
- 1斯坦福AI2021报告出炉!详解七大热点,论文引用中国首超美国
- 2OpenAI 开发系列(七):LLM提示工程(Prompt)与思维链(CoT)_llm 将高层次指令拆分成子任务
- 32. Transformer相关的原理(2.3. 图解BERT)_bertencoder图
- 4adb devices找不到设备的很多原因
- 5pytorch初学笔记(一):如何加载数据和Dataset实战_python dataset
- 6鸿蒙开发,对于前端开发来说,究竟是福是祸呢?_前端 鸿蒙
- 7宇视VM新BS界面配置告警联动上墙
- 8决策树python源码实现(含预剪枝和后剪枝)_def createdatalh(): data = np.array([['青年', '否', '
- 9hive集群搭建
- 10掌握Go语言:Go语言类型转换,解锁高级用法,轻松驾驭复杂数据结构(30)
【大模型信息抽取】KnowLM:知识图谱 + 大模型,实现更有效的信息抽取和知识管理_大模型抽取知识
赞
踩
KnowLM 原理
代码:https://github.com/zjunlp/KnowLM/blob/main/README_ZH.md
目前需要从大量文本中,抽取信息,构建知识图谱,加强和补足大模型的专业能力,避免胡说八道、宽泛模糊问题。
知识图谱 = 实体 + 关系 + 实体
-
实体:现实世界存在的事物,如人名、地名
-
关系:实体之间的关系,如朋友、家
-
举例:小明-电话-xxx,小明-年龄-20,小明-朋友-小张
安利 浙大的开源项目 KnowLM:
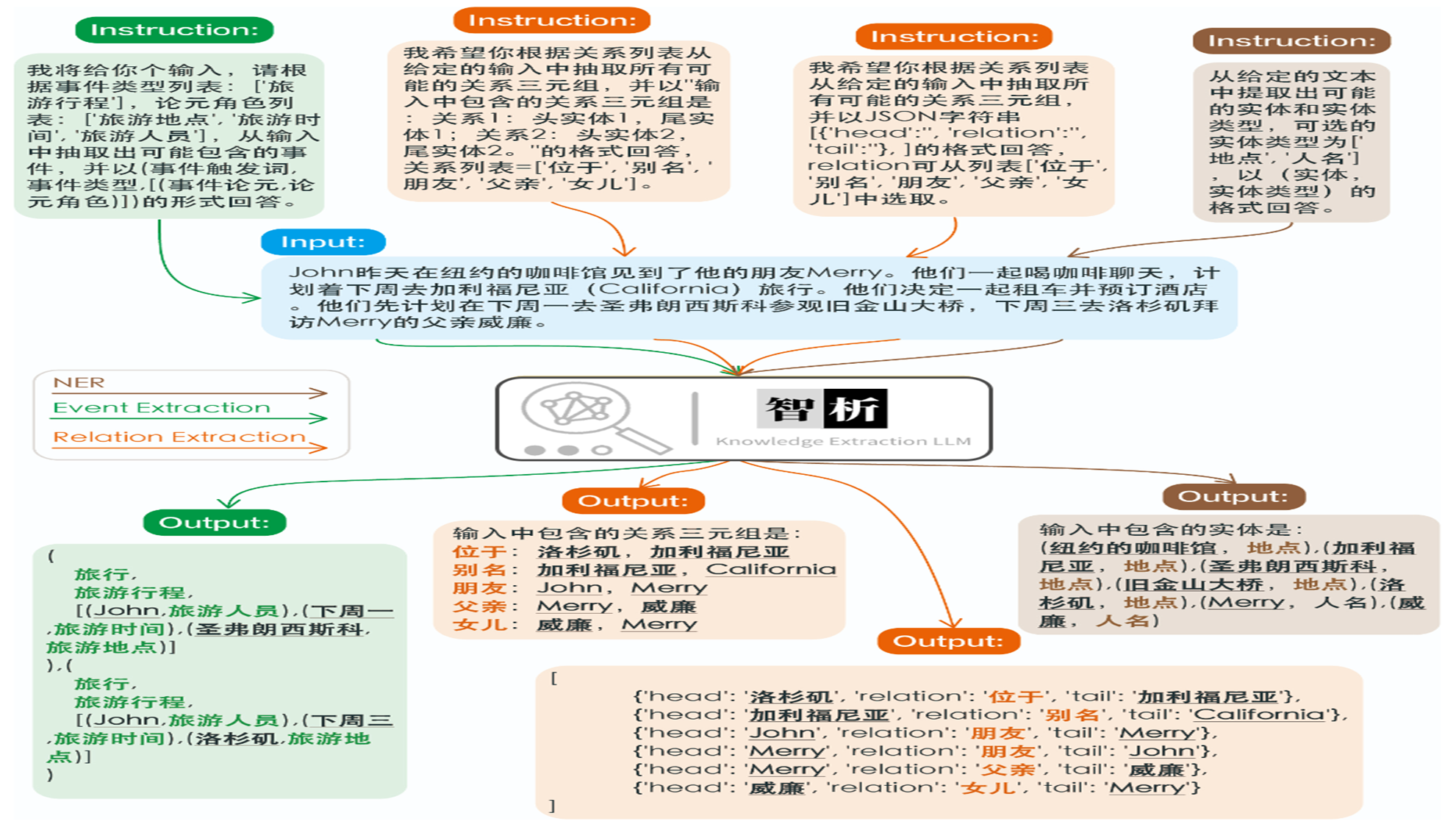
KnowLM 的信息抽取模型,叫 智能分析
- NER 是,实体命名识别(现实世界存在的事物,比如地名、人名)
- Event Extraction 是,事件抽取(哪里发生了什么事情,如旅游)
- Relation Extraction 是,关系抽取(对象之间的关系,如父亲、女儿、朋友)
这个项目是怎么实现的?
