
- 1如何对比 MySQL 主备数据的一致性?_mysql pt 主备比对
- 2五角场 IT 养老院的性价比!
- 3PostgreSQL入门到实战-第一弹
- 4数据库基线检查工具DB_BASELINE
- 5在pycharm中使用Git上传代码到Gitee/GitHub(适合新手小白的超级详细步骤讲解)_pycharm git上传代码
- 6git-lfs-windows安装使用_git-lf-windows
- 7C#编程实现判断素数的方法_c#判断素数
- 8C#动态控件生成与数据修改_c# 动态生成控件
- 9使用Docker快速搭建Gitlab,部署Git服务_docke 部署git
- 102023年十四届蓝桥杯省赛大学B组真题(Java完整版)_蓝桥杯2023javab组
零基础自学python(python知识点手册)_python手册
赞
踩
一、python的语言基础
1.1 注释
1.单行注释
#print(verse1)2.多行注释
- """
- 注释内容1
- 注释内容2
- ...
- """
1.2 python中的变量
1.2.1 保留字与标识符
保留字:不能作为变量、函数、类、模块和其他对象的名称来使用
- and as assert break class continue
- def del elif else except finally
- for form False global if import
- in is lambda nonlocal not None
- or pass raise return try True
- while with yield
标识符
简单来说就是标识对象的名称,由字母、下划线、“-”和数字组成,并且第一个字符不能是数字。
例如,下面是合法标识符
- USERID
- name
- model2
- user_age
下面是非法标识符
- 4word
- try
- $money
1.3 基本数字类型
1.3.1 数字
八进制整数。由0~7组成,进位规则是“逢八进一”并且以0o开头的数字,如0o123(转化为83)、
-0o123(-83)
十六进制整数。由0~9,A~F组成,进位规则是“逢十六进一”,并且以0x/0X开头的数,如0x25(37),0Xb01e(45086)
浮点数:由整数部分和小数部分组成。如1.414
复数:3.14+12.5j 3.14为实部,12.5为虚部
1.3.2
字符串
连续的字符序列。通常使用单引号“ ‘ ’ ” 、双引号“ ’‘ ‘’ “ 、三引号” ‘’‘ ’‘’ “ 括起来。
转义字符
- \ 续行符
- \n 换行符
- \0 空
- \t 水平制表符,用于横向跳到下一制表位
- \" 双引号
- \` 单引号
- \\ 一个反斜杠
- \f 换页
- \0dd 八进制数
- \xhh 十六进制
1.3.3 布尔类型
True 1 ; False 0
1.3.4 数据类型转换
- int(x) 整数型
- float(x) 浮点型
- complex(real [,imag]) 创建一个复数
- str(x) 字符串
- repr(x) 表达式字符串
- eval(str) 计算表达式,并返回一个对象
- chr(x) 字符
- ord(x) 将字符转换为整数值
- hex(x) 十六进制
- oct(x) 八进制
例题:假设超市设置一个抹零行为的算法
- money_all = 56.7+72.9+88.5+26.6+68.8
- print("sum:" +str(money_all))
- money_real=int(money_all)
- print("realsum:" +str(money_real))

1.4 基本输入和输出
input()函数输入
例题:根据身高、体重计算BMI指数
- height=float(input("height:"))
- weight=float(input("weight:"))
- bmi=weight/(height*height)
- print("BMI:" +str(bmi))

1.4.2 print函数输出
print(输出内容)
二、运算符与表达式
2.1 运算符
例题:计算学生的平均成绩
- python=95
- english=92
- c=89
- sub=python-c
- avg=(python+english+c)/3
- print("分数差:" +str(sub)+ "分\n")
- print("平均分:" +str(avg)+ "分")

2.1.2 赋值运算符
例如 x+=y x=x+y
2.1.3 比较(关系)运算符
- python=95
- english=92
- c=89
- print("python>english的结果" +str(python>english))

