
- 1全文检索四种技术解决方案_全文检索方案
- 2优雅地给element-ui和element-plus的el-tree控件添加结构线_element-tree-line
- 3解决:word打开后mathtype公式乱码、visio图乱码_office365查看visio出现乱码
- 4Java面试必背八股文,1000多道最新大厂架构面试题,赶紧收藏起来吧!
- 52023华为软件精英挑战赛赛题解析及baseline(C++实现)_华为软挑2023年技术分析
- 6Redis - 5k star! 一款简洁美观的 Redis 客户端工具~
- 7鱼哥赠书活动第12期:《基于React低代码平台开发》
- 8记录一下最近复现motionBERT和Alphapose遇到的问题_alphapose推理卡住
- 9LLMs之Grok-1:runners.py文件解读—基于JAX和设备分布的预训练语言模型inference服务+支持批量查询+利用设备资源高效推理同时可以被嵌入训练循环进行微调训练
- 10基于FPGA的并行PRBS实现方法
NLP深入学习:《A Survey of Large Language Models》详细学习(三)
赞
踩
1. 前言
最近正在读 LLM 论文的综述,当前采取的策略是部分内容走读+记录,论文原文见《A Survey of Large Language Models》
前情提要:
《NLP深入学习:《A Survey of Large Language Models》详细学习(一)》
《NLP深入学习:《A Survey of Large Language Models》详细学习(二)》
前文介绍了论文的摘要、引言以、总述部分以及讲解了 LLMs 相关资源,包含公开模型、API、预训练的数据集以及微调的数据集。
本文继续根据论文来介绍预训练部分,这是 LLMs 的重要部分!
2. 预训练
预训练建立了 LLMs 能力的基础。通过对大规模语料库的预训练,LLMs 可以获得基本的语言理解和生成技能。为了有效地预训练 LLMs,模型架构、加速方法和优化技术都需要精心设计。
2.1 数据搜集与准备
LLMs 对模型预训练的高质量数据有更强的需求,其模型能力在很大程度上依赖于预训练的语料库及其预处理。
2.1.1 数据源
数据源部分在原文中提及了通用文本数据(General Text Data)和专业文本数据(Specialized Text Data)两类。
-
通用文本数据(General Text Data):
- Webpages:网页是 LLMs 获取广泛知识的重要来源之一,其内容涵盖了多种话题、领域和风格的自然语言表达。尽管网络数据质量参差不齐,但通过过滤和清洗策略可以提高数据的质量,例如去除低质量或恶意内容。
- Books:书籍提供了长篇连贯、正式且结构化的文本,有利于模型学习更深层次的语言结构和复杂概念间的关联,对于提升模型生成连贯文本和理解长篇文章的能力至关重要。
- Conversation text:对话文本(如来自社交媒体平台、论坛等的用户交互记录)有助于增强模型的会话理解和响应能力,使其能够在实际对话场景下更好地模拟人类交流方式。
-
专业文本数据(Specialized Text Data):
- Multilingual data:多语种数据集用于训练具备跨语言理解与生成能力的 LLMs,比如 BLOOM 和 PaLM 就包含了多个语言的数据以提升模型的多语言处理性能。
- Scientific text:科学文献和其他科技资源被用于训练专门针对科学和技术任务优化的模型,帮助模型理解和生成包含数学公式、代码片段及专业知识的文本。
- Code data:编程相关的数据集(如 GitHub 上的开源代码库),用于训练能够理解和生成代码的 LLMs,如 GPT-4 在某些版本中加强了对代码的理解和生成能力。
2.1.2 数据预处理
数据预处理是构建大型语言模型(LLMs)的重要环节,它涉及多个关键步骤:
-
质量过滤(Quality Filtering):需要对原始收集的数据进行质量筛选,去除噪声或无用的信息,如HTML标签、超链接、模板文本以及不适宜的言语内容。通过特定关键词集检测并移除这些元素,确保模型训练时使用的文本质量较高。文中提到的方法:
