
- 1面向 “大模型” 的未来服务架构设计_大模型架构
- 2【AI绘画】Stablediffusion的AI动画教学之Ebsynth Utillity_stable diffusion ebsynthutilty
- 3人体姿态识别(教程+代码)_webgl 人体识别
- 4Python——循环嵌套_在python 中,除了while循环与for循环,还有循环嵌套。循环嵌套就是在一个循环体里
- 5深入了解Transformer模型及其优缺点_transformer的优点
- 6Python文本分析---笔记_python中文文本分析
- 7python 命名实体识别_Python NLTK学习11(命名实体识别和关系抽取)
- 8NLP算法-情绪分析-snowNLP算法库
- 9Transformer预训练模型已经变革NLP领域,一文概览当前现状
- 10pytorch代码实现注意力机制之MHSA
AGI之MFM:《Multimodal Foundation Models: From Specialists to General-Purpose Assistants多模态基础模型:从专家到通用助
赞
踩
AGI之MFM:《Multimodal Foundation Models: From Specialists to General-Purpose Assistants多模态基础模型:从专家到通用助手》翻译与解读之简介
导读:本文是对展示视觉和视觉语言能力的多模态基础模型的全面调查,重点关注从专业模型向通用助手的过渡。本文涵盖了五个核心主题:
>> 视觉理解:本部分探讨了学习视觉骨干用于视觉理解的方法,包括监督预训练、对比语言图像预训练、仅图像的自监督学习以及多模态融合、区域级和像素级预训练。
>> 视觉生成:本部分讨论了视觉生成的各个方面,如视觉生成中的人类对齐、文本到图像生成、空间可控生成、基于文本的编辑、文本提示跟随以及概念定制。
>> 统一视觉模型:本部分考察了视觉模型从封闭集到开放集模型、任务特定模型到通用模型、静态到可提示模型的演变。
>> 加持LLMs的大型多模态模型:本部分探讨了使用大型语言模型(LLMs)进行大型多模态模型训练,包括在LLMs中进行指导调整以及指导调整的大型多模态模型的开发。
>> 多模态智能体:本部分重点关注将多模态工具与LLMs链接以创建多模态代理,包括对MM-REACT的案例研究、高级主题以及多种多模态代理的应用。
本文的关键论点包括视觉在人工智能中的重要性,多模态基础模型从专业模型向通用助手的演变,以及大型多模态模型和多模态代理在各种应用中的潜力。本文旨在面向计算机视觉和视觉语言多模态社区的研究人员、研究生和专业人士,他们希望了解多模态基础模型的基础知识和最新进展。
目录
《Multimodal Foundation Models: From Specialists to General-Purpose Assistants多模态基础模型:从专家到通用助手》翻译与解读
研究了两类的5个核心主题:成熟的研究领域(视觉主干法+文本到图像生成)、探索性开放研究领域(基于LLM的统一视觉模型+多模态LLM的端到端训练+与LLMs链接多模态工具)
1.1、What are Multimodal Foundation Models?什么是多模态基础模型?
两大技术背景=迁移学习(成为可能)+规模定律(变强大),2018年底的BERT标志着基础模型时代的开始
图1.2:本文旨在解决的三个多模态基础模型代表性问题的示意图
(3)、General-purpose Interface通用接口(为特定目的而设计):三个研究主题
与LLMs的训练(遵循指令+能力扩展到多模态+端到端的训练):如Flamingo和Multimodal GPT-4
与LLMs链接的工具(集成LLMs和多模态的基础模型):如Visual ChatGPT/MM-REACT
1.2、Definition and Transition from Specialists to General-Purpose Assistants定义和从专家到通用助手的过渡
两类多模型基础模型:特定目的的预训练视觉模型=视觉理解模型(CLIP/SimCLR/BEiT/SAM)+视觉生成模型(Stable Diffusion)、通用助手=统一架构的通才+遵循人类指令
1.3、Who Should Read this Paper?谁应该阅读本文?
Figure 1.3: An overview of the paper’s structure, detailing Chapters 2-6.
Relations among Chapters 2-6. 第2-6章之间的关系。
1.4、Related Materials: Slide Decks and Pre-recorded Talks相关资料:幻灯片和预录演讲
过去十年主要研究图像表示的方法:图像级别(图像分类/图像-文本检索/图像字幕)→区域级别(目标检测/短语定位)→像素级别(语义/实例/全景分割)
如何学习图像表示:两种方法(图像中挖掘出的监督信号/从Web上挖掘的图像-文本数据集的语言监督)、三种学习方式(监督预训练/CLIP/仅图像的自监督学习)
2.3、Contrastive Language-Image Pre-training对比语言-图像预训练
2.3.1、Basics of CLIP Training-CLIP训练基础
语言数据+训练方式,如CLIP/ALIGN/Florence/BASIC/OpenCLIP等
固定数据集并设计不同的算法→DataComp提出转向→固定的CLIP训练方法来选择和排名数据集
Objective function.目标函数:细粒度监督、对比式描述生成、仅使用字幕损失、用于语言-图像预训练的Sigmoid损失
2.4、Image-Only Self-Supervised Learning仅图像自监督学习:三类(对比学习/非对比学习/遮蔽图像建模)
2.4.1、Contrastive and Non-contrastive Learning
Non-contrastive learning.非对比学习
2.4.2、Masked Image Modeling遮蔽图像建模
Targets目标:两类(低级像素特征【更细粒度图像理解】、高级特征),损失函数的选择取决于目标的性质,离散标记的目标(通常使用交叉熵损失)+像素值或连续值特征(选择是ℓ1、ℓ2或余弦相似度损失)
MIM for video pre-training视频预训练的MIM:将MIM扩展到视频预训练,如BEVT/VideoMAE/Feichtenhofer
Lack of learning global image representations全局图像表示的不足,如iBOT/DINO/BEiT等
Scaling properties of MIM—MIM的规模特性:尚不清楚探讨将MIM预训练扩展到十亿级仅图像数据的规模
2.5、Synergy Among Different Learning Approaches不同学习方法的协同作用
Combining CLIP with label supervision将CLIP与标签监督相结合,如UniCL、LiT、MOFI
Combining CLIP with image-only (non-)contrastive learning将CLIP与图像仅(非)对比学习相结合:如SLIP、xCLIP
Combining CLIP with MIM将CLIP与MIM相结合
浅层交互:将CLIP提取的图像特征用作MIM训练的目标(CLIP图像特征可能捕捉了在MIM训练中缺失的语义),比如MVP/BEiTv2等
深度整合:BERT和BEiT的组合非常有前景,比如BEiT-3
2.6、Multimodal Fusion, Region-Level and Pixel-Level Pre-training多模态融合、区域级和像素级预训练
2.6.1、From Multimodal Fusion to Multimodal LLM从多模态融合到多模态LLM
基于双编码器的CLIP(图像和文本独立编码+仅通过两者特征向量的简单点乘实现模态交互):擅长图像分类/图像-文本检索,不擅长图像字幕/视觉问答
OD-based models基于OD的模型:使用共同注意力进行多模态融合(如ViLBERT/LXMERT)、将图像特征作为文本输入的软提示(如VisualBERT)
2.6.2、Region-Level Pre-training区域级预训练
CLIP:通过对比预训练学习全局图像表示+不适合细粒度图像理解的任务(如目标检测【包含两个子任务=定位+识别】等)
基于图像-文本模型进行微调(如OVR-CNN)、只训练分类头(如Detic)、
2.6.3、Pixel-Level Pre-training像素级预训练(代表作SAE):
Concurrent to SAM与SAM同时并行:OneFormer(一种通用的图像分割框架)、SegGPT(一种统一不同分割数据格式的通用上下文学习框架)、SEEM(扩展了单一分割模型)
VG的目的(生成高保真的内容),作用(支持创意应用+合成训练数据),关键(生成严格与人类意图对齐的视觉数据,比如文本条件)
3.1.1、Human Alignments in Visual Generation视觉生成中的人类对齐:核心(遵循人类意图来合成内容),四类探究
3.1.2、Text-to-Image Generation文本到图像生成
T2I的目的(视觉质量高+语义与输入文本相对应)、数据集(图像-文本对进行训练)
Stable Diffusion的详解:基于交叉注意力的图像-文本融合机制(如自回归T2I生成),三模块(图像VAE+去噪U-Net+条件编码器)
VAE:包含一对编码器E和解码器D,将RGB图像x编码为潜在随机变量z→对潜在变量解码重建图像
文本编码器:使用ViT-L/14 CLIP文本编码器将标记化的输入文本查询y编码为文本特征τ(y)
去噪U-Net:预测噪声λ (zt, t)与目标噪声λ之间的L2损失来训练
3.2、Spatial Controllable Generation空间可控生成
痛点:仅使用文本在某些描述方面是无效(比如空间引用),需额外空间输入条件来指导图像生成
Region-controlled T2I generation区域可控T2I生成:可显著提高生成高分辨率图像,但缺乏空间可控性,需开放性文本描述的额外输入条件,如ReCo/GLIGEN
GLIGEN:即插即用的方法,冻结原始的T2I模型+训练额外的门控自注意层
T2I generation with dense conditions—T2I生成与密集条件
ControlNet:基于稳定扩散+引入额外的可训练的ControlNet分支(额外的输入条件添加到文本提示中)
Uni-ControlNet(统一输入条件+使单一模型能够理解多种输入条件类型)、Disco(生成可控元素【人类主题/视频背景/动作姿势】人类跳舞视频=成功将背景和人体姿势条件分开;
ControlNet的两个不同分支【图像帧+姿势图】,人类主体、背景和舞蹈动作的任意组合性)
Inference-time spatial guidance推理时的空间指导:
文本到图像编辑:通过给定的图像和输入文本描述合成新的图像+保留大部分视觉内容+遵循人类意图