2.1.4 逻辑运算符
- A B A and B A or B
- True True True True
- False True False True
- print("面包店正在打折,活动进行中...")
- strWeek=input("请输入中文星期:")
- intTime=int(input("请输入时间中的小时(0~23):"))
- if(strWeek=="星期二" and (intTime >= 19 and intTime <= 20)) or (strWeek=="星期六" and (intTime>=17 and intTime <= 18)):
- print("恭喜你")
- else:
- print("抱歉,来晚一步")
-
-


2.2 运算符优先级
从高到低依次为

2.3条件表达式
例题:使用表达式判断是否为闰年
- year=2023
- result="是闰年"if(year%4==0 and year % 100!=0) or (year%100==0) else"不是闰年"
- print("\n"+str(year)+"年"+result+"!")

三、流程控制语句
3.1.1 最简单的if的语句
- if表达式:
- 语句块1
- else:
- 语句块2
如下列代码:
- a=-9
- if a>0:
- b=a
- else:
- b=-a
- print(b)
也可以写成
- a=-9
- b= a if a>0 else -a
- print(b)
3.1.2 if...elif..else语句
- if 表达式1:
- 语句块1
- elif表达式2:
- 语句块2
- ...
- else:
- 语句块n
3.1.3 if语句的嵌套
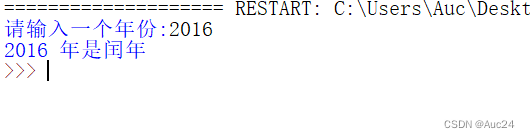
例题:判断输入的年份是否为闰年
- year=int(input("请输入一个年份:"))
- if year % 4 == 0:
- if year % 100 == 0:
- if year % 400 == 0:
- print(year,"年是闰年")
- else:
- print(year,"年不是闰年")
- else:
- print(year,"年是闰年")
- else:
- print(year,"年不是闰年")
3.2 循环语句
3.2.1 while循环
- while 条件表达式:
- 循环体
例题:用while循环写1累加到100
- i=0
- result=0
- while i<=100:
- result+=i
- i+=1
- print(result)

3.2.2 for循环语句
- for 迭代变量 in 对象:
- 循环体
例题:用while循环写1累加到100
- result=0
- for i in range(101):
- result+=i
- print(result)

range(start,end,step)
start:起始值,可以省略,默认从0开始
end:结束值,不能省略
step:指定步长,即两个数之间的距离,如果省略默认步长为1
如输出10以内的所有奇数
- for i in range(1,10,2):
- print(i,end=' ')

3.2.3 循环嵌套
例如打印九九乘法表
- for i in range(1,10):
- for j in range(1,i+1):
- print(str(j)+"X"+str(i)+"="+str(i*j)+"\t",end='')
- print('')

3.3 break、continue和pass语句
3.3.1 break语句和continue语句
break终止当前循环,continue中止本次循环提前进入下次循环
如计算100以内所有偶数的和
- total=0
- for number in range(1,100):
- if number%2 == 1:
- continue
- total+=number
- print("偶数和为:",total)

如果将continue改为break
- total=0
- for number in range(1,100):
- if number%2 == 1:
- break
- total+=number
- print("偶数和为:",total)
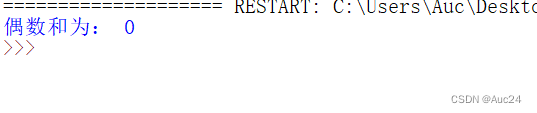
3.3.2 pass语句
表示空语句,起到占位的作用
- for i in range(1,10):
- if i%2 == 0:
- print(i,end=' ')
- else:
- pass
四、列表与元组
4.1 序列概述
4.1.1 索引
通过索引可以访问序列中任何元素。
- verse=["a","b","c","d"]
- print(verse[2]) #访问第三个元素
- print(verse[-1]) #访问最后一个元素