-
KnowLM 是使用知识图谱来增强大型语言模型的预训练、推理和可解释性。
-
用知识图谱的结构化数据来提高模型的专业知识和输出质量,同时也用大模型的能力来更新和维护知识图谱本身。
KnowLM 结构图:
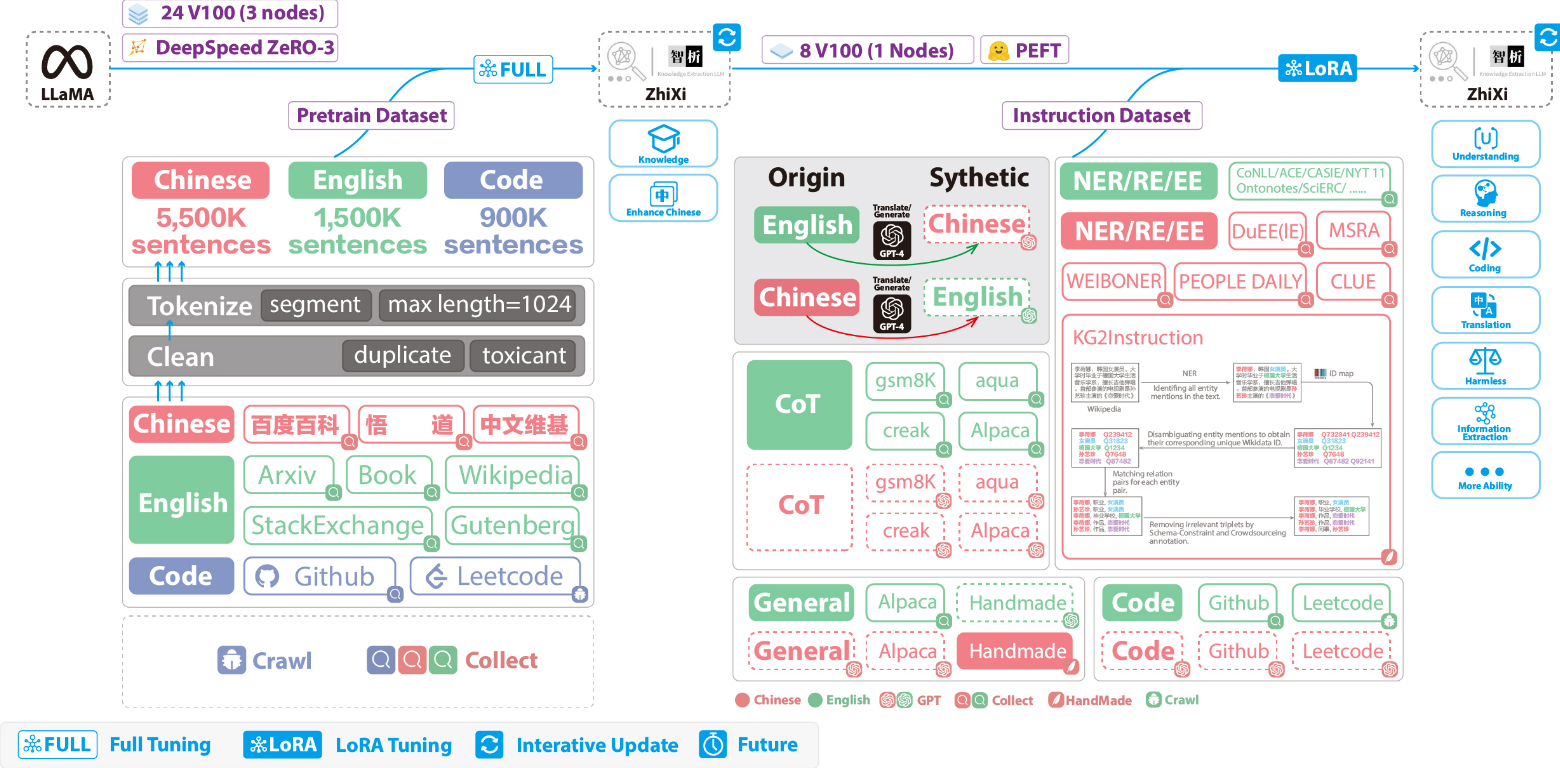
左侧用于预训练的数据集,包括中文(红色)、英文(绿色)、代码(蓝色),以及这些数据的处理步骤,如分词、清洗等。
- 预训练过程详细的数据处理代码和训练代码、完整的训练脚本、详细的训练情况:https://github.com/zjunlp/KnowLM/tree/main/pretrain
右侧更专注于指令数据集,包括实体识别(NER)、关系抽取(RE)、事件抽取(EE)等NLP任务,以及各种中文和英文的数据集。
- 详细的指令微调训练参数、训练脚本:https://github.com/zjunlp/KnowLM/tree/main/finetune/lora
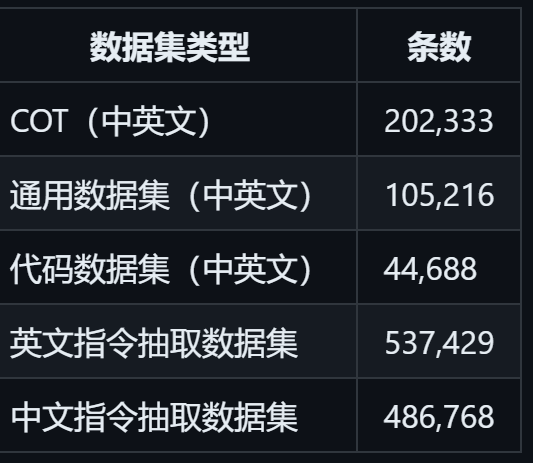
数据量:
在信息抽取(从文本中抽取信息,建立知识图谱),智析 对比 GPT:

在这个例子中,GPT在执行关系抽取任务时存在以下问题:
-
不准确的关系抽取:GPT未能正确识别和提取文本中的关系三元组。它提供的输出可能包含不正确的关系或实体,或者完全缺失了某些关系。
-
不完整的信息提取:GPT在输出结果时,可能未能包含所有相关的信息,导致提供的信息不全面或不具体。
-
不适用的格式:GPT可能没有遵循指定的结构化输出格式,这是关系抽取任务中一个重要的要求,以便于后续的信息整合和知识图谱构建。
与之相比,“智析”这个系统在以下方面显示出了改进:
-