三个代表性方向:改变局部图像区域(删除或更高)、语言用作编辑指令、编辑系统集成不同的专业模块(如分割模型和大型语言模型)
3.4、Text Prompts Following文本提示跟随
采用图像-文本对鼓励但不强制完全遵循文本提示→当图像描述变得复时的两类研究=推断时操作+对齐调整
Summary and trends总结和趋势:目的(增强T2I模型更好地遵循文本提示能力),通过调整对齐来提升T2I模型根据文本提示生成图像的能力,未来(基于RL的方法更有潜力但需扩展)
3.5、Concept Customization概念定制:旨在使这些模型能够理解和生成与特定情况相关的视觉概念
语言的痛点:表达人类意图强大但全面描述细节效率较低,因此直接通过图像输入扩展T2I模型来理解视觉概念是更好的选择
三大研究(视觉概念自定义在T2I模型中的应用研究进展):单一概念定制、多概念定制、无Test-time微调的定制
Summary and trends摘要和趋势:早期(测试阶段微调嵌入)→近期(直接在冻结模型中执行上下文图像生成),两个应用=检索相关图像来促进生成+基于描述性文本指令的统一图像输入的不同用途
3.6、Trends: Unified Tuning for Human Alignments趋势:人类对齐的统一调整
调整T2I模型以更准确地符合人类意图的三大研究:提升空间可控性、编辑现有图像以改进匹配程度、个性化T2I模型以适应新的视觉概念
一个趋势:即朝着需要最小问题特定调整的整合性对齐解决方案转移
对齐调优阶段有两个主要目的:扩展了T2I的文本输入以合并交错的图像-文本输入,通过使用数据、损失和奖励来微调基本的T2I模型
Tuning with alignment-focused loss and rewards以对齐为焦点的损失和奖励的调整:
Closed-loop of multimodal content understanding and generation多模态内容理解和生成的闭环
4、Unified Vision Models统一的视觉模型
NLP的发展:2018年之前(不同的NLP任务使用不同的任务特定模型解决,如翻译/语义解析/摘要生成)→2018年之后(GPT-style模型+NST任务+指令微调,如ChatGPT)
建模方面:差异很大的视觉任务=不同类型输入的任务+不同粒度的任务+输出也具有不同的格式
数据方面:标注成本差异大且粒度和语义各异+收集图像成本高且数量少
Towards a unified vision model朝着统一视觉模型迈进:三大类研究=衔接视觉与语言的桥梁(如CLIP)+统一多任务建模+类似LLM的可提示接口
4.2、From Closed-Set to Open-Set Models从封闭集模型到开放集模型
传统基于任务的定制模型(如图像分类/目标检测,痛点=很难迁移)→近期提出CLIP(通过引入对比语言图像预训练方法来训练开放集模型+不是输入到标签的映射+学习而是学习对齐的视觉-语义空间)
CLIP模型引领了使用大量文本-图像对进行不同粒度的视觉理解模型的发展:图像级(如图像分类/图像-文本检索/图像字幕生成)、区域级(目标检测/短语定位)、像素级(图像分割/指代分割)
维度1:Model initialization模型初始化:
CLIP增强:使用预训练的CLIP模型来辅助模型训练,知识蒸馏CLIP特征(如ViLD)、利用CLIP模型提供特征和分数(例如MaskCLIP和Mask-Adapted CLIP)
其他方法:使用监督预训练模型或从零开始训练(如GLIP/OpenSeeD//)、采用联合训练的方法(如GroupViT)、利用预训练的稳定扩散模型提取紧凑的掩码(如ODISE)
端到端模型:将目标检测视为textual grounding语言地面匹配+整体训练
维度3:Model pre-training模型预训练:三种学习方法
监督学习:利用现有标注转换为语言监督训练=将标签监督转化为语言监督+使用现有的标注数据来训练开放式模型
半监督学习:同时利用标注数据和未标注或弱标记数据+通过丰富的语义信息提高模型的泛化能力
4.2.1、Object Detection and Grounding目标检测和定位
4.2.2、Image Segmentation and Referring图像分割和引用
图像分割:三个子任务(语义分割【每个像素的语义】+实例分割【相同语义含义的像素分组成对象】+全景分割【前二者】)
基于CNN的架构→基于Transformer的架构(如Mask2Former)
Unified Segmentation统一分割:将所有分割任务统一到单一框架中,如X-Decoder(重定义任务+使用通用的编码器-解码器结构)、UNINEXT(早期融合策略来统一不同的分割任务)
Figure 4.6: (a) CV task landscape
4.3、From Task-Specific Models to Generic Models从特定任务模型到通用模型
背景(之前模型主要针对单个任务设计+未能利用不同粒度或领域任务之间的协同关系)、两大原因(视觉任务分类多样【空间+时间+模态】+数据量规模不同→使得建立统一模型面临重重困难)
类别1—Sparse and discrete outputs稀疏和离散输出
UniTab:通过特殊符号统一文本和坐标输出,通过符号代表坐标进行序列解码实现不同任务输出统一
Pix2SeqV2:统一球体定位和引用分割,提出任务提示词来区分球体定位和引用分割两个任务
类别2—Dense and continuous outputs密集和连续输出
Unified-IO:采用多个VQ-VAE模型和Transformer编码器-解码器,预训练不同任务后端到端训练,来实现任务统一
扩散增强:使用已有的稳定扩散模型来构建通用的视觉模型,如Prompt Diffusion和InstructDiffusion
4.3.2、Functionality Unification功能统一
Unified learning统一学习:借助Transformer和开放集模型的发展,任务间障碍渐渐淡化,使得不同模态输入可以学习共享语义空间
GLIPv2—强调预训练策略:通过预训练任务融合定位与匹配模块训练
X-Decoder—注重设计支持不同任务学习:采用编码器-解码器架构+三个关键设计,分离图像与文本编码器支持不同粒度任务,通过不同类型查询和输出支撑不同粒度任务学习
Uni-Perceiver-v2—侧重统一不同数据级别任务学习:引入提议网络编码预测框来统一处理定位与非定位任务训练
4.4、From Static to Promptable Models从静态到可提示模型
4.4.1、Multi-modal Prompting多模态提示
4.4.2、In-context Prompting上下文提示
LLMs中的ICL能力使得模型可借助提示而无需更新模型参数,但视觉模型中的ICL能力的探究较少,两个尝试(如Flamingo和Kosmos-1)但只能生成文本输出
修复进行视觉提示的方法:通过修复输入图像的方式来教导模型预测稠密输出的方法
Painter→SegGPT :Painter通过预测连续像素输出实现不同任务统一,比如为分割任务用颜色表示不同个体、SegGPT基于Painter去专注图像分割应用
Hummingbird:利用目标与示例图像间的关注机制聚合信息,为密集预测任务匹配实例图像Label来进行预测。探索了一种新的视觉项目学习实现机制,即利用示例与目标间关联关系来传播语义信息
Discussion讨论:未来研究方向=单一模型能够在多模态输入下以上下文学习方式预测不同类型的输出
4.5、Summary and Discussion总结与讨论
视觉和语言间存在4大固有差异:数据标记处理、数据标签、数据多样性和存储成本
视觉和语言间的固有差异带来的三大探究:域外计算机视觉(无法涵盖世界全貌)、视觉中的规模定律(是否也会有类似LLMs的涌现能力)、以视觉为中心的模型(继续扩大模型规模还是采用适度规模去组合LLMs)
5、Large Multimodal Models: Training with LLM大型多模型:与LLM一起训练
5.1.1、Image-to-Text Generative Models图像到文本生成模型
目前LLM主要是一种图像到文本的生成模型:将图像作为输入/输出文本序列+采用编码器-解码器架构(图像编码器提取视觉特征/语言模型解码文本序列)+训练目标(通过文本自回归损失进行训练)
LLM的网络结构的不同实践(在架构和预训练策略上有差异+但共同遵循自回归训练目标):基于图像-文本对训练的GIT、BLIP2、基于交错的图像-文本序训练的Flamingo
5.2、Pre-requisite: Instruction Tuning in Large Language Models先决条件:大型语言模型中的指令调优
需要在训练中引入任务指令以提升模型通用性:传统的NLP数据表示使用seq2seq格式,但没有明确的任务指令,这导致模型难以在新任务上进行零迁移学习
指令语言数据:将任务指令明确加入模型训练,使模型能够通过任务组合在推理阶段执行多个任务,从而实现在未经训练的情况下解决新任务
5.2.1、Instruction Tuning指令调优:探索如何通过指令调优来使多模态语言模型(LLMs)能够遵循自然语言指令并完成现实世界的任务
两大方法:使用人类提供的任务指令和反馈进行微调、使用公共基准和数据集进行有监督微调
5.2.2、Self-Instruct and Open-Source LLMs自我指导和开源LLMs
开源社区涌现出众多开放式多模态语言模型,ChatGPT和GPT-4的成功为通过指令调优来改进开源LLMs提供了巨大机会
Further discussions进一步的讨论:三个研究方向,数据驱动AI、开源LLMs与专有LLMs之间的差距辩论、基础LLMs的发展
5.3、Instruction-Tuned Large Multimodal Models指导调整的大型多模态模型
Data Creation数据创建:提高模型的多模态能力=将图像转换为符号序列表示+采用图像的标题和边界框信息+三种类型的指令遵循数据
Performance性能:LLaVA是一个多模态聊天模型,通过自我指导方法在多模态指令遵循数据上进行微调,在多个任务和领域中展现了良好的性能
近期指令调优多模态语言模型研究呈现出蓬勃发展的势头,涌现出多个新模型和研究方向,将对多模态语言理解和生成领域产生重要影响。
Improving Visual Instruction Data Quantity and Quality改进视觉指导数据的数量和质量:
Multimodal In-Context-Learning多模态上下文学习:
Parameter-Efficient Training参数高效训练:精细调整成本过高→参数高效训练和模型量化是减小内存占用的有效方法
Benchmarks基准测试:通过对多个评估指标和数据集开展实验,结果显示开源模型在某些数据集上已与SOTA相当
Applications应用:通过在专业领域如医学等训练专项模型,采用自监督学习方法训练出能够开放回答图像研究问题的对话助
5.5、How Close We Are To OpenAI Multimodal GPT-4?我们距离OpenAI多模态GPT-4有多近?
