
- 1玩机进阶教程------手机定制机 定制系统 解除系统安装软件限制的一些步骤解析
- 2MySQL获取当前时间_mysql 当前时间戳
- 3[大模型]Qwen1.5-7B-Chat-GPTQ-Int4 部署环境
- 4砂石厂智能监管预警系统 解决传统监管难题_砂石防人员掩埋预警系统
- 5sql中删除数据的几种方式_sql删除数据
- 6java后端接口开发详细教程,javamap集合面试题
- 7中文命名实体识别(ner)迁移学习_迁移学习的命名实体抽取
- 8GPT实战系列-LangChain的Tools函数转换器
- 9简易安装gpt4all_gpt4all安装无组件
- 10vivado simulation仿真(38译码器实现)_vivadio实现3—8译码器的设计文件代码
(CVPR2019)图像语义分割(18) DANet-集成双路注意力机制的场景分割网络_danet双通道自注意网络
赞
踩
论文地址: Dual Attention Network for Scene Segmentation
工程地址:github链接
1. 介绍
该论文提出新型的场景分割网络DANet,利用自注意力机制进行丰富语义信息的捕获,在带有空洞卷积的FCN架构的尾部添加两个并行的注意力模块:位置注意力模块和通道注意力模块,论文在Cityscapes,PASCAL Context和COCO数据集上都取得了SOTA效果。
具体地在位置注意力模块中,任一位置的特征的更新是通过图像所有位置上特征的带权聚合进行更新,权重是由两个位置上特征的相似性决定的,也就是说无论两个位置的距离只要他们的特征相似那么就能得到更高的权重。
通道注意力模块中也应用了相似的自注意力机制来学习任意两个通道映射之间的关系,同样通过所有通道的带权加和来更新某一个通道。
2. 双路注意力网络
DANet的整体框架如下图所示,对ResNet进行变形,移除最后两个模块的下采样后应用空洞卷积,得到一个输出特征图,尺寸为输入图像的1/8,然后这个输出特征图分别输入给两个注意力模块中以捕获全局(long-range)语义信息[像素点之间建立的某种联系]。在位置注意力模块中,首先生成一个位置注意力矩阵用于对任意两个点之间的关系建模,接着注意力矩阵与特征矩阵进行矩阵乘法,然后对相乘结果和原始特征矩阵进行逐元素的加法得到最终对全局语义具有一定表征能力的结果。通道注意力模块的操作相似,只不过乘法实在通道维度进行计算。最终将两个模块的结果进行聚合得到一个更好的表征结果已进行接下来的逐像素预测。
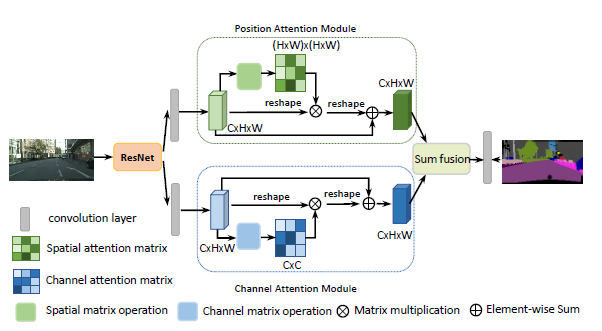
2.1 位置注意力模块
对于场景理解具有判别力的特征表示是关键的,位置注意力模块通过编码更广范围的语义信息到局部感受野中以增强特征图表示能力,论文这一节就详细描述了该模块是怎样逐步聚合位置语义的过程。
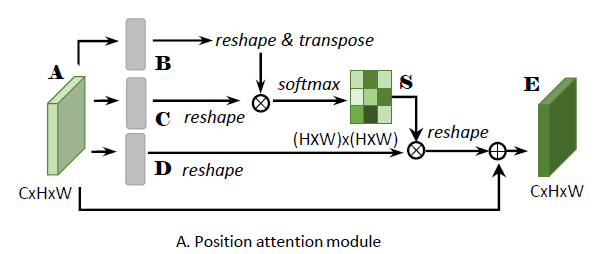
如上图所示,给定一个特征
A
∈
R
C
×
H
×
W
A \in R^{C \times H \times W}
A∈RC×H×W,然后经过一个带有BN层和ReLU层的卷积操作得到两个新的特征B,C,其中{
B
,
C
B,C
B,C}
∈
R
C
×
H
×
W
\in R^{C \times H \times W}
∈RC×H×W,然后将这两个特征reshape到
R
C
×
N
R^{C \times N}
RC×N,其中
N
=
H
×
W
N=H \times W
N=H×W,然后在B和C的转置上应用一次矩阵乘法,之后应用softmax层计算位置注意力映射图
S
∈
R
N
×
N
S \in R^{N \times N}
S∈RN×N,具体地,
s i j = e x p ( B i ⋅ C j ) ∑ i = 1 N e x p ( B i ⋅ C j ) s_{ij}=\frac{exp(B_i \cdot C_j)}{\sum^N_{i=1}exp(B_i \cdot C_j)} sij=∑i=1Nexp(Bi⋅Cj)exp(Bi⋅Cj)
其中
s
i
j
s_{ij}
sij表示第
i
i
i个位置对第
j
j
j个位置的影响,两个位置的特征越相似对这个值的影响越大。
同时将特征
A
A