- 基于分类器的方法(classifier-based approach):这种方法首先训练一个分类器,用于识别高质量和低质量文本。通过该分类器对整个语料库进行筛选,将得分较低、被标记为低质量的数据样本从预训练数据集中剔除。这种做法要求具备足够数量的高质量和低质量样本来训练分类器,并确保分类器具有良好的泛化能力。
- 启发式规则方法(heuristic-based approaches):这一策略不依赖于机器学习模型,而是根据一系列明确设计的规则来识别并去除低质量数据。例如,可以通过检测重复内容、检查语言质量指标(如拼写错误率、语法结构复杂度)、统计特征分析(如标点符号分布、符号与单词比率、句子长度等),以及关键词黑名单过滤等方式,确定并删除不符合标准的文本片段。
-
去重(De-duplication):为了提高模型训练的效率和稳定性,必须在不同粒度层面对重复数据进行识别与删除。这包括句子级别、文档级别甚至整个数据集级别的重复检查。例如,从低质量的重复词语和短语开始清理,以避免在语言建模过程中引入重复模式,并确保模型学习到更多样化的表达。
-
隐私保护(Privacy Reduction):考虑到预训练数据中可能包含敏感或个人身份信息,研究者采用规则方法(如关键词检测)来识别并移除个人信息,如姓名、地址和电话号码等。此外,有研究表明,预训练语料库中的重复个人身份信息可能会增加模型在隐私攻击下的脆弱性,因此去重也是降低隐私风险的一种手段。
-
分词(Tokenization):将原始文本分割成一系列单个标记的过程至关重要,这些标记随后作为 LLMs 的输入。神经网络模型越来越多地使用字符级分词(如 ELMo 中的 CNN 单词编码器),下面介绍三种主要的子词级别的分词方法:Byte-Pair Encoding (BPE) tokenization、WordPiece tokenization 以及 Unigram tokenization。
- Byte-Pair Encoding (BPE) tokenization:
BPE 最初作为一种通用数据压缩算法于1994年被提出,随后在自然语言处理中被用于词汇单元的分割。该方法从一个基础符号集合(如字母和边界字符)开始,逐步合并频次最高的相邻字节对作为新符号(称为merge)。每一步的合并选择基于训练语料库中连续 token 对的共现频率,重复此过程直至达到预设的词汇表大小限制。 - WordPiece tokenization:
WordPiece 是谷歌内部开发的一种子词分词算法,最初应用于语音搜索系统的开发,后来在2016年的神经机器翻译系统中使用,并且在2018年BERT 中被采用为单词 tokenizer。与BPE类似,WordPiece 也是通过迭代合并连续的标记来生成新的词汇单元,但其合并策略略有不同。WordPiece 首先训练一个语言模型以评估所有可能的标记对得分,然后在每次 merge 时选择使训练数据似然性提升最大的一对标记。 - Unigram tokenization:
与 BPE 和 WordPiece 相比,Unigram tokenization采 取了不同的初始化方式,即从一个包含足够数量候选子串或子 token 的大集合开始,通过迭代移除当前词汇表中的令牌,直到达到预期的词汇表大小为止。其选择准则基于假设移除某个 token 后训练数据的似然性增加的情况,利用训练好的 unigram 语言模型来估计这种增加。
- Byte-Pair Encoding (BPE) tokenization:
-
关于数据质量影响的讨论(Discussion on Effect of Data Quality):文章指出,预训练数据的质量对于 LLMs 的能力至关重要。使用含有噪声、有毒内容和重复数据的低质量语料库进行训练会显著损害模型性能。实验结果表明,在清洗过的高质量数据上进行预训练可以显著改善 LLMs 的表现,特别是去重有助于稳定训练过程,避免模型受到重复数据的影响导致性能下降。同时,重复数据还可能导致模型在上下文学习等方面的“双重下降”现象,即在一定阶段性能先降后升的现象,从而影响模型在下游任务上的泛化能力。因此,在实际应用中,要特别注意利用诸如质量过滤、毒性过滤及去重等预处理方法仔细清理预训练语料库。
