代码:
import os os.environ["CUDA_VISIBLE_DEVICES"] = "0" import torch import torch.nn as nn import bitsandbytes as bnb import transformers from datasets import load_dataset from transformers import AutoTokenizer, AutoConfig, AutoModelForCausalLM from peft import prepare_model_for_int8_training, LoraConfig, get_peft_model # 正常地加载大模型参数 model = AutoModelForCausalLM.from_pretrained( "facebook/opt-6.7b", load_in_8bit=True, device_map="auto", ) # 加载tokenizer tokenizer = AutoTokenizer.from_pretrained("facebook/opt-6.7b") # 将大模型参数进行INT8量化 model = prepare_model_for_int8_training(model) # 配置Parameter-efficient LORA config = LoraConfig( r=16, lora_alpha=32, target_modules=["q_proj", "v_proj"], lora_dropout=0.05, bias="none", task_type="CAUSAL_LM" ) # 获得增加LORA的新模型 model = get_peft_model(model, config) # 加载数据 data = load_dataset("Abirate/english_quotes") data = data.map(lambda samples: tokenizer(samples["quote"]), batched=True) # 获得Trainer trainer = transformers.Trainer( model=model, train_dataset=data["train"], args=transformers.TrainingArguments( per_device_train_batch_size=4, gradient_accumulation_steps=4, warmup_steps=100, max_steps=200, learning_rate=2e-4, fp16=True, logging_steps=1, output_dir="outputs", ), data_collator=transformers.DataCollatorForLanguageModeling(tokenizer, mlm=False), ) # 模型训练 model.config.use_cache = False # silence the warnings. Please re-enable for inference! trainer.train()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
LoRA涉及到如下一些配置:

在推理阶段,只需要加载LoRA的参数,并集成到原始的OPT-6.7B模型中即可,实现如下:
import torch
from peft import PeftModel, PeftConfig
from transformers import AutoModelForCausalLM, AutoTokenizer
peft_model_id = "ybelkada/opt-6.7b-lora" # 他人针对OPT-6.7B训练好的LORA参数
config = PeftConfig.from_pretrained(peft_model_id)