6、Multimodal Agents:Chaining Tools with LLM 多模态智能代理:与LLM协同工作
提出新的建模范式:将多个工具或专家与LLMs协同链接以解决复杂的开放问题,不需要训练,只需要示例教导
建模范式的演变:特定任务模型→大型多模态模型→带有LLM的链接工具范式(无需任何训练+加持现有开源平台或API工具)
(1)、Evolution of modeling paradigm建模范式的演变:
特定任务的专用模型→预训练模型的二阶段(预训练+微调范式,如NLP中的BSRT系列、VL中的UNITER/OSCAR,仍是针对特定任务的微调)→
→基于通用的大型语言/多模态模型(比如GPT系列/PaLM/LLaMA系列/Flamingo)→基于通用模型的构建指令跟随(比如Alpaca/LLaVA【视觉指令调优】)
(2)、New modeling paradigm:新的建模范式:与LLM链接的工具链
痛点:基本功能上的挑战(数学推理/信息检索)、通用局限性(能力依赖于过时训练数据的世界而无法及时更新信息)
提出语言建模一种新的建模范式(外部NLP工具补充LLMs,如计算器/搜索引擎/翻译系统/日历等)→未来的智能代理(使用工具启用LLMs对多模态信号进行感知)
典型多模态智能体框架实现:通过用户与工具分配器的直接交互,由LLM担任分配器的大脑来规划使用单个或协同多个工具完成用户需求的步骤,执行后汇集结果输入到LLM中实现响应
Tools工具:提供LLM缺失的多模态信息,比如开源模型/API/代码解释器
Execution执行:由LLM翻译计划调用工具得到结果与用户对话
6.3、Case Study: MM-REACT案例研究:MM-REACT
6.3.1、System Design系统设计:MM-REACT设计智能体范式,通过ChatGPT作为大脑结合多模态视觉专家,支持图像和视频等多模态输入输出实现多模态推理与行动能力
User prompt用户提示:MM-REACT利用图像文件路径作为ChatGPT输入,让其在规划阶段通过调用视觉工具来理解图像内容并回答用户问题
Planning规划:MM-REACT通过提示词与正则判断是否需要外部工具,并提供工具描述与使用示例指导 ChatGPT合理调用视觉专家完成任务
Execution执行:MM-REACT通过正则匹配解析ChatGPT的动作请求,调用相应工具完成各类视觉任务后,汇总结果与ChatGPT对话,解决用户提出的问题。
6.3.2、Capabilities能力:MM-REACT 证明了多种代表性能力和应用场景
6.3.3、Extensibility可扩展性(工具链构建多模态智能体的优势):可扩展性的两大策略
(1)、Upgrading LLM升级LLM:MM-REACT的系统设计可不需重训练就将LLM升级为更强大的新模型,比如ChatGPT升级到多模态能力的GLP-4
6.4.1、Comparison to Training with LLM in Chapter与第五章中LLM训练的比较
构建基于LLM的高级多模态系统方向上的两个方法→融合两种范式优势的中间领域的可能性→探讨:否可以用LLaVA替代LLM作为工具分配器+需要哪些能力来启用工具
T1、通过指令调整实现端到端模型+直接解释多模态输入中的丰富语义+但需要数据筛选和训练+成本较高
T2、通过将LLM与现成的工具链接+借助上下文中的少样本示例来教导LLM进行规划+但存在如何选择工具的问题且弱领域专家导致性能差
6.4.2、Improving Multimodal Agents提高多模态智能体的性能
痛点:当前主要依赖上下文内的少样本示例来教导LLM进行规划,导致不够可靠和不准确
Improving accuracy in tool using: self-assessment提高工具使用的准确性—自我评估:AssistGPT试图通过自我评估提升工具使用准确性
LMM 作为工具分配器?将LMM替换为系统中的多模态工具分配器,取消统一工具输出为文本序列的需求,支持更自然的多模态工具交互,如模态GPT-4
6.4.3、Diverse Applications of Multimodal Agents多模态智能体的多样应用
通过组合来自特定领域的工具的系统范式可以支持多样化的领域特定应用,比如图像合成、机器人执行、音频生成、3D场景生成、医学图像理解和视觉语言导航等
6.4.4、Evaluation of Multimodal Agents多模态智能体的评估
多模态工具使用能力广泛但其工具使用准确率尚无定量研究:API-Bank(是在系统评估工具增强型LLM中的起点
NLP领域:探索通过编写代码或指令来即时创建工具以满足用户需求,比如CREATOR
多模态智能体领域:寻找方法来创建能够处理多模态输入的工具,比如ViperGPT/AutoML GPT
6.4.6、Retrieval-Augmented Multimodal Agents检索增强的多模态智能体
背景:大部分信息存储在数据库中,用户可能需要准确检索这些信息
NLP领域:通过外部数据以结构化语言和关系表示来增强LLMs,通过检索器检索相关文档并使用生成器生成预测,以解决无法将所有世界知识编码到预训练模型的权重中的问题
多模态智能体领域:基于检索增强模型的启发,利用视觉和/或文本知识来提高视觉任务,通过检索和应用外部知识,提供核心模型所需的额外信息来改善任务性能,比如RAC/K-LITE/REACT//
7、Conclusions and Research Trends结论和研究趋势
多模态基础模型在快速发展:共同的总体目标是—创建通用型模型能够遵循人类意图并执行各种域外视觉任务
7.1、Summary and Conclusions总结和结论:多模态基础模型研究的最新进展的两大类
特定用途的多模态基础模型:关注问题相关数据的预训练和零-少样本迁移
通用型助手:关注具有统一网络架构和接口的通用型助手模型研究,为视觉任务提供了类似于NLP中的通用助手的解决方案
7.2、Towards Building General-Purpose AI Agents迈向构建通用AI代理
专门的多模态基础模型→通用视觉助手:目前已出现强大的视觉助手(如Flamingo和 multimodal GPT-4相),但相比未来的多模态AI智能体仍处于初级阶段
Alignment with human intents与人类意图的对齐:视觉提示比语言表达更好,基于视觉提示的多模态人机交互是解锁新场景的关键
相关文章
AGI之MFM:《Multimodal Foundation Models: From Specialists to General-Purpose Assistants多模态基础模型:从专家到通用助手》翻译与解读之简介
AGI之MFM:《Multimodal Foundation Models: From Specialists to General-Purpose Assistants多模态基础模型:从专家到通用助手》翻译与解读之视觉理解、视觉生成
AGI之MFM:《多模态基础模型:从专家到通用助手》翻译与解读之视觉理解、视觉生成_一个处女座的程序猿的博客-CSDN博客
AGI之MFM:《Multimodal Foundation Models: From Specialists to General-Purpose Assistants多模态基础模型:从专家到通用助手》翻译与解读之统一的视觉模型、加持LLMs的大型多模态模型
AGI之MFM:《多模态基础模型:从专家到通用助手》翻译与解读之统一的视觉模型、加持LLMs的大型多模态模型-CSDN博客
AGI之MFM:《Multimodal Foundation Models: From Specialists to General-Purpose Assistants多模态基础模型:从专家到通用助手》翻译与解读之与LLM协同工作的多模态智能体、结论和研究趋势
AGI之MFM:《多模态基础模型:从专家到通用助手》翻译与解读之与LLM协同工作的多模态智能体、结论和研究趋势-CSDN博客
《Multimodal Foundation Models: From Specialists to General-Purpose Assistants多模态基础模型:从专家到通用助手》翻译与解读

| 地址 | |
| 时间 | 2023年9月18日 |
| 作者 | 微软团队 |
Abstract
研究了两类的5个核心主题:成熟的研究领域(视觉主干法+文本到图像生成)、探索性开放研究领域(基于LLM的统一视觉模型+多模态LLM的端到端训练+与LLMs链接多模态工具)
| This paper presents a comprehensive survey of the taxonomy and evolution of multimodal foundation models that demonstrate vision and vision-language ca-pabilities, focusing on the transition from specialist models to general-purpose assistants. The research landscape encompasses five core topics, categorized into two classes. (i) We start with a survey of well-established research areas: multi-modal foundation models pre-trained for specific purposes, including two topics –methods of learning vision backbones for visual understanding and text-to-image generation. (ii) Then, we present recent advances in exploratory, open research areas: multimodal foundation models that aim to play the role of general-purpose assistants, including three topics – unified vision models inspired by large lan-guage models (LLMs), end-to-end training of multimodal LLMs, and chaining multimodal tools with LLMs. The target audiences of the paper are researchers, graduate students, and professionals in computer vision and vision-language mul-timodal communities who are eager to learn the basics and recent advances in multimodal foundation models. | 本文提供了一份综合性的调查,涵盖了展示视觉和视觉语言能力的多模态基础模型的分类和演化,重点关注了从专业模型过渡到通用助手的过程。研究领域涵盖了五个核心主题,分为两类。 (i)我们首先调查了一些成熟的研究领域:为特定目的预先训练的多模态基础模型,包括两个主题——用于视觉理解的学习视觉主干方法和文本到图像的生成。。 (ii)然后,我们介绍了探索性开放研究领域的最新进展:旨在扮演通用助手角色的多模态基础模型,包括三个主题 - 受大型语言模型(LLMs)启发的统一视觉模型、多模态LLMs的端到端训练以及与LLMs链接多模态工具。本文的目标受众是渴望学习多模态基础模型的基础知识和最新进展的计算机视觉和视觉语言社区的研究人员、研究生和专业人员。 |
1 Introduction
| Vision is one of the primary channels for humans and many living creatures to perceive and interact with the world. One of the core aspirations in artificial intelligence (AI) is to develop AI agents to mimic such an ability to effectively perceive and generate visual signals, and thus reason over and interact with the visual world. Examples include recognition of the objects and actions in the scenes, and creation of sketches and pictures for communication. Building foundational models with visual capabilities is a prevalent research field striving to accomplish this objective. | 视觉是人类和许多生物感知和与世界互动的主要渠道之一。人工智能(AI)的核心目标之一是开发AI代理,模仿这种有效感知和生成视觉信号的能力,从而在视觉世界中进行推理和互动。示例包包括对场景中物体和动作的识别,以及创建用于沟通的草图和图片。建立具有视觉能力的基础模型是一个广泛存在的研究领域,旨在实现这一目标。 |
特定任务的模型(需从头开始训练)→基于语言理解和生成的语言模型(为适应下游任务提供基础,如BERT/GPT-2等)→基于大统一的大型语言模型LLMs(出现新兴能力【如ICL/CoT】,如GPT-3等)→基于通用助手的LLMs(有趣的能力【互动和使用工具】,如ChatGPT/GPT-4)
