
- 1【故障诊断分析】滚动轴承故障诊断特征提取附Matlab代码
- 2遗传算法原理及其在车辆路径规划中的应用_车辆路径问题遗传算法
- 3英伟达黄仁勋发布GB200,比H100推理能力提高30倍,能耗降低25倍,将AI4S能力做成微服务_数据吞吐推升高速连接器需求;英伟达gb200 nvl72内部互联采用铜缆方案
- 4【深度学习】生成对抗网络(GANs)详解!
- 5突破编程_C++_设计模式(中介者模式)
- 6【论文阅读】Point Transformer解读
- 7深度学习CV八股文_深度学习八股文
- 8无人机摄影测量---倾斜摄影测量原理与关键技术
- 9使用VScode开发ESP8266,PlatformIO开发ESP8266
- 10Uniapp中实战实现左右点击滚动功能_uniapp左右滑动切换页面
yolov8与yolov5网络对比_yolov5、yolov7和yolov8网络结构图
赞
踩
回顾一下YOLOv5,不然没机会了
这里粗略回顾一下,这里直接提供YOLOv5的整理的结构图吧:
- Backbone:CSPDarkNet结构,主要结构思想的体现在C3模块,这里也是梯度分流的主要思想所在的地方;
- PAN-FPN:双流的FPN,必须香,也必须快,但是量化还是有些需要图优化才可以达到最优的性能,比如cat前后的scale优化等等,这里除了上采样、CBS卷积模块,最为主要的还有C3模块(记住这个C3模块哦);
- Head:Coupled Head+Anchor-base,毫无疑问,YOLOv3、YOLOv4、YOLOv5、YOLOv7都是Anchor-Base的,后面会变吗?
- Loss:分类用BEC Loss,回归用CIoU Loss。
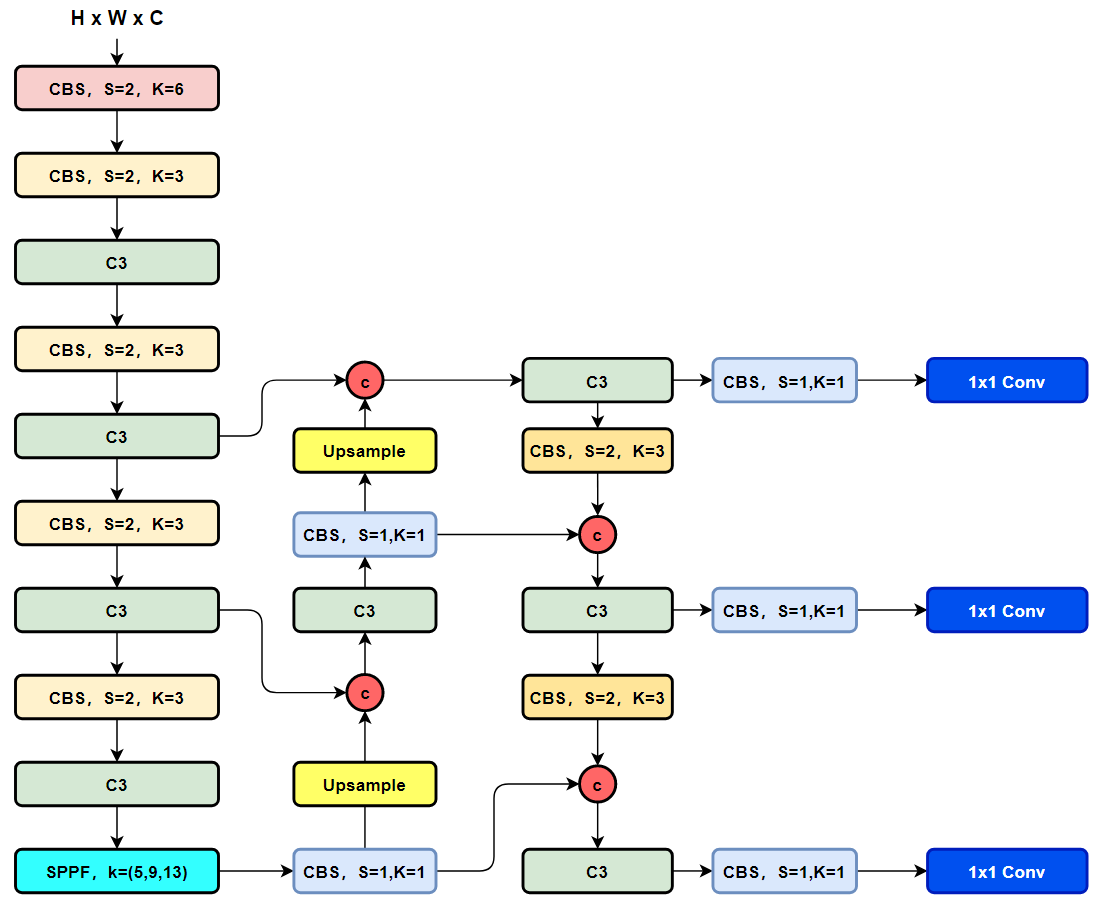
话不多说,直接YOLOv8吧!
直接上YOLOv8的结构图吧,小伙伴们可以直接和YOLOv5进行对比,看看能找到或者猜到有什么不同的地方?