A输入到一个带有BN层和ReLU层的卷积层产生另外一个特征图
D
∈
R
C
×
H
×
W
D \in R^{C \times H \times W}
D∈RC×H×W,同样reshape到
R
C
×
N
R^{C \times N}
RC×N,然后对D和S的转置应用一次矩阵乘法,reshape为
R
C
×
H
×
W
R^{C \times H \times W}
RC×H×W,然后乘上一个因子
α
\alpha
α,与特征A进行一个逐元素的相加操作得到最终额的输出
E
∈
R
C
×
H
×
W
E \in R^{C \times H \times W}
E∈RC×H×W,即:
E j = α ∑ i = 1 N ( s j i D i ) + A j E_j=\alpha \sum^{N}_{i=1}(s_{ji}D_i)+A_j Ej=αi=1∑N(sjiDi)+Aj
其中 α \alpha α初始化为0然后逐渐学习,通过上面这个公式可以看出最终的特征E的每一个位置都是所有位置的特征和原始特征的带权加和得到,因此能够聚合全局语义信息。
2.2 通道注意力模块
高层特征的每一个通道映射可以看做一个类别明确的响应并且不同的语义响应之间互相联系。通过获取不同通道映射之间的相互依赖性可以有效增强特征图对于特定语义的表征能力,因此设计该通道注意力模块。
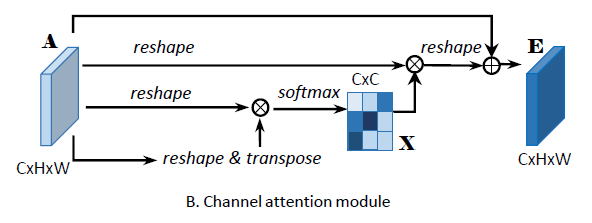
通道注意力模块如上图所示,与位置注意力模块不同的是,论文直接从原始特征
A
∈
R
C
×
H
×
W
A \in R^{C \times H \times W}
A∈RC×H×W直接计算
X
∈
R
C
×
C
X \in R^{C \times C}
X∈RC×C。首先对特征图A进行reshape操作至
R
C
×
N
R^{C \times N}
RC×N,然后在A与A的转置上应用一次矩阵乘法,最终应用一个softmax层以获得通道注意力图
X
∈
R
C
×
C
X \in R^{C \times C}
X∈RC×C,其中
x
j
i
=
e
x
p
(
A
i
⋅
A
j
)
∑
i
=
1
C
e
x
p
(
A
i
⋅
A
j
)
x_{ji}=\frac{exp(A_i \cdot A_j)}{\sum ^C_{i=1}exp(A_i \cdot A_j)}
xji=∑i=1Cexp(Ai⋅Aj)exp(Ai⋅Aj)
其中 x j i x_{ji} xji表示了第i个通道对第j个通道的影响。之后论文对X的转置和A进行一次矩阵乘法然后reshape到 R C × H × W R^{C \times H \times W} RC×H×W,然后乘上一个因子 β \beta β,然后与原始特征A进行一个逐元素的加和操作得到最终的特征图 E ∈ R C × H × W E \in R^{C \times H \times W} E∈RC×H×W,具体地,
E j = β ∑ i = 1 C ( x j i A i ) + A j E_j=\beta \sum^{C}_{i=1}(x_{ji}A_i)+A_j Ej=βi=1∑C(xjiAi)+Aj
同理, β \beta β初始化为0并且逐渐学习,上个公式表明最终输出的每个通道的特征都是所有通道的特征和原始特征图的带权加和,从而增强了通道特征图之间的全局语义依赖,最终增强了特征图的判别能力。
2.3 将注意力模块集成到网络中
为了更好地利用两个注意模块的全局语义信息,论文将模块的输出经过一个卷积层后进行一个逐元素的加和实现特征融合,然后接一个卷积层得到最终的预测结果。
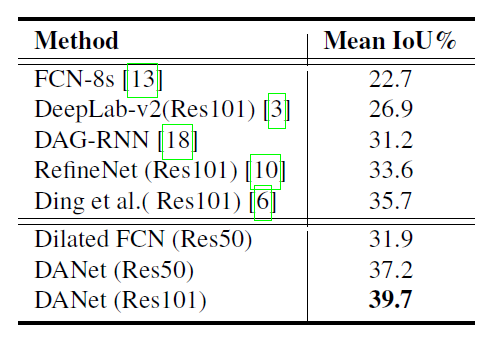
3. 实验结果
Cityscapes验证集上结果的可视化,从左到右,原始图像,两个不同位置点的子特征图,通道11和4的特征图,预测结果和groud truth

Cityscapes测试集上的mIoU和每个类别的结果

Pascal VOC 测试集结果

Pascal Context 测试集结果

COCO测试集结果
欢迎扫描二维码关注微信公众号 深度学习与数学 [每天获取免费的大数据、AI等相关的学习资源、经典和最新的深度学习相关的论文研读,算法和其他互联网技能的学习,概率论、线性代数等高等数学知识的回顾]