4.1.2 切片
访问序列中元素的另一种方法
sname[start:end:step]
sname:序列名称
start:切片开始位置,若不指定,默认为0
end:切片截至位置(不包括该位置),如果不指定,默认为序列长度
step:切片步长,如果省略,默认为1
- verse=["a","b","c","d","e","f","g","h","i","j"]
- print(verse[1:6]) #获取第2个到第6个元素
- print(verse[1:6:2]) #获取第2个、第4个和第6个元素
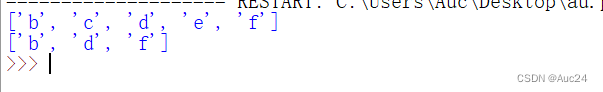
4.1.3 序列相加
- verse1=["a","b","c","d","e","f","g","h","i","j"]
- verse2=["h","i","j"]
- print(verse1+verse2)

4.1.4 乘法
- verse=["h","i","j"]
- print(verse*3)

除对序列的乘法,话可以实现初始化指定长度列表的功能
- verse=["h"]*5
- print(verse)

4.1.5 检查某个元素是否是序列的成员(元素)
value in sequence
value 要检查的元素;sequence指定的序列
- verse=["a","b","c","d","e","f","g"]
- print("e"in verse)

- verse=["a","b","c","d","e","f","g"]
- print("e"not in verse)

4.1.6 计算序列的长度、最大值和最小值
- num=[7,14,21,28,35,42,49,56,63]
- print("序列num的长度为",len(num))

- num=[7,14,21,28,35,42,49,56,63]
- print("序列",num,"中最大值为",max(num))
-

- num=[7,14,21,28,35,42,49,56,63]
- print("序列",num,"中最小值为",min(num))
-

除了上面三个内置函数,还有如下内置函数
list() 将序列转换为列表
str() 将序列转换为字符串
sum() 计算元素和
sorted() 对元素进行排序
reversed() 反向序列中的元素
enumerate() 将序列组合为一个索引序列,多用在for循环中
4.2 列表
4.2.1 列表的创建和删除
1.使用赋值运算符直接创建列表
listname=[element1,element2,element3,...,element n]
2.创建空列表
emptylist=[]
3.创建数值列表
list(data)
data表示可以转换为列表的数据
如,创建一个10~20的所有偶数列表
- num=list(range(10,20,2))
- print(num)

4.删除列表
del listname
listname为要删除列表的名称
verse=["a","b","c","d"]
del verse
4.2.2 访问列表元素
若想直接输出列表,可直接使用print()函数
- verse=["a","b","c","d"]
- print(verse)

也可以通过索引获取指定元素
- verse=["a","b","c","d"]
- print(verse[2])

4.2.3 遍历列表
1.直接使用for循环实现
for item in listname:
# 输出 item
item用于保存获取到的元素值;listname为列表名称。
- verse=["a","b","c","d"]
- for item in verse:
- print(item)

2.使用for循环和enumerate()函数实现
for index,item in enumerate(listname):
# 输出 index 和 item
index:用于保存元素的索引
item:用于保存获取到的元素值
listname:列表名称
- verse=["a","b","c","d"]
- for index,item in enumerate(verse):
- print(index,item)

如每两句一行输出古诗《登高》
- print(" "*11,"登高")
- verse=["风急天高猿啸哀","渚清沙白鸟飞回","无边落木萧萧下",
- "不尽长江滚滚来","万里悲秋常作客","百年多病独登台",
- "艰难苦恨繁霜鬓","潦倒新停浊酒杯"]
- for index,item in enumerate(verse):
- if index%2==0:
- print(item+",",end='')
- else:
- print(item+"。")

4.2.4 添加、修改和删除列表元素
1.添加元素
listname.append(obj)
listname为要添加的元素名称;obj为添加列表末尾的对象
- verse=["a","b","c","d"]
- verse.append("e")
- print(verse)

如果想将一个列表添加到另一个列表中,可以用extend()
listname.extend(seq)
listname为原列表;seq为要添加的元素
- verse1=["a","b","c","d"]
- verse2=["e","f"]
- verse2.extend(verse1)
- print(verse2)