下面就直接揭晓答案吧,具体改进如下:
- Backbone:使用的依旧是CSP的思想,不过YOLOv5中的C3模块被替换成了C2f模块,实现了进一步的轻量化,同时YOLOv8依旧使用了YOLOv5等架构中使用的SPPF模块;
- PAN-FPN:毫无疑问YOLOv8依旧使用了PAN的思想,不过通过对比YOLOv5与YOLOv8的结构图可以看到,YOLOv8将YOLOv5中PAN-FPN上采样阶段中的卷积结构删除了,同时也将C3模块替换为了C2f模块;
- Decoupled-Head:是不是嗅到了不一样的味道?是的YOLOv8走向了Decoupled-Head;
- YOLOv8抛弃了以往的Anchor-Base,使用了Anchor-Free的思想;
- 损失函数:YOLOv8使用VFL Loss作为分类损失,使用DFL Loss+CIOU Loss作为分类损失;
- 样本匹配:YOLOv8抛弃了以往的IOU匹配或者单边比例的分配方式,而是使用了Task-Aligned Assigner匹配方式。
1、C2f模块是什么?与C3有什么区别?
我们不着急,先看一下C3模块的结构图,然后再对比与C2f的具体的区别。针对C3模块,其主要是借助CSPNet提取分流的思想,同时结合残差结构的思想,设计了所谓的C3 Block,这里的CSP主分支梯度模块为BottleNeck模块,也就是所谓的残差模块。同时堆叠的个数由参数n来进行控制,也就是说不同规模的模型,n的值是有变化的。

其实这里的梯度流主分支,可以是任何之前你学习过的模块,比如,美团提出的YOLOv6中就是用来重参模块RepVGGBlock来替换BottleNeck Block来作为主要的梯度流分支,而百度提出的PP-YOLOE则是使用了RepResNet-Block来替换BottleNeck Block来作为主要的梯度流分支。而YOLOv7则是使用了ELAN Block来替换BottleNeck Block来作为主要的梯度流分支。
C3模块的Pytorch的实现如下:
class C3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
下面就简单说一下C2f模块,通过C3模块的代码以及结构图可以看到,C3模块和名字思路一致,在模块中使用了3个卷积模块(Conv+BN+SiLU),以及n个BottleNeck。
通过C3代码可以看出,对于cv1卷积和cv2卷积的通道数是一致的,而cv3的输入通道数是前者的2倍,因为cv3的输入是由主梯度流分支(BottleNeck分支)依旧次梯度流分支(CBS,cv2分支)cat得到的,因此是2倍的通道数,而输出则是一样的。
不妨我们再看一下YOLOv7中的模块:

YOLOv7通过并行更多的梯度流分支,放ELAN模块可以获得更丰富的梯度信息,进而或者更高的精度和更合理的延迟。
C2f模块的结构图如下:
我们可以很容易的看出,C2f模块就是参考了C3模块以及ELAN的思想进行的设计,让YOLOv8可以在保证轻量化的同时获得更加丰富的梯度流信息。