| Over the last decade, the field of AI has experienced a fruitful trajectory in the development of models. We divide them into four categories, as illustrated in Figure 1.1. The categorization can be shared among different fields in AI, including language, vision and multimodality. We first use language models in NLP to illustrate the evolution process. (i) At the early years, task-specific mod- els are developed for individual datasets and tasks, typically being trained from scratch. (ii) With large-scale pre-training, language models achieve state-of-the-art performance on many established language understanding and generation tasks, such as BERT (Devlin et al., 2019), RoBERTa (Liu et al., 2019), T5 (Raffel et al., 2020), DeBERTa (He et al., 2021) and GPT-2 (Radford et al., 2019)). These pre-trained models serve the basis for downstream task adaptation. (iii) Exemplified by GPT-3 (Brown et al., 2020), large language models (LLMs) unify various language understanding and generation tasks into one model. With web-scale training and unification, some emerging ca- pabilities appear, such as in-context-learning and chain-of-thoughts. (iv) With recent advances in human-AI alignment, LLMs start to play the role of general-purpose assistants to follow human intents to complete a wide range of language tasks in the wild, such as ChatGPT (OpenAI, 2022) and GPT-4 (OpenAI, 2023a). These assistants exhibit interesting capabilities, such as interaction and tool use, and lay a foundation for developing general-purpose AI agents. It is important to note that the latest iterations of foundation models build upon the noteworthy features of their earlier counterparts while also providing additional capabilities. | 在过去的十年里,AI领域在模型的发展方面经历了一个富有成效的轨迹。我们将它们分为四个类别,如图1.1所示。这种分类可以在AI的不同领域共享,包括语言、视觉和多模态。我们首先使用自然语言处理(NLP)中的语言模型来说明演化过程。 (i) 在早期,为个别数据集和任务开发了特定任务的模型,通常是从头开始训练的。 (ii) 借助大规模预训练,语言模型在许多已建立的语言理解和生成任务上取得了最先进的性能,如BERT(Devlin等人,2019)、RoBERTa(Liu等人,2019)、T5(Raffel等人,2020)、DeBERTa(He等人,2021)和GPT-2(Radford等人,2019)。这些预训练模型为下游任务的适应提供了基础。 (iii) 以GPT-3(Brown等人,2020)为代表,大型语言模型(LLMs)将各种语言理解和生成任务统一到一个模型中。通过规模庞大的训练和统一,出现了一些新兴的能力,如上下文学习ICL和思维链CoT。 (iv) 随着人工智能与人类意图的对齐的最新进展,LLMs开始扮演通用助手的角色,遵循人类的意图,在域外完成各种语言任务,如ChatGPT(OpenAI,2022)和GPT-4(OpenAI,2023a)。这些助手展示出了有趣的能力,如互动和工具使用,并为开发通用AI代理奠定了基础。重要的是要注意,最新的基础模型版本在保留其早期版本的显著特征的基础上,还提供了额外的功能。 |
| Inspired by the great successes of LLMs in NLP, it is natural for researchers in the computer vision and vision-language community to ask the question: what is the counterpart of ChatGPT/GPT-4 for vision, vision-language and multi-modal models? There is no doubt that vision pre-training and vision-language pre-training (VLP) have attracted a growing attention since the birth of BERT, and has become the mainstream learning paradigm for vision, with the promise to learn universal transferable visual and vision-language representations, or to generate highly plausible images. Ar- guably, they can be considered as the early generation of multimodal foundation models, just as BERT/GPT-2 to the language field. While the road-map to build general-purpose assistants for lan- guage such as ChatGPT is clear, it is becoming increasingly crucial for the research community to explore feasible solutions to building its counterpart for computer vision: the general-purpose visual assistants. Overall, building general-purpose agents has been a long-standing goal for AI. LLMs with emerging properties have significantly reduced the cost of building such agents for language tasks. Similarly, we foresee emerging capabilities from vision models, such as following the instruc- tions composed by various visual prompts like user-uploaded images, human-drawn clicks, sketches and mask, in addition to text prompt. Such strong zero-shot visual task composition capabilities can significantly reduce the cost of building AI agents. | 受到LLMs在NLP领域的巨大成功的启发,计算机视觉和视觉语言社区的研究人员很自然地会提出这样的问题:对于视觉、视觉语言和多模态模型,ChatGPT/GPT-4的对应物是什么? 毫无疑问,自BERT诞生以来,视觉预训练和视觉语言预训练(VLP)已经引起了越来越多的关注,并已成为视觉领域的主流学习范式,有望学习普遍可转移的视觉和视觉语言表征,或生成高度可信的图像。可以说,它们可以被视为多模态基础模型的早期代表,就像BERT/GPT-2对语言领域一样。虽然建立像ChatGPT这样的语言通用助手的路线图已经明确,但对于计算机视觉的对应物——通用视觉助手,研究社区越来越需要探索可行的解决方案。 总的来说,构建通用代理已经是AI的长期目标。LLMs的新兴特性极大地降低了为语言任务构建这种代理的成本。同样,我们预见到视觉模型的新兴能力,例如除了文本提示外,还可以遵循由各种视觉提示组成的指令,如用户上传的图像、人工绘制的点击、草图和掩码,这种强大的零样本视觉任务组成能力可以显著降低构建AI代理的成本。 |
图1.1:语言和视觉/多模态基础模型发展轨迹的示意图

| Figure 1.1: Illustration of foundation model development trajectory for language and vision/multi- modality. Among the four categories, the first category is the task-specific model, and the last three categories belong to foundation models, where these foundation models for language and vision are grouped in green and blue blocks, respectively. Some prominent properties of models in each category are highlighted. By comparing the models between language and vision, we are foreseeing that the transition of multimodal foundation models follows a similar trend: from the pre-trained model for specific purpose, to unified models and general-purpose assistants. However, research 1 exploration is needed to figure out the best recipe, which is indicated as the question mark in the figure, as multimodal GPT-4 and Gemini stay private. | 图1.1:语言和视觉/多模态的基础模型发展轨迹示意图。在四个类别中,第一类别是特定于任务的模型,而最后三个类别属于基础模型,其中语言和视觉的基础模型分别以绿色和蓝色方块分组。突出显示了每个类别中模型的一些显著特性。通过比较语言和视觉之间的模型,我们预见多模态基础模型的转变会遵循类似的趋势:从针对特定目的的预训练模型到统一模型和通用助手。然而,因为多模态GPT-4和Gemini仍然保密,仍需要进行研究探索以找出最佳的方法,这在图中用问号表示。 |
| In this paper, we limit the scope of multimodal foundation models to the vision and vision-language domains. Recent survey papers on related topics include (i) image understanding models such as self-supervised learning (Jaiswal et al., 2020; Jing and Tian, 2020; Ozbulak et al., 2023), segment anything (SAM) (Zhang et al., 2023a,c), (ii) image generation models (Zhang et al., 2023b; Zhou and Shimada, 2023), and (iii) vision-language pre-training (VLP). Existing VLP survey papers cover VLP methods for task-specific VL problems before the era of pre-training, image-text tasks, core vision tasks, and/or video-text tasks (Zhang et al., 2020; Du et al., 2022; Li et al., 2022c; Ruan and Jin, 2022; Chen et al., 2022a; Gan et al., 2022; Zhang et al., 2023g). Two recent survey papers cover the integration of vision models with LLM (Awais et al., 2023; Yin et al., 2022). | 在本文中,我们将多模态基础模型的范围限定在视觉和视觉语言领域。最近关于相关主题的调查论文包括 (i)图像理解模型,如自监督学习(Jaiswal等,2020;Jing和Tian,2020;Ozbulak等,2023)、任何物体分割(SAM)(Zhang等,2023a,c)、 (ii)图像生成模型(Zhang等,2023b;Zhou和Shimada,2023),以及 (iii)视觉语言预训练(VLP)。现有的VLP调查论文涵盖了VLP方法,用于在预训练时代之前的特定任务的VL问题,图像-文本任务,核心视觉任务和/或视频文本任务(Zhang等,2020;Du等,2022;Li等,2022c;Ruan和Jin,2022;Chen等,2022a;Gan等,2022;Zhang等,2023g)。最近有两篇调查论文涵盖了将视觉模型与LLM集成在一起的问题(Awais等,2023;Yin等,2022)。 |
