
- 1pyltp安装及运行_pyltp扩展包
- 2最新ChatGPT GPT-4 自然语言理解NLU与句词分类技术详解(附ipynb与python源码及视频讲解)——开源DataWhale发布入门ChatGPT技术新手从0到1必备使用指南手册(四)_gpt nlu
- 3关于设置VMware虚拟机里的IP所在网段与主机(Windows)电脑上的Ip所在网段一致的问题_与虚机同网段
- 4Transformer_transformer神经网络
- 5放心吧!基于图灵机的AI不会超越人类
- 6QGIS常用图源(谷歌中国、mapbox、esri、天地图等)(weixin公众号【图说GIS】)_qgis地图资源
- 7CVPR2021|一个高效的金字塔切分注意力模块PSA_高效金字塔注意力分割模块(epsa)
- 8pip国内镜像源_pipjingxiangyuan
- 9三大特征提取器(RNN/CNN/Transformer)
- 10C++PrimerPlus 课后习题第四章第8题(4.8)为什么getline()接受不到数据_c++为什么getline获取不到内容
VLE基于预训练文本和图像编码器的图像-文本多模态理解模型:支持视觉问答、图文匹配、图片分类、常识推理等_lert模型
赞
踩

项目设计集合(人工智能方向):助力新人快速实战掌握技能、自主完成项目设计升级,提升自身的硬实力(不仅限NLP、知识图谱、计算机视觉等领域):汇总有意义的项目设计集合,助力新人快速实战掌握技能,助力用户更好利用 CSDN 平台,自主完成项目设计升级,提升自身的硬实力。

