
- 1Apache DolphinScheduler内置时间参数_$[yyyymmdd-1]
- 2maven 打jar包:mvn clean package
- 3前端面试技巧和注意事项
- 4STP_stp报文
- 5使用Diamond比对NR数据库获取物种注释_diamond nr
- 6一、开源共享精神_简述gun gpl和开发源代码精神
- 7在git上更改github的token_github token过期
- 8java如何实现Socket的长连接和短连接
- 9从永远到永远-Git撤销某次commit_webstorm 修改了文件commit还是灰色
- 10如何解决Command timed out after 1 minute(s) 问题
Stable Diffusion XL Turbo
赞
踩
使用一块 A100,出图的延迟只有 200 毫秒。SDXL Turbo、LCM相继发布,AI画图进入实时生成时代:字打多快,出图就有多快
本周二,Stability AI 推出了新一代图像合成模型 Stable Diffusion XL Turbo,引发了一片叫好。人们纷纷表示,图像到文本生成从来没有这么轻松。
你可以不需要其他操作,只用在文本框中输入你的想法,SDXL Turbo 就能够迅速响应,生成对应内容。一边输入,一边生成,内容增加、减少,丝毫不影响它的速度。

你还可以根据已有的图像,更加精细地完成创作。手中只需要拿一张白纸,告诉 SDXL Turbo 你想要一只白猫,字还没打完,小白猫就已经在你的手中了。

你还可以根据已有的图像,更加精细地完成创作。手中只需要拿一张白纸,告诉 SDXL Turbo 你想要一只白猫,字还没打完,小白猫就已经在你的手中了。
SDXL Turbo 模型的速度达到了近乎「实时」的程度,让人不禁开始畅想:图像生成模型是不是可以干些其他事了。
有人直接连着游戏,获得了 2fps 的风格迁移画面:
据官方博客介绍,在 A100 上,SDXL Turbo 可在 207 毫秒内生成 512x512 图像(即时编码 + 单个去噪步骤 + 解码,fp16),其中单个 UNet 前向评估占用了 67 毫秒。
如此,我们可以判断,文生图已经进入「实时」时代。
这样的「即时生成」效率,与前不久爆火的清华 LCM 模型看起来有些相似,但是它们背后的技术内容却有所不同。Stability 在同期发布的一篇研究论文中详细介绍了该模型的内部工作原理。该研究重点提出了一种名为对抗扩散蒸馏(Adversarial Diffusion Distillation,ADD)的技术。SDXL Turbo 声称的优势之一是它与生成对抗网络(GAN)的相似性,特别是在生成单步图像输出方面。
论文地址:https://static1.squarespace.com/static/6213c340453c3f502425776e/t/65663480a92fba51d0e1023f/1701197769659/adversarial_diffusion_distillation.pdf
论文细节
简单来说,对抗扩散蒸馏是一种通用方法,可将预训练扩散模型的推理步数量减少到 1-4 个采样步,同时保持高采样保真度,并有可能进一步提高模型的整体性能。
为此,研究者引入了两个训练目标的组合:(i)对抗损失和(ii)与 SDS 相对应的蒸馏损失。对抗损失迫使模型在每次前向传递时直接生成位于真实图像流形上的样本,避免了其他蒸馏方法中常见的模糊和其他伪影。蒸馏损失使用另一个预训练(且固定)的 扩散模型作为教师,有效利用其广泛知识,并保留在大型扩散模型中观察到的强组合性。在推理过程中,研究者未使用无分类器指导,进一步减少了内存需求。他们保留了模型通过迭代细化来改进结果的能力,这比之前基于 GAN 的单步方法具有优势。
训练步骤如图 2 所示:

表 1 介绍了消融实验的结果,主要结论如下:

接下来是与其他 SOTA 模型的对比,此处研究者没有采用自动化指标,而是选择了更加可靠的用户偏好评估方法,目标是评估 prompt 遵循情况和整体图像。
实验通过使用相同的 prompt 生成输出来比较多个不同的模型变体(StyleGAN-T++、OpenMUSE、IF-XL、SDXL 和 LCM-XL)。在盲测中,SDXL Turbo 以单步击败 LCM-XL 的 4 步配置,并且仅用 4 步击败 SDXL 的 50 步配置。通过这些结果,可以看到 SDXL Turbo 的性能优于最先进的 multi-step 模型,其计算要求显著降低,而无需牺牲图像质量。

图 7 可视化了有关推理速度的 ELO 分数。

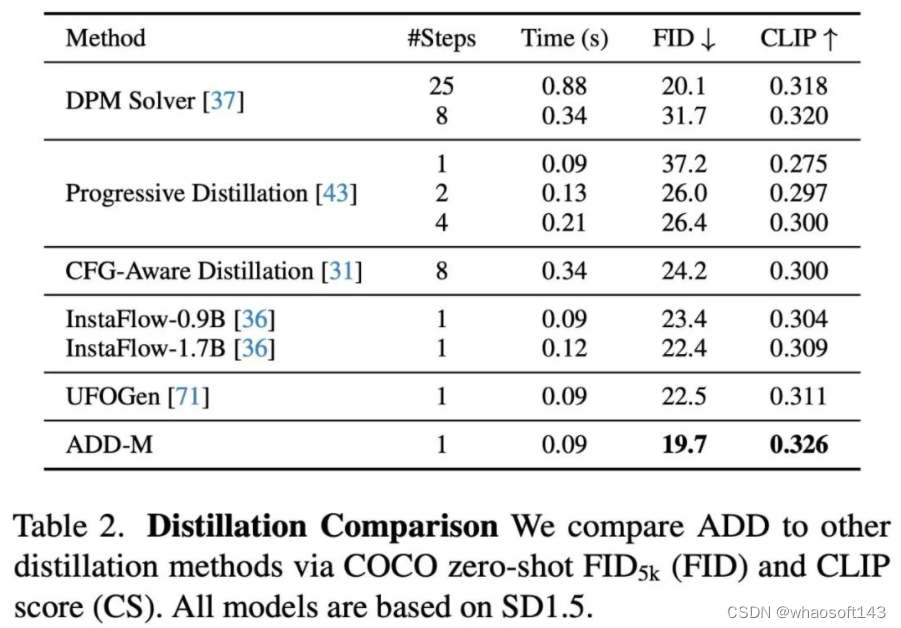
表 2 比较了使用相同基础模型的不同 few-step 采样和蒸馏方法。结果显示,ADD 的性能优于所有其他方法,包括 8 步的标准 DPM 求解器。 whaosoft aiot http://143ai.com
作为定量实验结果的补充,论文也展示了部分定性实验结果,展示了 ADD-XL 在初始样本基础上的改进能力。图 3 将 ADD-XL(1 step)与 few-step 方案中当前最佳基线进行了比较。图 4 介绍了 ADD-XL 的迭代采样过程。图 8 将 ADD-XL 与其教师模型 SDXL-Base 进行了直接比较。正如用户研究所示,ADD-XL 在质量和 prompt 对齐方面都优于教师模型。