2.1.3 数据调度
在大型语言模型(LLMs)的训练中,数据调度是一个关键环节,它包括了两个主要方面:数据混合(Data Mixture)和数据课程(Data Curriculum)。
-
数据混合(Data Mixture):
数据混合是指为预训练 LLMs 选择并组合不同来源、不同类型的数据的过程。研究者不仅手动设置数据的混合比例,还探索优化数据混合以提高模型的预训练效果。针对不同的下游任务,可以优先选择特征空间相近或对目标任务性能有正面影响的数据源。为了减少对特定任务的依赖,一些研究提出了动态调整数据源权重的方法,如 DoReMi 使用小型参考模型来确定哪些领域数据之间的似然性差异较大,然后通过一个小型代理模型去增加这些领域的权重,最后将学习到的领域权重应用于大规模 LLM 的训练。为了找到一个有效的数据混合策略,文中提到了多种常见方法:- 增加数据来源的多样性:通过收集和整合来自不同领域、语言和格式的数据源,例如网页、书籍、对话记录、代码库以及多语种文本等。这样做的目的是让模型在训练过程中接触更广泛的自然语言表达,从而增强其泛化能力和处理多样化任务的能力。
- 优化数据混合:针对特定目标任务或应用场景,研究人员会精心设计和调整数据集组合的比例。这可能包括对高质量数据集(如 FLAN 或 P3)进行优先采样以提高模型性能,或者设置数据上限来避免大容量数据集主导整个分布,确保各类型数据有公平的学习机会。此外,还可能采用基于特征空间相似度、下游任务表现等因素来选择最优数据组合。
- 针对性地提升特定能力:根据所期望的语言模型具备哪些特殊技能或属性,可以有针对性地增大某些特定数据类型的占比。比如,在提升数学推理或编程能力时,增加含有数学公式和代码示例的数据;若要提高长篇文本理解能力,则可以更多地使用包含长距离依赖关系的书籍片段等。这种策略旨在通过专门的数据训练强化模型在特定领域的表现。
-
数据课程(Data Curriculum):
数据课程则关注如何按照一定的顺序向 LLMs 提供预训练数据。研究表明,在某些情况下,遵循“先易后难”的教学原则(即从基础技能到目标技能的序列学习),相较于直接从单一关注目标技能的数据集中进行训练,能够更有效地提升模型能力。这种基于课程的学习方式旨在组织 LLMs 预训练过程中的多源数据,使其在预训练的不同阶段接触难度逐步升级的任务实例。- 编程能力(Coding):为了提高模型的编程理解和生成能力,研究者会在数据课程中加入大量代码片段、编程任务示例以及相关文档等内容。例如,通过在预训练过程中增加编程相关的数据源比重,并按从简单到复杂的顺序逐步引入不同类型的编程任务,如基本语法教学、函数调用直至复杂算法实现等,从而使得 LLMs 能够更好地理解并生成代码。以下是三个常见的利用数据课程进行强化的能力:
- 数学能力(Mathematics):为了增强模型处理数学问题的能力,数据课程会包含数学公式、定理证明、问题解答等数学文本材料。研究人员可能会先让模型学习基础数学概念和符号表示,然后过渡到更高级别的数学推理任务,比如解决代数、几何或微积分问题。这种有序的数据输入有助于模型逐渐建立对数学知识结构的理解。
- 长文语境理解(Long context):对于 LLMs 来说,理解长篇文本中的上下文关系是一项重要能力。在数据课程的设计中,研究者会逐步递增训练样本的长度和复杂性,包括连续篇章、长篇文章乃至书籍级别的内容。例如,首先使用较短的文本段落训练模型捕捉局部信息,随后增加文本长度以便于模型适应处理更长的上下文依赖关系。这一策略有助于提高模型在长文本任务上的表现,如篇章连贯性、事件因果推断和主题一致性等方面。
2.2 架构设计
2.2.1 典型架构
下面是典型的 LLMs 模型的细节参数:
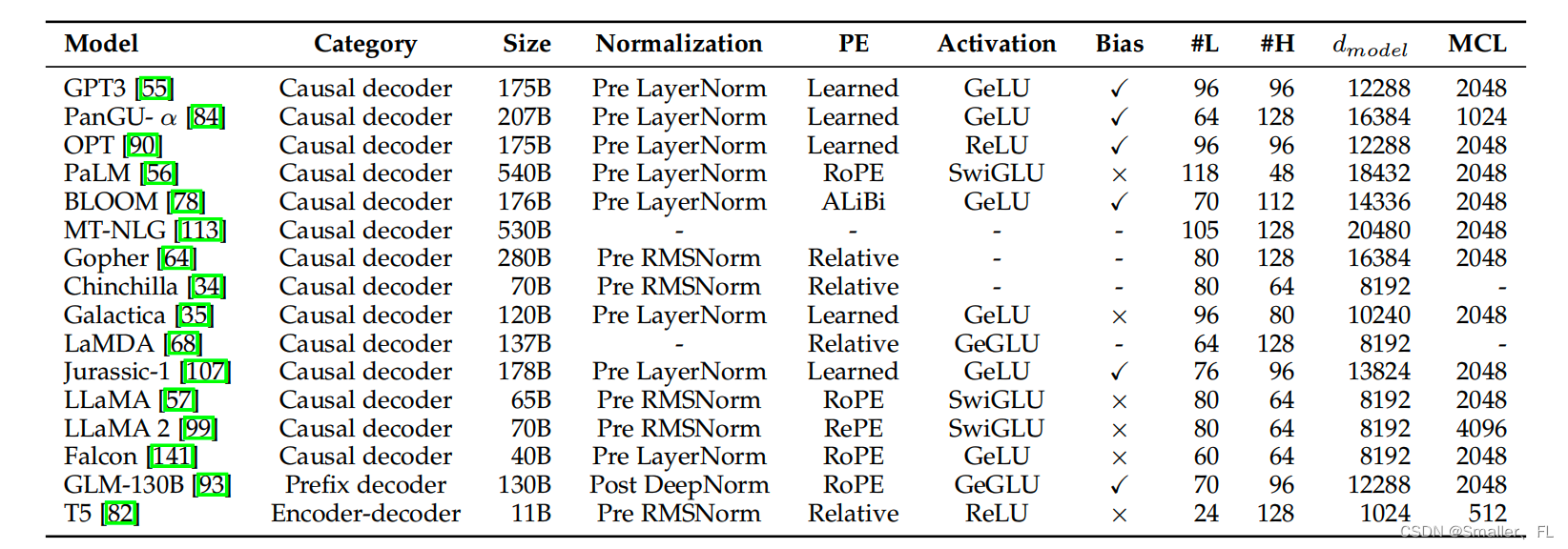
ps:PE 表示位置嵌入、#L 表示层数,#H 表示 attention heads 的数量,
d
m
o
d
e
l
d_{model}
dmodel 表示隐藏状态的 size,MCL 表示训练期间的最大上下文长度。
下图是三种主流架构中的 attention 模式的比较。
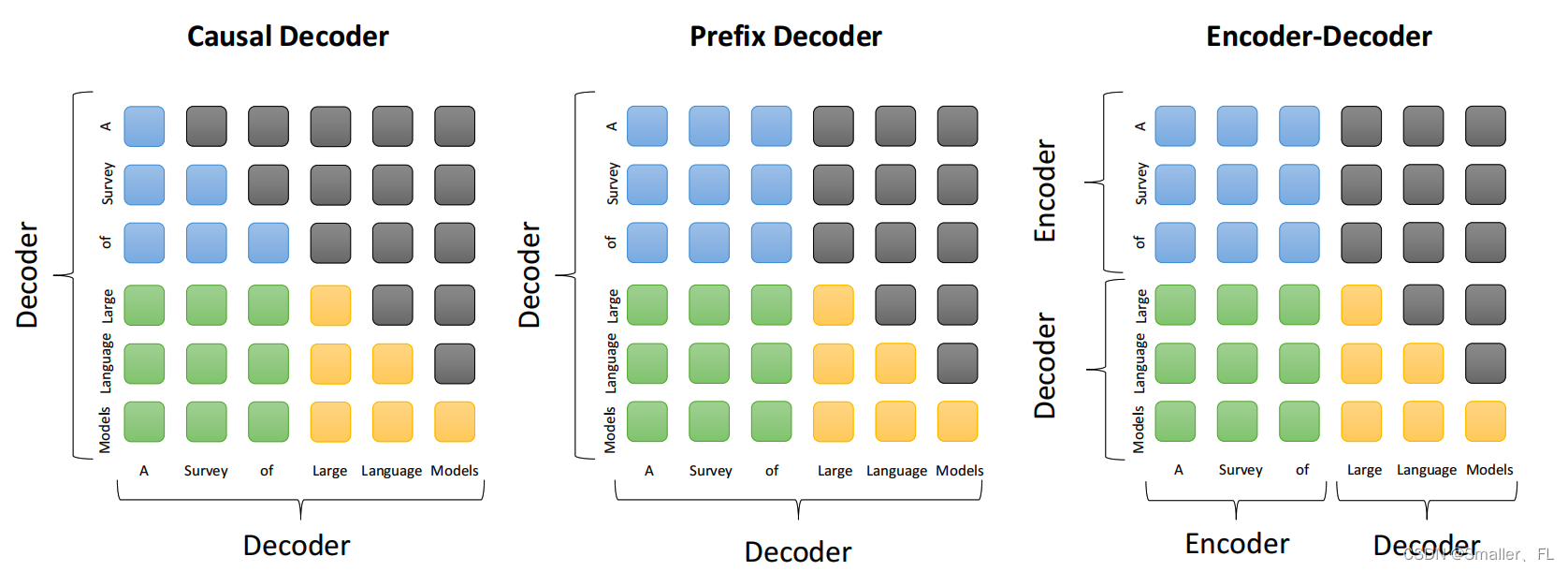
蓝色:前缀 tokens 之间的 attention