更准确的关系识别:智析能够更准确地识别出文本中的实体和关系,提供更符合预期的关系三元组。
-
完整性:智析提供的输出更完整,覆盖了指令中要求识别的所有相关信息。
-
遵循格式:智析能够根据指定的{s_format}格式提供结构化输出,这对于后续自动化处理和知识图谱的构建是非常有用的。
智析 相比 通用的GPT模型,在准确性、完整性和遵循指定输出格式方面的优势。
KnowLM 应用框架:
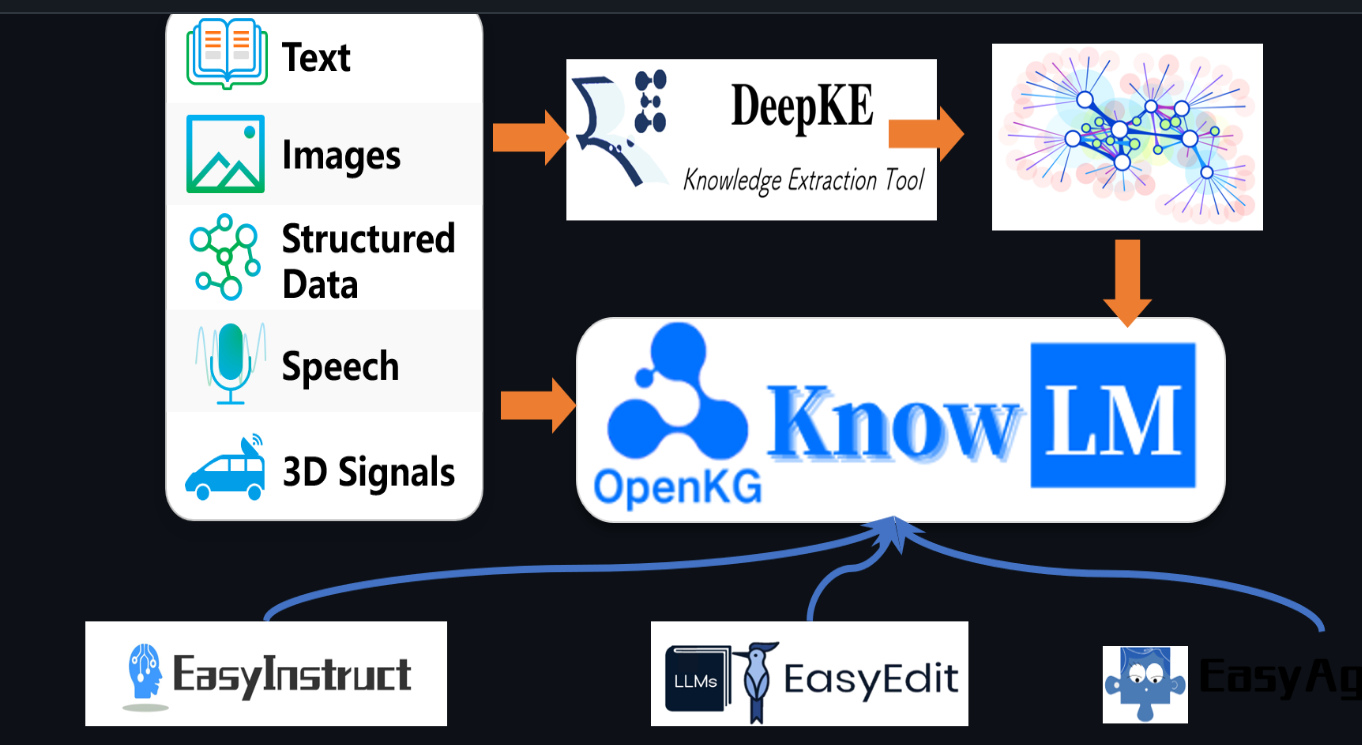
1.知识提示 - EasyInstruct:基于知识图谱等结构化数据的知识提示生成和知识增强约束技术,解决知识抽取和推理问题
2.知识编辑 - EasyEdit:基于知识编辑技术对齐大模型内过时、错误及价值观不正确的知识,解决知识谬误问题 (英文版Tutorial)
3.知识交互 - EasyAgent:基于知识动态交互和反馈实现工具组合学习及多智能体协作,解决大模型具身认知问题 (英文版Tutorial)
KnowLM 部署
跟着教程部署就行:
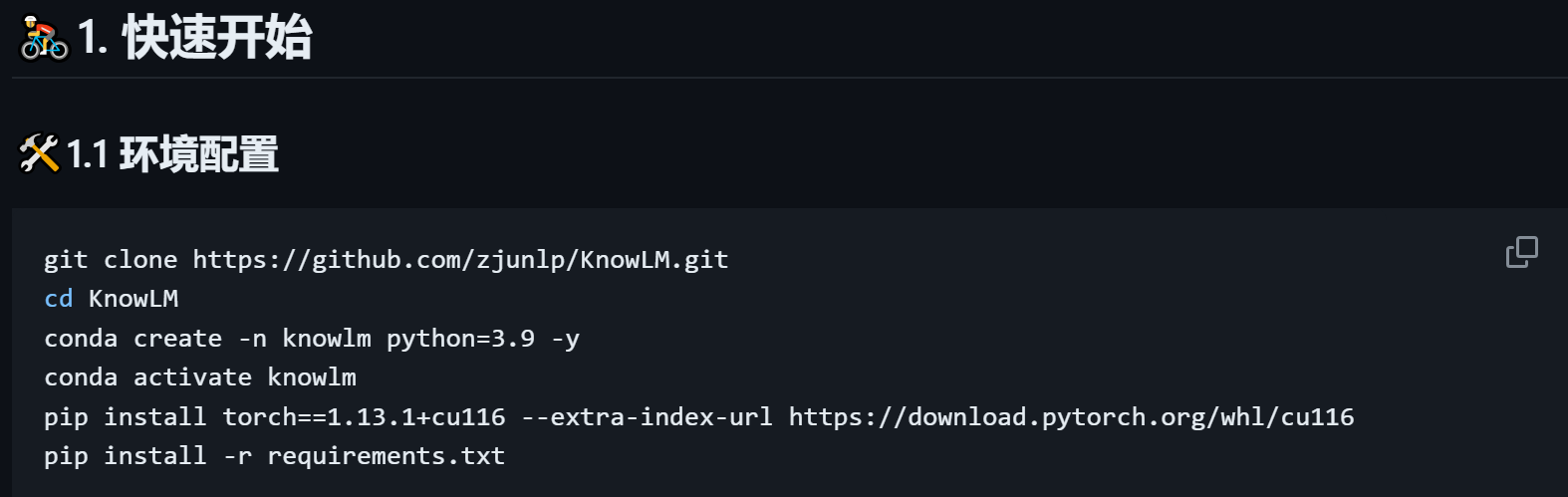
遇到问题在 issues 提问即可:
KnowLM 应用
模板用于构建模型输入的指令,包括三个部分:
- 任务描述:明确定义模型的功能和需要完成的任务,如实体识别、关系抽取、事件抽取等。
- 候选标签列表{s_schema}(可选):定义模型需要抽取的标签类别,如实体类型、关系类型、事件类型等。
- 结构化输出格式{s_format}:指定模型应如何呈现它提取的结构化信息。
指定候选标签列表的模板:
