- 1文本的向量化表示总结_当前比较流行的文本向量化算法有
- 2计算机视觉方向怎么样?应该怎么准备计算机视觉方向保研?_计算机视觉考研
- 3How Rocket Companies run their data science platform on AWS
- 4李沐动手学深度学习pytorch :问题:找不到d2l包,No module named ‘d2l’_modulenotfounderror: no module named 'd2l
- 5TF-IDF实现关键词提取_tfidf关键词提取
- 6空间和时间 ----节选《时间简史》 霍金_python人马大战csdn免费专区
- 7图像情感分析标签分布学习
- 8机器学习入门指南_机器学习入门教程
- 9ESP8266 开发之旅 网络篇 无线更新 --OTA 固件更新_zolo-1d-pp1sl0dbijy
- 10作业_比较不同分类模型_hourlyrate和monthlyincome 的区别
CVPR24_ArGue: Attribute-Guided Prompt Tuning for Vision-Language Models
赞
踩
Abstract
尽管软提示微调在调整视觉语言模型以适应下游任务方面表现出色,但在处理分布偏移方面存在局限性,通过属性引导提示微调(Attribute-Guided,ArGue)来解决这个问题
Contributions
- 与直接在类名之前添加软提示的传统方法相比,通过大型语言模型(LLM)生成的原始视觉属性对齐模型,模型在这些属性上表达高置信度意味着其辨别正确类别理由的能力
- 引入属性采样来消除不利属性,只有语义上有意义的属性被保留下来