2.修改元素
- verse=["a","b","c","d"]
- print(verse)
- verse[2]="e"
- print(verse)

3.删除元素
(1)根据索引删除
- verse=["a","b","c","d"]
- del verse[-1]
- print(verse)

(2)根据元素值删除
如果想要删除一个不确定其位置的元素,可以使用remove()方法实现
- verse=["a","b","c","d"]
- verse.remove("b")
- print(verse)
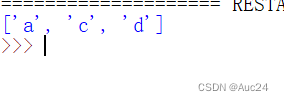
4.2.5 对列表进行统计计算
1.获取指定元素出现的次数
listname.count(obj)
listname表示列表名称,obj表示判断是否存在对象
- verse=["a","b","c","d","a","c"]
- num=verse.count("a")
- print(num)

2.获取指定元素首次出现的下标
listname.index(obj)
listname:列表名称
obj:要查找的对象
返回值:首次出现的索引
- verse=["a","b","c","d","a","c"]
- position=verse.index("d")
- print(position)

3.统计数值列表的元素和
sum(iterable[,start])
iterable:表示要统计的列表
start:表示统计结果是从哪个数开始,如果没有指定,默认为0
- grade=[98,99,97,95,96,94,93]
- total=sum(grade)
- print("英语成绩为:",total)

4.2.6 对列表进行排序
1.使用列表对象的sort()方法实现
listname.sort(key=None,reverse=False)
listname:进行排序的列表
key:指定一个从每个列表元素中提取一个比较键
reverse:可选参数,如果其值指定为True,表示降序,如果为False,表示升序,默认为升序
例如定义一个保存10名学生英语成绩的列表,然后用sort()进行排序
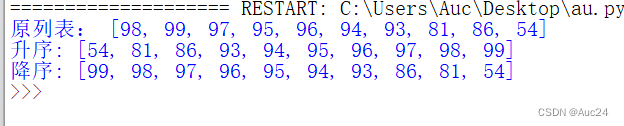
- grade=[98,99,97,95,96,94,93,81,86,54]
- print("原列表:",grade)
- grade.sort()
- print("升序:",grade)
- grade.sort(reverse=True)
- print("降序:",grade)
若对字母进行排序,需指定其key参数
- char=['dog','Mike','Jay','cat']
- char.sort()
- print("区分大小写:",char)
- char.sort(key=str.lower)
- print("不区分字母大小写:",char)
-

2.使用内置的sorted()函数实现
sorted(iterable,key=None,reverse=False)
iterable:进行排序的列表名称
key:指定从每个元素中提取一个用于比较的键
reverse:可选参数,如果其值指定为True,表示降序,如果为False,表示升序,默认为升序
- grade=[98,99,97,95,96,94,93,81,86,54]
- grade_as=sorted(grade)
- print("升序:",grade_as)
- grade_des=sorted(grade,reverse=True)
- print("降序:",grade)
- print("原列表:",grade)
-

4.2.7 列表推导式
(1)生成指定范围的数值列表
list=[Expression for var in range]
list:表示生成的列表名称
Expression:表达式,用于计算新列表的元素
var:循环变量
range:采用range()函数生成的range对象
例如生成一个包括10个随机数的列表,要求数的范围在10~100
- import random
- randomnumber=[random.randint(10,100)for i in range(10)]
- print("生成的随机数为:",randomnumber)

(2)根据列表生成指定需求的列表
newlist=[Expression for var in list]
newlist:新生成的列表名称
Expression:表达式,用于计算新列表的元素
var:变量
list:用于生成新列表的原列表
例如,定义一个商品价格的列表,并生成一个全部商品打五折的列表
- price=[1200,5330,2987,6201,1987,9999]
- sale=[int(x*0.5) for x in price]
- print("原价格:",price)
- print("打五折的价格:",sale)