| Among them, Gan et al. (2022) is a survey on VLP that covers the CVPR tutorial series on Recent Advances in Vision-and-Language Research in 2022 and before. This paper summarizes the CVPR tutorial on Recent Advances in Vision Foundation Models in 2023. Different from the aforemen- tioned survey papers that focus on literature review of a given research topic, this paper presents our perspectives on the role transition of multimodal foundation models from specialists to general- purpose visual assistants, in the era of large language models. The contributions of this survey paper are summarized as follows. >> We provide a comprehensive and timely survey on modern multimodal foundation models, not only covering well-established models for visual representation learning and image generation, but also summarizing emerging topics for the past 6 months inspired by LLMs, including unified vision models, training and chaining with LLMs. >> The paper is positioned to provide the audiences with the perspective to advocate a transition in developing multimodal foundation models. On top of great modeling successes for specific vi- sion problems, we are moving towards building general-purpose assistants that can follow human intents to complete a wide range of computer vision tasks in the wild. We provide in-depth discus- sions on these advanced topics, demonstrating the potential of developing general-purpose visual assistants. | 其中,Gan等(2022)是一份关于VLP的调查,涵盖了2022年及以前的CVPR视觉与语言研究的最新进展教程系列。本文总结了2023年的CVPR视觉基础模型最新进展教程。与前述调查论文不同,它们侧重于给定研究主题的文献综述,本文提出了我们对多模态基础模型从专业人员向通用视觉助手的角色转变的看法,在大型语言模型时代。本调查论文的贡献总结如下。 >> 我们对现代多模态基础模型进行了全面和及时的调查,不仅涵盖了视觉表示学习和图像生成的成熟模型,还总结了受LLMs启发的过去6个月出现的新兴主题,包括统一视觉模型、与LLMs的训练和链接。 >>本文旨在为读者提供一个视角,倡导发展多模态基础模型的转型。在对特定视觉问题建模取得巨大成功的基础上,我们正朝着构建通用助手的方向发展,它可以跟随人类的意图,在域外完成广泛的计算机视觉任务。我们对这些高级主题进行了深入的讨论,展示了开发通用视觉助手的潜力。 |
1.1、What are Multimodal Foundation Models?什么是多模态基础模型?
两大技术背景=迁移学习(成为可能)+规模定律(变强大),2018年底的BERT标志着基础模型时代的开始
| As elucidated in the Stanford foundation model paper (Bommasani et al., 2021), AI has been under- going a paradigm shift with the rise of models (e.g., BERT, GPT family, CLIP (Radford et al., 2021) and DALL-E (Ramesh et al., 2021a)) trained on broad data that can be adapted to a wide range of downstream tasks. They call these models foundation models to underscore their critically central yet incomplete character: homogenization of the methodologies across research communities and emergence of new capabilities. From a technical perspective, it is transfer learning that makes foun- dation models possible, and it is scale that makes them powerful. The emergence of foundation models has been predominantly observed in the NLP domain, with examples ranging from BERT to ChatGPT. This trend has gained traction in recent years, extending to computer vision and other fields. In NLP, the introduction of BERT in late 2018 is considered as the inception of the foundation model era. The remarkable success of BERT rapidly stimulates interest in self-supervised learning in the computer vision community, giving rise to models such as SimCLR (Chen et al., 2020a), MoCo (He et al., 2020), BEiT (Bao et al., 2022), and MAE (He et al., 2022a). During the same time period, the success of pre-training also significantly promotes the vision-and-language multimodal field to an unprecedented level of attention. | 正如斯坦福基础模型论文(Bommasani等,2021)所阐明的那样,随着模型的崛起(例如BERT、GPT家族、CLIP(Radford等,2021)和DALL-E(Ramesh等,2021a)),人工智能正在经历一场范式转变,这些模型是在广泛数据上训练的,可以适应各种下游任务。他们将这些模型称为基础模型,以强调其关键的核心但不完整的特征:跨研究社区的方法同质化和新能力的出现。 从技术角度来看,正是迁移学习使得基础模型成为可能,规模(定律)使得它们变得强大。基础模型的出现主要在NLP领域观察到,从BERT到ChatGPT都有例证。这一趋势近年来逐渐受到重视,扩展到计算机视觉和其他领域。在NLP领域,2018年底引入BERT被视为基础模型时代的开始。BERT的显著成功迅速激发了计算机视觉社区对自监督学习的兴趣,催生了模型如SimCLR(Chen等,2020a)、MoCo(He等,2020)、BEiT(Bao等,2022)和MAE(He等,2022a)的出现。在同一时期,预训练的成功也显著地将视觉和语言多模态领域提升到前所未有的关注水平。 |
图1.2:本文旨在解决的三个多模态基础模型代表性问题的示意图
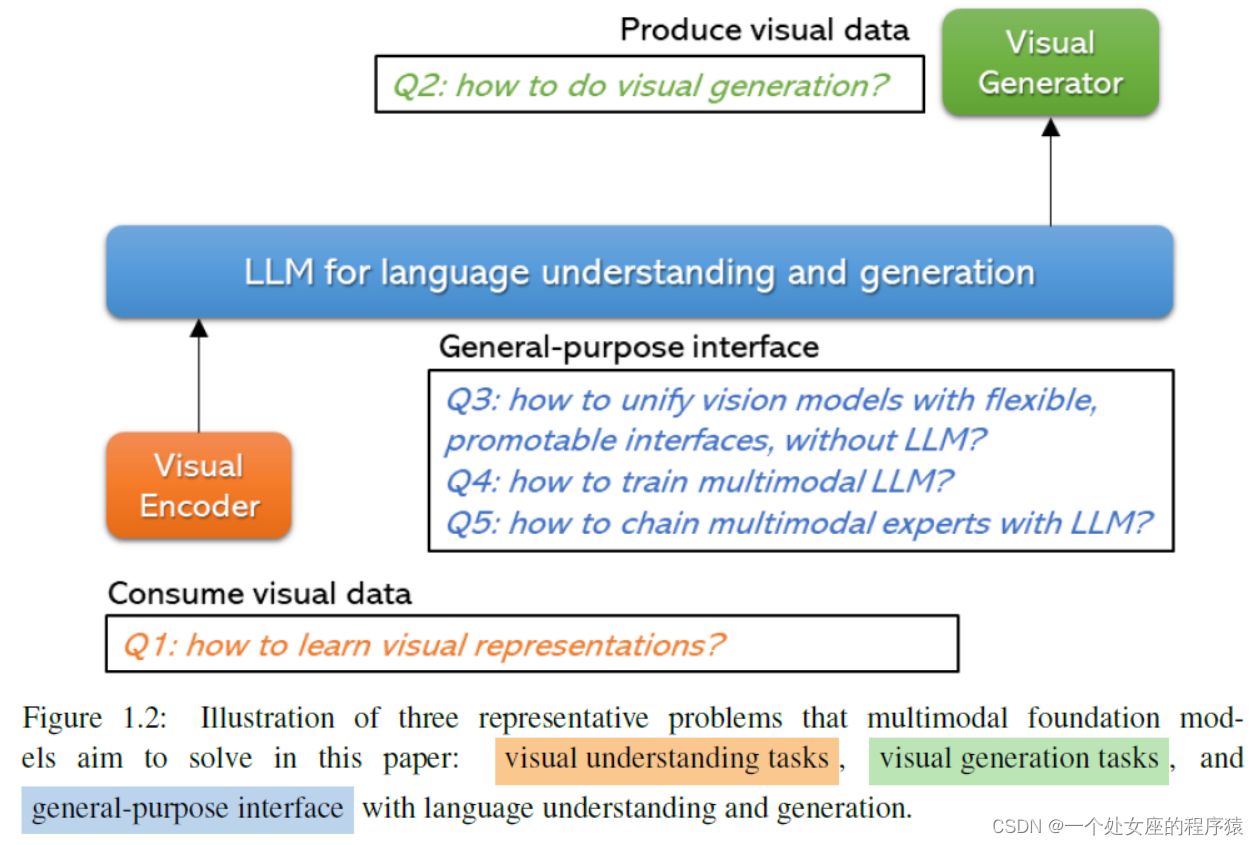
| Figure 1.2: Illustration of three representative problems that multimodal foundation models aim to solve in this paper: visual understanding tasks , visual generation tasks , and general-purpose interface with language understanding and generation. | 图1.2:本文旨在解决的三个多模态基础模型代表性问题的示意图:视觉理解任务、视觉生成任务以及与语言理解和生成的通用接口。 |
| In this paper, we focus on multimodal foundation models, which inherit all properties of foundation models discussed in the Stanford paper (Bommasani et al., 2021), but with an emphasis on models with the capability to deal with vision and vision-language modalities. Among the ever-growing literature, we categorize multimodal foundation models in Figure 1.2, based on their functional- ity and generality. For each category, we present exemplary models that demonstrate the primary capabilities inherent to these multimodal foundation models. | 在本文中,我们专注于多模态基础模型,它继承了斯坦福论文中讨论的基础模型的所有属性(Bommasani et al., 2021),但重点关注具有处理视觉和视觉语言模态能力的模型。在不断增长的文献中,我们根据其功能和通用性对图1.2中的多模态基础模型进行了分类。对于每个类别,我们提供了示例模型,展示了这些多模态基础模型固有的主要能力。 |
(1)、Visual Understanding Models. 视觉理解模型:三级范围(图像级→区域级→像素级),三类方法(基于监督信号不同,标签监督【如ImageNet】/语言监督【如CLIP和ALIGN】/仅图像自监督【如对比学习等】/多模态融合【如CoCa/Flamingo/GLIP/SAM】)
| (Highlighted with orange in Figure 1.2) Learning general visual representations is essential to build vision foundation models, as pre-training a strong vision back- bone is foundamental to all types of computer vision downstream tasks, ranging from image-level (e.g., image classification, retrieval, and captioning), region-level (e.g., detection and grounding) to pixel-level tasks (e.g., segmentation). We group the methods into three categories, depending on the types of supervision signals used to train the models. >>Label supervision. Datasets like ImageNet (Krizhevsky et al., 2012) and ImageNet21K (Rid- nik et al., 2021) have been popular for supervised learning, and larger-scale proprietary datasets are also used in industrial labs (Sun et al., 2017; Singh et al., 2022b; Zhai et al., 2022a). >>Language supervision. Language is a richer form of supervision. Models like CLIP (Radford et al., 2021) and ALIGN (Jia et al., 2021) are pre-trained using a contrastive loss over millions or even billions of