- 提出负提示,列举类别无关的属性以激活虚假相关性,并鼓励模型相对于这些负特征生成高度正交的概率分布
Intro.
在典型的分类任务中,提示微调直接在类名之前引入可学习的上下文。然而,零样本识别强调了将描述类别的视觉属性加入输入的重要性。尽管类名捕捉了高级语义,但在推断过程中,原始属性(例如,长尾/黑色爪子)提供了更精确的正则
本文通过识别VL模型中存在的捷径(shortcuts)来分析视觉属性对迁移学习的影响。这些模型在适应新任务时往往会提供不正确的决策理由。例如,正确地将天空中的物体分类为鸟,并不是因为它理解了语义特征,而是因为它检测到了鸟和天空之间的虚假相关性。一个主要突出虚假相关性的模型,例如背景,往往无法有效地推广到分布外数据。
与直接将图像特征与类名对齐的传统提示微调方法不同,ArGue鼓励模型在识别由LLMs生成的相关视觉属性时表现出高置信度。能够识别这些原始属性的模型捕捉到了类的正确理由,而不是受到虚假相关性的影响。
关键优势:
- 仅基于类名生成的属性自然地避免了图像中存在的捷径
- 原始属性可能被其他类共享,增强模型的泛化能力
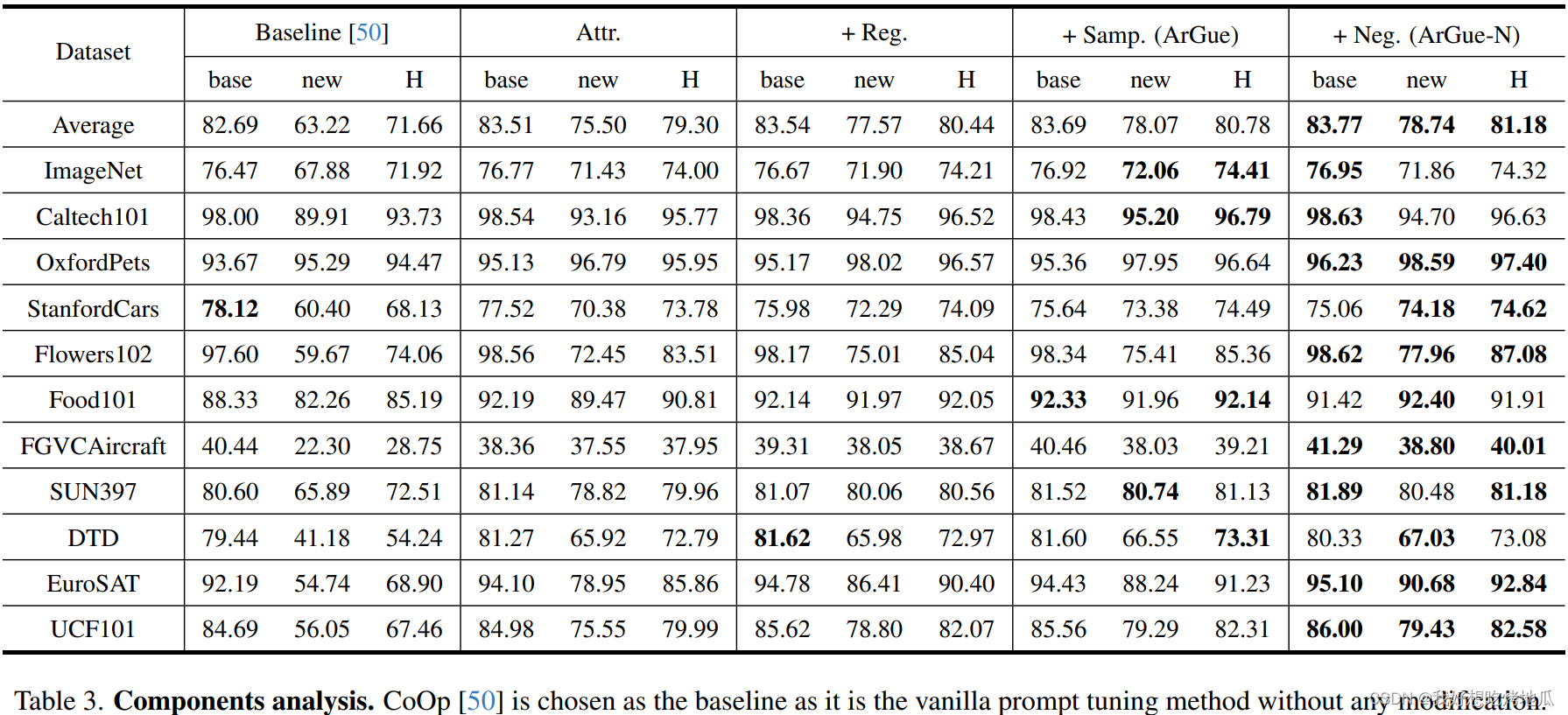
尽管经过细致的提示调整,直接从LLMs生成的属性的固有质量仍不稳定。提出了属性采样来选择最具代表性和非冗余的属性,使其与相应的图像对齐。利用属性池聚类来选择每个簇中最具代表性的属性,同时避免冗余。根据簇在特征空间中与图像的相似性对属性进行排名,选择最相关的属性。该过程为图像选择最具语义相关性的视觉属性,实验表明减少80%的属性数量会使准确性的提高,同时减少计算资源开销。