(3)从列表中选择符合条件的元素组成新的列表
newlist=[Expression for var in list if condition]
newlist:列表名称
Expression:计算新列表的元素
var:变量
list:生成新列表的原列表
condition:指定筛选条件
例如,定义一个记录商品的列表,并生成一个价格高于5000的列表
- price=[1200,5330,2987,6201,1987,9999]
- sale=[x for x in price if x>5000]
- print("原价格:",price)
- print("高于5000价格:",sale)

4.2.8 二维列表
1.直接定义二维列表
- verse=[['a','b','c','d'],['e','f','g','h'],
- ['i','j','k','l']]
- print(verse)
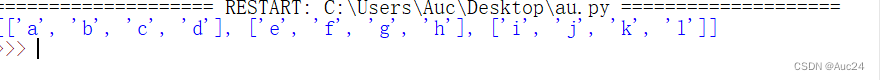
2.使用嵌套的for循环创建
如创建一个包含4行5列的二维列表
- arr=[]
- for i in range(4):
- arr.append([])
- for j in range(5):
- arr[i].append(j)
3.使用列表推导式创建
arr=[[j for j in range(5)] for i in range(4)]创建二维数组后可以用以下语法访问
listname[下标1][下标2]
listname:列表名称;
如访问第2行,第4列,可以用verse[1][3]
4.3 元组
4.3.1 元组的创建和删除
1.使用赋值运算直接创建元组
tuplename=(element1,element2,...,element n)
2.创建空元组
emptyuple=()
3.创建数值元组
tuple(data)
例如创建一个10~20的偶数元组
- oushu=tuple(range(10,20,2))
- print(oushu)
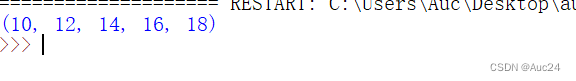
4.删除元组
del tuplename
4.3.2 访问元组元素
- title=('Python',24,('a','b'),['yi','er'])
- print(title[0])

元组也可以采用切片方式获取指定元素
- title=('Python',24,('a','b'),['yi','er'])
- print(title[:3])

4.3.3 修改元组
元组是不可变序列,所以只能对元组重新赋值
- name=('a','e','c','d')
- name=('a','b','c','d')
- print(name)
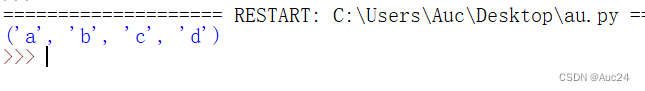
4.3.4 元组推导式
例如使用元组推导式生成一个包含10个随机数,并转换为元组
- import random
- randomnumber=(random.randint(10,100)for i in range(10))
- print("转换后:",tuple(randomnumber))

五、字典与集合
5.1 字典
字典的主要特征:
通过键而不是通过索引来读取;
字典是任意对象的无序集合
字典是可变的,并且可以任意嵌套
字典中的键必须唯一
字典中的键必须不可变
5.1.1 字典的创建和删除
dictionary={'key1':'value1','key2':'value2',...,'keyn':'valuen',}
dictionary:字典名称
key1,...,keyn:元素的键,必须是唯一且不可变
value1,...,valuen:元素的值,可以是任何数据类型,不是必须唯一
例如保存一个登录界面信息的字典
- dictionary={'账号':'1234567','密码':'23432145'}
- print(dictionary)

创建空字典
dictionary={}
或者
dictionary=dict()
dict()除了可以创建空字典,还可以通过已有数据快速创建字典,分别有两种:
1.通过映射函数创建字典
dictionary=dict(zip(list1,list2))
例如根据名字和学号创建一个字典
- number=['1','2','3','4']
- name=['小明','小红','小白','小蓝']
- dictionary=dict(zip(number,name))
- print(dictionary)