绿色:前缀和目标 tokens 之间的 attention
黄色:目标 tokens 间的 attention
灰色:masked attention
下面是具体的架构:
-
Encoder-decoder Architecture:
在自然语言处理领域,经典的 Transformer 模型采用了编码器-解码器架构。这种架构由两部分组成:编码器负责对输入序列进行编码,通过多层自注意力机制捕获上下文信息;解码器则根据编码器生成的隐状态逐步生成输出序列,并采用自回归方式预测每个位置的下一个单词,同时利用跨注意力机制关注到编码器的输出以理解上下文。 -
Causal Decoder Architecture:
因果解码器架构是专门为自回归任务设计的 Transformer 变体,它主要应用于如 GPT 系列的大规模预训练语言模型中。此架构中的注意力掩码确保了在解码过程中,当前时间步只能访问其之前的已生成词汇信息,从而避免未来信息泄露的问题。 -
Prefix Decoder Architecture:
前缀解码器(非因果解码器)改进了常规的自回归注意力机制,允许模型在生成目标序列时能够双向关注前缀部分的输入。例如,GLM-130B 和 U-PaLM 等模型采用了这一架构,使得模型不仅能够像编码器那样对输入序列进行双向编码,同时还能保持自回归地生成输出序列。 -
Mixture-of-Experts (MoE):
混合专家模型是一种扩展大规模语言模型参数量的策略,在不同输入情况下激活不同的子网络或专家。例如 Switch Transformer 和 GLaM 使用了 MoE 结构,其中一部分神经网络权重仅针对特定输入被激活。这种方法可以在不显著增加计算成本的情况下提高模型性能,并且通过增加专家数量或总参数规模可以观察到显著性能提升。 -
Emergent Architectures:
新兴架构是指为了应对传统 Transformer 架构存在的问题(如二次复杂度带来的效率挑战)而发展出的新颖结构。这些新架构包括但不限于参数化状态空间模型(如 S4、GSS 和 H3)、长卷积网络(如 Hyena)、以及结合递归更新机制的 Transformer-like 架构(如 RWKV和 RetNet)。这些创新结构旨在通过并行化计算和更有效地处理长序列信息来提高模型的效率和性能。
2.2.2 详细配置
在构建和优化大型语言模型(LLMs)时,以下几个关键配置技术对于模型性能和训练效率至关重要:
-
Normalization Methods:在大型语言模型(LLMs)的架构设计中,归一化位置(Normalization Position)是一个重要的考虑因素。在 Transformer架构中,常见的归一化方法如 LayerNorm、RMSNorm 和 DeepNorm 等通常应用于不同的网络层位置以实现不同目的。
-
LayerNorm (LN):是 Transformer 架构中广泛采用的一种归一化方法,在每个层的输出上执行独立于批次大小的标准化操作,通过计算每层激活值的均值和标准差来重新中心化并缩放数据,从而稳定模型训练过程并提高收敛速度。此外,还有像 RMSNorm 等替代方案被提出以进一步优化效率和稳定性。
-
RMSNorm:作为对 LayerNorm 的一种改进,它简化了计算过程,仅基于激活值总和的平方根进行归一化。研究表明,该方法可以加速训练并提升模型在 Transformer 上的表现。
-
DeepNorm:由微软提出,旨在解决深度 Transformer 模型训练不稳定的问题。DeepNorm 作为一种特殊的归一化层设计,配合残差连接应用于极深的网络结构中,有助于确保即使在数百甚至数千层的网络中也能保持良好的训练效果。
-
-
Normalization Position:
-
Post-LN (Post Layer Normalization):原始 Transformer 架构采用的是后置归一化(Post-Norm),即在每个自注意力或前馈神经网络子层之后进行归一化操作。这种方法有助于稳定训练过程,尤其是在深度网络中通过抑制内部层间梯度爆炸或消失的问题,提高模型收敛速度和性能表现。
-