在属性引导提示调整的基础上,引入了负提示 ArGue-N。当提供一个不具有类别特定语义并激活虚假相关性的负属性时,模型应该避免偏向于任何类。**ArGue-N 提供了一个通用的负提示,即“the background of a {class}”,背景激活了与类别不相关的区域。在使用负提示时,强制模型产生均匀的预测概率分布。**尽管通用负提示假设较弱,但在分布外数据集上观察到了稳定性能提升。
Method

ArGue: Attribute-Guided Prompt Tuning
传统的训练方法使CLIP实现高准确度,但可能并没有找到图像中的对应属性的一种“捷径”。当提供鸟类的类名时,CLIP可能会与天空建立语义相关,引入了对背景而不是捕捉鸟类语义的依赖,对虚假相关性的依赖大大削弱了泛化能力。提出训练一个对相关视觉属性表现出高置信度的模型:
- 与高级类别名称相比,明确与视觉属性对齐鼓励模型优先考虑类的内在语义
- 表示低级特征的视觉属性可能与多个类共享,从而促进对新类别或分布外数据的泛化

直接获取这些视觉属性的一种方法是查询LLMs关于特定类别的视觉特征。LLM的输入仅包括类别名称,从根本上规避了图像中存在的学习捷径。形式上,给定任何标签 c c c,得到一系列属性。优化Eq.4意味着期望模型对标签的每个属性表现出高置信度,同时最小化其与任何其他属性的关联
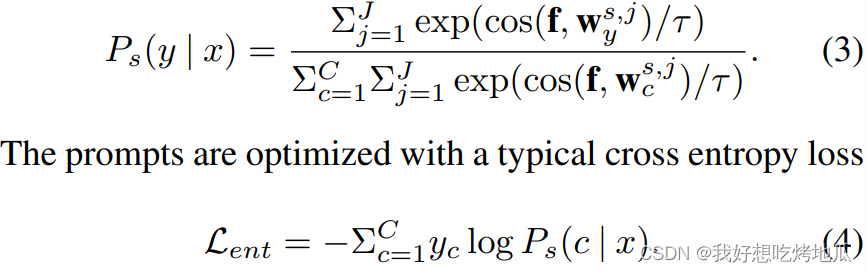
Attribute Sampling
虽然LLMs可以生成与类名相关的属性,但一些属性与视觉特征的语义相关性比其他属性更强。移除无效属性不仅减少了内存消耗,还提高了模型的准确性
- 所选属性应既具有代表性又不重复
- 所选属性应在语义上与特定类别的图像相关联