2.通过给定的”键-值对“创建字典
dictionary=dict(key1=value1,key2=value2,...,keyn=valuen)
- dictionary=dict(1 = '小明',2 = '小红',3 = '小白',4 = '小蓝')
- print(dictionary)
另外还可以通过已经存在的元组和列表创建字典
- number=('1','2','3','4')
- name=['小明','小红','小白','小蓝']
- dict1={number:name}
- print(dict1)

5.1.2 访问字典
print(dictionary)
dictionary.get(key[,default])
5.1.3 遍历字典
dictionary.items()
- dictionary={'账号':'1234567','密码':'d32wd34','验证码':'xy13'}
- for item in dictionary.items():
- print(item)

如果想分别得到键和值,可以采用以下代码
- dictionary={'账号':'1234567','密码':'d32wd34','验证码':'xy13'}
- for key,item in dictionary.items():
- print(key,item)

5.1.4 添加、修改和删除字典元素
dictioary[key]=value
例如在创建的字典中添加一个元素
- dictionary=dict((('小明','一'),('小红','二'),('小白','三')))
- dictionary["小蓝"]="四"
- print(dictionary)

如果要修改一个元素
- dictionary=dict((('小明','一'),('小红','二'),('小白','三')))
- dictionary["小白"]="四"
- print(dictionary)

删除一个元素
- dictionary=dict((('小明','一'),('小红','二'),('小白','三')))
- del dictionary["小白"]
- print(dictionary)
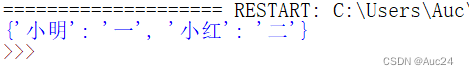
5.1.5 字典推导式
字典推导式可以快速生成一个字典,例如生成一个包含4个随机数的字典
- import random
- randomdict={i:random.randint(10,100) for i in range(1,5)}
- print("生成字典为:",randomdict)

使用字典推导式也可以根据列表生成字典
- number=('1','2','3','4')
- name=['小明','小红','小白','小蓝']
- dictionary={i:j for i,j in zip(number,name)}
- print(dictionary)

5.2 集合
6.2.1 创建集合
1.直接使用“{}”创建
setname={element 1,element 2,element 3,..,element n}
2.直接使用set()函数创建
setname=set(iteration)
- set1=set("Everything will be ok in the end")
- print(set1)

从上面可以看出,如果出现重复元素,只保留其中一个
5.2.2 向集合中添加和删除元素
1.向集合中添加元素
setname.add(element)
- au=set(["Everything will be ok in the end"])
- au.add(',if is not ok,it not in the end')
- print(au)

2,从集合中删除元素
- au=set(['Everything will be ok in the end','if is not ok it not in the end'])
- au.remove('if is not ok it not in the end')
- print(au)
![]()
六、字符串
6.1 字符串编码转换
6.1.1 encode()方法编码
str.encode([encoding="utf-8"][,errors="stric"])
str:要进行转换的字符串
encoding=“utf-8”:可选参数,用于指定进行转码时采用的字符编码,若使用简体中文,可设置为gb2312.
errors=”strict“:用于指定错误的处理方式,strict(遇到非法字符就抛出异常)、ignore(忽略非法字符)、replace(用“?”替换非法字符)、xmlcharrefreplace(使用XML的字符引用)
例如定义一个字符串,然后使用encode()方法采用GBK编码转换为二进制数,并输出
- au="我自横刀谢天笑"
- aun=au.encode('GBK')
- print('原字符串:',au)
- print('转换后:',aun)

6.1.2 使用decode()方法解码
bytes.decode([encoding="utf-8"][,errors="strict"]
bytes:表示要进行转换的二进制数据
eencoding=“utf-8”:可选参数,用于指定进行转码时采用的字符编码,若使用简体中文,可设置为gb2312.
errors=”strict“:用于指定错误的处理方式,strict(遇到非法字符就抛出异常)、ignore(忽略非法字符)、replace(用“?”替换非法字符)、xmlcharrefreplace(使用XML的字符引用)
例如将二进制数据进行解码
- au="我自横刀谢天笑"
- aun=au.encode('GBK')
- print('原字符串:',au)
- print('转换后:',aun)
- print('解码后:',aun.decode("GBK"))

