
- 1Hume获5000万美元融资,推出首个“情商”AI聊天助手
- 2.NET中的IO操作基础介绍
- 3如何搭建一个 tts 语言合成模型_tts模型训练
- 4微信小程序--多种类型日期选择器(年月、月日...)_微信小程序时间筛选
- 5HarmonyOS学习第二课:关于横向滚动视图的一些想法_harmonyos div 滚动
- 6ChatGPT扩展系列之跨平台桌面客户端ChatBox
- 7SSM+Vue+Element-UI实现网上跳蚤市场_uview跳蚤市场
- 8手把手教你做小型机器狗,毕业设计。必看_机器狗编程制作教程
- 98、MapReduce实现WordCount单词统计_wordcount只统计长度超过2的单词怎么设计mapreduce函数
- 102024年的七大前端Web开发趋势_2024 年 7 个 web 前端开发趋势
AI 框架部署方案之模型部署概述
赞
踩
0 概述
模型训练重点关注的是如何通过训练策略来得到一个性能更好的模型,其过程似乎包含着各种“玄学”,被戏称为“炼丹”。整个流程包含从训练样本的获取(包括数据采集与标注),模型结构的确定,损失函数和评价指标的确定,到模型参数的训练,这部分更多是业务方去承接相关工作。一旦“炼丹”完成(即训练得到了一个指标不错的模型),如何将这颗“丹药”赋能到实际业务中,充分发挥其能力,这就是部署方需要承接的工作。
因此,一般来说,学术界负责各种 SOTA(State of the Art) 模型的训练和结构探索,而工业界负责将这些 SOTA 模型应用落地,赋能百业。本文将要讲述的是,在 CV 场景中,如何实现模型的快速落地,赋能到产业应用中。模型部署一般无需再考虑如何修改训练方式或者修改网络结构以提高模型精度,更多的是需要明确部署的场景、部署方式(中心服务化还是本地终端部署)、模型的优化指标,以及如何提高吞吐率和减少延迟等,接下来将逐一进行介绍。
1 模型部署场景
这个问题主要源于中心服务器云端部署和边缘部署两种方式的差异 云端部署常见的模式是,模型部署在云端服务器,用户通过网页访问或者 API 接口调用等形式向云端服务器发出请求,云端收到请求后处理并返回结果。边缘部署则主要用于嵌入式设备,主要通过将模型打包封装到 SDK,集成到嵌入式设备,数据的处理和模型推理都在终端设备上执行。
2 模型部署方式
针对上面提到的两种场景,分别有两种不同的部署方案,Service 部署和 SDK 部署。 Service 部署:主要用于中心服务器云端部署,一般直接以训练的引擎库作为推理服务模式。SDK 部署:主要用于嵌入式端部署场景,以 C++ 等语言实现一套高效的前后处理和推理引擎库(高效推理模式下的 Operation/Layer/Module 的实现),用于提供高性能推理能力。此种方式一般需要考虑模型转换(动态图静态化)、模型联合编译等进行深度优化

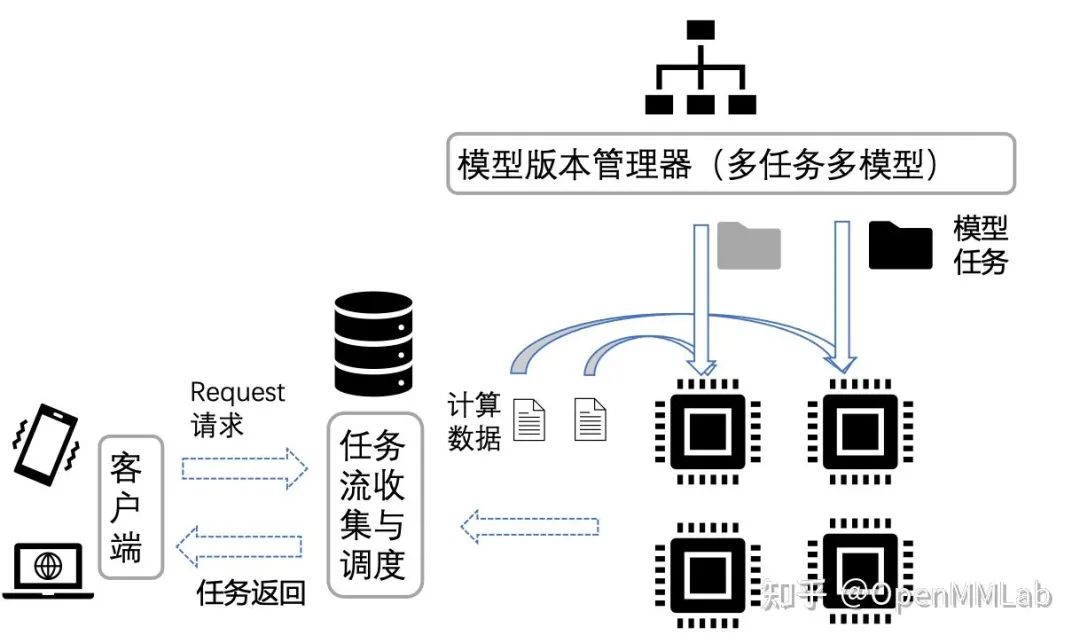
3 部署的核心优化指标
部署的核心目标是合理把控成本、功耗、性价比三大要素。