Pre-LN (Pre Layer Normalization):相比之下,前置归一化(Pre-Norm)是指在每个子层运算之前先对输入进行归一化处理。一些研究发现,在某些情况下,预归一化能够改善极深网络的训练稳定性,因为它可以确保每一层接收到的输入具有相近的动态范围,从而避免了深层网络中的梯度问题。
-
Sandwich-LN (Sandwich Layer Normalization):同时,还有研究提出“三明治”式的归一化结构,即将归一化层置于自注意力模块内部的 QKV 计算前后,形成一种前后双归一化的模式,这种策略旨在结合预归一化和后归一化的优点,既能保持训练稳定性又能提升模型性能。
-
-
Activation Functions:
- ReLU: 基础的非线性激活函数,通常用于神经网络隐藏层,其特点是当输入大于零时输出等于输入,小于零时输出为零。
- GeLU:通用误差线性单元(Gaussian Error Linear Units, GeLU),是ReLU的一个变种,引入了近似高斯分布的非线性变换,能够提供更平滑的梯度传播,并在实践中被证明能有效改善模型的表现,如在GPT-3和相关后续模型中广泛应用。
- Swish 和 SwiGLU / GeGLU 等新型激活函数也被提及,它们通过结合 sigmoid 或双门控机制实现了更好的性能,例如 Swish 利用了自身的输入值与 sigmoid 函数结果相乘,而 SwiGLU 和 GeGLU 则将这些新颖特性应用到多头注意力模块中的全连接层中,提高了模型的学习能力和泛化性能。
-
Position Embeddings:
- 绝对位置编码(Absolute Positional Encoding):在原始Transformer中使用固定的位置向量来表示序列中各词的位置信息。
- 相对位置编码(如RoPE、ALiBi):相较于绝对位置编码,这些方法关注词语间的相对距离关系,通过学习可适应上下文变化的位置偏移量矩阵,使得模型更好地捕捉长距离依赖。
- 旋转位置嵌入(Rotary Position Embedding):是一种用于Transformer架构的语言模型中改进位置编码方法。相较于传统的绝对或相对位置编码,该方法引入了一种新颖的机制来处理序列中的位置信息。
- ALiBi,用于改进模型处理长距离依赖的能力。注意力分数的计算引入了与查询和键之间距离相关的线性偏置。具体来说,对于自注意力层中的每个注意力头,在计算注意力权重时会在键和查询向量之间的相似度计算上添加一个与它们距离成比例的偏置项。这个偏置是预先定义好的,并且随着查询与键之间的距离增加而增大,从而鼓励模型在处理较远位置的关系时能够更加关注序列两端的信息。
-
Attention Mechanism:
注意机制是 Transformer 的一个重要组成部分。-
Full attention(全注意力)是 Transformer 模型最初提出的自注意力机制,它允许序列中的每个位置与所有其他位置进行交互。在全注意力机制中,每个查询向量会计算其与所有键向量的相似度,并基于这些相似度生成权重分布,随后用这些权重对值向量进行加权求和以得到最终的上下文向量。尽管全注意力提供了完整的上下文信息,但其计算复杂度随着序列长度的平方增长,导致处理长序列时效率低下。
-
Sparse attention 是为了解决全注意力计算效率问题而提出的一种改进方法,通过设计特定模式的注意力矩阵,使得模型仅关注部分位置而不是全局范围内的所有位置。例如,局部窗口注意力只考虑当前位置附近的邻居信息,从而大大降低了计算复杂度。
-
Multi-query/grouped-query attention 优化了模型在处理多任务或大规模并行请求时的效率。多查询注意力允许一个查询同时与多个键-值对进行匹配,减少重复计算;分组查询注意力则是将多个查询按某种规则划分成不同的组,在组内执行注意力操作,提高并行处理能力。
-
FlashAttention 和 PagedAttention 是针对大规模语言模型数据传输和内存访问瓶颈问题所提出的两种优化技术:
-
FlashAttention:通过优化GPU上的数据加载策略和计算流程,可以显著加快自注意力层的计算速度,特别是在处理长文本时,它通过并行加载键和值来加速注意力计算过程。
-
