
- 1华为官方推荐:学习鸿蒙开发高分好书,这6本能帮你很多!_鸿蒙开发 推荐 书籍
- 2ELF文件中得section(.data .bss .text .altinstr_replacement、.altinstr_aux)_.section .datar, data
- 3ssm的maven坐标_ssm maven 坐标
- 4MySQL存储引擎详解(一)-InnoDB架构_mysql引擎innodb
- 5(一)使用AI、CodeFun开发个人名片微信小程序_ai生成小程序代码
- 6求助:R包安装失败_cannot open compressed file description
- 74款超好用的AI换脸软件,一键视频直播换脸(附下载链接)
- 8【深度学习】激活函数(sigmoid、ReLU、tanh)_sigmoid激活函数
- 9操作系统的程序内存结构 —— data和bss为什么需要分开,各自的作用_为什么分bss和data
- 10记一次 Docker Nginx 自定义 log_format 报错的解决方案_log_format" directive no dyconf_version config in
阿里云开源通义千问多模态大模型 Qwen-VL
赞
踩
Qwen-VL 以通义千问 70 亿参数模型 Qwen-7B 为基座语言模型研发,支持图文输入,具备多模态信息理解能力。在主流的多模态任务评测和多模态聊天能力评测中,Qwen-VL 取得了远超同等规模通用模型的表现。
Qwen-VL 是支持中英文等多种语言的视觉语言(Vision Language,VL)模型,相较于此前的 VL 模型,Qwen-VL 除了具备基本的图文识别、描述、问答及对话能力之外,还新增了视觉定位、图像中文字理解等能力。
用户可从魔搭社区直接下载模型,也可通过阿里云灵积平台访问调用 Qwen-VL 和 Qwen-VL-Chat,阿里云为用户提供包括模型训练、推理、部署、精调等在内的全方位服务。
Qwen-VL 可用于知识问答、图像标题生成、图像问答、文档问答、细粒度视觉定位等场景。
比如,一位不懂中文的外国游客到医院看病,不知怎么去往对应科室,他拍下楼层导览图问 Qwen-VL “骨科在哪层”“耳鼻喉科去哪层”,Qwen-VL 会根据图片信息给出文字回复,这是图像问答能力;再比如,输入一张上海外滩的照片,让 Qwen-VL 找出东方明珠,Qwen-VL 能用检测框准确圈出对应建筑,这是视觉定位能力。


Qwen-VL 是业界首个支持中文开放域定位的通用模型,开放域视觉定位能力决定了大模型 “视力” 的精准度,也即,能否在画面中精准地找出想找的事物,这对于 VL 模型在机器人操控等真实应用场景的落地至关重要。
Qwen-VL 以 Qwen-7B 为基座语言模型,在模型架构上引入视觉编码器,使得模型支持视觉信号输入,并通过设计训练过程,让模型具备对视觉信号的细粒度感知和理解能力。Qwen-VL 支持的图像输入分辨率为 448,此前开源的 LVLM 模型通常仅支持 224 分辨率。在 Qwen-VL 的基础上,通义千问团队使用对齐机制,打造了基于 LLM 的视觉 AI 助手 Qwen-VL-Chat,可让开发者快速搭建具备多模态能力的对话应用。
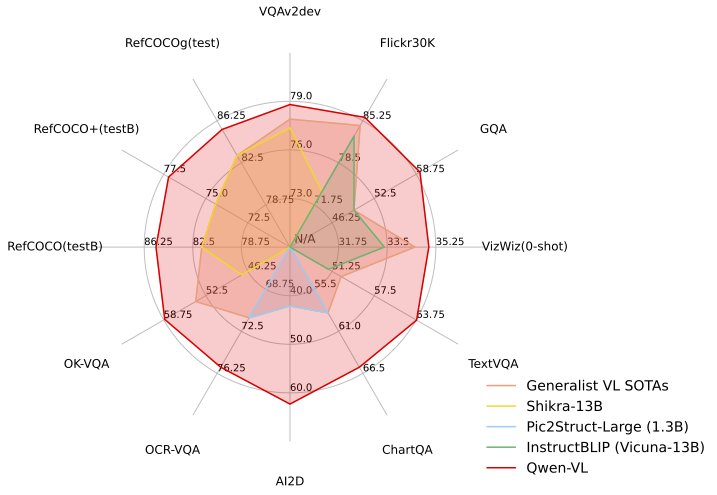
在四大类多模态任务(Zero-shot Caption/VQA/DocVQA/Grounding)的标准英文测评中,Qwen-VL 取得了同等尺寸开源 LVLM 的最好效果。
为了测试模型的多模态对话能力,通义千问团队构建了一套基于 GPT-4 打分机制的测试集 “试金石”,对 Qwen-VL-Chat 及其他模型进行对比测试,Qwen-VL-Chat 在中英文的对齐评测中均取得了开源 LVLM 最好结果。
8 月初,阿里云gnss通义千问 70 亿参数通用模型 Qwen-7B 和对话模型 Qwen-7B-Chat,成为国内首个加入大模型开源行列的大型科技企业。