C2f模块对应的Pytorch实现如下:
class C2f(nn.Module):
# CSP Bottleneck with 2 convolutions
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
def forward(self, x):
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
SPPF改进了什么?
这里讲解的文章就很多了,这里也就不具体描述了,直接给出对比图了
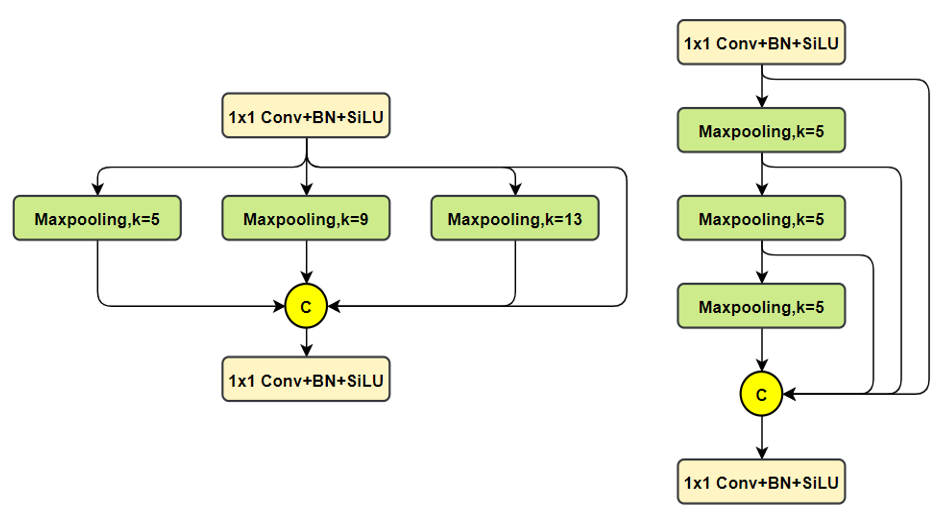
上图中,左边是SPP,右边是SPPF。
PAN-FPN改进了什么?
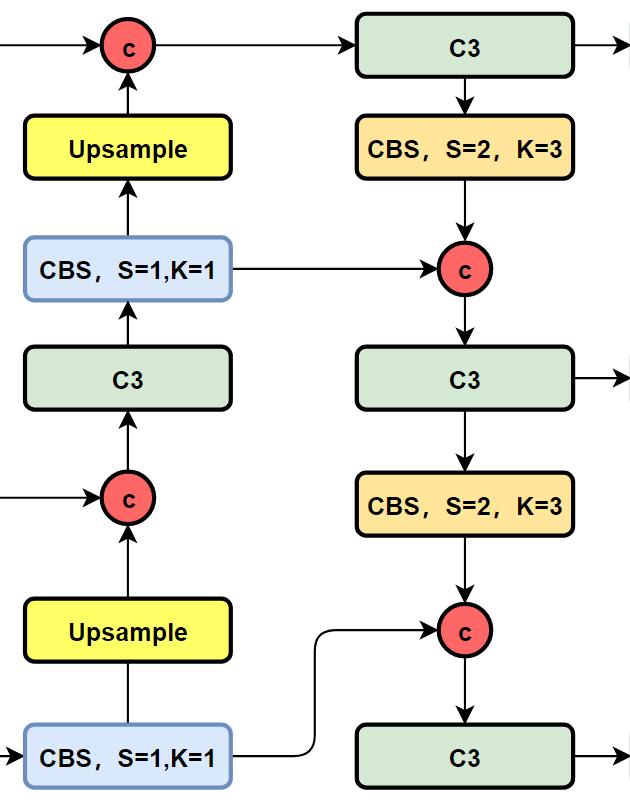
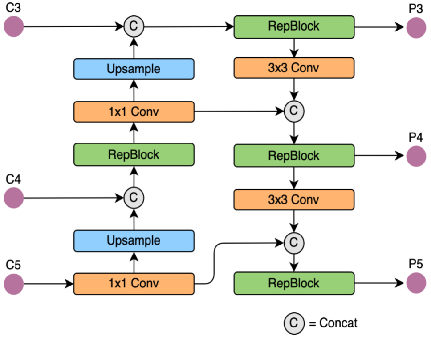
我们先看一下YOLOv5以及YOLOv6的PAN-FPN部分的结构图:
YOLOv5的Neck部分的结构图如下:
YOLOv6的Neck部分的结构图如下:
我们再看YOLOv8的结构图:
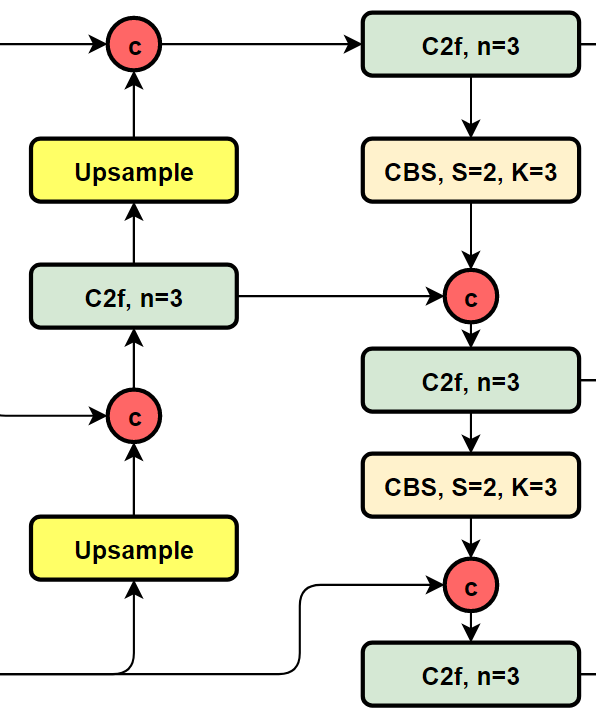
可以看到,相对于YOLOv5或者YOLOv6,YOLOv8将C3模块以及RepBlock替换为了C2f,同时细心可以发现,相对于YOLOv5和YOLOv6,YOLOv8选择将上采样之前的1×1卷积去除了,将Backbone不同阶段输出的特征直接送入了上采样操作。
Head部分都变了什么呢?
先看一下YOLOv5本身的Head(Coupled-Head):