VLE基于预训练文本和图像编码器的图像-文本多模态理解模型:支持视觉问答、图文匹配、图片分类、常识推理等

多模态预训练模型通过在多种模态的大规模数据上的预训练,可以综合利用来自不同模态的信息,执行各种跨模态任务。在本项目中,我们推出了VLE (Vision-Language Encoder),一种基于预训练文本和图像编码器的图像-文本多模态理解模型,可应用于如视觉问答、图像-文本检索等多模态判别任务。特别地,在对语言理解和推理能力有更强要求的视觉常识推理(VCR)任务中,VLE取得了公开模型中的最佳效果。
最近,大型语言模型(LLM)取得了巨大成功,并被用于翻译、问答、摘要等文本任务。虽然LLM是单模态模型,但它们的能力也可用于辅助多模态理解任务。借助LLM的zero-shot能力,我们设计了一种VQA+LLM方案,将大型语言模型集成到视觉问答任务中,实现了帮助视觉问答模型生成更准确和流畅的答案。
开源VLE相关资源以供学术研究参考。
在线演示地址:https://huggingface.co/spaces/hfl/VQA_VLE_LLM
中文LERT | 中英文PERT | 中文MacBERT | 中文MiniRBT | 中文ELECTRA | 中文XLNet | 中文BERT | 知识蒸馏工具TextBrewer | 模型裁剪工具TextPruner
查看更多哈工大讯飞联合实验室(HFL)发布的资源:https://github.com/iflytek/HFL-Anthology
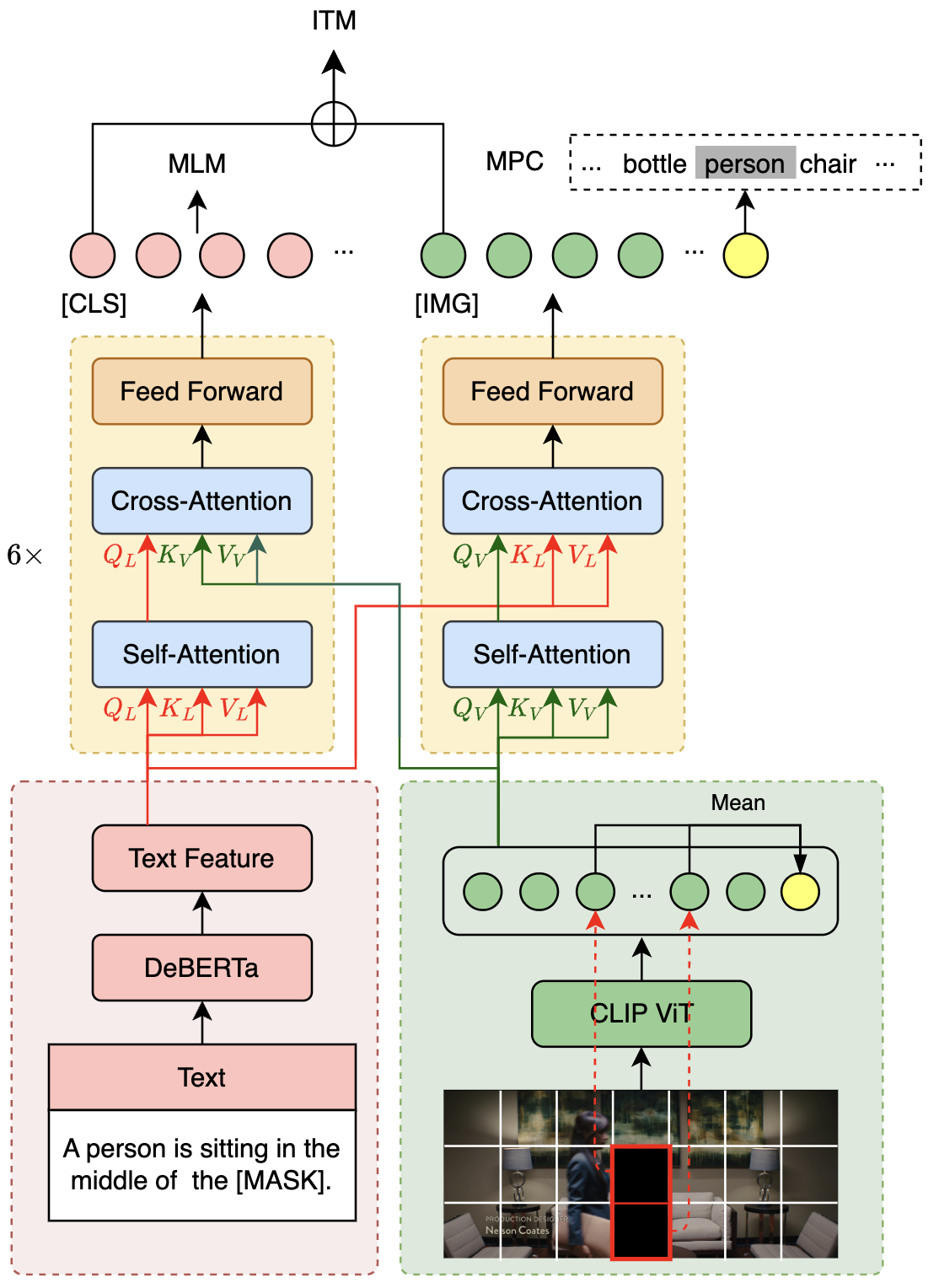
1.模型结构
VLE模型采用双流结构,与METER模型结构类似,由两个单模态编码器(图像编码器和文本编码器)和一个跨模态融合模块构成。VLE与METER的结构上的差异在于:
- VLE使用DeBERTa-v3作为文本编码器,其性能优于METER中使用的RoBERTa-base。
- 在VLE-large中,跨模态融合模块的隐层维度增加至1024,以增加模型的容量。
- 在精调阶段,VLE引入了额外的token类型向量表示。
2.预训练
VLE使用图文对数据进行预训练。在预训练阶段,VLE采用了四个预训练任务:
- MLM (Masked Language Modeling):掩码预测任务。给定图文对,随机遮掩文本中的部分单词,训练模型还原遮掩的文本。
- ITM (Image-Text Matching):图文匹配预测任务。给定图文对,训练模型判断图像和文本是否匹配。
- MPC (Masked Patch-box Classification):遮掩Patch分类任务,给定图文对,并遮掩掉图片中包含具体对象的patch,训练模型预测被遮掩的对象种类。
- PBC (Patch-box classification):Patch分类任务。给定图文对,预测图片中的哪些patch与文本描述相关。
VLE在14M的英文图文对数据上进行了25000步的预训练,batch大小为2048。下图展示了VLE的模型结构和部分预训练任务(MLM、ITM和MPC)。
3.下游任务适配
3.1视觉问答 (VQA)
- 我们遵循标准做法,使用VQA的训练集(training set)和验证集(validation set)训练模型,在test-dev集上进行验证。我们采用模型的融合层的pooler的输出进行分类任务的训练。
3.2 视觉常识推理 (VCR)
- 我们将VCR格式化为一个类似于RACE的选择题任务,并对于每张图像中的对象,将覆盖该对象的patch的表示的平均池化值添加到融合模块之前的图像特征序列中。我们还为图像和文本中的对象添加额外的token_type_ids,以注入不同模态之间的对齐信息,提升模型的对齐性能。
3.3 模型下载
本次发布了VLE-base和VLE-large两个版本的预训练模型,模型权重为PyTorch格式,可以选择手动从
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