成本问题是部署硬件的重中之重,AI 模型部署到硬件上的成本将极大限制用户的业务承受能力。成本问题主要聚焦于芯片的选型,比如,对比寒武纪 MLU220 和 MLU270,MLU270 主要用作数据中心级的加速卡,其算力和功耗都相对于边缘端的人工智能加速卡MLU220要低。至于 Nvida 推出的 Jetson 和 Tesla T4 也是类似思路,Tesla T4 是主打数据中心的推理加速卡,而 Jetson 则是嵌入式设备的加速卡。对于终端场景,还会根据对算力的需求进一步细分,比如表中给出的高通骁龙芯片,除 GPU 的浮点算力外,还会增加 DSP 以增加定点算力,篇幅有限,不再赘述,主要还是根据成本和业务需求来进行权衡。
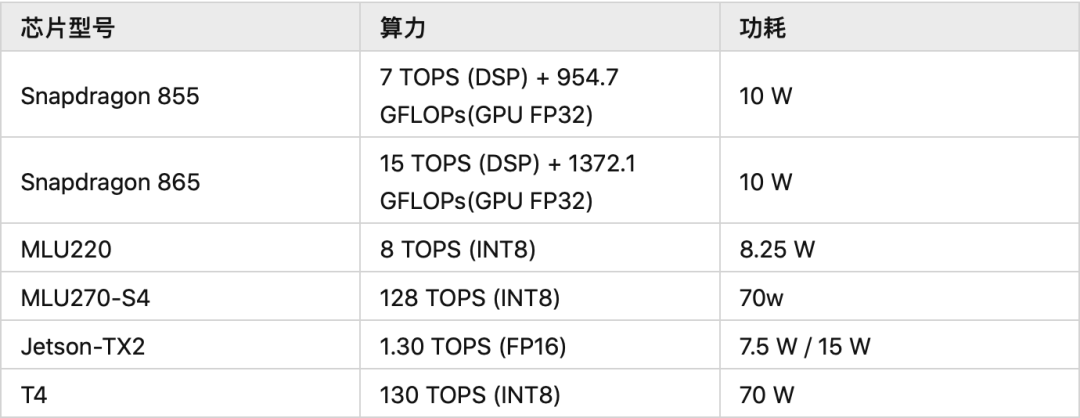
在数据中心服务场景,对于功耗的约束要求相对较低;在边缘终端设备场景,硬件的功耗会影响边缘设备的电池使用时长。因此,对于功耗要求相对较高,一般来说,利用 NPU 等专用优化的加速器单元来处理神经网络等高密度计算,能节省大量功耗。
不同的业务场景对于芯片的选择有所不同,以达到更高的性价比。从公司业务来看,云端相对更加关注是多路的吞吐量优化需求,而终端场景则更关注单路的延时需要。在目前主流的 CV 领域,低比特模型相对成熟,且 INT8/INT4 芯片因成本低,且算力比高的原因已被广泛使用;但在NLP或者语音等领域,对于精度的要求较高,低比特模型精度可能会存在难以接受的精度损失,因此 FP16 是相对更优的选择。在 CV 领域的芯片性价比选型上,在有 INT8/INT4 计算精度的芯片里,主打低精度算力的产品是追求高性价比的主要选择之一,但这也为平衡精度和性价比提出了巨大的挑战。
4 部署流程
上面简要介绍了部署的主要方式和场景,以及部署芯片的选型考量指标,接下来以 SDK 部署为例,给大家概括介绍一下 SenseParrots 在部署中的整体流程。SenseParrots 部署流程大致分为以下几个步骤:模型转换、模型量化压缩、模型打包封装 SDK。
4.1 模型转换
模型转换主要用于模型在不同框架之间的流转,常用于训练和推理场景的连接。目前主流的框架都以 ONNX 或者 caffe 为模型的交换格式,SenseParrots 也不例外。SenseParrots 的模型转换主要分为计算图生成和计算图转换两大步骤,另外,根据需要,还可以在中间插入计算图优化,对计算机进行推理加速(诸如常见的 CONV/BN 的算子融合)。
计算图生成是通过一次 inference 并追踪记录的方式,将用户的模型完整地翻译成静态的表达。在模型 inference 的过程中,框架会记录执行算子的类型、输入输出、超参、参数和调用该算子的模型层次,最后把 inference 过程中得到的算子信息和模型信息结合得到最终的静态计算图。
在计算图生成之后与计算图转换之前,可以进行计算图优化,例如去除冗余 op,计算合并等。SenseParrots 原生实现了一批计算图的精简优化 pass,也开放接口鼓励用户对计算图进行自定义的处理和优化操作。
计算图转换是指分析静态计算图的算子,对应转换到目标格式。SenseParrots 支持了多后端的转换,能够转换到各个 opset 的 ONNX、原生 caffe 和多种第三方版本的 caffe。框架通过算子转换器继承或重写的方式,让 ONNX 和 caffe 的不同版本的转换开发变得更加简单。同时,框架开放了自定义算子生成和自定义算子转换器的接口,让第三方框架开发者也能够轻松地自主开发实现 SenseParrots 到第三方框架的转换。