命名实体识别(NER):您是专门从事实体抽取的专家。 请根据候选实体类型列表{s_schema},从下面的输入中提取可能的实体, 如果某个实体不存在,请输出NAN。请按照{s_format}格式回答。 关系抽取(RE):您是抽取关系三元组的专家。 请根据候选关系列表{s_schema},从下面的输入中提取可能的头实体和尾实体,并提供相应的关系三元组。 如果关系不存在,请输出NAN。请以{s_format}格式回答。 事件抽取(EE):您是事件抽取的专家。根据候选事件字典{s_schema},请从下面的输入中提取任何可能的事件。 如果事件不存在,请输出NAN。请以{s_format}格式回答。 事件类型抽取(EET):作为事件分析专家,您需要审查输入并根据事件类型目录{s_schema}确定可能的事件。 所有答案应基于{s_format}格式。如果事件类型不匹配,请标记为NAN。 事件论元抽取(EEA):您是事件论元抽取的专家。 鉴于事件字典{s_schema1},以及事件类型和触发词{s_schema2},请从以下输入中提取可能的论元。 如果事件论元不存在,请输出NAN。请以{s_format}格式回答。

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
举例:
应用:
要使用这些模板构建知识图谱,我们需要从文本中抽取实体、关系和事件。以下是一个如何应用这些模板的例子:
示例输入文本:
小明和小红是同学,他们都在北京大学读书。
小明的专业是计算机科学,而小红的专业是金融学。
他们经常一起在图书馆学习。
上周,小明和小红参加了学校的编程比赛并获得了第一名。
- 1
- 2
- 3
- 4
1. 命名实体识别(NER)
使用NER模板识别文本中的实体。
候选实体类型列表(s_schema)可能包括:人名、地点、学校、专业等。