PagedAttention:该技术利用了页面管理的思想,将键值对缓存分割成连续的块或者“页面”,以便高效地管理内存资源和优化数据访问。这种方案尤其适用于处理超长序列的场景,能够有效缓解长距离依赖学习中因内存限制而导致的问题,提高了模型处理长文本的能力。
-
-
2.2.3 预训练任务
在大型语言模型(LLMs)的预训练任务中,主要包括以下几种类型:
-
Language Modeling (LM):这是最常见的预训练任务之一,目的是让模型学习预测给定文本序列中下一个单词的概率分布。通过自回归的方式,模型基于前面的上下文信息预测后续的词汇。例如,GPT 系列模型和 BERT 中的 Masked Language Model 都是基于语言建模进行预训练的。
-
Denoising Autoencoding (DAE):去噪自编码是另一种预训练方法,它通过引入噪声到输入数据(通常是文本),然后要求模型恢复原始未受干扰的文本内容。这种方法有助于提高模型对不完整、有噪声或损坏数据的理解能力。如 T5和 GLM-130B 等模型在预训练阶段采用了 DAE 任务。
-
Mixture-of-Denoisers (MoD) 或称为 UL2 损失:这是一种结合了多个不同类型的去噪任务的统一预训练目标。在 MoD 框架下,模型需要处理多种类型的噪声,并采用不同的 “denoiser” 来应对这些噪声。比如 PaLM 2 就采用了这种混合型去噪任务,其中包含了短跨度低噪声、长跨度高噪声等多种情况下的文本恢复任务,旨在增强模型在不同复杂度场景下的表现和泛化能力。
2.2.4 长上下文建模
主要包含以下两种策略:
-
Scaling Position Embeddings:随着语言模型处理的文本长度增加,对位置嵌入(Position Embeddings)进行扩展至关重要。原有的位置嵌入通常设计用于固定大小的上下文窗口内,但在处理更长的文本时可能无法捕捉到远距离依赖关系。为了应对这一挑战,研究者采用了一些技术来调整和扩展位置嵌入。
- 直接模型微调(Direct model fine-tuning):对于已经预训练好的模型,研究者尝试直接在更大上下文长度上进行微调。这种方法假设模型通过微调能够适应更长的位置索引,并且学习到适当的位置表示。
- 位置插值(Position interpolation):当需要处理超出原模型上下文窗口限制的文本时,可以采用线性或非线性插值的方法来生成新的位置嵌入。具体而言,通过对原始位置嵌入表中的相邻向量进行插值计算,以模拟未见过的更长距离的位置信息。
- 位置截断(Position truncation):对于过长的输入序列,一些研究将位置索引截断至预训练模型支持的最大范围之内,只考虑部分位置信息。然而,这种方法可能会影响模型对长距离依赖关系的学习和表达。
- 基础修改(Base modification):一种改进位置嵌入的方式是改变其底层数学结构。例如,在原有绝对位置编码的基础上,引入新的公式或参数化方式以适应不同长度的序列。
- 基底截断(Basis truncation):这是一种更为复杂的技术,涉及对位置嵌入矩阵进行分解并仅使用部分基向量来表示任意位置。例如,通过选择一个低秩基底集合,然后用这些基向量的线性组合来构建新的位置嵌入,从而允许模型处理比原始位置嵌入表更大的索引范围,同时保持计算效率和内存占用相对较低。
-
Adapting Context Window:
-
并行上下文窗口(Parallel context window):当模型需要处理的文本长度超出原始上下文窗口时,可以采用将长序列切分为多个小片段,并对每个片段独立应用自注意力机制。这种方式允许模型同时关注到文本的不同部分,通过信息聚合或跳过连接的方式在片段之间传递和融合信息。
-
Λ-shaped context window(Lambda-shaped context window):此策略关注的是序列的起始和结束部分以及它们之间的最近邻居。其设计灵感来源于人类阅读长文档时往往更关注开头、结尾以及过渡段落。在实践中,Λ形注意力窗口通过对注意力矩阵进行特定形状的设计,使得模型能更好地聚焦于关键信息区域,减少冗余计算,提高处理长序列的能力。
-
外部记忆(External memory):为了克服固定大小上下文窗口的限制,一些研究引入了外部存储系统来扩展模型的记忆容量。这种方法允许模型在必要时访问历史上下文信息,而无需将其全部加载至内存中。