noisy image-text pairs mined from the Web. These models enable zero- shot image classification, and make traditional computer vision (CV) models to perform open-vocabulary CV tasks. We advocate the concept of computer vision in the wild,1 and encourage the development and evaluation of future foundation models for this. >>Image-only self-supervision. This line of work aims to learn image representations from su- pervision signals mined from the images themselves, ranging from contrastive learning (Chen et al., 2020a; He et al., 2020), non-contrastive learning (Grill et al., 2020; Chen and He, 2021; Caron et al., 2021), to masked image modeling (Bao et al., 2022; He et al., 2022a). >>Multimodal fusion, region-level and pixel-level pre-training. Besides the methods of pre- training image backbones, we will also discuss pre-training methods that allow multimodal fusion (e.g., CoCa (Yu et al., 2022a), Flamingo (Alayrac et al., 2022)), region-level and pixel- level image understanding, such as open-set object detection (e.g., GLIP (Li et al., 2022e)) and promptable semgentation (e.g., SAM (Kirillov et al., 2023)). These methods typically rely on a pre-trained image encoder or a pre-trained image-text encoder pair. | (在图1.2中以橙色突出显示)学习一般性的视觉表示对于构建视觉基础模型至关重要,因为预训练一个强大的视觉骨干是所有类型的计算机视觉下游任务的基础,范围从图像级(例如,图像分类、检索和字幕)、区域级(例如,检测和接地)到像素级任务(例如,分割)。根据用于训练模型的监督信号的类型,我们将这些方法分为三类。 >>标签监督。像ImageNet(Krizhevsky等,2012)和ImageNet21K(Ridnik等,2021)这样的数据集一直以来都在监督学习中很受欢迎,工业实验室也使用了规模更大的专有数据集(Sun等,2017;Singh等,2022b;Zhai等,2022a)。 >>语言监督。语言是一种更丰富的监督形式。像CLIP(Radford等,2021)和ALIGN(Jia等,2021)这样的模型是使用从网络上挖掘的数百万甚至数十亿的噪声图像-文本对的对比损失进行预训练的。这些模型使得零采样图像分类成为可能,并使传统的计算机视觉(CV)模型能够执行开放词汇的CV任务。我们倡导域外计算机视觉的概念,并鼓励为此开发和评估未来的基础模型。 >>仅图像自监督。这一领域的工作旨在从图像本身挖掘监督信号,学习图像表示,包括对比学习(Chen等,2020a;He等,2020)、非对比学习(Grill等,2020;Chen和He,2021;Caron等,2021)以及图像掩码建模(Bao等,2022;He等,2022a)等。 >>多模态融合、区域级别和像素级预训练。除了预训练图像主干的方法外,我们还将讨论允许多模态融合(例如CoCa(Yu等,2022a)、Flamingo(Alayrac等,2022))以及区域级别和像素级别图像理解的预训练方法,例如开放式目标检测(例如GLIP(Li等,2022e))和可提示分割(例如SAM(Kirillov等,2023))。这些方法通常依赖于预训练的图像编码器或预训练的图像-文本编码器对。 |
(2)、Visual Generation Models. 视觉生成模型:三大技术(量量化VAE方法/基于扩散的模型/回归模型),两类(文本条件的视觉生成【文本到图像生成模型{DALL-E/Stable Diffusion/Imagen}+文本到视频生成模型{Imagen Video/Make-A-Video}】、人类对齐的视觉生成器)
| (Highlighted with green in Figure 1.2) Recently, foundation image generation models have been built, due to the emergence of large-scale image-text data. The techniques that make it possible include the vector-quantized VAE methods (Razavi et al., 2019), diffusion-based models (Dhariwal and Nichol, 2021) and auto-regressive models. >>Text-conditioned visual generation. This research area focuses on generating faithful vi- sual content, including images, videos, and more, conditioned on open-ended text descrip- tions/prompts. Text-to-image generation develops generative models that synthesize images of high fidelity to follow the text prompt. Prominent examples include DALL-E (Ramesh et al., 2021a), DALL-E 2 (Ramesh et al., 2022), Stable Diffusion (Rombach et al., 2021; sta, 2022), Imagen (Saharia et al., 2022), and Parti (Yu et al., 2022b). Building on the success of text- to-image generation models, text-to-video generation models generate videos based on text prompts, such as Imagen Video (Ho et al., 2022) and Make-A-Video (Singer et al., 2022). >>Human-aligned visual generator. This research area focuses on improving the pre-trained visual generator to better follow human intentions. Efforts have been made to address vari- ous challenges inherent to base visual generators. These include improving spatial control- lability (Zhang and Agrawala, 2023; Yang et al., 2023b), ensuring better adherence to text prompts (Black et al., 2023), supporting flexible text-based editing (Brooks et al., 2023), and facilitating visual concept customization (Ruiz et al., 2023). | (在图1.2中以绿色突出显示)近年来,由于大规模图像-文本数据的出现,建立了基础图像生成模型。使之成为可能的技术包括向量量化VAE方法(Razavi等,2019)、基于扩散的模型(Dhariwal和Nichol,2021)和自回归模型。 >>文本条件的视觉生成。这一研究领域专注于生成忠实于开放性文本描述/提示的视觉内容,包括图像、视频等。文本到图像生成开发了生成模型,能够根据文本提示合成高保真度的图像。著名的示例包括DALL-E(Ramesh等,2021a)、DALL-E 2(Ramesh等,2022)、Stable Diffusion(Rombach等,2021;sta,2022)、Imagen(Saharia等,2022)和Parti(Yu等,2022b)。在文本到图像生成模型取得成功的基础上,文本到视频生成模型基于文本提示生成视频,如Imagen Video(Ho等,2022)和Make-A-Video(Singer等,2022)等。 >>人类对齐的视觉生成器。这一研究领域专注于改进预训练的视觉生成器以更好地遵循人类意图。努力解决基础视觉生成器固有的各种挑战。这些包括提高空间控制不稳定性(Zhang和Agrawala,2023;Yang等,2023b)、确保更好地遵循文本提示(Black等,2023)、支持灵活的基于文本的编辑(Brooks等,2023)以及促进视觉概念定制化(Ruiz等,2023)等。 |
(3)、General-purpose Interface通用接口(为特定目的而设计):三个研究主题
| (3)、General-purpose Interface. (Highlighted with blue in Figure 1.2) The aforementioned multi- modal foundation models are designed for specific purposes – tackling a specific set of CV prob- lems/tasks. Recently, we see an emergence of general-purpose models that lay the basis of AI agents. Existing efforts focus on three research topics. The first topic aims to unify models for vi- sual understanding and generation. These models are inspired by the unification spirit of LLMs in NLP, but do not explicitly leverage pre-trained LLM in modeling. In contrast, the other two topics embrace and involve LLMs in modeling, including training and chaining with LLMs, respectively. | (在图1.2中以蓝色突出显示)上述多模态基础模型是为特定目的而设计的,旨在解决一组特定的CV问题/任务。最近,我们看到了通用模型的出现,为AI代理打下了基础。现有的努力集中在三个研究主题上。第一个主题旨在统一用于视觉理解和生成的模型。这些模型受到NLP中LLMs统一精神的启发,但没有明确地在建模中利用预训练的LLM。相反,其他两个主题在建模中涵盖和涉及LLMs,包括与LLMs的训练和链接。 |
用于理解和生成的统一视觉模型:采用统一的模型体系结构(如CLIP/GLIP/OpenSeg)、统一不同粒度级别的不同VL理解任务(如IO统一方法/Unified-IO/GLIP-v2/X-Decoder)、具互动性和提示性(如SAM/SEEM )
