
热门标签
热门文章
- 1爬虫之如何爬取海量的图片_图集中图片url不变怎么爬取
- 2字节、京东等大厂年薪50w的测试都什么水平?_京东程序员 年薪50万
- 3BERT,XLNET分词方法bpe,unigram等介绍
- 4vue大屏展示代码
- 5计算机二级Python操作题练习(第五套)_# 以下代码为提示框架 # 请在...处使用一行或多行代码替换 # 请在______处使用一
- 6Java实现学生信息管理系统:从Excel中提取数据的实用方法_学生信息管理系统 excel
- 72020年下半年软考中级——软件设计师考试总结感想(已过!!!)_软件设计师考试心得
- 8面了个腾讯30k+出来的,他让我见识到什么是基础的天花板_腾讯字节30k什么水平
- 9【谷粒学院】MybatisPlus乐观锁和悲观锁_mybatis-plus使用悲观锁
- 10Adobe After Effects 2024 v24.3 macOS 视频合成及特效制作软件 兼容 M1/M2/M3
当前位置: article > 正文
网络爬虫实战 | 上传以及下载处理后的文件_网站传送的文件怎么用爬虫
作者:繁依Fanyi0 | 2024-04-12 05:50:04
赞
踩
网站传送的文件怎么用爬虫
详细代码在文尾
以实现爬虫一个简单的(SimFIR (doctrp.top))网址为例,需要遵循几个步骤:
1. 分析网页结构
- 首先,需要分析该网页的结构,了解图片是如何存储和组织的。这通常涉及查看网页的HTML源代码,可能还包括CSS和JavaScript文件。
- 检查图片URL的模式,看看是否有规律可循,这将有助于编写爬虫时定位和下载图片。
2. 编写爬虫代码
- 使用Python中的库,如
requests来访问网页,BeautifulSoup来解析HTML。 - 编写代码以遍历网页,定位图片链接,并将它们下载到您的本地存储。
3. 实现畸变矫正
- 选择适合的畸变矫正算法。需要使用像OpenCV这样的图像处理库。
- 编写代码以批量读取下载的图片,应用畸变矫正算法,并保存矫正后的图片。
4. 自动化和优化
- 使整个过程自动化,以便只需运行一个脚本即可完成从爬取到矫正的整个流程。
- 确保您的代码在处理大量数据时效率高并且稳定。
实战开始
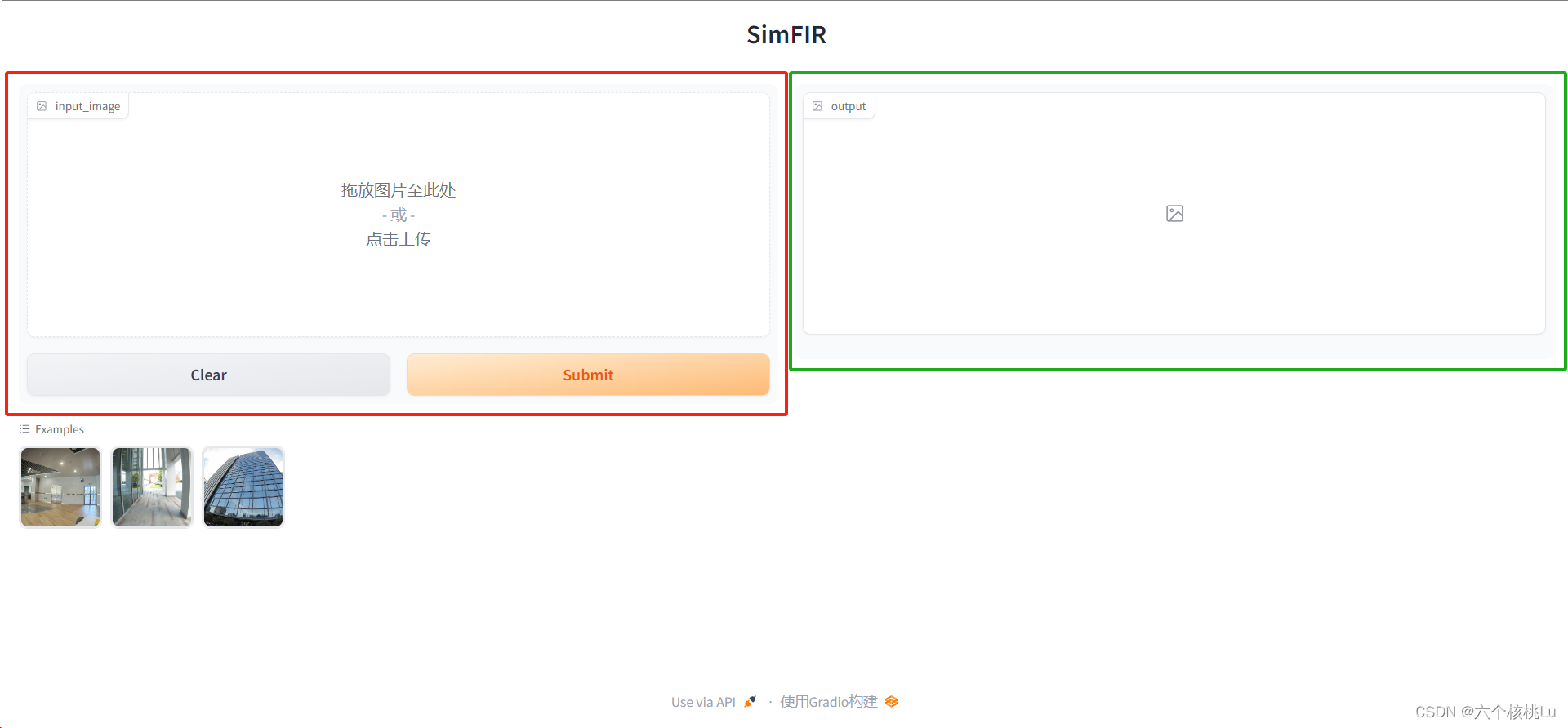
观察到红色框内"点击上传"处上传文件,然后点击按钮"Submit"实现文件上传;转换后的图片会显示在绿色框内,可点击"Download"按钮下载。
1)找到正确的URL
通常这些信息可以从网络请求中找到,使用浏览器的开发者工具观察网络请求。在浏览器中打开开发者工具(通常可以通过按F12或右键检查来打开),然后尝试正常上传一个文件。在"网络"(Network)选项卡中,可以监控到所有由网页发出的HTTP请求。找到文件上传时的请求,可以看到请求的URL、方法、请求头和请求体等信息。这里的URL就是上传接口的URL。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/繁依Fanyi0/article/detail/409422
推荐阅读
相关标签