-
2.2.5 解码策略
在对 LLMs 进行预训练后,必须使用特定的解码策略从 LLMs 中生成适当的输出。
-
Improvement for Greedy Search
在大型语言模型(LLMs)的解码过程中,贪婪搜索是最简单的策略,它会在每一步选择当前概率最高的词汇作为输出。然而,贪婪搜索存在一些局限性,如容易陷入局部最优解,导致生成结果质量受限。为改进贪婪搜索,研究者提出了以下两种方法:- Beam Search:波束搜索是一种贪心式的启发式搜索算法,它通过同时维护一组(通常是k个)最有可能的候选序列,并在每个时间步更新这些候选序列来生成文本。相比于贪婪搜索只关注一个最高概率路径,波束搜索保留了多条潜在的高质量路径,从而提高了找到全局最优解的可能性。然而,波束搜索也引入了额外的计算开销,并可能导致生成的结果过于保守或缺乏多样性。
- Length Penalty:长度惩罚是在评估候选序列得分时加入的一个修正因子,通常用于调整波束搜索中不同长度候选序列的权重。其目的是克服波束搜索倾向于生成较短序列的问题,确保在生成不同长度的句子时可以保持平衡。例如,在计算候选序列的概率总和时,对序列长度进行相应的惩罚或奖励,使得更长但质量较高的序列有更大的机会被选中。这样一来,即使较长的序列在单个词上的概率较低,但由于整体内容的连贯性和丰富性,也可能得到更高的综合评价分数。
-
Improvement for Random Sampling
在大型语言模型(LLMs)的解码过程中,随机采样是一种生成文本的基本策略,其中每个时间步根据词汇表中所有词的概率分布进行随机选择。然而,原始随机采样可能导致生成结果的质量不稳定和不连贯。为了改进随机采样方法,研究者提出了以下几种策略:- Temperature Sampling:
在 softmax 函数中引入一个温度参数(temperature),可以控制输出词汇概率分布的平滑度。当温度设置得较低时,模型倾向于更集中地生成高概率词汇;而当温度较高时,概率分布会更加均匀,使得低概率词汇也有机会被选中,从而增加生成结果的多样性。通过调整温度参数,可以在生成质量和多样性之间找到平衡。 - Top-k Sampling:
在这种策略下,模型首先计算出下一个词的所有可能选项的概率分布,然后仅从概率最高的k个词中随机选取一个作为输出。这种方法减少了生成结果中低质量或不合理的词汇出现的可能性,并有助于提高生成序列的整体流畅性和合理性。 - Top-p (Nucleus) Sampling:
与 top-k 类似,但不是固定选择前 k 个最高概率的词,而是选择累积概率大于阈值 p(也称为截断阈值)的词汇集合(即“核”)。这种方式允许更多样化的词汇组合,同时避免了过于罕见的词汇被过度采样的问题,因此可以进一步提升生成内容的多样性和连贯性。
- Temperature Sampling:
2.3 模型训练
2.3.1 优化设置
在大型语言模型(LLMs)的优化设置中,以下因素至关重要:
-
Batch Training:
批量训练是深度学习中的常用策略,它允许模型同时处理一批样本,从而利用并行计算资源提高训练效率。对于 LLMs 而言,选择合适的批量大小对训练速度和模型性能有重要影响。通常,较大的批量大小可以加速训练,但可能会降低模型的泛化能力;而较小的批量则有利于捕捉更多样化的数据模式,但可能导致训练过程更慢。 -
Learning Rate:
学习率是决定模型参数更新幅度的关键超参数。适当的调整学习率可以加速收敛、改善模型表现,并避免过拟合或欠拟合。研究者采用多种学习率调度策略,如余弦退火、指数衰减、分段线性衰减等。 -
Optimizer:
选择正确的优化器对于LLMs的训练效果至关重要。常见的优化器包括 SGD(随机梯度下降)、Adam及其变种如 AdamW(添加了权重衰减),还有针对大规模模型优化的特定算法如 LAMB、Adafactor 等。这些优化器通过不同的方式来更新模型参数,以实现更好的收敛性和稳定性。 -
Stabilizing the Training:
