
热门标签
热门文章
- 1iOS Runtime原理及使用
- 2数据结构 第三章 线性表(三)
- 3【刷题】备战蓝桥杯 — dfs 算法
- 4Elasticsearch文档内部的父子关系_elasticsearch父子关系
- 5MySQL5种索引类型_mysql 索引类型
- 63DGS(3D Guassian Splatting)部署验证+个人数据训练
- 7MindManager2023中文版本思维导图_mindmanager 2023 license key
- 8OpenCV+Cuda+Cmake+VStudio配置踩坑记录_cmake --help-policy cmp0148
- 9Git和GitHub资料汇总_github buct资料
- 10音频调试(2)
当前位置: article > 正文
python爬虫去哪儿网上爬取旅游景点14万条,可以做大数据分析的数据基础_去哪儿网景点数据采集
作者:繁依Fanyi0 | 2024-04-12 03:58:35
赞
踩
去哪儿网景点数据采集
从去哪儿网上爬取旅游景点的相关信息。主要包括以下几个步骤:
-
导入所需的库:
BeautifulSoup用于解析网页内容,pandas用于处理数据,requests用于发送网络请求,re用于正则表达式匹配。 -
定义函数
crawer_travel_url_content(url):根据给定的URL地址发送网络请求,获取网页内容并返回BeautifulSoup对象。 -
定义函数
removenone(mylist):移除列表中的空值。 -
定义函数
regnum(s):从字符串中提取数值。 -
定义函数
crawer_travel_attraction_url(url):根据给定的城市URL,获取该城市旅游景点的总数maxnum。然后根据每页10条的规则,计算出需要爬取的页数page。遍历每一页的URL,解析页面内容,并提取景点的各种信息。将提取的信息写入CSV文件中。 -
定义景点信息的列名数组
clums。 -
创建CSV文件,并写入列名。
-
读取包含城市链接的CSV文件。
-
遍历城市链接列表,调用
crawer_travel_attraction_url(url)函数进行爬取。
主要代码如下:
def crawer_travel_url_content(url):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0'}
req = requests.get(url, headers=headers)
content = req.text
bsObj = BeautifulSoup(content, 'lxml')
return bsObj
def removenone(mylist):#移除参数中空值的函数
while '' in mylist:
mylist.remove('')
return mylist
def regnum(s):#提取爬取到的字符串中的数值
mylist = re.findall(r'[\d+\.\d]*', s)
mylist = removenone(mylist)
return mylist
def crawer_travel_attraction_url(url):
# 该城市最大景点数
maxnum = crawer_travel_url_content(url + '-jingdian').find('p', {'class': 'nav_result'}).find('span').text
# 提取数字
maxnum = int(''.join([x for x in maxnum if x.isdigit()]))