6.2 字符串常用操作
6.2.1 拼接字符串
- auo="别人笑我太疯的"
- aut="我笑他人看不穿"
- print(auo+','+aut)
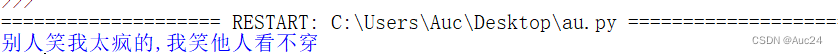
6.2.2 计算字符串长度
len(string)
- aun="这看起来,非常very good"
- length=len(aun)
- print(length)

默认情况下,通过len()函数计算字符串都会把所有字符串认为是一个,有时需要获取字符串实际字数,若采用UTF-8,汉字占3个字节;若采用GBK或GB2312,汉字占2个字节。
- aun="这看起来,非常very good"
- length=len(aun.encode())
- print(length)
![]()
- aun="这看起来,非常very good"
- length=len(aun.encode('gbk'))
- print(length)
![]()
6.2.3 截取字符串
string[start:end:step]
string:要截取的字符
start:要截取的第一个字符的索引,默认为0
end:要截取的最后一个字符的索引,默认为字符串的长度
step:切片步长,默认为1
- aun="这看起来,非常very good"
- aun1=aun[1]
- aun2=aun[5:]
- aun3=aun[:5]
- aun4=aun[2:5]
- print('原字符串:',aun)
- print(aun1+'\n'+aun2+'\n'+aun3+'\n'+aun4)

6.2.4 分割、合并字符串
1.分割字符串
str.split(sep,maxsplit)
str:要进行分割的字符串
sep:指定分隔符
maxsplit:指定分割次数,若不指定或者为-1,则分割次数没有限制,否则返回结果列表的元素个数最多为maxsplit+1
例如用split()方法输出名字
- aun='@小明 @小红 @小蓝'
- list=aun.split(' ')
- print("你@的好友:")
- for item in list:
- print(item[1:])
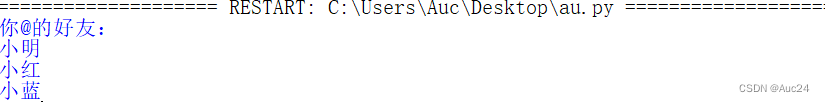
2.合并字符串
strnew=string.join(iterable)
strnew:合并后生成的新字符串
string:指定合并时的分隔符
iterable:可迭代对象
- aun=['小明','小红','小蓝']
- friends='@'.join(aun)
- ate='@'+friends
- print("你@的好友:",ate)
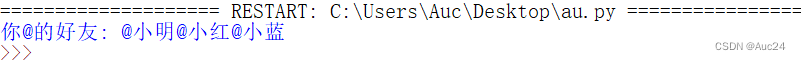
6.2.5 检索字符串
1.count()方法
str.count(sub[,start[,end]])
str:原字符串
sub:要检索的字符串
start:检索范围的起始位置的索引,若未指定,则从头开始检索
end:检索范围的起始位置的索引,若未指定,则一直检索到结尾
例如应用count()方法检索该字符中“@”出现的次数
- aun='@小明 @小白 @小蓝'
- print('字符串 "',aun,'" 中包括',aun.count('@'),'个@符号')

2.find()方法
str.find(sub[,start[,end]])
str:原字符串
sub:要检索的字符串
start:检索范围的起始位置的索引,若未指定,则从头开始检索
end:检索范围的起始位置的索引,若未指定,则一直检索到结尾
应用find()方法检索“@”符号出现的索引位置
- aun='@小明 @小白 @小蓝'
- print('字符串 "',aun,'" 中@符号首次出现的索引位置为:',aun.find('@'))

3.index()方法
str.index(sub[,start[,end]])
str:原字符串
sub:要检索的字符串
start:检索范围的起始位置的索引,若未指定,则从头开始检索
end:检索范围的起始位置的索引,若未指定,则一直检索到结尾
例如应用index()方法检索“@”符号首次出现的位置
- aun='@小明 @小白 @小蓝'
- print('字符串 "',aun,'" 中@符号首次出现的索引位置为:',aun.index('@'))