稳定训练过程涉及到多个方面,包括但不限于正则化技术(如权重衰减、Dropout 等)、层归一化方法(LayerNorm、RMSNorm 等)、初始化策略的选择以及残差连接的使用。此外,为了避免梯度消失/爆炸问题,研究者还探索了各种先进的激活函数和注意力机制设计。在训练 LLMs 时,有时还会引入动态批标准化(Dynamic Batch Normalization)或混合专家架构(Mixture-of-Experts, MoE)来平衡计算资源和模型性能。
2.3.2 可扩展(Scalable)的训练技术
以下是现有 LLMs 的详细优化设置:
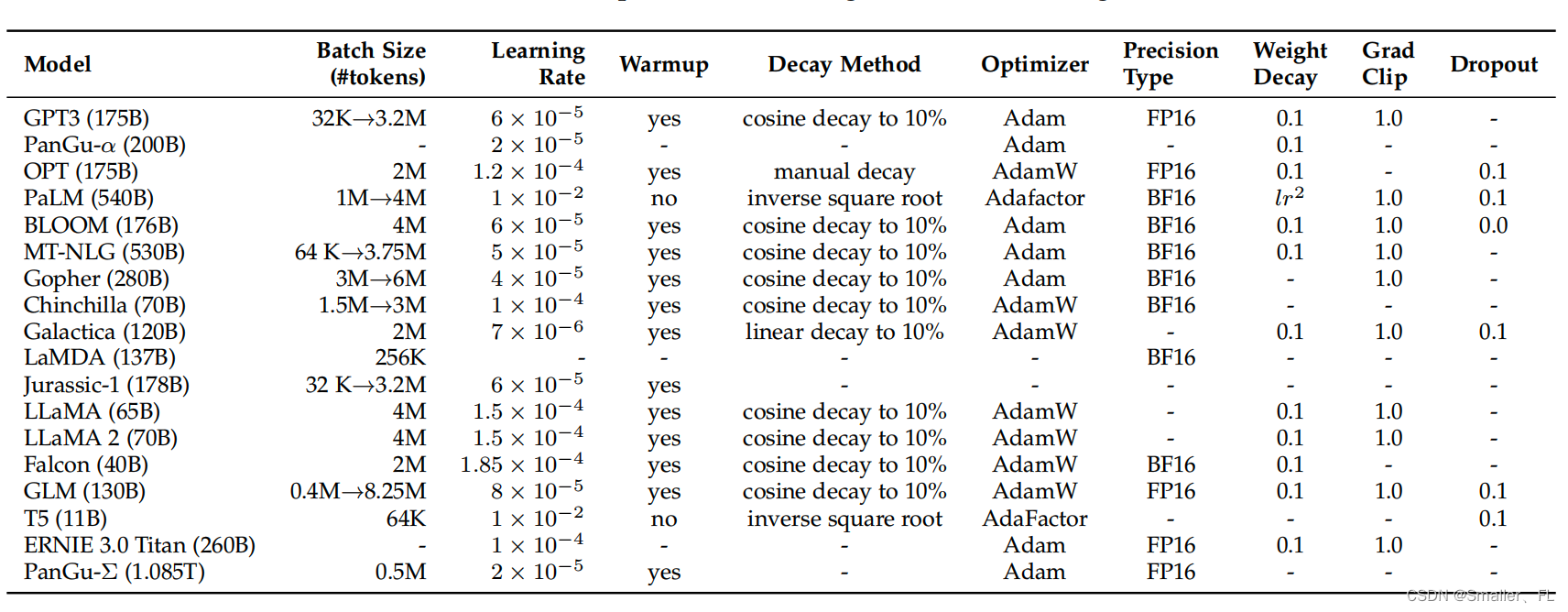
随着模型和数据规模的增加,在有限的计算资源下有效地训练 LLMs 需要解决两个主要的技术问题,:增加训练吞吐量、并将更大的模型加载到 GPU 内存中。以下是一些优化方式:
-
3D Parallelism:
三维并行化是一种将模型训练过程分解为三个维度的技术,包括数据并行性、模型并行性和流水线并行性。以下是三种主要的并行方式:- Data Parallelism:
数据并行是深度学习中最常用的一种并行方法。在这种模式下,模型参数在多台设备上保持副本,每个设备处理输入数据的不同子集(批次)。所有设备并行地进行前向传播和反向传播计算,并通过诸如All-Reduce通信操作将各个设备上的梯度求和,最终更新各自持有的模型参数副本。这种并行策略可以有效地利用多个GPU卡或服务器节点的计算资源。 - Pipeline Parallelism:
管道并行则关注于模型结构层面的并行化。它将深度学习模型按层切分成多个阶段,这些阶段分布在不同设备上,形成一个流水线式的处理流程。在一个时间步内,输入数据会依次经过各个阶段完成部分前向传播;而随着数据流向前推进,在最后一个阶段输出的同时,首个阶段开始处理新的批次数据。通过这种方式,管道并行能够在不增加显存需求的情况下训练更深、更大的模型。 - Tensor Parallelism:
张量并行(也称为模型并行)是另一种分割模型权重的方法。与数据并行相比,张量并行不是将整个模型复制到多台设备上,而是将模型内部某些大尺寸的权重矩阵沿某一维度拆分,然后分配给多个设备进行并行计算。例如,可以在隐层神经元之间进行张量并行,使得每一设备只负责一部分权重矩阵的运算。这有助于进一步突破单一设备的内存限制,尤其对于具有海量参数的大规模语言模型而言至关重要。
- Data Parallelism:
-
ZeRO (Zero Redundancy Optimizer):
ZeRO 是一种深度学习训练优化技术,它旨在减少 GPU 之间的通信开销,特别是对于大规模模型而言。ZeRO 采用了三层优化策略:数据分区消除冗余存储、梯度分区以减少通信量以及优化器状态分区。通过这些措施,ZeRO 使得各计算节点仅需保存其负责部分的参数、梯度和优化器状态,从而显著降低内存占用并提升大规模分布式训练的效率。 -
Mixed Precision Training:
混合精度训练是指在训练过程中同时使用单精度浮点数(FP32)和半精度浮点数(如FP16)。通常,权重更新和计算损失函数时采用 FP32 以保持数值稳定性,而在前向传播和反向传播的大部分计算环节则使用 FP16,从而减小内存需求并加速计算速度。这种方法能够有效利用现代 GPU 对半精度运算的高度优化支持,显著提高训练效率。 -
建议
对于大规模语言模型的训练,在实际应用中结合上述多种可扩展训练技术。首先,根据模型规模和硬件配置选择合适的并行策略(如3D 并行),其次利用 ZeRO 等内存优化技术减少通信成本和内存使用,最后结合混合精度训练以加快计算速度。此外,还需密切关注训练过程中的稳定性问题,适时调整学习率、正则化策略及超参数设置,确保模型能够高效收敛且具有良好的泛化性能。通过这些技术和策略的组合运用,可以有效地解决大规模 LLMs 训练面临的挑战,并进一步推动模型容量和性能边界的发展。
3. 参考
《A Survey of Large Language Models》
《NLP深入学习:《A Survey of Large Language Models》详细学习(一)》
《NLP深入学习:《A Survey of Large Language Models》详细学习(二)》
后续内容也在持续更新中…
欢迎关注本人,我是喜欢搞事的程序猿; 一起进步,一起学习;
也欢迎关注我的wx公众号:一个比特定乾坤