print(maxnum)
url = url + '-jingdian-1-'
# 这里取top10景点 每页10条 page从1开始
page = math.ceil(maxnum/10)
if page>200:
page=200
else:
page = math.ceil(maxnum/10)
for i in range(1, page):
url1 = url + str(i)
bsObj = crawer_travel_url_content(url1)
dw=bsObj.find_all('div',class_='ct')
dq=bsObj.find_all('li', {'class': 'item pull'})
if len(dq)<3:
sheng=dq[1].find('a').text
city=dq[1].find('a').text
else:
sheng = dq[1].find('a').text
city = dq[2].find('a').text
for i in dw:
cat = []
name=i.find('span',class_='cn_tit').text
wenzhang_num=i.find('div',class_="strategy_sum").text
pls=i.find('div',class_="comment_sum").text
pf=regnum(i.find('span',class_="cur_star").get('style'))[0]
zhanbi=i.find('span',class_='sum').text
jisnjir=i.find('div',class_='desbox').text
cat.append(sheng)
cat.append(city)
cat.append(maxnum)
cat.append(name)
cat.append(wenzhang_num)
cat.append(pls)
cat.append(pf)
cat.append(zhanbi)
cat.append(jisnjir)
print(sheng,city,name,wenzhang_num,pls,pf,zhanbi,jisnjir)
with open('去哪儿网城市景点汇总1.csv', 'a', encoding='utf-8-sig', newline='') as f:
a = csv.writer(f)
a.writerow(cat)
f.close()
print(url1+'已采集完成')
return True
import csv
clums = ['省份', '城市','景点数','景点名','文章数','评论数','评分','占比','简介']
with open('去哪儿网城市景点汇总1.csv', 'w', encoding='utf-8-sig', newline='') as f:
a = csv.writer(f)
a.writerow(clums)
f.close()
df=pd.read_csv('去哪儿网城市.csv',encoding='utf-8')
for i in df['链接'].tolist():
try:
crawer_travel_attraction_url(i)
except:
pass
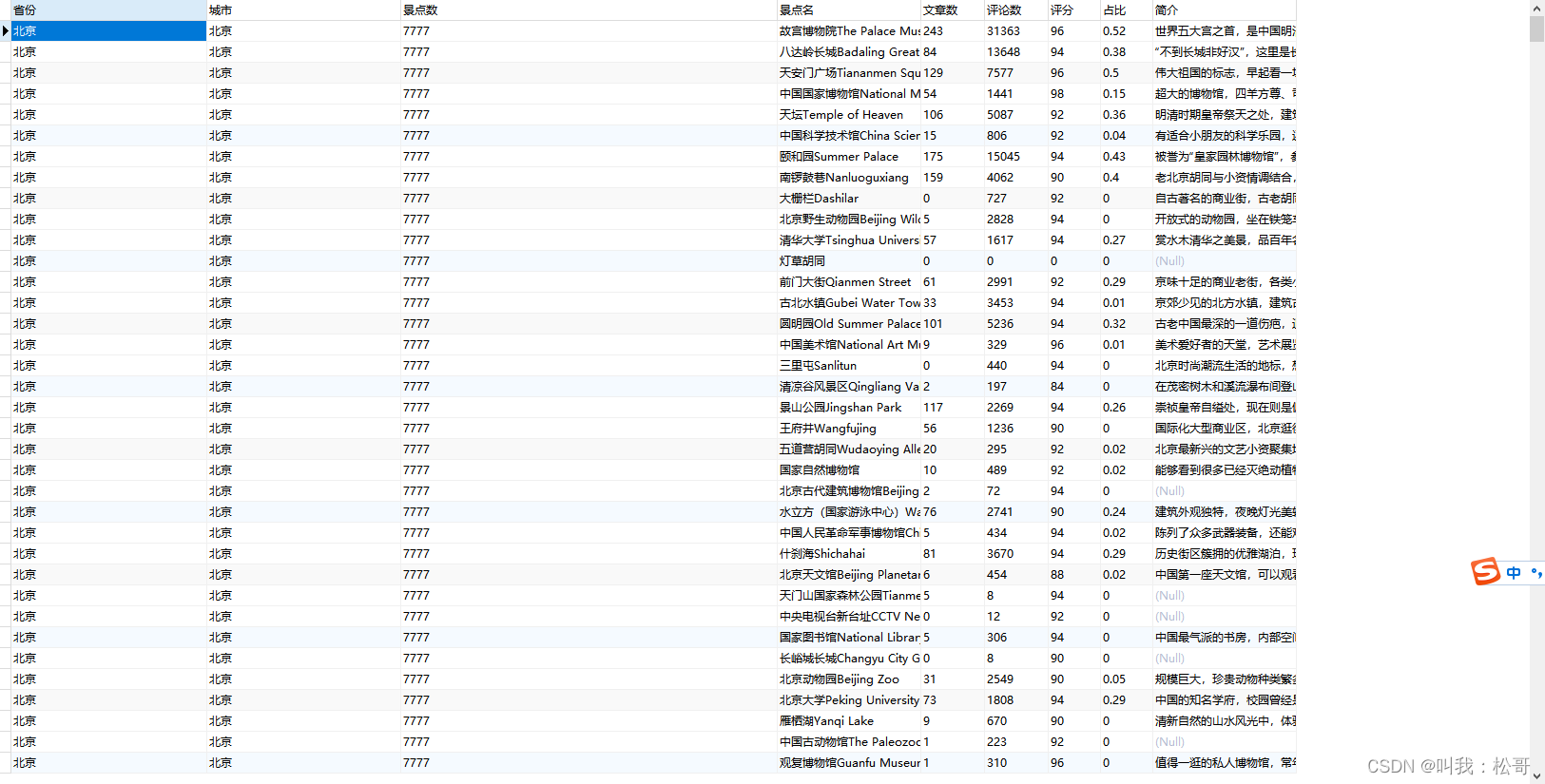
运行效果:
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/繁依Fanyi0/article/detail/409046
推荐阅读
相关标签