| >>Unified vision models for understanding and generation. In computer vision, several at- tempts have been made to build a general-purpose foundation model by combining the func- tionalities of specific-purpose multimodal models. To this end, a unified model architecture is adopted for various downstream computer vision and vision-language (VL) tasks. There are different levels of unification. First, a prevalent effort is to bridge vision and language by converting all closed-set vision tasks to open-set ones, such as CLIP (Radford et al., 2021), GLIP (Li et al., 2022f), OpenSeg (Ghiasi et al., 2022a), etc. Second, the unification of differ- ent VL understanding tasks across different granularity levels is also actively explored, such as I/O unification methods like UniTAB (Yang et al., 2021), Unified-IO (Lu et al., 2022a)), Pix2Seq-v2 (Chen et al., 2022d) and functional unification methods like GPV (Gupta et al., 2022a), GLIP-v2 (Zhang et al., 2022b)) and X-Decoder (Zou et al., 2023a). In the end, it is also necessitated to make the models more interactive and promptable like ChatGPT, and this has been recently studied in SAM (Kirillov et al., 2023) and SEEM (Zou et al., 2023b). | >>用于理解和生成的统一视觉模型。在计算机视觉领域,已经有几个尝试通过结合特定用途的多模态模型的功能来构建通用基础模型。为此,对各种下游计算机视觉和视觉语言(VL)任务采用统一的模型体系结构。有不同层次的统一。首先,一个普遍的努力是通过将所有封闭集视觉任务转化为开放集视觉任务来架起视觉和语言的桥梁,例如CLIP(Radford等,2021)、GLIP(Li等,2022f)、OpenSeg(Ghiasi等,2022a)等。其次,还积极探索了不同粒度级别的不同VL理解任务的统一,如I/O统一方法(如UniTAB(Yang等,2021)、Unified-IO(Lu等,2022a))和功能统一方法(如GPV(Gupta等,2022a)、GLIP-v2(Zhang等,2022b)和X-Decoder(Zou等,2023a)等。最后,还需要使模型像ChatGPT一样更具互动性和提示性,最近在SAM (Kirillov et al., 2023)和SEEM (Zou et al., 2023b)中对此进行了研究。 |
与LLMs的训练(遵循指令+能力扩展到多模态+端到端的训练):如Flamingo和Multimodal GPT-4
| >>Training with LLMs. Similar to the behavior of LLMs, which can address a language task by following the instruction and processing examples of the task in their text prompt, it is desirable to develop a visual and text interface to steer the model towards solving a multimodal task. By extending the capability of LLMs to multimodal settings and training the model end-to-end, multimodal LLMs or large multimodal models are developed, including Flamingo (Alayrac et al., 2022) and Multimodal GPT-4 (OpenAI, 2023a). | >>与LLMs的训练。与LLMs的行为类似,LLMs可以通过遵循指令和处理任务的文本提示中的示例来解决语言任务,因此有必要开发一个视觉和文本接口,以引导模型解决多模态任务。通过将LLMs的能力扩展到多模态设置并进行端到端的训练,开发了多模态LLMs或大型多模态模型,包括Flamingo(Alayrac等,2022)和Multimodal GPT-4(OpenAI,2023a)等。 |
与LLMs链接的工具(集成LLMs和多模态的基础模型):如Visual ChatGPT/MM-REACT
| >>Chaining tools with LLM. Exploiting the tool use capabilities of LLMs, an increasing num- ber of studies integrate LLMs such as ChatGPT with various multimodal foundation models to facilitate image understanding and generation through a conversation interface. This interdis- ciplinary approach combines the strengths of NLP and computer vision, enabling researchers to develop more robust and versatile AI systems that are capable of processing visual informa- tion and generating human-like responses via human-computer conversations. Representative works include Visual ChatGPT (Wu et al., 2023a) and MM-REACT (Yang* et al., 2023). | >>与LLMs链接的工具。越来越多的研究将LLMs(如ChatGPT)与各种多模态基础模型集成起来,通过对话接口促进图像理解和生成。这种跨学科方法结合了NLP和计算机视觉的优势,使研究人员能够开发出更强大、更通用的人工智能系统,能够处理视觉信息,并通过人机对话产生类似人类的反应。代表性作品包括Visual ChatGPT(Wu等,2023a)和MM-REACT(Yang*等,2023)。 |
1.2、Definition and Transition from Specialists to General-Purpose Assistants定义和从专家到通用助手的过渡
两类多模型基础模型:特定目的的预训练视觉模型=视觉理解模型(CLIP/SimCLR/BEiT/SAM)+视觉生成模型(Stable Diffusion)、通用助手=统一架构的通才+遵循人类指令
| Based on the model development history and taxonomy in NLP, we group multimodal foundation models in Figure 1.2 into two categories. >> Specific-Purpose Pre-trained Vision Models cover most existing multimodal foundation mod- els, including visual understanding models (e.g., CLIP (Radford et al., 2021), SimCLR (Chen et al., 2020a), BEiT (Bao et al., 2022), SAM (Kirillov et al., 2023)) and visual generation models (e.g., Stable Diffusion (Rombach et al., 2021; sta, 2022)), as they present powerful transferable ability for specific vision problems. >> General-Purpose Assistants refer to AI agents that can follow human intents to complete various computer vision tasks in the wild. The meanings of general-purpose assistants are two-fold: (i) generalists with unified architectures that could complete tasks across different problem types, and (ii)easy to follow human instruction, rather than replacing humans. To this end, several research topics have been actively explored, including unified vision modeling (Lu et al., 2022a; Zhang et al., 2022b; Zou et al., 2023a), training and chaining with LLMs (Liu et al., 2023c; Zhu et al., 2023a; Wu et al., 2023a; Yang* et al., 2023). | 基于NLP中的模型发展历史和分类,我们将多模态基础模型分为两类,如图1.2所示。 >>特定目的的预训练视觉模型包括大多数现有的多模态基础模型,包括视觉理解模型(例如CLIP(Radford等,2021)、SimCLR(Chen等,2020a)、BEiT(Bao等,2022)、SAM(Kirillov等,2023))和视觉生成模型(例如Stable Diffusion(Rombach等,2021;sta,2022)),因为它们具有针对特定视觉问题的强大的可转移能力。 >>通用助手是指能够跟随人类意图在域外完成各种计算机视觉任务的AI代理。通用助手的含义有两层: (i)具具有统一架构的通才,可以完成不同问题类型的任务, (ii)易于遵循人类指令,而不是取代人类。为此,已经积极探讨了几个研究主题,包括统一的视觉建模(Lu等,2022a;Zhang等,2022b;Zou等,2023a)、与LLMs的培训和链接(Liu等,2023c;Zhu等,2023a;Wu等,2023a;Yang*等,2023)。 |
1.3、Who Should Read this Paper?谁应该阅读本文?
| This paper is based on our CVPR 2023 tutorial,2 with researchers in the computer vision and vision- language multimodal communities as our primary target audience. It reviews the literature and explains topics to those who seek to learn the basics and recent advances in multimodal foundation models. The target audiences are graduate students, researchers and professionals who are not ex- perts of multimodal foundation models but are eager to develop perspectives and learn the trends in the field. The structure of this paper is illustrated in Figure 1.3. It consists of 7 chapters. | 本文基于我们的CVPR 2023教程,以计算机视觉和视觉语言多模态社区的研究人员为主要目标受众。它回顾了文献并向那些寻求学习多模态基础模型的基础知识和最新进展的人解释了主题。目标受众是研究生,研究人员和专业人士,他们不是多模态基础模型的专家,但渴望发展观点和了解该领域的趋势。本文的结构如图1.3所示。全文共分七章。 |
| >> Chapter 1 introduces the landscape of multimodal foundation model research, and presents a his- torical view on the transition of research from specialists to general-purpose assistants. >> Chapter 2 introduces different ways to consume visual data, with a focus on how to learn a strong image backbone. >> Chapter 3 describes how to produce visual data that aligns with human intents. >> Chapter 4 describes how to design unified vision models, with an interface that is interactive and promptable, especially when LLMs are not employed. >> Chapter 5 describes how to train an LLM in an end-to-end manner to consume visual input for understanding and reasoning. >> Chapter 6 describes how to chain multimodal tools with an LLM to enable new capabilities. >> Chapter 7 concludes the paper and discusses research trends. | >>第1章介绍了多模态基础模型研究的背景,并提供了从专家到通用助手的研究过渡的历史视图。 >>第2章介绍了使用视觉数据的不同方法,重点介绍了如何学习强大的图像主干。 >>第3章描述了如何生成与人类意图一致的视觉数据。 >>第4章描述了如何设计统一的视觉模型,具有交互和可提示的接口,特别是在不使用LLMs的情况下。 >>第5章描述了如何以端到端的方式训练LLMs以使用视觉输入进行理解和推理。 >>第6章描述了如何将多模态工具与LLMs链接以实现新的能力。 >>第7章全文进行了总结,并对研究趋势进行了展望。 |
Figure 1.3: An overview of the paper’s structure, detailing Chapters 2-6.