4.2 模型量化压缩
终端场景中,一般会有内存和速度的考虑,因此会要求模型尽量小,同时保证较高的吞吐率。除了人工针对嵌入式设备设计合适的模型,如 MobileNet 系列,通过 NAS(Neural Architecture Search) 自动搜索小模型,以及通过蒸馏/剪枝的方式压缩模型外,一般还会使用量化来达到减小模型规模和加速的目的。
量化的过程主要是将原始浮点 FP32 训练出来的模型压缩到定点 INT8(或者 INT4/INT1) 的模型,由于 INT8 只需要 8 比特来表示,因此相对于 32 比特的浮点,其模型规模理论上可以直接降为原来的 1/4,这种压缩率是非常直观的。另外,大部分终端设备都会有专用的定点计算单元,通过低比特指令实现的低精度算子,速度上会有很大的提升,当然,这部分还依赖协同体系结构和算法来获得更大的加速。
量化的技术栈主要分为量化训练(QAT, Quantization Aware Training)和离线量化(PTQ, Post Training Quantization), 两者的主要区别在于,量化训练是通过对模型插入伪量化算子(这些算子用来模拟低精度运算的逻辑),通过梯度下降等优化方式在原始浮点模型上进行微调,从来调整参数得到精度符合预期的模型。离线量化主要是通过少量校准数据集(从原始数据集中挑选 100-1000 张图,不需要训练样本的标签)获得网络的 activation 分布,通过统计手段或者优化浮点和定点输出的分布来获得量化参数,从而获取最终部署的模型。两者各有优劣,量化训练基于原始浮点模型的训练逻辑进行训练,理论上更能保证收敛到原始模型的精度,但需要精细调参且生产周期较长;离线量化只需要基于少量校准数据,因此生产周期短且更加灵活,缺点是精度可能略逊于量化训练。实际落地过程中,发现大部分模型通过离线量化就可以获得不错的模型精度(1% 以内的精度损失,当然这部分精度的提升也得益于优化策略的加持),剩下少部分模型可能需要通过量化训练来弥补精度损失,因此实际业务中会结合两者的优劣来应用。
量化主要有两大难点:一是如何平衡模型的吞吐率和精度,二是如何结合推理引擎充分挖掘芯片的能力。比特数越低其吞吐率可能会越大,但其精度损失可能也会越大,因此,如何通过算法提升精度至关重要,这也是组内的主要工作之一。另外,压缩到低比特,某些情况下吞吐率未必会提升,还需要结合推理引擎优化一起对模型进行图优化,甚至有时候会反馈如何进行网络设计,因此会是一个算法与工程迭代的过程。
4.3 模型打包封装 SDK
实际业务落地过程中,模型可能只是产品流程中的一环,用于实现某些特定功能,其输出可能会用于流程的下一环。因此,模型打包会将模型的前后处理,一个或者多个模型整合到一起,再加入描述性的文件(前后处理的参数、模型相关参数、模型格式和版本等)来实现一个完整的功能。因此,SDK 除了需要一些通用前后处理的高效实现,对齐训练时的前后处理逻辑,还需要具有足够好的扩展性来应对不同的场景,方便业务线同学扩展新的功能。可以看到,模型打包过程更多是模型的进一步组装,将不同模型组装在一起,当需要使用的时候将这些内容解析成整个流程(pipeline)的不同阶段(stage),从而实现整个产品功能。