给定来自属性池的与类别 c c c 相关的属性 a t t r c attr_c attrc,根据它们在CLIP空间中的特征相似性将它们分成 N N N个簇,旨在确保每个簇代表一个不同信息,例如颜色或形状。在每个簇内,通过评估它们与CLIP空间内视觉特征的相似性来对属性进行排名,并选择与之最相关的属性,基于此过滤了:
- 非视觉属性,例如“甜”,“可食用”
- 与图像在语义上不相关的不正确的视觉属性
Prompt Regularization
少样本设置中,软提示学习的一个问题是模型可能会过拟合训练样本,在测试时导致未见数据的性能下降。提示正则化使软提示在特征空间中与自然文本接近,从而处理过拟合
Negative Prompting
使用负提示目标是明确列举缺乏特定类别信息的属性,期望模型在提供这些负属性时不偏向任何类别。当引入负提示,例如“the background of a cat”时,模型应该提供一个没有主导类的均匀预测。“the background of a [CLASS]"代表了一种典型的负属性,缺乏特定类别的信息,同时激活了图像中的虚假相关性。虽然可能提供更具体的负属性,但是为每个类手动标记开销较大,并且实验结果表明尽管“the background of a [CLASS]"是一个弱假设,其在大多数数据集上表现较好。
当模型过于依赖类别名称时,属性的影响往往会减弱。考虑到负提示包括类名,模型被设计为减弱负属性的影响,同时减弱类名的重要性。因此,模型能够识别并关注到由特定类别属性指示的区域,优先考虑这部分区域以获得精确的激活。为确保模型不偏向任何一个类,强制概率是均匀的(目标是最大化分布的熵)。
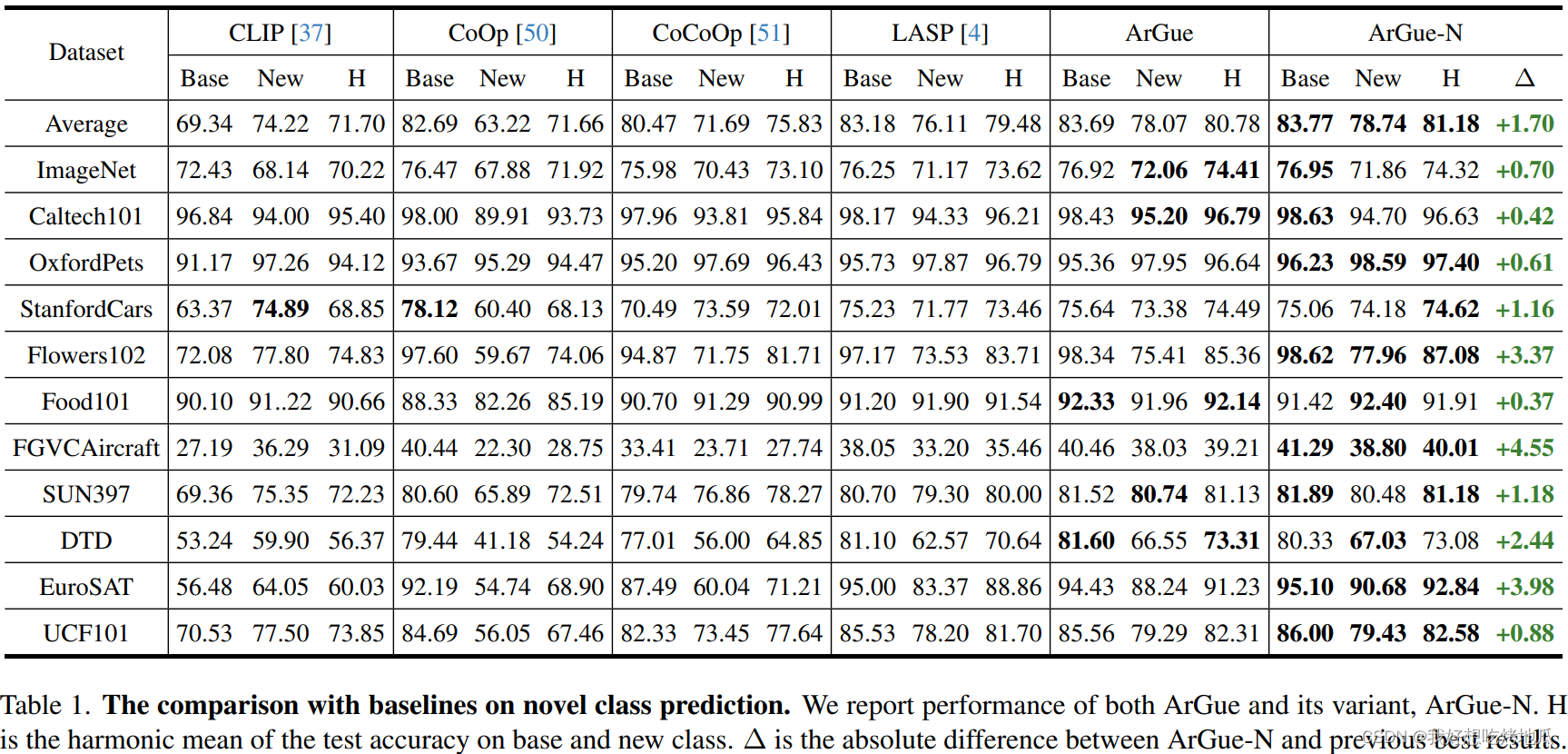
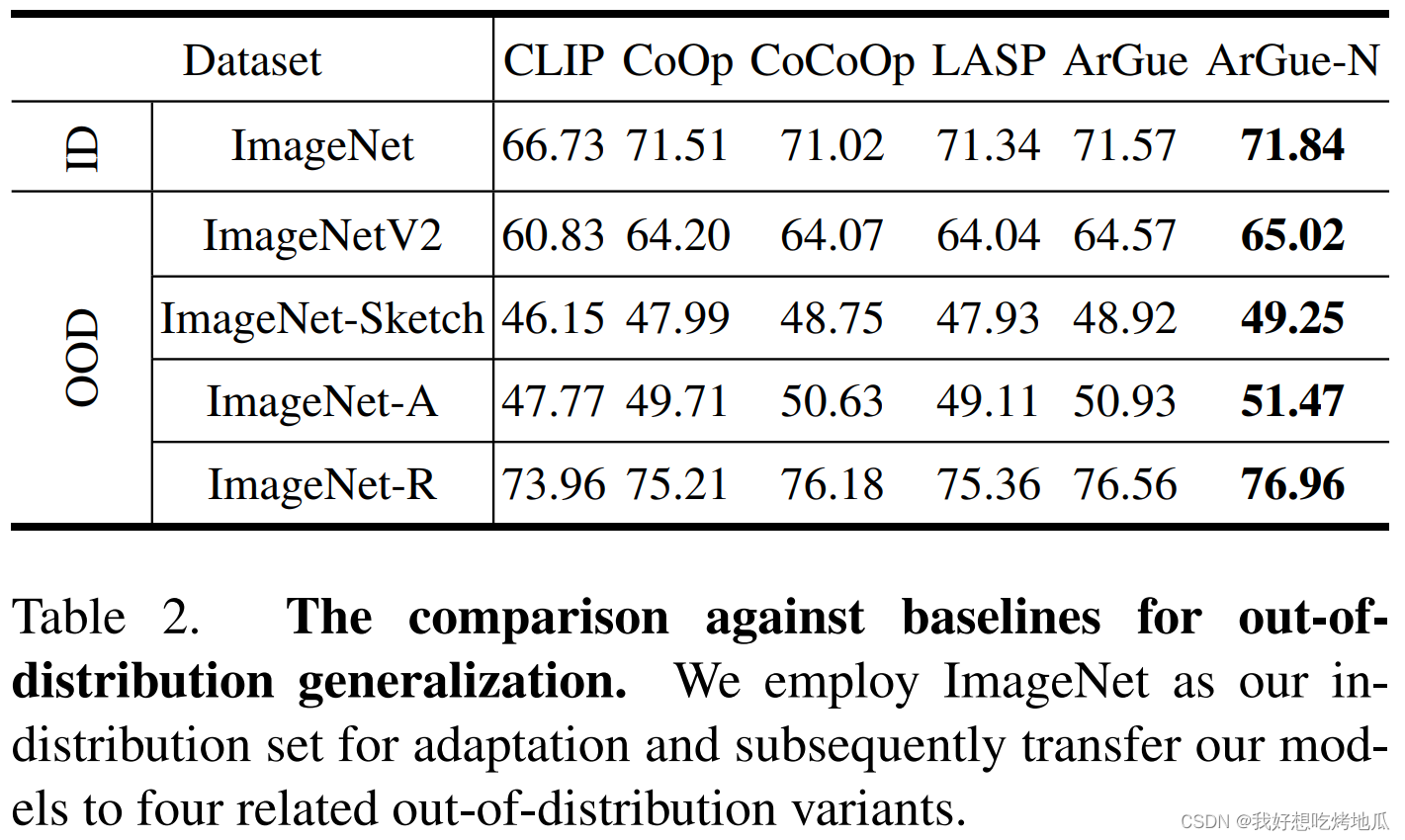
Experiments