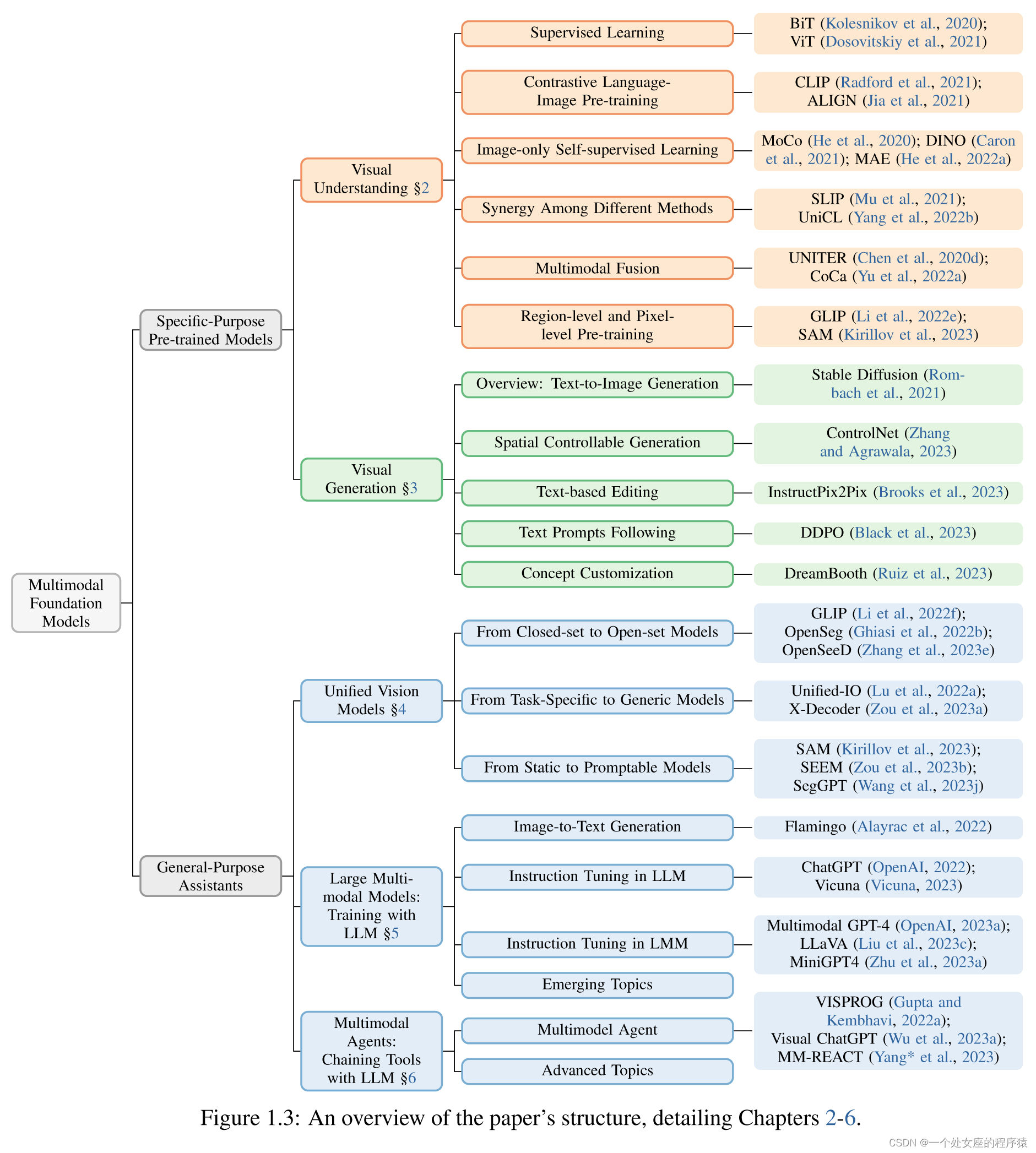
Relations among Chapters 2-6. 第2-6章之间的关系。
| Chapter 2-6 are the core chapters of this survey paper. An overview of the structure for these chapters are provided in Figure 1.2. We start with a discus- sion of two typical multimodal foundation models for specific tasks, including visual understanding in Chapter 2 and visual generation in Chapter 3. As the notion of multimodal foundation models are originally based on visual backbone/representation learning for understanding tasks, we first present a comprehensive review to the transition of image backbone learning methods, evolving from early supervised methods to the recent language-image contrastive methods, and extend the discussion on image representations from image-level to region-level and pixel-level (Chapter 2). Recently, generative AI is becoming increasingly popular, where vision generative foundation models have been developed. In Chapter 3, we discuss large pre-trained text-to-image models, and various ways that the community leverage the generative foundation models to develop new techniques to make them better aligned with human intents. Inspired by the recent advances in NLP that LLMs serve as general-purpose assistants for a wide range of language tasks in daily life, the computer vision com- munity has been anticipating and attempting to build general-purpose visual assistants. We discuss three different ways to build general-purpose assistants. Inspired by the spirit of LLMs, Chapter 4 focuses on unifying different vision models of understanding and generation without explicitly in- corporating LLMs in modeling. In contrast, Chapter 5 and Chapter 6 focus on embracing LLMs to build general-purpose visual assistants, by explicitly augmenting LLMs in modeling. Specifically, Chapter 5 describes end-to-end training methods, and Chapter 6 focuses on training-free approaches that chain various vision models to LLMs. | 第2-6章是本调查论文的核心章节。这些章节的结构概述如图1.2所示。我们首先讨论针对特定任务的两个典型的多模态基础模型,包括第2章的视觉理解和第3章的视觉生成。由于多模态基础模型的概念最初是基于用于理解任务的视觉骨干/表示学习,因此我们首先对图像骨干学习方法的转变进行了全面回顾,从早期的监督方法到最近的语言-图像对比方法,并将对图像表示的讨论从图像级扩展到区域级和像素级(第2章)。最近,生成式人工智能变得越来越流行,其中开发了视觉生成基础模型。在第3章中,我们讨论了大型预训练的文本到图像模型,以及社区利用生成基础模型开发新技术以使其更好地与人类意图保持一致的各种方法。受到NLP领域最新进展的启发,LLMs在日常生活中可以作为各种语言任务的通用助手,计算机视觉社区一直在期望并尝试构建通用视觉助手。我们讨论了三种不同的构建通用助手的方式。受LLMs的精神启发,第4章侧重于统一不同的理解和生成视觉模型,而不在建模中明确地包含LLMs。相反,第5章和第6章侧重于通过显式地在建模中增加LLMs来构建通用的视觉助手。具体来说,第5章描述了端到端训练方法,第6章侧重于无需训练即可将各种视觉模型链接到LLMs的方法。 |
How to read the paper. 如何阅读本文
| Different readers have different backgrounds, and may have different purposes of reading this paper. Here, we provide a few guidance. >> Each chapter is mostly self-contained. If you have a clear goal and a clear research direction that you want to focus on, then just jump to the corresponding chapter. For example, if you are interested in building a mini prototype using OpenAI’s multimodal GPT-4, then you can directly jump to Chapter 5. >> If you are a beginner of multimodal foundation models, and are interested in getting a glimpse of the cutting-edge research, we highly recommend that you read the whole paper chapter by chapter in order, as the early chapters serve as the building blocks of later chapters, and each chapter provides the description of the key concepts to help you understand the basic ideas, and a comprehensive literature review that to help you grasp the landscape and state of the art. >> If you already have rich experience in multimodal foundation models and are familiar with the literature, feel free to jump to specific chapters you want to read. In particular, we include in most chapters a section to discuss advanced topics and sometimes provide our own perspectives, based on the up-to-date literature. For example, in Chapter 6, we discuss several important aspects of multimodal agents in tool use, including tool creation and its connection to retrieval-augmented methods. | 不同的读者有不同的背景,可能阅读本文的目的也不同。在这里,我们提供一些建议。 >> 每一章基本上都是独立的。如果你有一个明确的目标和一个你想要关注的明确的研究方向,那么就直接跳到相应的章节。例如,如果您对使用OpenAI的多模式GPT-4构建迷你原型感兴趣,那么您可以直接跳到第5章。 >> 如果您是多模态基础模型的初学者,并且有兴趣了解前沿研究的概貌,我们强烈建议您按顺序逐章阅读整篇文章,因为早期章节是后续章节的基石,每章提供了关键概念的描述,帮助您理解基本思想,并提供了全面的文献回顾,帮助您掌握领域的概貌和最新技术。 >> 如果您已经在多模态基础模型领域拥有丰富的经验,并且熟悉相关文献,可以随意跳转到您想要阅读的特定章节。特别是在大多数章节中,我们都包含了讨论高级主题的部分,有时还根据最新文献提供了我们自己的观点。例如,在第6章中,我们讨论了多模态工具在工具使用中的几个重要方面,包括工具的创建以及与检索增强方法的关联。 |
1.4、Related Materials: Slide Decks and Pre-recorded Talks相关资料:幻灯片和预录演讲
| This survey paper extends what we present in the CVPR 2023 tutorial by covering the most recent advances in the field. Below, we provide a list of slide decks and pre-recorded talks, which are related to the topics in each chapter, for references. Chapter 2: Visual and Vision-Language Pre-training (Youtube, Bilibili) Chapter 3: Alignments in Text-to-Image Generation (Youtube, Bilibili) Chapter 4: From Representation to Interface: The Evolution of Foundation for Vision Under- standing (Youtube, Bilibili) Chapter 5: Large Multimodal Models (Youtube, Bilibili) Chapter 6: Multimodal Agents: Chaining Multimodal Experts with LLMs (Youtube, Bilibili) | 本调查论文扩展了我们在CVPR 2023教程中提出的内容,涵盖了该领域最新的进展。以下是与每章主题相关的幻灯片和预录演讲的列表,供参考。 第2章:视觉和视觉语言预训练(Youtube,Bilibili) 第3章:文本到图像生成中的对齐(Youtube,Bilibili) 第4章:从表示到接口:视觉理解基础的演变(Youtube,Bilibili) 第5章:大型多模态模型(Youtube,Bilibili) 第6章:多模态智能体:将多模态专家与LLMs链接(Youtube,Bilibili) |