model = AutoModelForCausalLM.from_pretrained(
config.base_model_name_or_path, return_dict=True, load_in_8bit=True, device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path)
# 将原始的OPT模型与LORA参数合并
model = PeftModel.from_pretrained(model, peft_model_id)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
八、混合专家训练
混合专家训练(Mixed-of Experts)也是一个比较常用的大模型训练技术,其典型代表是Switch-Transformer模型,如下图所示:
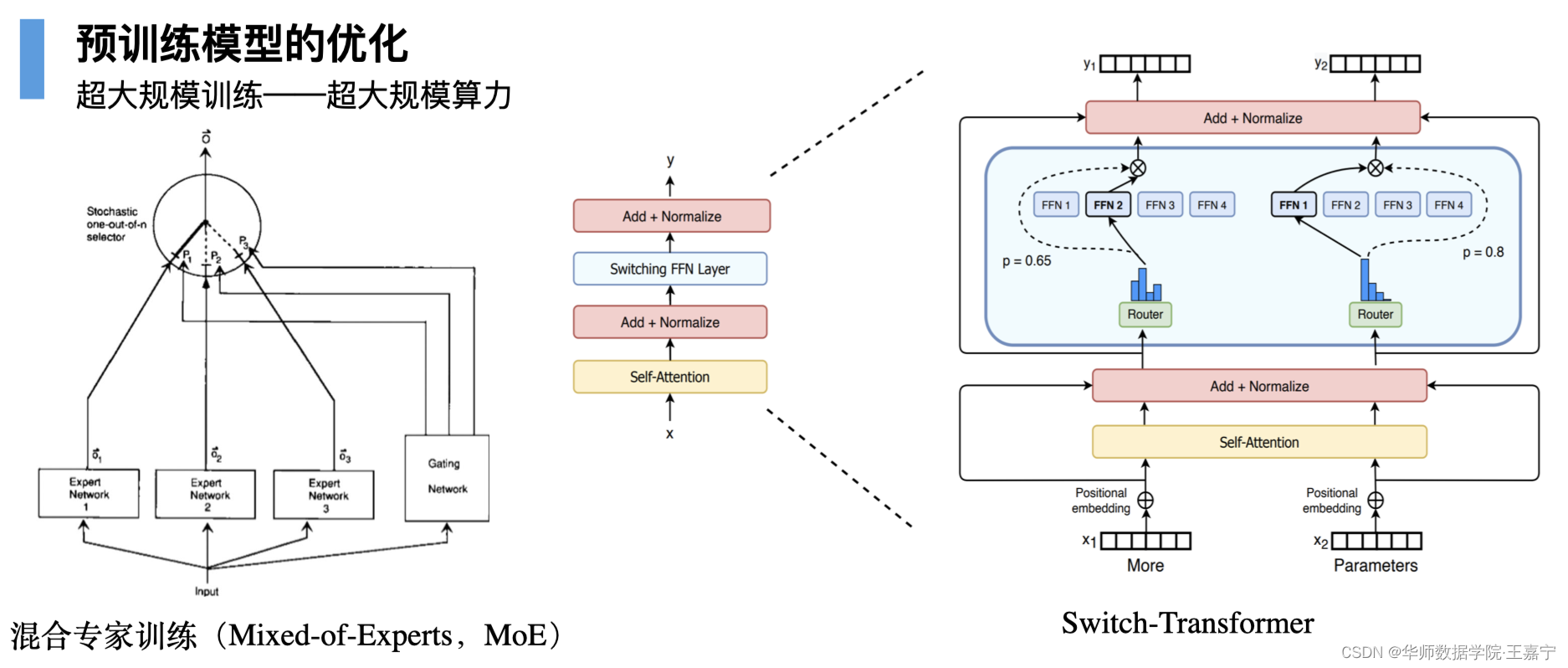
混合专家是一种比较古老的专家系统方法,对于一个决策问题,交给众多专家进行决策投票,根据投票的结果来进行加权求和实现最终决策。在预训练中,则采用了这种思想。
上图中展示了MoE的单层结构,其中包括一个router和若干个expert。router负责决定给每个expert的权重,并制定权重最高的expert作为当前数据进行前后向传播的路由。例如上图中的FeedForward参数有4个,分别指定了FFN2和FFN1作为当前Batch的路由,此时只会对FFN2和FFN1进行参数更新,而其余的参数则固定不变。
因此可以发现,MoE是一种变相的参数有效性训练方法,只不过不同于LoRA等方法,MoE所引入的参数只是控制路由的,且在推理阶段不再使用router,因此对具体的模型推理能力并不起作用。
九、梯度累积
梯度累积是一个比较简单的优化技术,其从Batch size的层面来降低显存占用的。一般情况下,显存的占用直接受到输入数据的影响,包括Batch size、Sequence length等,如果显存溢出,我们最直接的做法就是将Batch size调低。但是对于预训练和指令微调时,扩大Batch size是提高模型训练效果的重要因素,降低Batch size可能会降低模型的效果。
为了不降低Batch size,可以采用梯度累积的方法。梯度累积是指在前向传播之后所计算梯度并不立刻用于参数更新,而是接着继续下一轮的前向传播,每次计算的梯度会暂时存储下来,待在若干次前向传播之后,一并对所有梯度进行参数更新。因此梯度累积相当于是拿时间换空间。
HuggingFace的Transformers库中也实现了梯度累积方法,只需要调用如下参数即可:
–gradient_accumulation_steps=2
例如上面参数“2”的意思是累积两轮的前向传播后计算的梯度值,此时Batch size相当于扩大了1倍,同时训练的总耗时也大约扩大了1倍。
十、梯度检查点(Gradient Checkpointing)
回顾一下在“DeepSpeed分布式训练”章节中普通的分布式数据并行梯度更新的过程,通常是在前向传播过程中,顺便把每一个参数的梯度预先计算好,并存储下来的。所以在训练过程中,可以直接从显存中提取对应参数的梯度,而无需从模型最顶层依次进行链式推导,起到加速参数更新的作用。但是这种机制是拿空间换时间。现在空间不过,我们必须要再把空间换回来。
梯度检查点的工作原理即使把时间换空间是,即在反向传播时重新计算深度神经网络的中间值。
先前的方法是提前存储每个神经元的对应的反向传播过程中需要计算的梯度等信息;
gradient checkpoint旨在不去存储,而是重新计算,从而避免了占用显存,但损失了时间。
在 torch 中使用:把 model 用一个 customize 的 function 包装一下即可,详见:Explore Gradient-Checkpointing in PyTorch
在 Huggingface Transformers 中使用:gradient-checkpointing