结构化输出格式(s_format)可以选择为:“(实体类型: 实体)”。
示例输出(NER):
- (人名: 小明)
- (人名: 小红)
- (地点: 北京大学)
- (专业: 计算机科学)
- (专业: 金融学)
- (事件: 编程比赛)
2. 关系抽取(RE)
接下来使用RE模板抽取实体间的关系。
候选关系列表(s_schema)可能包括:同学、读书于、专业是、一起学习、参加比赛、获得名次等。
结构化输出格式(s_format)可以为:“{‘head’: ‘头实体’, ‘relation’: ‘关系’, ‘tail’: ‘尾实体’}”。
示例输出(RE):
- {‘head’: ‘小明’, ‘relation’: ‘同学’, ‘tail’: ‘小红’}
- {‘head’: ‘小明’, ‘relation’: ‘读书于’, ‘tail’: ‘北京大学’}
- {‘head’: ‘小明’, ‘relation’: ‘专业是’, ‘tail’: ‘计算机科学’}
- {‘head’: ‘小红’, ‘relation’: ‘专业是’, ‘tail’: ‘金融学’}
- {‘head’: ‘小明’, ‘relation’: ‘参加比赛’, ‘tail’: ‘编程比赛’}
- {‘head’: ‘小明’, ‘relation’: ‘获得名次’, ‘tail’: ‘第一名’}
3. 事件抽取(EE)
使用EE模板抽取文本中的事件。
候选事件字典(s_schema)可能包括:学习、比赛等。
结构化输出格式(s_format)可以为:“事件: {事件类型}”。
示例输出(EE):
- 事件: 学习
- 事件: 比赛
通过这样的过程,我们可以从文本中抽取出实体、关系和事件,构建成一个知识图谱。