4.startswith()方法
str.startwith(prefix[,start[, end]]
str:原字符串
sub:要检索的字符串
start:检索范围的起始位置的索引,若未指定,则从头开始检索
end:检索范围的起始位置的索引,若未指定,则一直检索到结尾
例如应用startswith()方法检索字符串是否以“@”符号开头
- aun='@小明 @小白 @小蓝'
- print('字符串 "',aun,'" 是否以@符号开头,结果为:',aun.startswith('@'))

5.endswith()方法
str.endswith(suffix[,start[,end]])
str:原字符串
suffix:要检索的字符串
start:检索范围的起始位置的索引,若未指定,则从头开始检索
end:检索范围的起始位置的索引,若未指定,则一直检索到结尾
例如应用endswith()方法检索该字符是否以“.com”结尾
- aun='http://www.aun.com'
- print('字符串 "',aun,'" 是否以.com结尾,结果为:',aun.endswith('.com'))

6.2.6 字母的大小写转换
str.lower()
例如将下列字母转换为小写字母
- aun='AUN'
- print(aun.lower())
![]()
2.upper()方法
str.upper()
例如将下列字母转换为大写字母
- aun='aun'
- print(aun.upper())
![]()
6.2.7 去除字符串中的空格和特殊字符
1.strip()方法
str.strip([chars])
例如去除下列左右两侧的特殊字符
- aun='@aun#¥'
- print(aun.strip('@#'))
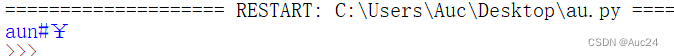
2.lstrip()方法
str.lstrip([chars])
例如去除左侧的特殊字符
- aun='@aun#¥'
- print(aun.lstrip('@#¥'))
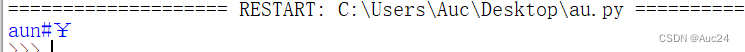
3.rstrip()方法
str.rstrip([chars])
- aun='@aun#¥'
- print(aun.rstrip('@#¥'))
![]()
6.2.8 格式化字符串
格式化字符串意思是先制定一个模板,在模板中预留几个空位,然后根据需要填上相应的内容
1.使用%操作符
'%[-][+][0][m][.n]格式化字符'%exp
-:左对齐
+:右对齐
0:右对齐,正数前方元符号,负数前方加负号
m:占有宽度
.n:小数点后保留的位数
格式化字符:用于指定类型
例如定义一个保存学生信息的字符串模板,然后应用该模板输出不同学生的信息
- aun='学号: %09d\t 姓名: %s \t 学校地址: http://www.%s.com'
- auc1=(2,'小明','aun1')
- auc2=(3,'小蓝','aun2')
- print(aun%auc1)
- print(aun%auc2)

2.使用字符串对象的format()方法
str.format(args)
{[index][:[[fill]agin][sign][#][width][.precision][type]]}
index:用于指定要设置格式的对象在索引的位置
fill:指定空白处填充的字符
align:指定对齐方式(“<"左对齐,">"右对齐,"="表示内容右对齐,将符号放在填充内容的最左侧,且只对数字类型有效;”^"表示内容居中)
sign:指定有无符号数
#:在二进制、八进制、十六进制前加上“#”,则显示出0b/0o/0x前缀
width:指定所占宽度
.precision:指定保留的小数位数
type:指定类型
例如定义一个保存学生信息的字符串模板,然后应用该模板输出不同学生的信息
- aun='学号: {:0>9s}\t 姓名: {:s}\t 学校地址: http://www.{:s}.com'
- auc1=aun.format('2','小明','aun1')
- auc2=aun.format('3','小蓝','aun2')
- print(auc1)
- print(auc2)

到此为止,基础python内容结束,往后会持续更新!