十一、Flash Attention
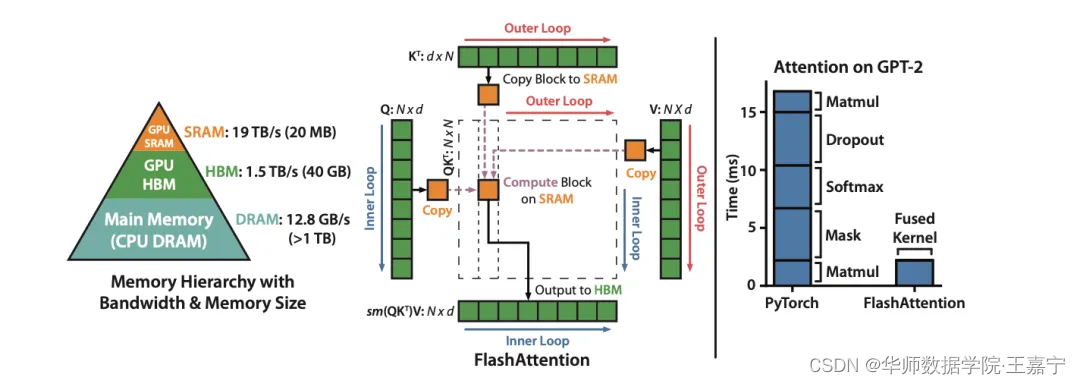
最后介绍一个从算法层面上提高显存优化的方法,其由斯坦福大学提出的方法,论文为FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness。
我们知道Self-attention的计算公式是:
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
S
o
f
t
m
a
x
(
Q
K
T
d
k
)
V
Attention(Q, K, V)=Softmax(\frac{QK^T}{\sqrt{d_k}})V
Attention(Q,K,V)=Softmax(dk
QKT)V
算子主要由“matmul + div + masking + softmax + matmul”几个组成。当Sequence length比较大的时候(例如2048,甚至是GPT-4中的32K),Attention矩阵会是 O ( n 2 ) O(n^2) O(n2)的空间复杂度,如果在单卡上进行计算,会大量占用显存。
Flash Attention则是让Attention的几个算子能够通过分块并行地进行计算,如果这4个算子都能够分块处理,那么就可以实现这一目的,因此下面一一介绍各个算子的分块处理过程。
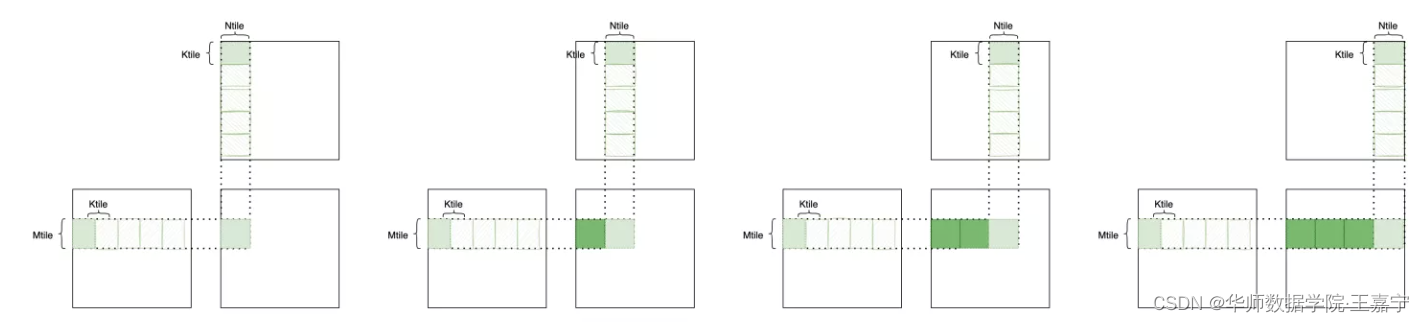
(1)
Q
K
T
QK^T
QKT:矩阵乘积算子,可以采用分块矩阵的方法进行并行计算。如下图所示,两个矩阵相乘,可以用分块矩阵分别在矩阵
Q
Q
Q的行、
K
T
K^T
KT的列(即
K
K
K的行)上进行滑动,并将滑动的每个分块结果累加即可:
(2) Q K T d k \frac{QK^T}{\sqrt{d_k}} dk QKT:这一步需要进行除法操作,因为除法是element-wise的操作,所以非常容易进行分块处理;
(3) S o f t m a x ( Q K T d k ) V Softmax(\frac{QK^T}{\sqrt{d_k}})V Softmax(dk QKT)V:这一步是关键之处,因为涉及到Softmax和乘法操作。特别地,Softmax既不是乘法,也不是element-wise操作,而是对矩阵 Q K T d k \frac{QK^T}{\sqrt{d_k}} dk QKT的每一行进行归一化,因此需要对该算子单独设计并行处理策略。斯坦福大学团队提出Softmax Tiling策略实现Softmax和乘法算子的并行合并处理。
譬如我们要计算数组x的softmax。然后我们每次只能算2个数,我们先算第1、2个数的softmax,即
cur_sum = exp(x[0]) + exp(x[1])
y[0:2] = x[0:2] / cur_sum
pre_sum = cur_sum
然后我们算第3、4个数的softmax,这时候cur_sum会被更新,之前的sum在变量pre_sum里,这个时候我们可以通过把之前前两个数的softmax结果除以cur_sum/pre_sum来得到正确的结果。如果softmax后面还跟一个matmul的话,上次softmax的结果会和D的一个块乘在一起,然后累积起来,这样我们只需要scale这个累积的值就行。依次类推,在每轮循环都把累积的值scale一下,就能incrementally计算softmax或者softmax + matmul的结果。
整个Flash Attention的详细算法流程如下所示:

HuggingFace新版本集成了OpenLLaMA库,其中采用了Flash Attention的训练方法,代码可参考:https://github.com/huggingface/transformers/blob/main/src/transformers/models/open_llama/modeling_open_llama.py
还有更多大模型训练和推理优化技术吗,请分享在评论区~