而YOLOv8则是使用了Decoupled-Head,同时由于使用了DFL 的思想,因此回归头的通道数也变成了4*reg_max的形式:

对比一下YOLOv5与YOLOv8的YAML

损失函数
对于YOLOv8,其分类损失为VFL Loss,其回归损失为CIOU Loss+DFL的形式,这里Reg_max默认为16。
VFL主要改进是提出了非对称的加权操作,FL和QFL都是对称的。而非对称加权的思想来源于论文PISA,该论文指出首先正负样本有不平衡问题,即使在正样本中也存在不等权问题,因为mAP的计算是主正样本。
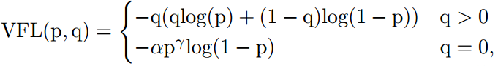
q是label,正样本时候q为bbox和gt的IoU,负样本时候q=0,当为正样本时候其实没有采用FL,而是普通的BCE,只不过多了一个自适应IoU加权,用于突出主样本。而为负样本时候就是标准的FL了。可以明显发现VFL比QFL更加简单,主要特点是正负样本非对称加权、突出正样本为主样本。
针对这里的DFL(Distribution Focal Loss),其主要是将框的位置建模成一个 general distribution,让网络快速的聚焦于和目标位置距离近的位置的分布。
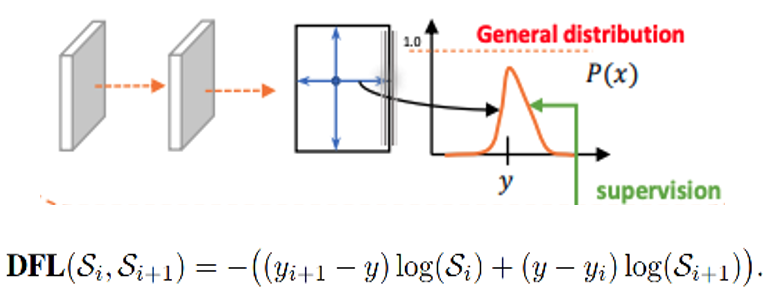
DFL 能够让网络更快地聚焦于目标 y 附近的值,增大它们的概率;
DFL的含义是以交叉熵的形式去优化与标签y最接近的一左一右2个位置的概率,从而让网络更快的聚焦到目标位置的邻近区域的分布;也就是说学出来的分布理论上是在真实浮点坐标的附近,并且以线性插值的模式得到距离左右整数坐标的权重。
样本的匹配
标签分配是目标检测非常重要的一环,在YOLOv5的早期版本中使用了MaxIOU作为标签分配方法。然而,在实践中发现直接使用边长比也可以达到一阿姨给你的效果。而YOLOv8则是抛弃了Anchor-Base方法使用Anchor-Free方法,找到了一个替代边长比例的匹配方法,TaskAligned。
为与NMS搭配,训练样例的Anchor分配需要满足以下两个规则:
- 正常对齐的Anchor应当可以预测高分类得分,同时具有精确定位;
- 不对齐的Anchor应当具有低分类得分,并在NMS阶段被抑制。
基于上述两个目标,TaskAligned设计了一个新的Anchor alignment metric 来在Anchor level 衡量Task-Alignment的水平。并且,Alignment metric 被集成在了 sample 分配和 loss function里来动态的优化每个 Anchor 的预测。
Anchor alignment metric:
分类得分和 IoU表示了这两个任务的预测效果,所以,TaskAligned使用分类得分和IoU的高阶组合来衡量Task-Alignment的程度。使用下列的方式来对每个实例计算Anchor-level 的对齐程度:

s 和 u 分别为分类得分和 IoU 值,α 和 β 为权重超参。
从上边的公式可以看出来,t 可以同时控制分类得分和IoU 的优化来实现 Task-Alignment,可以引导网络动态的关注于高质量的Anchor。
Training sample Assignment:
为提升两个任务的对齐性,TOOD聚焦于Task-Alignment Anchor,采用一种简单的分配规则选择训练样本:对每个实例,选择m个具有最大t值的Anchor作为正样本,选择其余的Anchor作为负样本。然后,通过损失函数(针对分类与定位的对齐而设计的损失函数)进行训练。
参考
[1].https://github.com/uyolo1314/ultralytics.
[2].https://github.com/meituan/YOLOv6.
[3].https://arxiv.org/abs/2209.02976.
[4].https://github.com/PaddlePaddle/PaddleDetection.
[5].https://github.com/PaddlePaddle/PaddleYOLO.
[6].https://github.com/open-mmlab/mmyolo.