另外,考虑到模型很大程度是研究员的研究成果,对外涉及保密问题,因此会对模型进行加密,以保证其安全性。加密算法的选择需要根据实际业务需求来决定,诸如不同加密算法其加解密效率不一样,加解密是否有中心验证服务器,其核心都是为了保护研究成果。
PS:欢迎大家关注 AI 框架技术分享专栏内容,如果有感兴趣的技术内容和难点欢迎随时指出,可以多多评论留言。我们也希望能通过本次技术分享让大家了解到更多的 AI 框架前沿技术,也期待和大家一起探讨,更欢迎大家加入我们,一同为 AI 框架及 AI 发展贡献力量!感兴趣的小伙伴儿欢迎加入小 P 家,简历投递:parrotshr@sensetime.com
5 参考文献
- # https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/tesla-t4/t4-tensor-core-datasheet-951643.pdf
- # https://www.nvidia.com/en-us/autonomous-machines/embedded-systems/jetson-tx2/
- # https://www.cambricon.com/index.php?m=content&c=index&a=lists&catid=57
- # https://www.cambricon.com/index.php?m=content&c=index&a=lists&catid=36
- # https://www.nvidia.com/en-us/data-center/tesla-t4/
- # https://zhuanlan.zhihu.com/p/58864114
- # https://www.wikiwand.com/en/List_of_Qualcomm_Snapdragon_processors#/Snapdragon_855/855+(2019)_and_860(2021)
注:本文转载自知乎文章,已由作者授权转载,未经允许,不得二次转载。
原文链接:
https://zhuanlan.zhihu.com/p/367042545
编辑:商汤学术
本文仅做学术分享,如有侵权,请联系删文。
下载1
在「3D视觉工坊」公众号后台回复:3D视觉,即可下载 3D视觉相关资料干货,涉及相机标定、三维重建、立体视觉、SLAM、深度学习、点云后处理、多视图几何等方向。
下载2
在「3D视觉工坊」公众号后台回复:3D视觉github资源汇总,即可下载包括结构光、标定源码、缺陷检测源码、深度估计与深度补全源码、点云处理相关源码、立体匹配源码、单目、双目3D检测、基于点云的3D检测、6D姿态估计源码汇总等。
下载3
在「3D视觉工坊」公众号后台回复:相机标定,即可下载独家相机标定学习课件与视频网址;后台回复:立体匹配,即可下载独家立体匹配学习课件与视频网址。
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、orb-slam3等视频课程)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近2000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、可答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~ 

